|
| 1 | +### 题目描述 |
| 2 | + |
| 3 | +这是 LeetCode 上的 **[745. 前缀和后缀搜索](https://leetcode.cn/problems/prefix-and-suffix-search/solution/by-ac_oier-ayej/)** ,难度为 **困难**。 |
| 4 | + |
| 5 | +Tag : 「字典树」 |
| 6 | + |
| 7 | + |
| 8 | + |
| 9 | +设计一个包含一些单词的特殊词典,并能够通过前缀和后缀来检索单词。 |
| 10 | + |
| 11 | +实现 `WordFilter` 类: |
| 12 | + |
| 13 | +* `WordFilter(string[] words)` 使用词典中的单词 `words` 初始化对象。 |
| 14 | +* `f(string pref, string suff)` 返回词典中具有前缀 `prefix` 和后缀 `suff` 的单词的下标。如果存在不止一个满足要求的下标,返回其中 最大的下标 。如果不存在这样的单词,返回 $-1$ 。 |
| 15 | + |
| 16 | +示例: |
| 17 | +``` |
| 18 | +输入 |
| 19 | +["WordFilter", "f"] |
| 20 | +[[["apple"]], ["a", "e"]] |
| 21 | + |
| 22 | +输出 |
| 23 | +[null, 0] |
| 24 | + |
| 25 | +解释 |
| 26 | +WordFilter wordFilter = new WordFilter(["apple"]); |
| 27 | +wordFilter.f("a", "e"); // 返回 0 ,因为下标为 0 的单词:前缀 prefix = "a" 且 后缀 suff = "e" 。 |
| 28 | +``` |
| 29 | +提示: |
| 30 | +* 1ドル <= words.length <= 10^4$ |
| 31 | +* 1ドル <= words[i].length <= 7$ |
| 32 | +* 1ドル <= pref.length, suff.length <= 7$ |
| 33 | +* `words[i]`、`pref` 和 `suff` 仅由小写英文字母组成 |
| 34 | +* 最多对函数 `f` 执行 10ドル^4$ 次调用 |
| 35 | + |
| 36 | +--- |
| 37 | + |
| 38 | +### 基本分析 |
| 39 | + |
| 40 | +为了方便,我们令 `words` 为 `ss`,令 `pref` 和 `suff` 分别为 `a` 和 `b`。 |
| 41 | + |
| 42 | +搜索某个前缀(后缀可看做是反方向的前缀)容易想到字典树,但单词长度数据范围只有 7ドル,ドル十分具有迷惑性,使用暴力做法最坏情况下会扫描所有的 $ss[i],ドル不考虑任何的剪枝操作的话,计算量也才为 2ドル \times \ 7 \times 1e4 = 1.4 \times 10^5,ドル按道理是完全可以过的。 |
| 43 | + |
| 44 | +但不要忘记 LC 是一个具有「设定每个样例时长,同时又有总时长」这样奇怪机制的 OJ。 |
| 45 | + |
| 46 | +--- |
| 47 | + |
| 48 | +### 暴力(TLE or 双百) |
| 49 | + |
| 50 | +于是有了 `Java` 总时间超时,`TypeScripe` 双百的结果(应该是 `TypeScript` 提交不多,同时设限宽松的原因): |
| 51 | + |
| 52 | +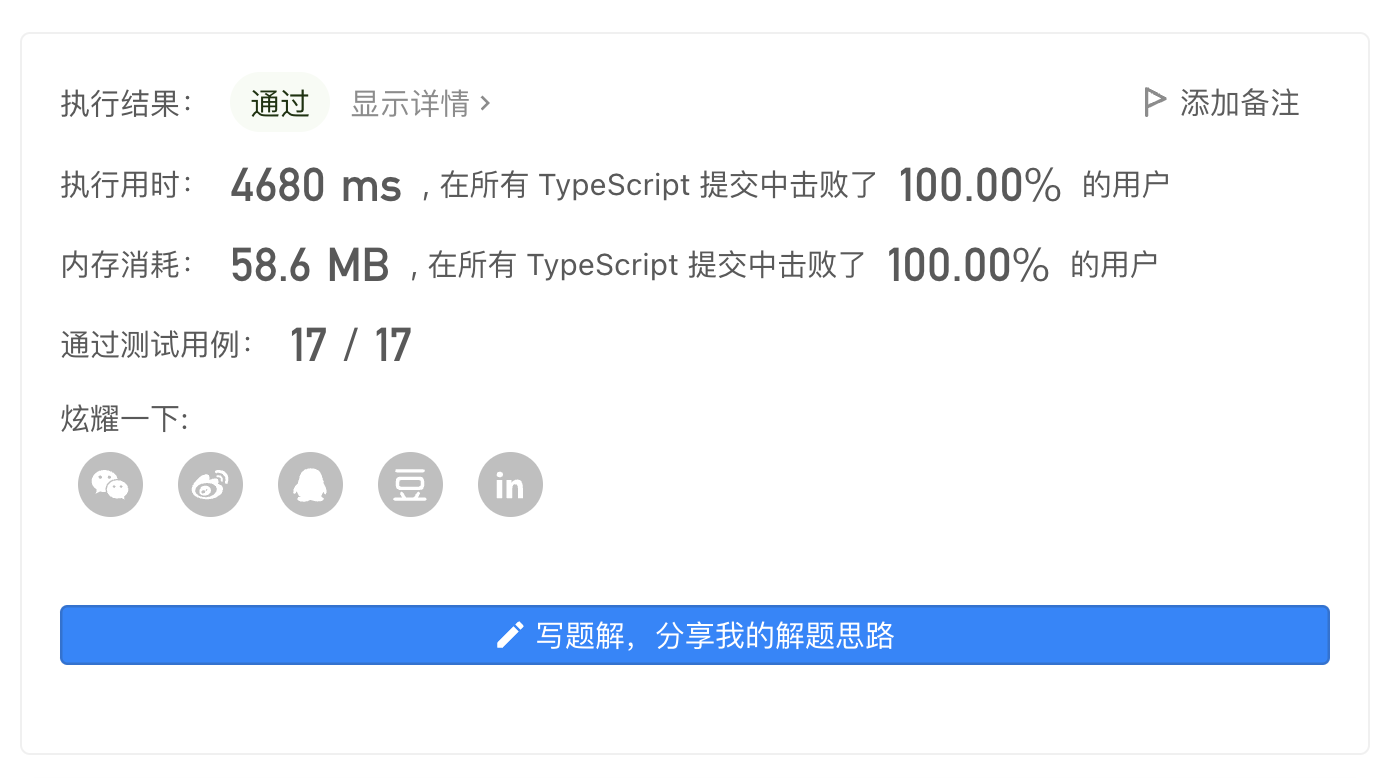 |
| 53 | + |
| 54 | +Java 代码: |
| 55 | +```Java |
| 56 | +class WordFilter { |
| 57 | + String[] ss; |
| 58 | + public WordFilter(String[] words) { |
