|
| 1 | +### 题目描述 |
| 2 | + |
| 3 | +这是 LeetCode 上的 **[127. 单词接龙](https://leetcode-cn.com/problems/word-ladder/solution/gong-shui-san-xie-ru-he-shi-yong-shuang-magjd/)** ,难度为 **困难**。 |
| 4 | + |
| 5 | +Tag : 「双向 BFS」 |
| 6 | + |
| 7 | + |
| 8 | + |
| 9 | +字典 wordList 中从单词 beginWord 和 endWord 的 转换序列 是一个按下述规格形成的序列: |
| 10 | + |
| 11 | +* 序列中第一个单词是 beginWord 。 |
| 12 | +* 序列中最后一个单词是 endWord 。 |
| 13 | +* 每次转换只能改变一个字母。 |
| 14 | +* 转换过程中的中间单词必须是字典 wordList 中的单词。 |
| 15 | + |
| 16 | +给你两个单词 beginWord 和 endWord 和一个字典 wordList ,找到从 beginWord 到 endWord 的 最短转换序列 中的 单词数目 。如果不存在这样的转换序列,返回 0。 |
| 17 | + |
| 18 | + |
| 19 | +示例 1: |
| 20 | +``` |
| 21 | +输入:beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log","cog"] |
| 22 | +输出:5 |
| 23 | +解释:一个最短转换序列是 "hit" -> "hot" -> "dot" -> "dog" -> "cog", 返回它的长度 5。 |
| 24 | +``` |
| 25 | +示例 2: |
| 26 | +``` |
| 27 | +输入:beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log"] |
| 28 | +输出:0 |
| 29 | +解释:endWord "cog" 不在字典中,所以无法进行转换。 |
| 30 | +``` |
| 31 | + |
| 32 | +提示: |
| 33 | +* 1 <= beginWord.length <= 10 |
| 34 | +* endWord.length == beginWord.length |
| 35 | +* 1 <= wordList.length <= 5000 |
| 36 | +* wordList[i].length == beginWord.length |
| 37 | +* beginWord、endWord 和 wordList[i] 由小写英文字母组成 |
| 38 | +* beginWord != endWord |
| 39 | +* wordList 中的所有字符串 互不相同 |
| 40 | + |
| 41 | +--- |
| 42 | + |
| 43 | +### 基本分析 |
| 44 | + |
| 45 | +根据题意,每次只能替换一个字符,且每次产生的新单词必须在 `wordList` 出现过。 |
| 46 | + |
| 47 | +一个朴素的实现方法是,使用 BFS 的方式求解。 |
| 48 | + |
