Fizz Buzz is a common challenge given during interviews. The challenge goes something like this:
Write a program that prints the numbers from 1 to n. If a number is divisible by 3, write Fizz instead. If a number is divisible by 5, write Buzz instead. However, if the number is divisible by both 3 and 5, write FizzBuzz instead.
The goal of this question is to write a FizzBuzz implementation that goes from 1 to infinity (or some arbitrary very very large number), and that implementation should do it as fast as possible.
Checking throughput
Write your fizz buzz program. Run it. Pipe the output through <your_program> | pv > /dev/null. The higher the throughput, the better you did.
Example
A naive implementation written in C gets you about 170MiB/s on an average machine:
#include <stdio.h>
int main() {
for (int i = 1; i < 1000000000; i++) {
if ((i % 3 == 0) && (i % 5 == 0)) {
printf("FizzBuzz\n");
} else if (i % 3 == 0) {
printf("Fizz\n");
} else if (i % 5 == 0) {
printf("Buzz\n");
} else {
printf("%d\n", i);
}
}
}
There is a lot of room for improvement here. In fact, I've seen an implementation that can get more than 3GiB/s on the same machine.
I want to see what clever ideas the community can come up with to push the throughput to its limits.
Rules
- All languages are allowed.
- The program output must be exactly valid fizzbuzz. No playing tricks such as writing null bytes in between the valid output - null bytes that don't show up in the console but do count towards
pvthroughput.
Here's an example of valid output:
1
2
Fizz
4
Buzz
Fizz
7
8
Fizz
Buzz
11
Fizz
13
14
FizzBuzz
16
17
Fizz
19
Buzz
# ... and so on
Valid output must be simple ASCII, single-byte per character, new lines are a single \n and not \r\n. The numbers and strings must be correct as per the FizzBuzz requirements. The output must go on forever (or a very high astronomical number, at-least 2^58) and not halt / change prematurely.
Parallel implementations are allowed (and encouraged).
Architecture specific optimizations / assembly is also allowed. This is not a real contest - I just want to see how people push fizz buzz to its limit - even if it only works in special circumstances/platforms.
Scores
Scores are from running on my desktop with an AMD 5950x CPU (16C / 32T). I have 64GB of 3200Mhz RAM. CPU mitigations are disabled.
**By far the best score so far is in C++ by @David Frank - generating FizzBuzz at around 1.7 Terrabit/s
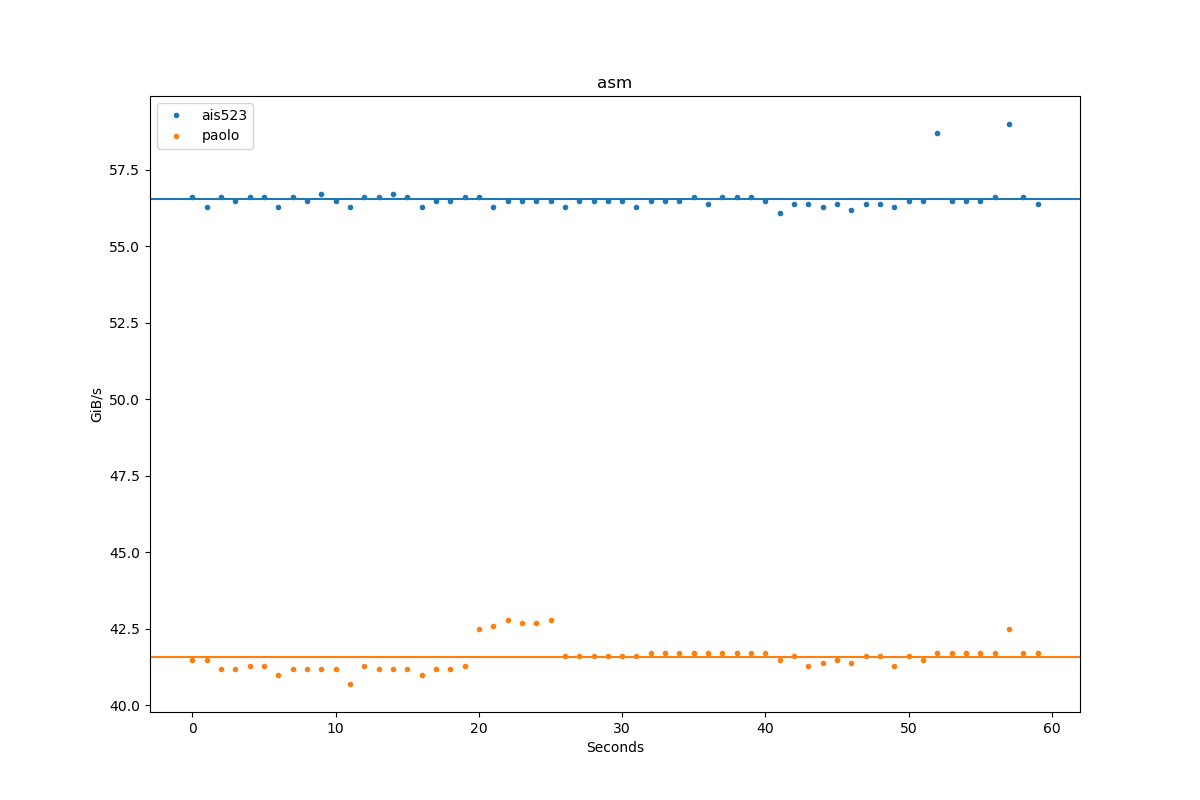
At the second place - @ais523 - generating FizzBuzz at 61GiB/s with x86 assembly.