| 59 | + ss = words; |
| 60 | + } |
| 61 | + public int f(String a, String b) { |
| 62 | + int n = a.length(), m = b.length(); |
| 63 | + for (int k = ss.length - 1; k >= 0; k--) { |
| 64 | + String cur = ss[k]; |
| 65 | + int len = cur.length(); |
| 66 | + if (len < n || len < m) continue; |
| 67 | + boolean ok = true; |
| 68 | + for (int i = 0; i < n && ok; i++) { |
| 69 | + if (cur.charAt(i) != a.charAt(i)) ok = false; |
| 70 | + } |
| 71 | + for (int i = 0; i < m && ok; i++) { |
| 72 | + if (cur.charAt(len - 1 - i) != b.charAt(m - 1 - i)) ok = false; |
| 73 | + } |
| 74 | + if (ok) return k; |
| 75 | + } |
| 76 | + return -1; |
| 77 | + } |
| 78 | +} |
| 79 | +``` |
| 80 | +TypeScript 代码: |
| 81 | +```TypeScript |
| 82 | +class WordFilter { |
| 83 | + ss: string[] |
| 84 | + constructor(words: string[]) { |
| 85 | + this.ss = words |
| 86 | + } |
| 87 | + f(a: string, b: string): number { |
| 88 | + const n = a.length, m = b.length |
| 89 | + for (let k = this.ss.length - 1; k >= 0; k--) { |
| 90 | + const cur = this.ss[k] |
| 91 | + const len = cur.length |
| 92 | + if (len < n || len < m) continue |
| 93 | + let ok = true |
| 94 | + for (let i = 0; i < n && ok; i++) { |
| 95 | + if (cur[i] != a[i]) ok = false |
| 96 | + } |
| 97 | + for (let i = m - 1; i >= 0; i--) { |
| 98 | + if (cur[len - 1 - i] != b[m - 1 - i]) ok = false |
| 99 | + } |
| 100 | + if (ok) return k |
| 101 | + } |
| 102 | + return -1 |
| 103 | + } |
| 104 | +} |
| 105 | +``` |
| 106 | +* 时间复杂度:初始化操作复杂度为 $O(1),ドル检索操作复杂度为 $O(\sum_{i = 0}^{n - 1} ss[i].length)$ |
| 107 | +* 空间复杂度:$O(\sum_{i = 0}^{n - 1} ss[i].length)$ |
| 108 | + |
| 109 | +--- |
| 110 | + |
| 111 | +### Trie |
| 112 | + |
| 113 | +使用字典树优化检索过程也是容易的,分别使用两棵 `Trie` 树来记录 $ss[i]$ 的前后缀,即正着存到 `tr1` 中,反着存到 `Tr2` 中。 |
| 114 | + |