| 49 | +从 `beginWord` 出发,枚举所有替换一个字符的方案,如果方案存在于 `wordList` 中,则加入队列中,这样队列中就存在所有替换次数为 1ドル$ 的单词。然后从队列中取出元素,继续这个过程,直到遇到 `endWord` 或者队列为空为止。 |
| 50 | + |
| 51 | +同时为了「防止重复枚举到某个中间结果」和「记录每个中间结果是经过多少次转换而来」,我们需要建立一个「哈希表」进行记录。 |
| 52 | + |
| 53 | +哈希表的 KV 形式为 `{ 单词 : 由多少次转换得到 }`。 |
| 54 | + |
| 55 | +当枚举到新单词 `str` 时,需要先检查是否已经存在与「哈希表」中,如果不存在则更新「哈希表」并将新单词放入队列中。 |
| 56 | + |
| 57 | +**这样的做法可以确保「枚举到所有由 `beginWord` 到 `endWord` 的转换路径」,并且由 `beginWord` 到 `endWord` 的「最短转换路径」必然会最先被枚举到。** |
| 58 | + |
| 59 | +--- |
| 60 | + |
| 61 | +### 双向 BFS |
| 62 | + |
| 63 | +经过分析,BFS 确实可以做,但本题的数据范围较大:`1 <= beginWord.length <= 10` |
| 64 | + |
| 65 | +朴素的 BFS 可能会带来「搜索空间爆炸」的情况。 |
| 66 | + |
| 67 | +想象一下,如果我们的 `wordList` 足够丰富(包含了所有单词),对于一个长度为 10ドル$ 的 `beginWord` 替换一次字符可以产生 10ドル * 25$ 个新单词(每个替换点可以替换另外 25ドル$ 个小写字母),第一层就会产生 250ドル$ 个单词;第二层会产生超过 6ドル * 10^4$ 个新单词 ... |
| 68 | + |
| 69 | +**随着层数的加深,这个数字的增速越快,这就是「搜索空间爆炸」问题。** |
| 70 | + |
| 71 | +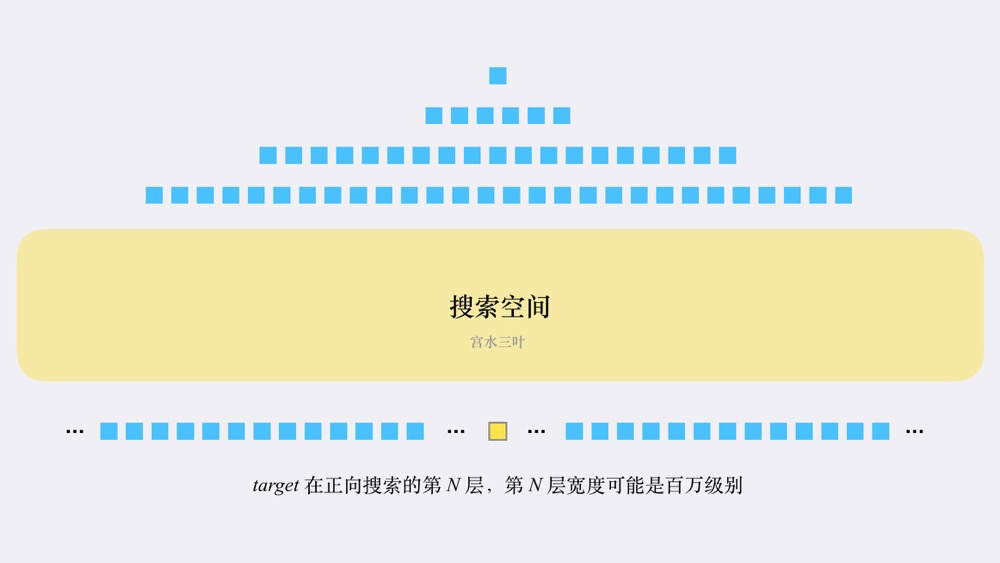 |
| 72 | + |
| 73 | +**在朴素的 BFS 实现中,空间的瓶颈主要取决于搜索空间中的最大宽度。** |
| 74 | + |
| 75 | +那么有没有办法让我们不使用这么宽的搜索空间,同时又能保证搜索到目标结果呢? |
| 76 | + |
| 77 | +「双向 BFS」 可以很好的解决这个问题: |
| 78 | + |
| 79 | +**同时从两个方向开始搜索,一旦搜索到相同的值,意味着找到了一条联通起点和终点的最短路径。** |
| 80 | + |
| 81 | +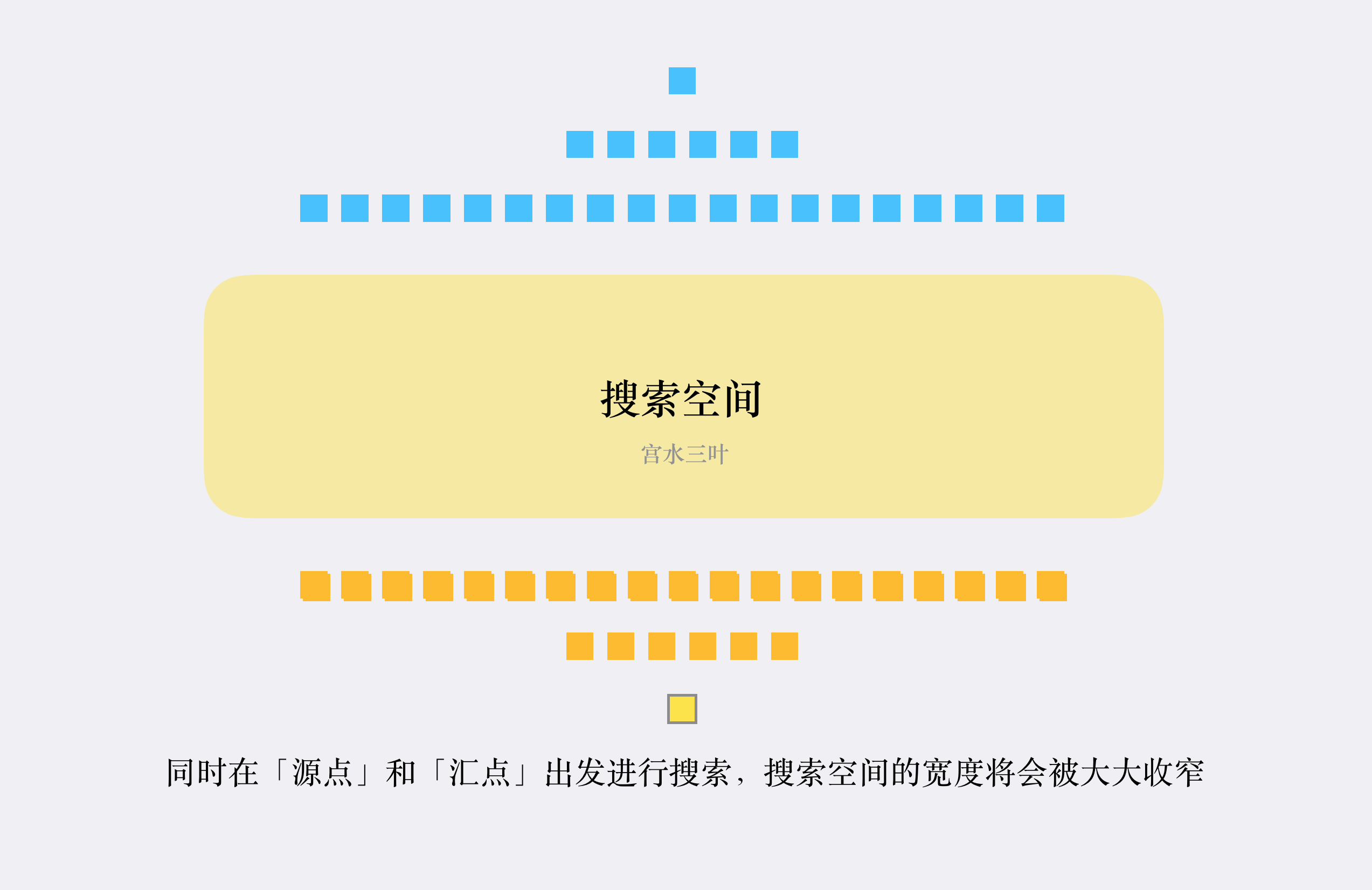 |
| 82 | + |
| 83 | +「双向 BFS」的基本实现思路如下: |
| 84 | + |
| 85 | +1. 创建「两个队列」分别用于两个方向的搜索; |
| 86 | +2. 创建「两个哈希表」用于「解决相同节点重复搜索」和「记录转换次数」; |
| 87 | +3. 为了尽可能让两个搜索方向"平均",每次从队列中取值进行扩展时,先判断哪个队列容量较少; |
| 88 | +4. 如果在搜索过程中「搜索到对方搜索过的节点」,说明找到了最短路径。 |
| 89 | + |
| 90 | +「双向 BFS」基本思路对应的伪代码大致如下: |