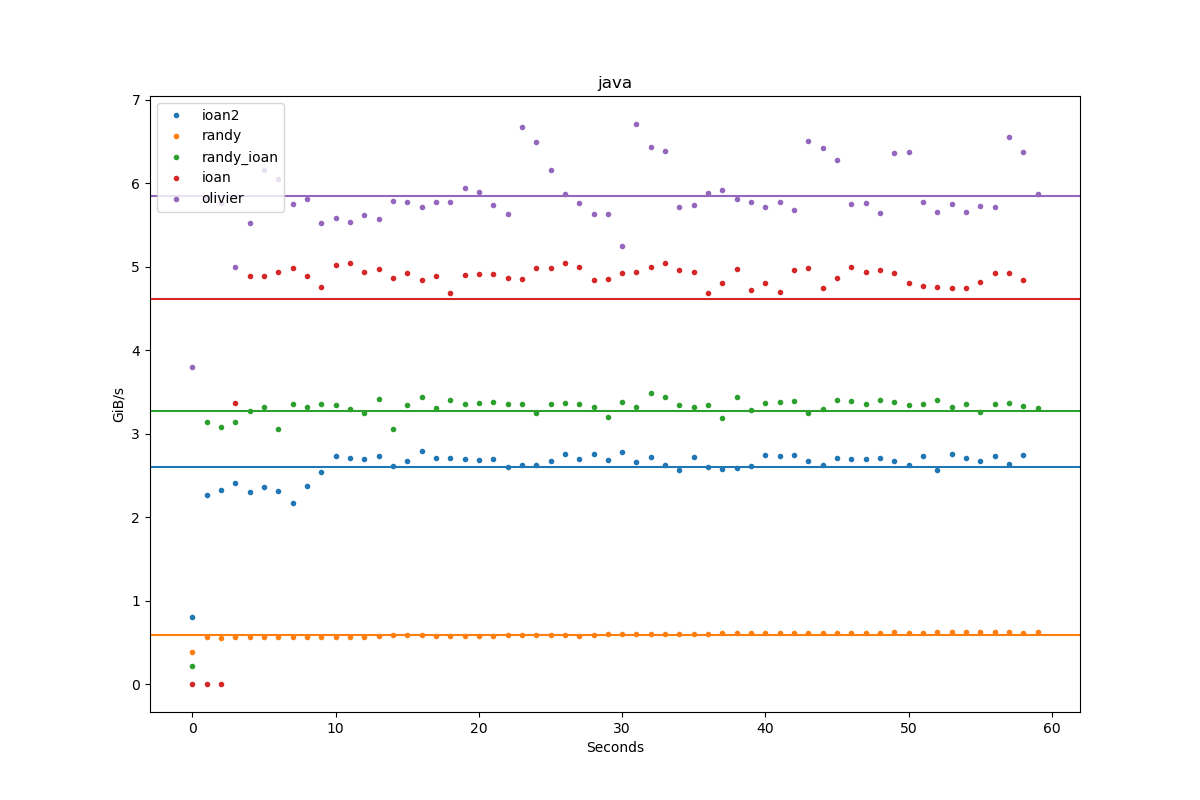
Results for java:
| Author | Throughput |
|---|---|
| ioan2 | 2.6 GiB/s |
| randy | 0.6 GiB/s |
| randy_ioan | 3.3 GiB/s |
| ioan | 4.6 GiB/s |
| olivier | 5.8 GiB/s |
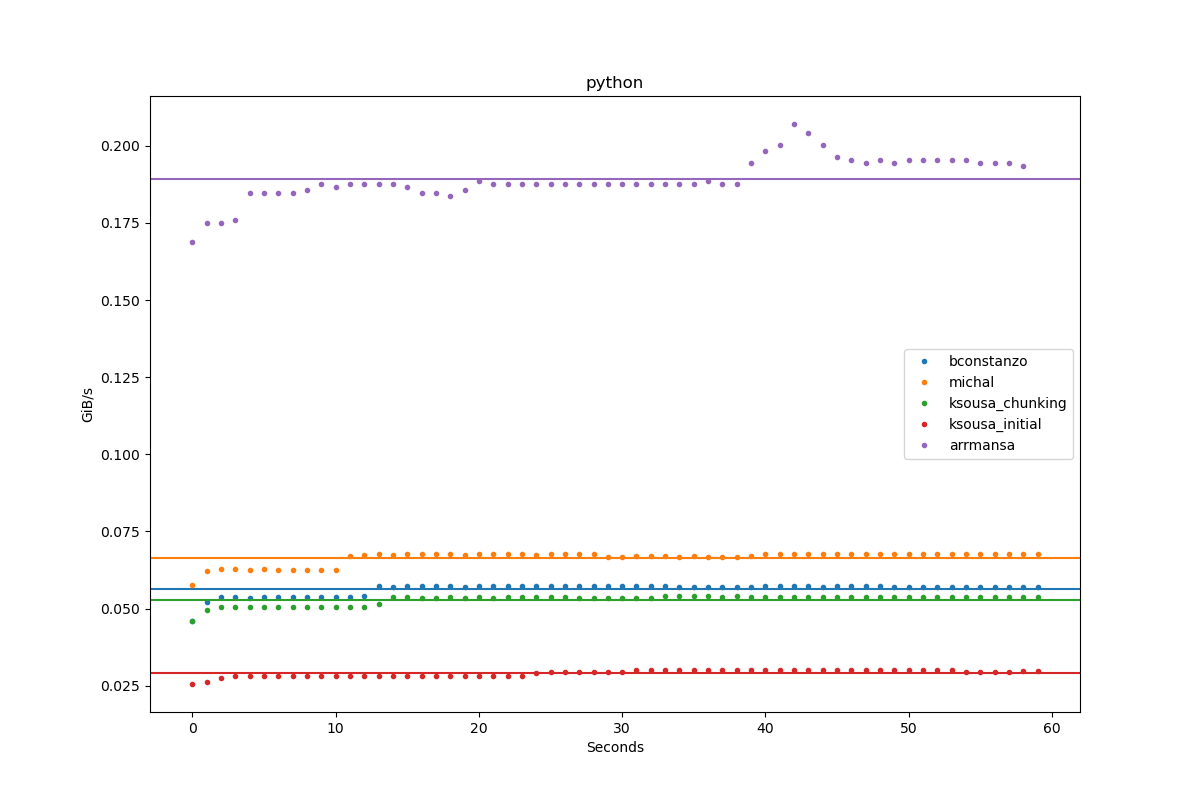
Results for python:
| Author | Throughput |
|---|---|
| bconstanzo | 0.1 GiB/s |
| michal | 0.1 GiB/s |
| ksousa_chunking | 0.1 GiB/s |
| ksousa_initial | 0.0 GiB/s |
| arrmansa | 0.2 GiB/s |
| antoine | 0.5 GiB/s |
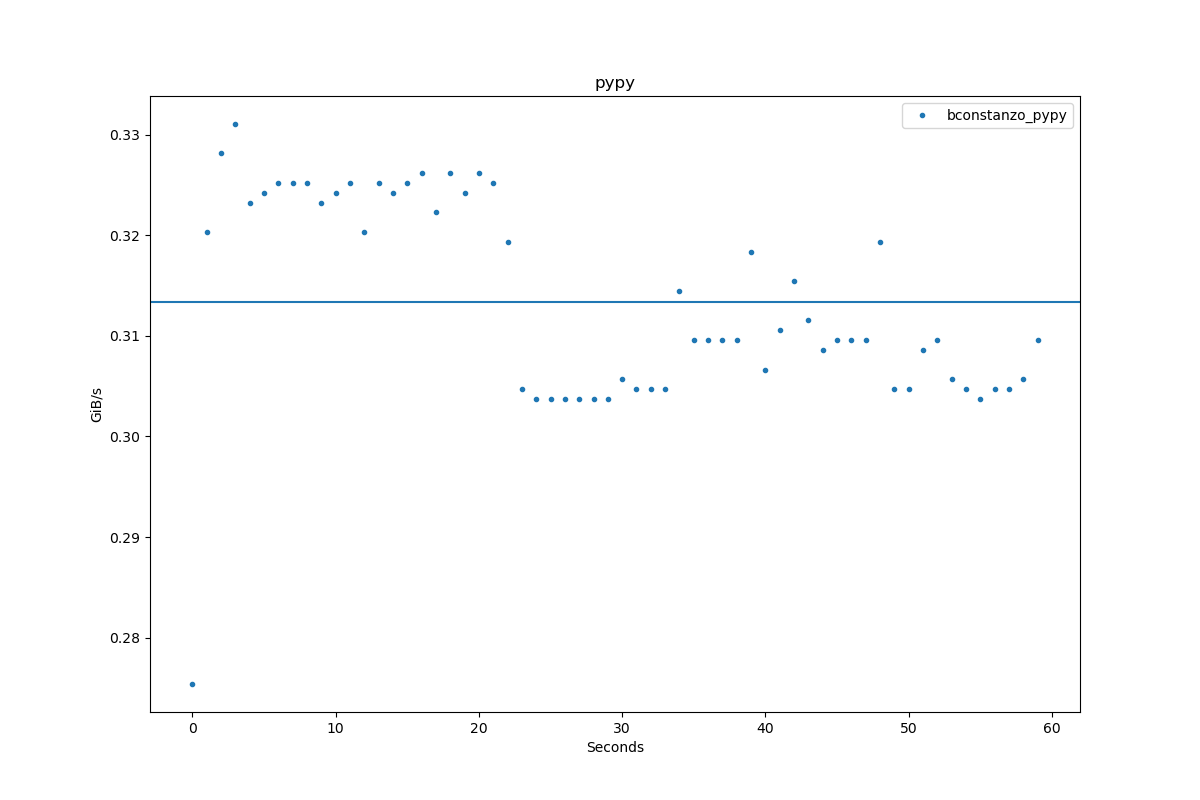