| 115 | +> 还不了解 `Trie` 的同学可以先看前置 🧀:[【设计数据结构】实现 Trie (前缀树)](https://mp.weixin.qq.com/s?__biz=MzU4NDE3MTEyMA==&mid=2247488490&idx=1&sn=db2998cb0e5f08684ee1b6009b974089) |
| 116 | +前置 🧀 通过图解形式讲解了 `Trie` 的结构与原理,以及提供了两种实现 `Trie` 的方式 |
| 117 | + |
| 118 | +同时对于字典树的每个节点,我们使用数组 `idxs` 记录经过该节点的字符串 $ss[i]$ 所在 `ss` 中的下标 $i,ドル若某个字典树节点的索引数组 `tr.idxs` 为 $[a_1, a_2, ..., a_k]$ 则代表「从根节点到 `tr` 节点所对应的字符串」为 $ss[a_1], ss[a_2], ..., ss[a_k]$ 的前缀。 |
| 119 | + |
| 120 | +这样我们可以即可在扫描前后缀 `a` 和 `b` 时,得到对应的候选下标列表 `l1` 和 `l2`,由于我们将 $ss[i]$ 添加到两棵 `tr` 中是按照下标「从小到大」进行,因此我们使用「双指针」算法分别从 `l1` 和 `l2` 结尾往后找到第一个共同元素即是答案(满足条件的最大下标)。 |
| 121 | + |
| 122 | +> 使用 `Trie` 优化后,`Java` 从 `TLE` 到 `AC`,`TypeScript` 耗时为原本的 $\frac{1}{7}$ : |
| 123 | + |
| 124 | +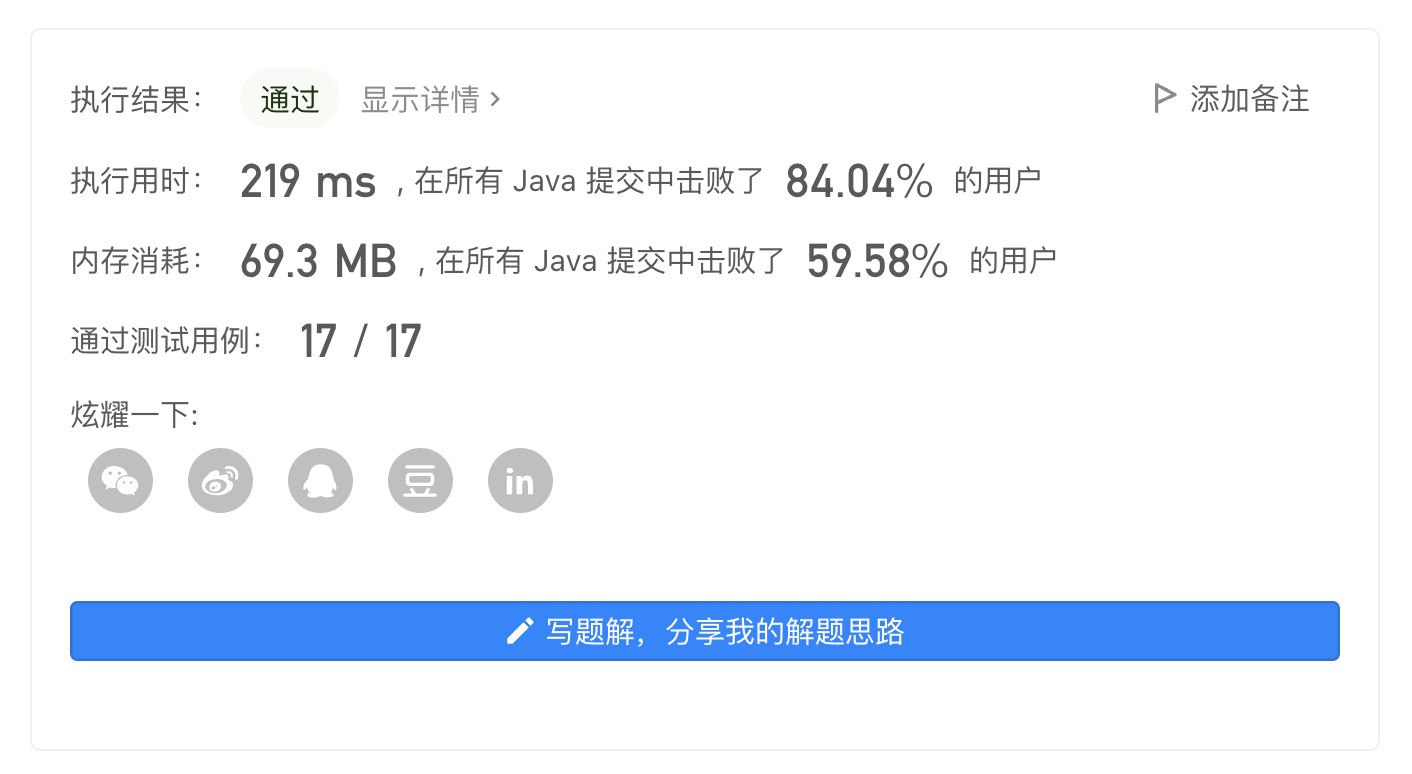 |
| 125 | + |
| 126 | +Java 代码: |
| 127 | +```Java |
| 128 | +class WordFilter { |
| 129 | + class TrieNode { |
| 130 | + TrieNode[] tns = new TrieNode[26]; |
| 131 | + List<Integer> idxs = new ArrayList<>(); |
| 132 | + } |
| 133 | + void add(TrieNode p, String s, int idx, boolean isTurn) { |
| 134 | + int n = s.length(); |
| 135 | + p.idxs.add(idx); |
| 136 | + for (int i = isTurn ? n - 1 : 0; i >= 0 && i < n; i += isTurn ? -1 : 1) { |
| 137 | + int u = s.charAt(i) - 'a'; |
| 138 | + if (p.tns[u] == null) p.tns[u] = new TrieNode(); |
| 139 | + p = p.tns[u]; |
| 140 | + p.idxs.add(idx); |
| 141 | + } |
| 142 | + } |
| 143 | + int query(String a, String b) { |
| 144 | + int n = a.length(), m = b.length(); |
| 145 | + TrieNode p = tr1; |
| 146 | + for (int i = 0; i < n; i++) { |
| 147 | + int u = a.charAt(i) - 'a'; |
| 148 | + if (p.tns[u] == null) return -1; |
| 149 | + p = p.tns[u]; |
| 150 | + } |
| 151 | + List<Integer> l1 = p.idxs; |
| 152 | + p = tr2; |
| 153 | + for (int i = m - 1; i >= 0; i--) { |
| 154 | + int u = b.charAt(i) - 'a'; |