| 91 | + |
| 92 | +```Java [] |
| 93 | +d1、d2 为两个方向的队列 |
| 94 | +m1、m2 为两个方向的哈希表,记录每个节点距离起点的 |
| 95 | + |
| 96 | +// 只有两个队列都不空,才有必要继续往下搜索 |
| 97 | +// 如果其中一个队列空了,说明从某个方向搜到底都搜不到该方向的目标节点 |
| 98 | +while(!d1.isEmpty() && !d2.isEmpty()) { |
| 99 | + if (d1.size() < d2.size()) { |
| 100 | + update(d1, m1, m2); |
| 101 | + } else { |
| 102 | + update(d2, m2, m1); |
| 103 | + } |
| 104 | +} |
| 105 | + |
| 106 | +// update 为从队列 d 中取出一个元素进行「一次完整扩展」的逻辑 |
| 107 | +void update(Deque d, Map cur, Map other) {} |
| 108 | +``` |
| 109 | + |
| 110 | +回到本题,我们看看如何使用「双向 BFS」进行求解。 |
| 111 | + |
| 112 | +估计不少同学是第一次接触「双向 BFS」,因此这次我写了大量注释。 |
| 113 | + |
| 114 | +建议大家带着对「双向 BFS」的基本理解去阅读。 |
| 115 | + |
| 116 | +代码: |
| 117 | + |
| 118 | +```Java [] |
| 119 | +class Solution { |
| 120 | + String s, e; |
| 121 | + Set<String> set = new HashSet<>(); |
| 122 | + public int ladderLength(String _s, String _e, List<String> ws) { |
| 123 | + s = _s; |
| 124 | + e = _e; |
| 125 | + // 将所有 word 存入 set,如果目标单词不在 set 中,说明无解 |
| 126 | + for (String w : ws) set.add(w); |
| 127 | + if (!set.contains(e)) return 0; |
| 128 | + int ans = bfs(); |
| 129 | + return ans == -1 ? 0 : ans + 1; |
| 130 | + } |
| 131 | + |
| 132 | + int bfs() { |
| 133 | + // d1 代表从起点 beginWord 开始搜索(正向) |
| 134 | + // d2 代表从结尾 endWord 开始搜索(反向) |
| 135 | + Deque<String> d1 = new ArrayDeque<>(), d2 = new ArrayDeque(); |
| 136 | + |
| 137 | + /* |
| 138 | + * m1 和 m2 分别记录两个方向出现的单词是经过多少次转换而来 |
| 139 | + * e.g. |
| 140 | + * m1 = {"abc":1} 代表 abc 由 beginWord 替换 1 次字符而来 |