Results for pypy:
| Author | Throughput |
|---|---|
| bconstanzo_pypy | 0.3 GiB/s |
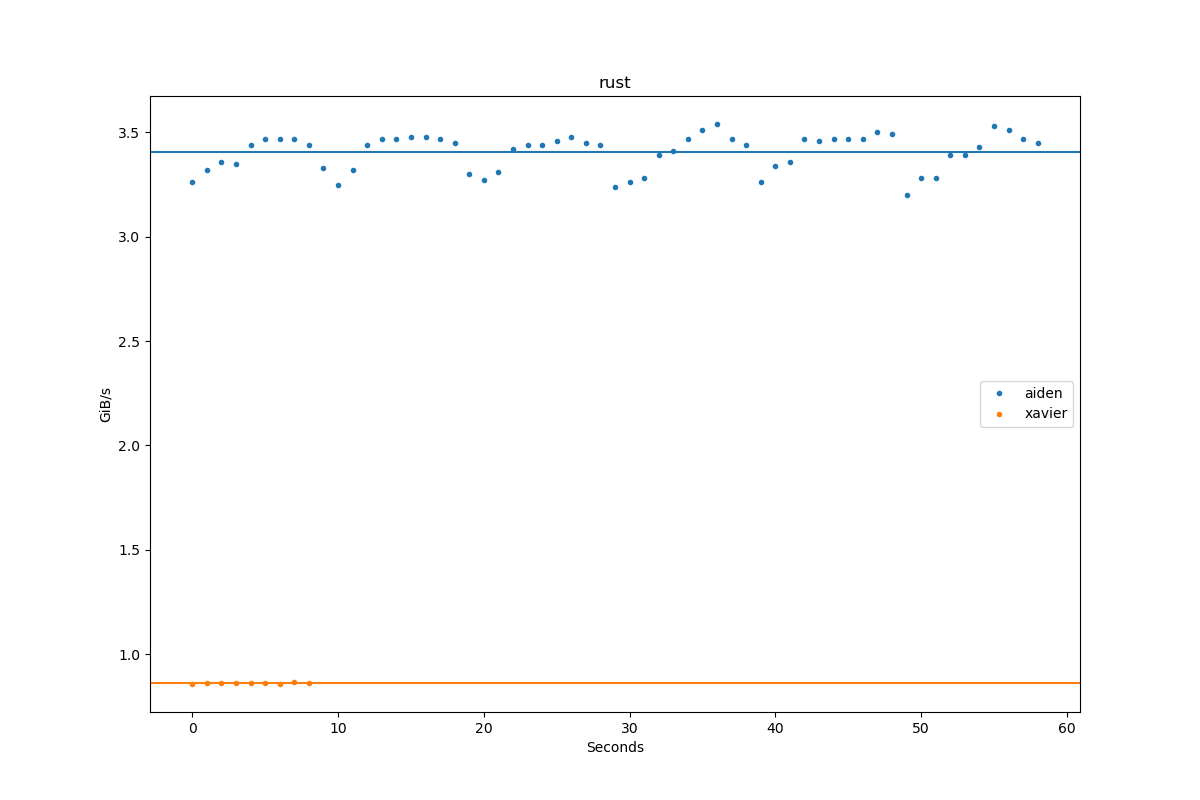
Results for rust:
| Author | Throughput |
|---|---|
| aiden | 3.4 GiB/s |
| xavier | 0.9 GiB/s |
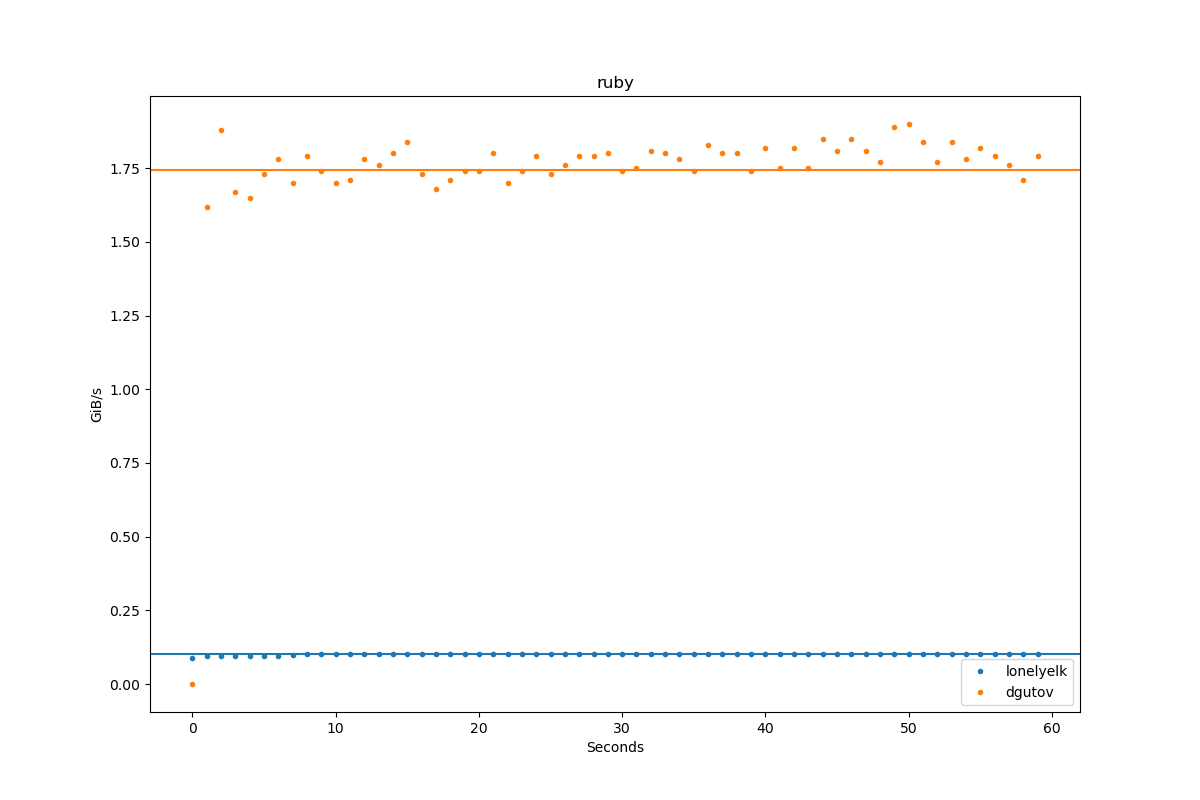
Results for ruby:
| Author | Throughput |
|---|---|
| lonelyelk | 0.1 GiB/s |
| dgutov | 1.7 GiB/s |
Results for asm:
| Author | Throughput |
|---|---|
| ais523 | 60.8 GiB/s |
| paolo | 39.0 GiB/s |