| 155 | + if (p.tns[u] == null) return -1; |
| 156 | + p = p.tns[u]; |
| 157 | + } |
| 158 | + List<Integer> l2 = p.idxs; |
| 159 | + n = l1.size(); m = l2.size(); |
| 160 | + for (int i = n - 1, j = m - 1; i >= 0 && j >= 0; ) { |
| 161 | + if (l1.get(i) > l2.get(j)) i--; |
| 162 | + else if (l1.get(i) < l2.get(j)) j--; |
| 163 | + else return l1.get(i); |
| 164 | + } |
| 165 | + return -1; |
| 166 | + } |
| 167 | + TrieNode tr1 = new TrieNode(), tr2 = new TrieNode(); |
| 168 | + public WordFilter(String[] ss) { |
| 169 | + int n = ss.length; |
| 170 | + for (int i = 0; i < n; i++) { |
| 171 | + add(tr1, ss[i], i, false); |
| 172 | + add(tr2, ss[i], i, true); |
| 173 | + } |
| 174 | + } |
| 175 | + public int f(String a, String b) { |
| 176 | + return query(a, b); |
| 177 | + } |
| 178 | +} |
| 179 | +``` |
| 180 | +TypeScript 代码: |
| 181 | +```TypeScript |
| 182 | +class TrieNode { |
| 183 | + tns: TrieNode[] = new Array<TrieNode>() |
| 184 | + idxs: number[] = new Array<number>() |
| 185 | +} |
| 186 | +class WordFilter { |
| 187 | + add(p: TrieNode, s: string, idx: number, isTurn: boolean): void { |
| 188 | + const n = s.length |
| 189 | + p.idxs.push(idx) |
| 190 | + for (let i = isTurn ? n - 1 : 0; i >= 0 && i < n; i += isTurn ? -1 : 1) { |
| 191 | + const u = s.charCodeAt(i) - 'a'.charCodeAt(0) |
| 192 | + if (p.tns[u] == null) p.tns[u] = new TrieNode() |
| 193 | + p = p.tns[u] |
| 194 | + p.idxs.push(idx) |
| 195 | + } |
| 196 | + } |
| 197 | + query(a: string, b: string): number { |
| 198 | + let n = a.length, m = b.length |
| 199 | + let p = this.tr1 |
| 200 | + for (let i = 0; i < n; i++) { |
| 201 | + const u = a.charCodeAt(i) - 'a'.charCodeAt(0) |
| 202 | + if (p.tns[u] == null) return -1 |
| 203 | + p = p.tns[u] |
| 204 | + } |
| 205 | + const l1 = p.idxs |
| 206 | + p = this.tr2 |
