|
15 | 15 | "\n", |
16 | 16 | "The model, a language model, was trained by just trying to predict the next word for many many millions of documents found on the web. This is called unsupervised learning because we don't have a set of labels we are trying to predict. \n", |
17 | 17 | "\n", |
18 | | - "The GPT-2 blog post and paper do not go into much detail into how the model was designed. However, we know that they use a transformer architecture. At a high level, the Transformer converts input sequences into output sequences.\n", |
| 18 | + "The GPT-2 blog post and paper do not go into much detail into how the model was designed. However, we know that they use a transformer architecture. At a high level, the Transformer converts input sequences into output sequences. It's composed of an encoding component and a decoding component.\n", |
19 | 19 | "\n", |
20 | | - "\n", |
21 | | - "\n", |
22 | | - "The Transformer is composed of an encoding component and a decoding component.\n", |
23 | | - "\n", |
24 | | - "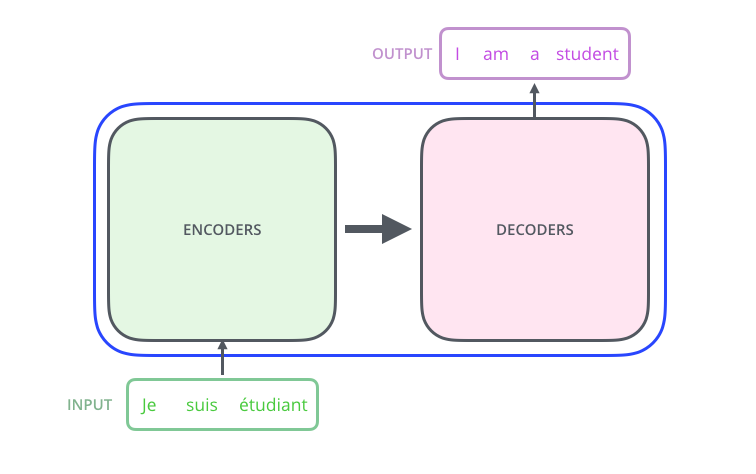\n", |
| 20 | + "\n", |
25 | 21 | "\n", |
26 | 22 | "The Transformer is actually composed of stacks of encoders and decoders.\n", |
27 | 23 | "\n", |
28 | | - "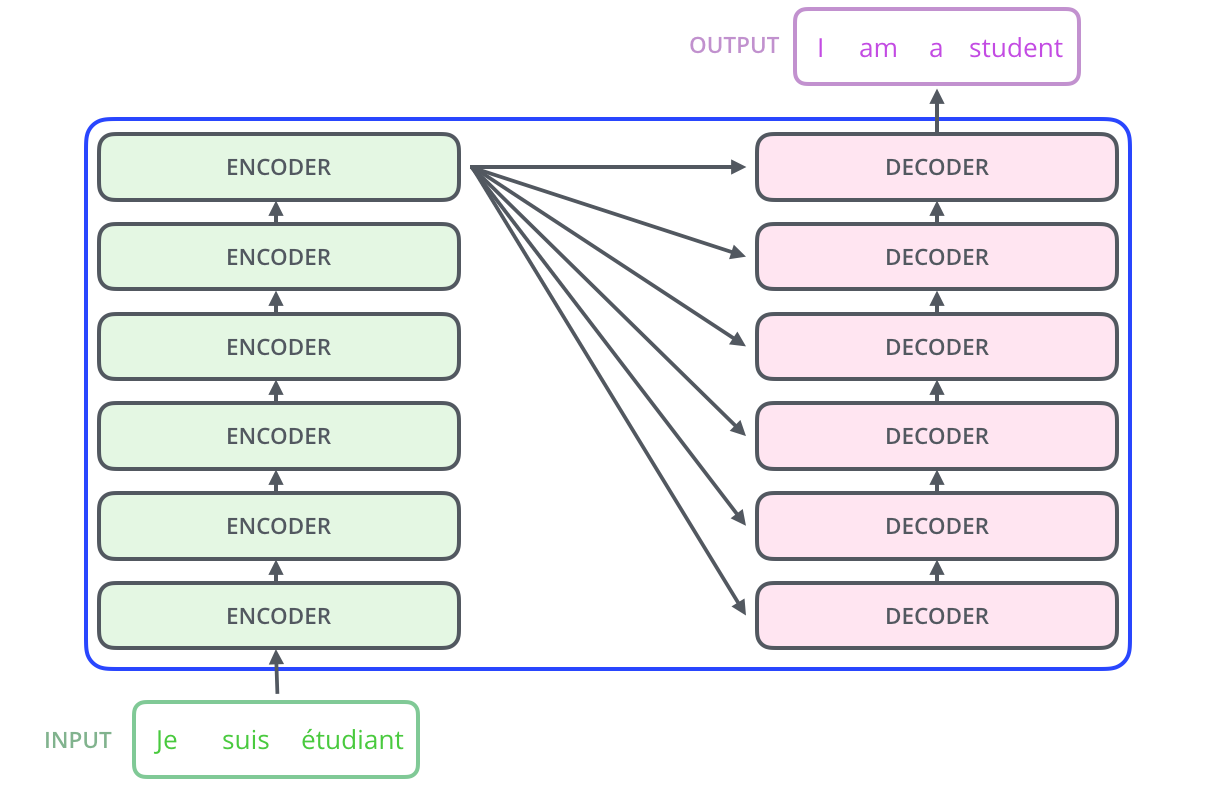\n", |
| 24 | + "\n", |
29 | 25 | "\n", |
30 | 26 | "We can see a snapshot of how tensors flow through this encoder-decoder architecture:\n", |
31 | 27 | "\n", |
|
{kind=link}
{kind=link}
0 commit comments