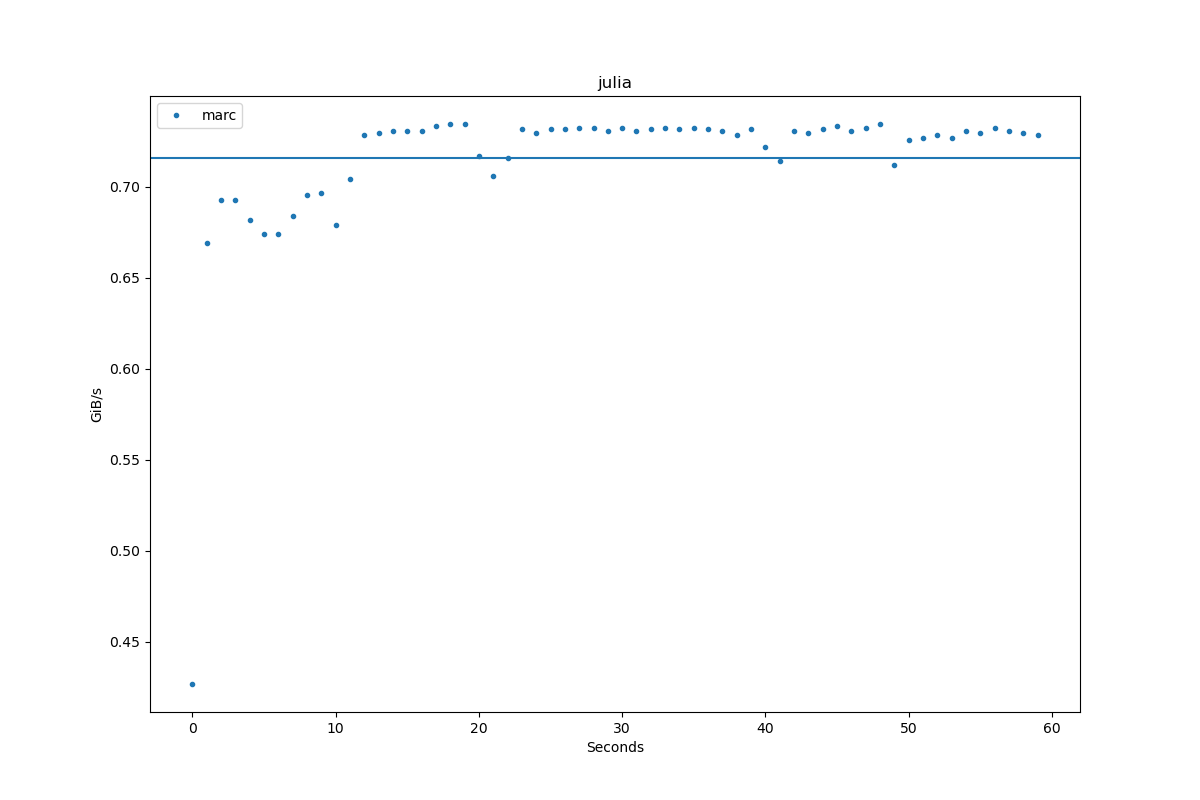
Results for julia:
| Author | Throughput |
|---|---|
| marc | 0.7 GiB/s |
| tkluck | 15.5 GiB/s |
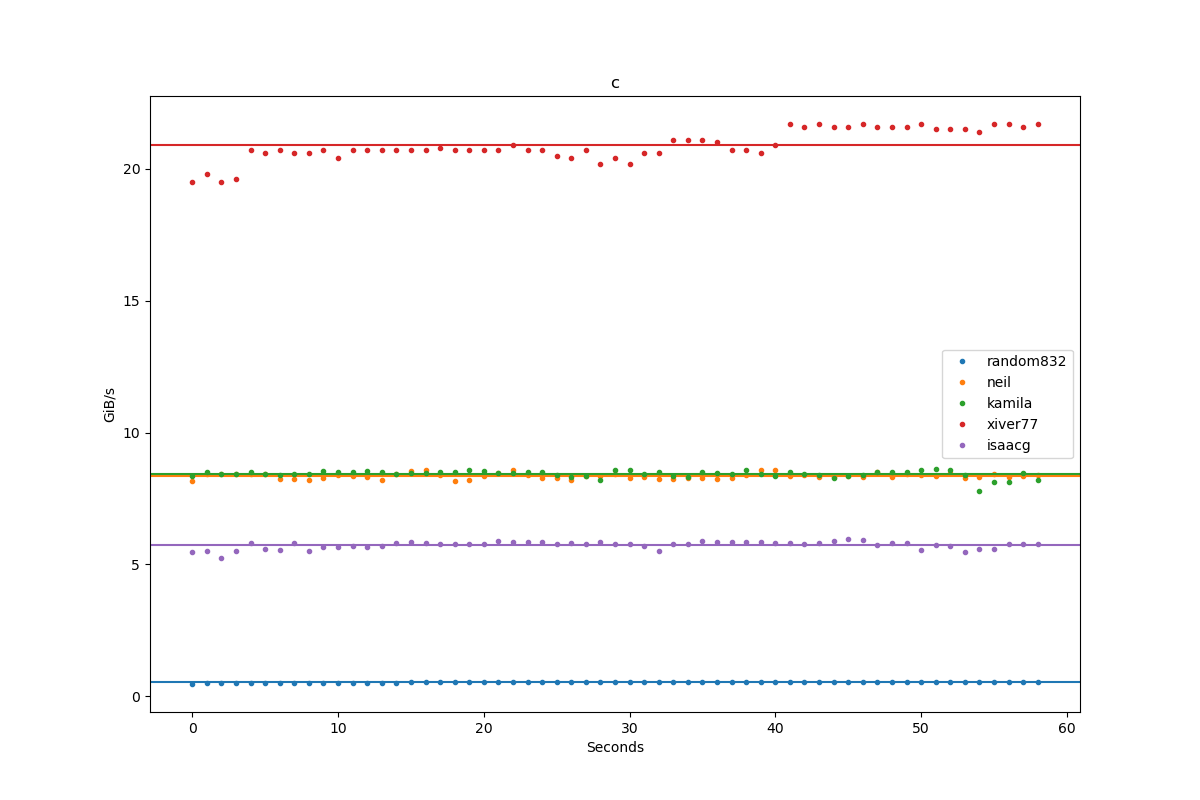
Results for c:
| Author | Throughput |
|---|---|
| random832 | 0.5 GiB/s |
| neil | 8.4 GiB/s |
| kamila | 8.4 GiB/s |
| xiver77 | 20.9 GiB/s |
| isaacg | 5.7 GiB/s |
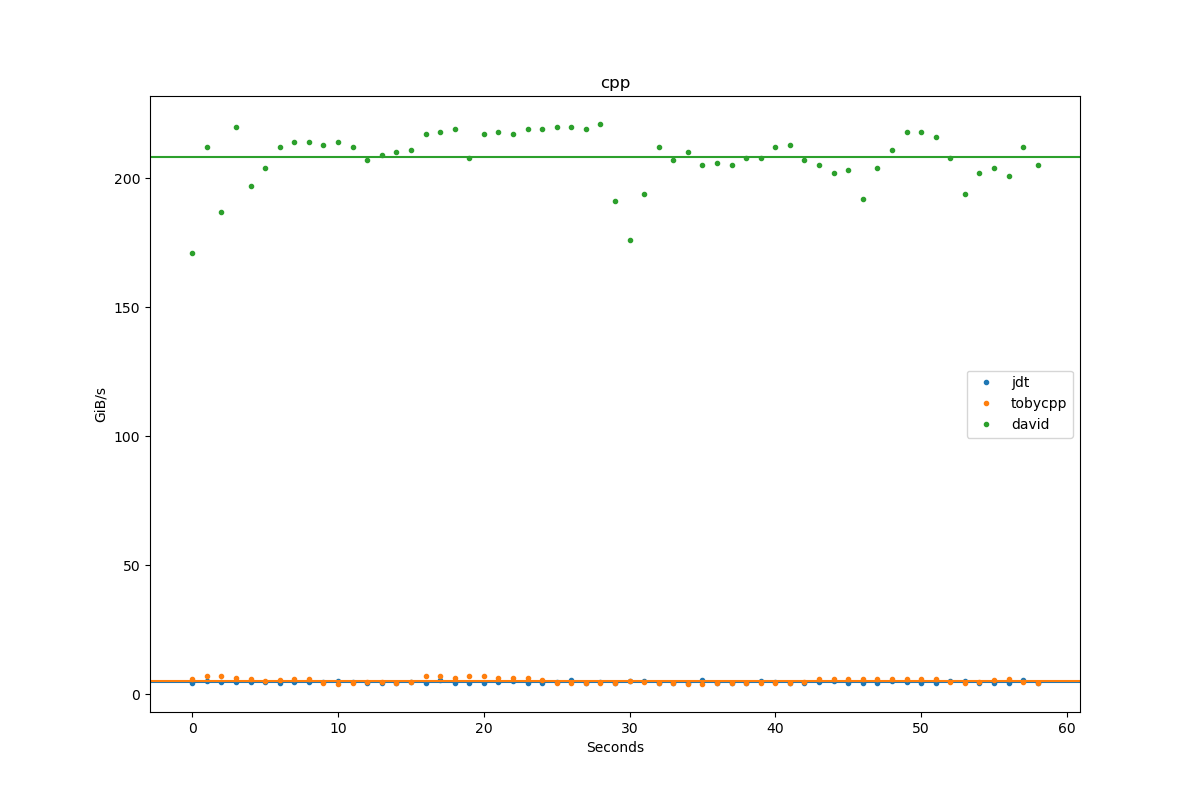
Results for cpp:
| Author | Throughput |
|---|---|
| jdt | 4.8 GiB/s |
| tobycpp | 5.4 GiB/s |
| david | 208.3 GiB/s |