| 207 | + for (let i = m - 1; i >= 0; i--) { |
| 208 | + const u = b.charCodeAt(i) - 'a'.charCodeAt(0) |
| 209 | + if (p.tns[u] == null) return -1 |
| 210 | + p = p.tns[u] |
| 211 | + } |
| 212 | + const l2 = p.idxs |
| 213 | + n = l1.length; m = l2.length |
| 214 | + for (let i = n - 1, j = m - 1; i >= 0 && j >= 0; ) { |
| 215 | + if (l1[i] < l2[j]) j-- |
| 216 | + else if (l1[i] > l2[j]) i-- |
| 217 | + else return l1[i] |
| 218 | + } |
| 219 | + return -1 |
| 220 | + } |
| 221 | + tr1: TrieNode = new TrieNode() |
| 222 | + tr2: TrieNode = new TrieNode() |
| 223 | + constructor(ss: string[]) { |
| 224 | + for (let i = 0; i < ss.length; i++) { |
| 225 | + this.add(this.tr1, ss[i], i, false) |
| 226 | + this.add(this.tr2, ss[i], i, true) |
| 227 | + } |
| 228 | + } |
| 229 | + f(a: string, b: string): number { |
| 230 | + return this.query(a, b) |
| 231 | + } |
| 232 | +} |
| 233 | +``` |
| 234 | +C++ 代码: |
| 235 | +```C++ |
| 236 | +class WordFilter { |
| 237 | +public: |
| 238 | + struct TrieNode { |
| 239 | + TrieNode* tns[26] {nullptr}; |
| 240 | + vector<int> idxs; |
| 241 | + }; |
| 242 | + |
| 243 | + void add(TrieNode* p, const string& s, int idx, bool isTurn) { |
| 244 | + int n = s.size(); |
| 245 | + p->idxs.push_back(idx); |
| 246 | + for(int i = isTurn ? n - 1 : 0; i >= 0 && i < n; i += isTurn ? -1 : 1) { |
| 247 | + int u = s[i] - 'a'; |
| 248 | + if(p->tns[u] == nullptr) p->tns[u] = new TrieNode(); |
| 249 | + p = p->tns[u]; |
| 250 | + p->idxs.push_back(idx); |
| 251 | + } |
| 252 | + } |
| 253 | + |
| 254 | + int query(const string& a, const string& b) { |
| 255 | + int n = a.size(), m = b.size(); |
| 256 | + auto p = tr1; |
| 257 | + for(int i = 0; i < n; i++) { |
| 258 | + int u = a[i] - 'a'; |
| 259 | + if(p->tns[u] == nullptr) return -1; |
| 260 | + p = p->tns[u]; |
| 261 | + } |