| 141 | + * m1 = {"xyz":3} 代表 xyz 由 endWord 替换 3 次字符而来 |
| 142 | + */ |
| 143 | + Map<String, Integer> m1 = new HashMap<>(), m2 = new HashMap<>(); |
| 144 | + d1.add(s); |
| 145 | + m1.put(s, 0); |
| 146 | + d2.add(e); |
| 147 | + m2.put(e, 0); |
| 148 | + |
| 149 | + /* |
| 150 | + * 只有两个队列都不空,才有必要继续往下搜索 |
| 151 | + * 如果其中一个队列空了,说明从某个方向搜到底都搜不到该方向的目标节点 |
| 152 | + * e.g. |
| 153 | + * 例如,如果 d1 为空了,说明从 beginWord 搜索到底都搜索不到 endWord,反向搜索也没必要进行了 |
| 154 | + */ |
| 155 | + while (!d1.isEmpty() && !d2.isEmpty()) { |
| 156 | + int t = -1; |
| 157 | + // 为了让两个方向的搜索尽可能平均,优先拓展队列内元素少的方向 |
| 158 | + if (d1.size() <= d2.size()) { |
| 159 | + t = update(d1, m1, m2); |
| 160 | + } else { |
| 161 | + t = update(d2, m2, m1); |
| 162 | + } |
| 163 | + if (t != -1) return t; |
| 164 | + } |
| 165 | + return -1; |
| 166 | + } |
| 167 | + |
| 168 | + // update 代表从 deque 中取出一个单词进行扩展, |
| 169 | + // cur 为当前方向的距离字典;other 为另外一个方向的距离字典 |
| 170 | + int update(Deque<String> deque, Map<String, Integer> cur, Map<String, Integer> other) { |
| 171 | + // 获取当前需要扩展的原字符串 |
| 172 | + String poll = deque.pollFirst(); |
| 173 | + int n = poll.length(); |
| 174 | + |
| 175 | + // 枚举替换原字符串的哪个字符 i |
| 176 | + for (int i = 0; i < n; i++) { |
| 177 | + // 枚举将 i 替换成哪个小写字母 |
| 178 | + for (int j = 0; j < 26; j++) { |
| 179 | + // 替换后的字符串 |
| 180 | + String sub = poll.substring(0, i) + String.valueOf((char)('a' + j)) + poll.substring(i + 1); |
| 181 | + if (set.contains(sub)) { |
| 182 | + // 如果该字符串在「当前方向」被记录过(拓展过),跳过即可 |