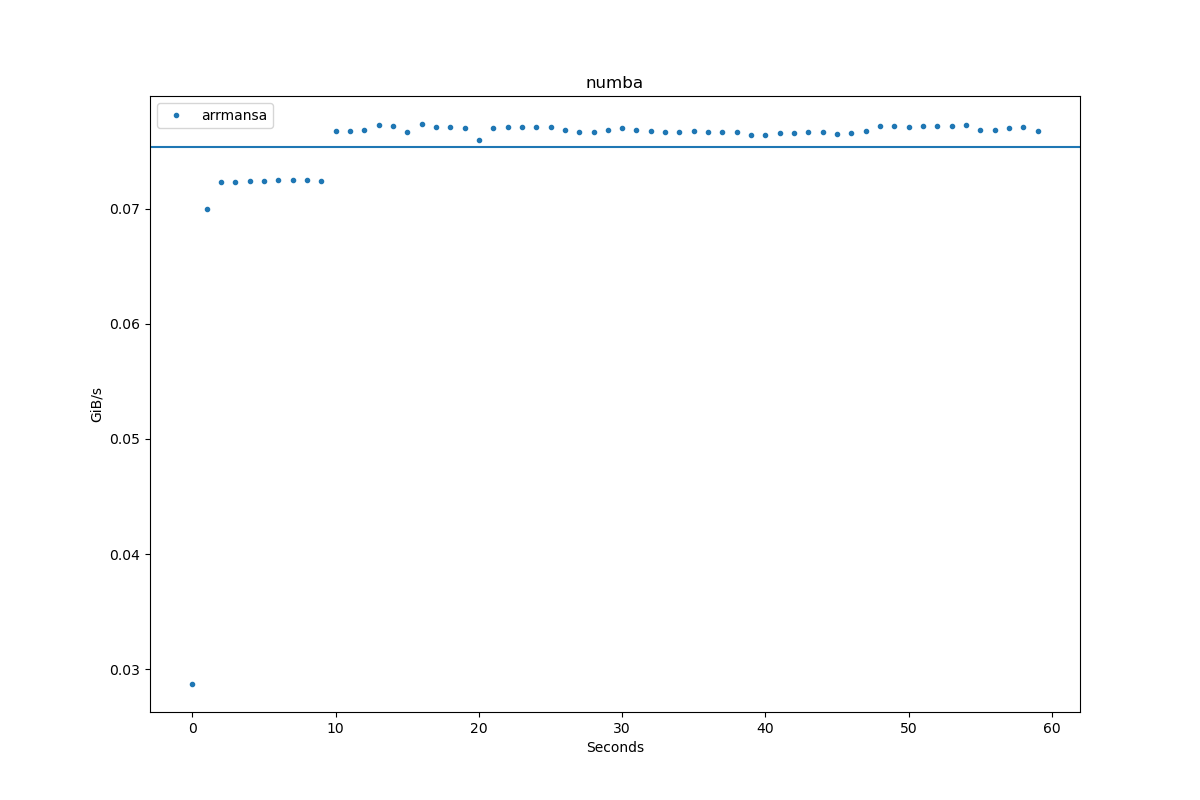
Results for numba:
| Author | Throughput |
|---|---|
| arrmansa | 0.1 GiB/s |
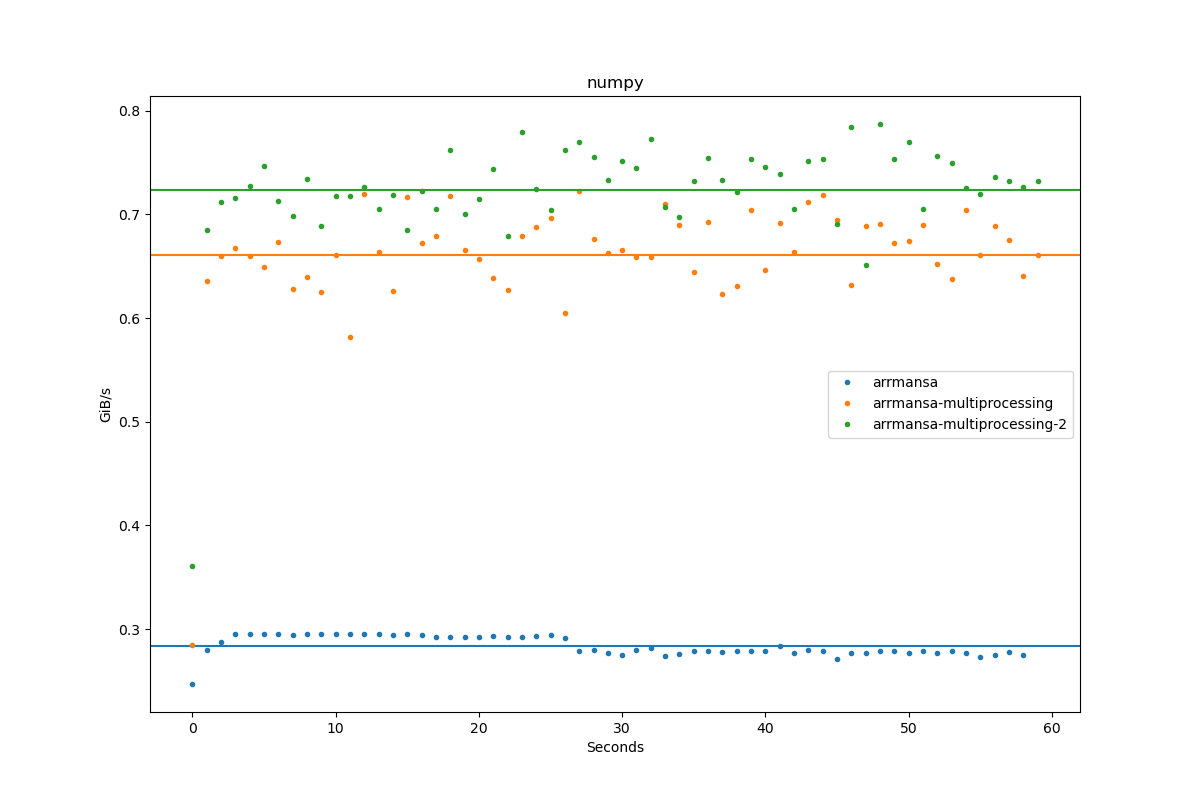
Results for numpy:
| Author | Throughput |
|---|---|
| arrmansa | 0.3 GiB/s |
| arrmansa-multiprocessing | 0.7 GiB/s |
| arrmansa-multiprocessing-2 | 0.7 GiB/s |
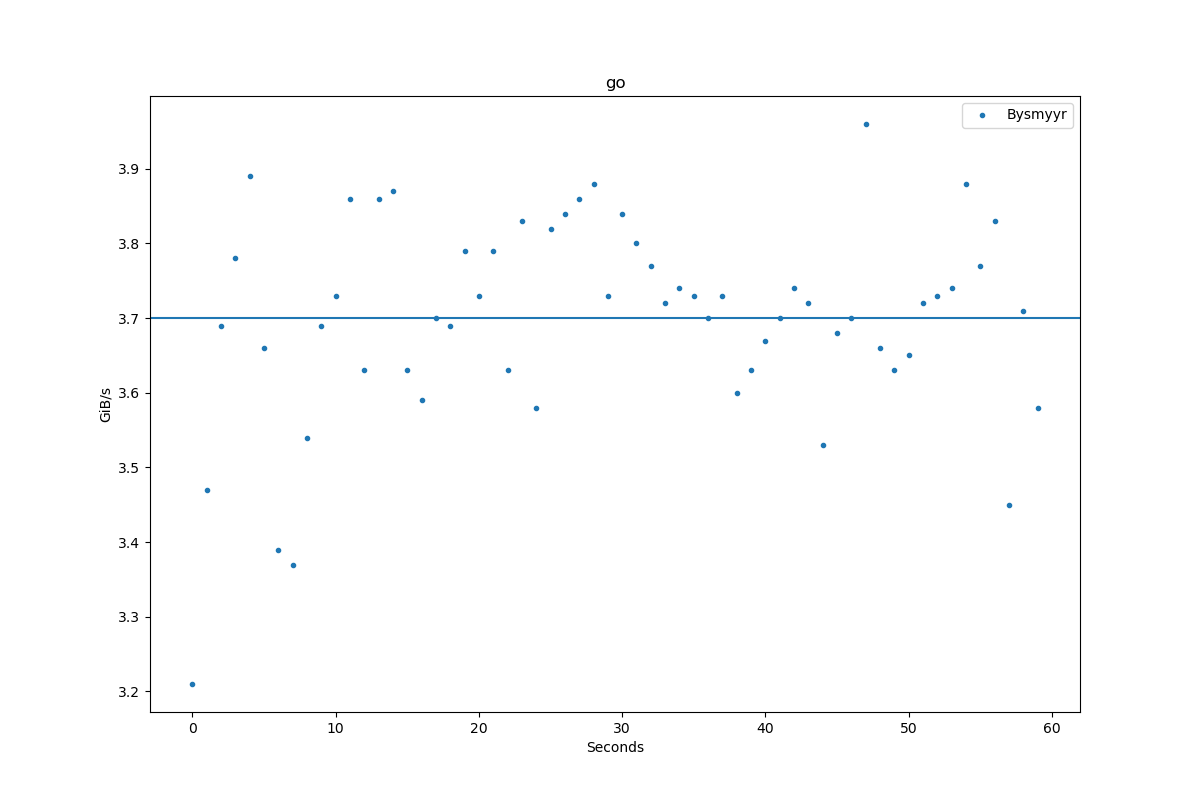
Results for go:
| Author | Throughput |
|---|---|
| Bysmyyr | 3.7 GiB/s |
| psaikko | 6.8 GiB/s |
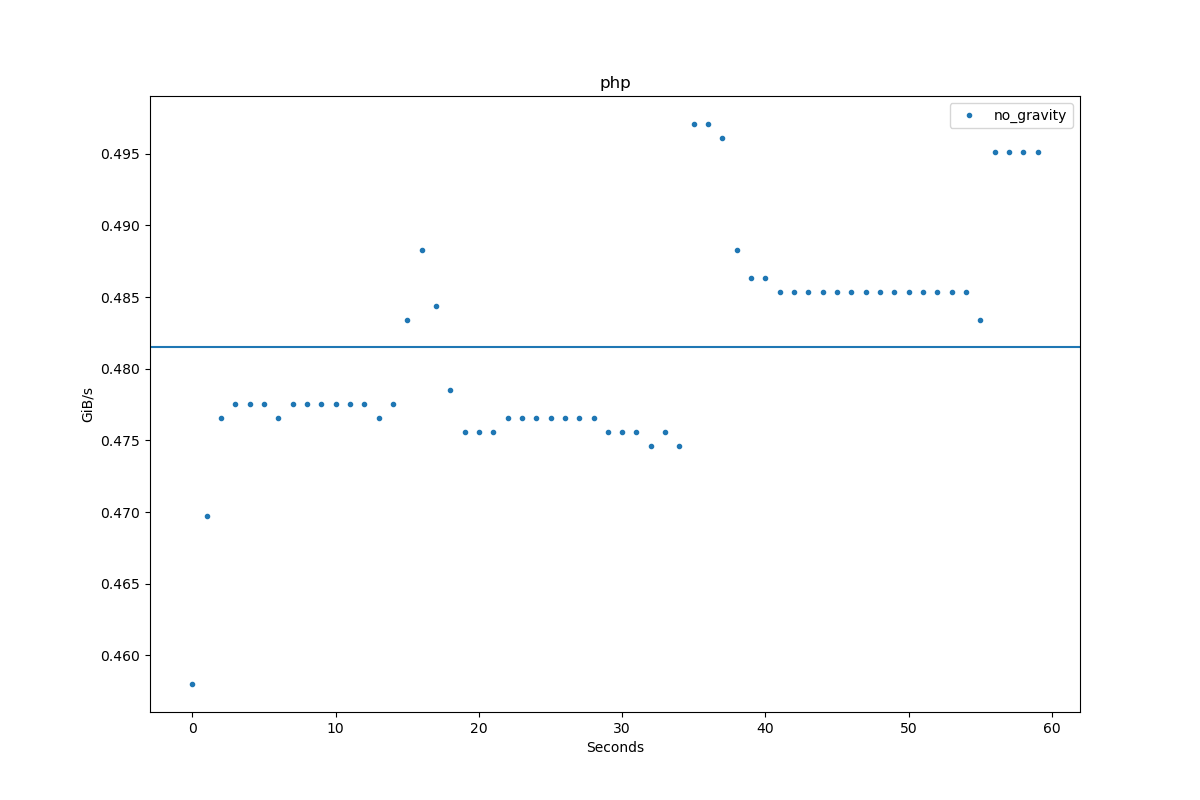