| 262 | + vector<int>& l1 = p->idxs; |
| 263 | + p = tr2; |
| 264 | + for(int i = m - 1; i >= 0; i--) { |
| 265 | + int u = b[i] - 'a'; |
| 266 | + if(p->tns[u] == nullptr) return -1; |
| 267 | + p = p->tns[u]; |
| 268 | + } |
| 269 | + vector<int>& l2 = p->idxs; |
| 270 | + n = l1.size(), m = l2.size(); |
| 271 | + for(int i = n - 1, j = m - 1; i >= 0 && j >= 0; ) { |
| 272 | + if(l1[i] > l2[j]) i--; |
| 273 | + else if(l1[i] < l2[j]) j--; |
| 274 | + else return l1[i]; |
| 275 | + } |
| 276 | + return -1; |
| 277 | + } |
| 278 | + |
| 279 | + TrieNode* tr1 = new TrieNode, *tr2 = new TrieNode; |
| 280 | + WordFilter(vector<string>& ss) { |
| 281 | + int n = ss.size(); |
| 282 | + for(int i = 0; i < n; i++) { |
| 283 | + add(tr1, ss[i], i, false); |
| 284 | + add(tr2, ss[i], i, true); |
| 285 | + } |
| 286 | + } |
| 287 | + |
| 288 | + int f(string a, string b) { |
| 289 | + return query(a, b); |
| 290 | + } |
| 291 | +}; |
| 292 | +``` |
| 293 | +* 时间复杂度:初始化操作复杂度为 $O(\sum_{i = 0}^{n - 1} ss[i].length),ドル检索过程复杂度为 $O(a + b + n),ドル其中 $a = b = 7$ 为前后缀的最大长度,$n = 1e4$ 为初始化数组长度,代表最多有 $n$ 个候选下标(注意:这里的 $n$ 只是粗略分析,实际上如果候选集长度越大的话,说明两个候选集是重合度是越高的,从后往前找的过程是越快结束的,可以通过方程算出一个双指针的理论最大比较次数 $k,ドル如果要将 $n$ 卡满成 1ドルe4$ 的话,需要将两个候选集设计成交替下标,此时 `f` 如果仍是 1ドルe4$ 次调用的话,必然会面临大量的重复查询,可通过引入 `map` 记录查询次数来进行优化) |
| 294 | +* 空间复杂度:$O(\sum_{i = 0}^{n - 1} ss[i].length)$ |
| 295 | + |
| 296 | +--- |
| 297 | + |
| 298 | +### 最后 |
| 299 | + |
| 300 | +这是我们「刷穿 LeetCode」系列文章的第 `No.745` 篇,系列开始于 2021年01月01日,截止于起始日 LeetCode 上共有 1916 道题目,部分是有锁题,我们将先把所有不带锁的题目刷完。 |
| 301 | + |
| 302 | +在这个系列文章里面,除了讲解解题思路以外,还会尽可能给出最为简洁的代码。如果涉及通解还会相应的代码模板。 |
| 303 | + |
| 304 | +为了方便各位同学能够电脑上进行调试和提交代码,我建立了相关的仓库:https://github.com/SharingSource/LogicStack-LeetCode 。 |
| 305 | + |
| 306 | +在仓库地址里,你可以看到系列文章的题解链接、系列文章的相应代码、LeetCode 原题链接和其他优选题解。 |
| 307 | + |
0 commit comments