| 183 | + if (cur.containsKey(sub)) continue; |
| 184 | + |
| 185 | + // 如果该字符串在「另一方向」出现过,说明找到了联通两个方向的最短路 |
| 186 | + if (other.containsKey(sub)) { |
| 187 | + return cur.get(poll) + 1 + other.get(sub); |
| 188 | + } else { |
| 189 | + // 否则加入 deque 队列 |
| 190 | + deque.addLast(sub); |
| 191 | + cur.put(sub, cur.get(poll) + 1); |
| 192 | + } |
| 193 | + } |
| 194 | + } |
| 195 | + } |
| 196 | + return -1; |
| 197 | + } |
| 198 | +} |
| 199 | +``` |
| 200 | +* 时间复杂度:令 `wordList` 长度为 $n,ドル`beginWord` 字符串长度为 $m$。由于所有的搜索结果必须都在 `wordList` 出现过,因此算上起点最多有 $n + 1$ 节点,最坏情况下,所有节点都联通,搜索完整张图复杂度为 $O(n^2)$ ;从 `beginWord` 出发进行字符替换,替换时进行逐字符检查,复杂度为 $O(m)$。整体复杂度为 $O(m * n^2)$ |
| 201 | +* 空间复杂度:同等空间大小。$O(m * n^2)$ |
| 202 | + |
| 203 | +--- |
| 204 | + |
| 205 | +### 总结 |
| 206 | + |
| 207 | +**这本质其实是一个「所有边权均为 `1`」最短路问题:将 `beginWord` 和所有在 `wordList` 出现过的字符串看做是一个点。每一次转换操作看作产生边权为 `1` 的边。问题求以 `beginWord` 为源点,以 `endWord` 为汇点的最短路径。** |
| 208 | + |
| 209 | +借助这个题,我向你介绍了「双向 BFS」,「双向 BFS」可以有效解决「搜索空间爆炸」问题。 |
| 210 | + |
| 211 | +**对于那些搜索节点随着层数增加呈倍数或指数增长的搜索问题,可以使用「双向 BFS」进行求解。** |
| 212 | + |
| 213 | +--- |
| 214 | + |
| 215 | +### 最后 |
| 216 | + |
| 217 | +这是我们「刷穿 LeetCode」系列文章的第 `No.127` 篇,系列开始于 2021年01月01日,截止于起始日 LeetCode 上共有 1916 道题目,部分是有锁题,我们将先将所有不带锁的题目刷完。 |
| 218 | + |
| 219 | +在这个系列文章里面,除了讲解解题思路以外,还会尽可能给出最为简洁的代码。如果涉及通解还会相应的代码模板。 |
| 220 | + |
| 221 | +为了方便各位同学能够电脑上进行调试和提交代码,我建立了相关的仓库:https://github.com/SharingSource/LogicStack-LeetCode 。 |
| 222 | + |
| 223 | +在仓库地址里,你可以看到系列文章的题解链接、系列文章的相应代码、LeetCode 原题链接和其他优选题解。 |
0 commit comments