Results for php:
| Author | Throughput |
|---|---|
| no_gravity | 0.5 GiB/s |
Results for elixir:
| Author | Throughput |
|---|---|
| technusm1 | 0.3 GiB/s |
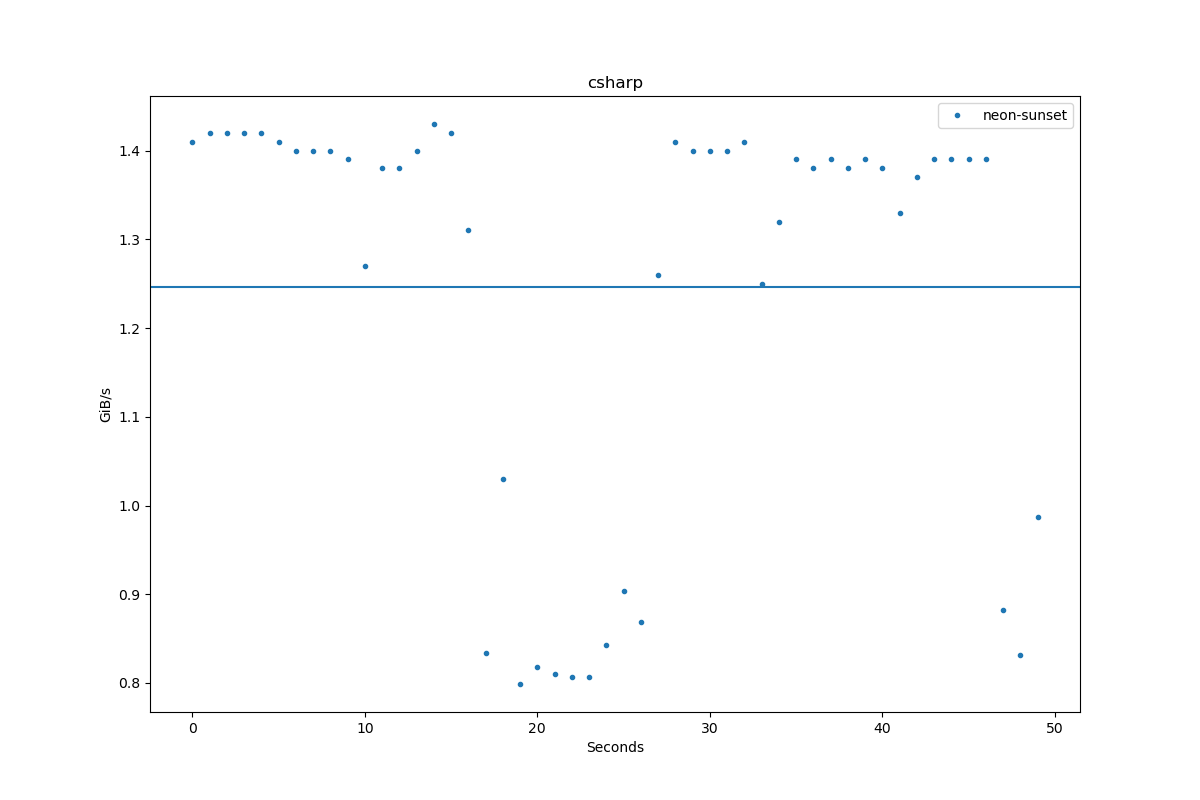
Results for csharp:
| Author | Throughput |
|---|---|
| neon-sunset | 1.2 GiB/s |
asm submissions java submissions pypy submissions python submissions ruby submissions rust submissions c submissions cpp submissions julia submissions numba submissions numpy submissions go submissions php submissions csharp submissions
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Plots generated using https://github.com/omertuc/fizzgolf
43 Answers 43
this is inspired by the previous Rust entry by aiden4 at https://codegolf.stackexchange.com/a/217455/118590
it's a threaded version of aiden4's code, with the macros replaced by inline functions, because i haven't learned macros yet =)
this will utilize all logical CPUs up to MAX_THREADS, and uses one thread to handle synchronization.
build with cargo build --release and run with ./target/release/fizz_buzz_threaded
/.cargo/config.toml (please adjust as necessary):
[target.x86_64-unknown-linux-gnu]
rustflags = ["-Ctarget-cpu=native"]
[target.x86_64-pc-windows-msvc]
rustflags = ["-Ctarget-cpu=native"]
[target.x86_64-pc-windows-gnu]
rustflags = ["-Ctarget-cpu=native"]
main.rs:
use std::io::*;
use std::sync::atomic::{AtomicUsize, Ordering};
use std::thread;
extern crate num_cpus;
const FIZZ: *const u8 = "Fizz\n".as_ptr();
const BUZZ: *const u8 = "Buzz\n".as_ptr();
const FIZZBUZZ: *const u8 = "FizzBuzz\n".as_ptr();
const MAX_NUM: usize = 90_000; // results to cache before writing output
const MAX_THREADS: usize = 256;
const BUF_SIZE: usize = MAX_NUM * 207; // i think max size for one round of fizz buzz ANSI is 206 bytes?
const UATOMIC: AtomicUsize = AtomicUsize::new(0);
static mut BUFS: [[u8; BUF_SIZE]; MAX_THREADS] = [[0u8; BUF_SIZE]; MAX_THREADS];
static mut BUF_COUNTS: [usize; MAX_THREADS] = [0usize; MAX_THREADS];
static mut LOCKS: [AtomicUsize; MAX_THREADS] = [UATOMIC; MAX_THREADS];
unsafe fn sync_threads(threads: usize) {
let mut synced = false;
let mut val: usize;
let mut out = stdout();
loop {
for x in 0..threads {
val = LOCKS[x].load(Ordering::SeqCst);
if val == 1 {
synced = true;
} else {
synced = false;
break;
}
}
if synced {
for x in 0..threads {
let res = out.write_all(BUFS[x].get_unchecked(..BUF_COUNTS[x]));
if res.is_err() {
println!("{:?}", res.err());
}
LOCKS[x].store(0, Ordering::SeqCst);
}
}
}
}
unsafe fn thread(id: usize, mut num: usize, worker_threads: usize) {
// alas, i haven't learned macros yet
unsafe fn itoap_write(id: usize, buf_count: &mut usize, num: usize) {
*buf_count +=
itoap::write_to_ptr(BUFS[id].get_unchecked_mut(*buf_count..).as_mut_ptr(), num);
BUFS[id].as_mut_ptr().add(*buf_count).write(b'\n');
*buf_count += 1;
}
unsafe fn str_write(id: usize, buf_count: &mut usize, string: *const u8, len: usize) {
let ptr = BUFS[id].get_unchecked_mut(*buf_count..).as_mut_ptr();
ptr.copy_from_nonoverlapping(string, len);
*buf_count += len;
}
let mut val: usize;
let mut count: usize = 0;
num += 1;
let number_skip = (worker_threads - 1) * MAX_NUM;
loop {
val = LOCKS[id].load(Ordering::SeqCst);
if val == 0 {
if count > MAX_NUM - 15 {
count = 0;
LOCKS[id].store(1, Ordering::SeqCst);
loop {
val = LOCKS[id].load(Ordering::SeqCst);
if val == 0 {
BUF_COUNTS[id] = 0;
num += number_skip;
break;
}
}
continue;
}
itoap_write(id, &mut BUF_COUNTS[id], num);
num += 1;
itoap_write(id, &mut BUF_COUNTS[id], num);
str_write(id, &mut BUF_COUNTS[id], FIZZ, 5);
num += 2;
itoap_write(id, &mut BUF_COUNTS[id], num);
str_write(id, &mut BUF_COUNTS[id], BUZZ, 5);
str_write(id, &mut BUF_COUNTS[id], FIZZ, 5);
num += 3;
itoap_write(id, &mut BUF_COUNTS[id], num);
num += 1;
itoap_write(id, &mut BUF_COUNTS[id], num);
str_write(id, &mut BUF_COUNTS[id], FIZZ, 5);
str_write(id, &mut BUF_COUNTS[id], BUZZ, 5);
num += 3;
itoap_write(id, &mut BUF_COUNTS[id], num);
str_write(id, &mut BUF_COUNTS[id], FIZZ, 5);
num += 2;
itoap_write(id, &mut BUF_COUNTS[id], num);
num += 1;
itoap_write(id, &mut BUF_COUNTS[id], num);
str_write(id, &mut BUF_COUNTS[id], FIZZBUZZ, 9);
num += 2;
count += 15;
}
}
}
fn main() {
let max_threads = num_cpus::get();
if max_threads < 2 {
panic!("multi-cpu only!")
}
let mut thread_ids: Vec<usize> = Vec::with_capacity(max_threads);
for x in 0..max_threads {
thread_ids.push(x);
}
thread::scope(|s| {
for x in thread_ids.iter_mut() {
if *x == max_threads - 1 {
let builder = thread::Builder::new();
let res = builder.spawn_scoped(s, || unsafe { sync_threads(max_threads - 1) });
if res.is_err() {
println!("Error spinning up sync thread: {}", res.err().unwrap());
}
} else {
let builder = thread::Builder::new();
let res = builder
.spawn_scoped(s, || unsafe { thread(*x, *x * MAX_NUM, max_threads - 1) });
if res.is_err() {
println!("Error spinning up worker thread: {}", res.err().unwrap());
}
}
}
});
}
Cargo.toml:
[package]
name = "fizz_buzz_threaded"
version = "0.1.0"
authors = ["0xDEADFED5","aiden4"]
edition = "2021"
[dependencies]
num_cpus = "1.15.0"
itoap = "0.1"
[profile.release]
lto = "fat"
also available at https://github.com/0xDEADFED5/fizz_buzz_threaded
-
\$\begingroup\$ It segfaults unless I adjust
MAX_THREADS.32works.64works.96works.231to256segfaults at runtime. If I set it to anything between116and230inclusive the compiler itself crashes! Anyway the throughput seems to be 4.3GB/s-ish. I'll try to find some time to add it to the tables since it seems to be the fastest \$\endgroup\$Omer Tuchfeld– Omer Tuchfeld2023年07月04日 10:13:46 +00:00Commented Jul 4, 2023 at 10:13 -
\$\begingroup\$ i did fix a bug in the code shortly after posting. was hoping it would be faster on your machine since for some strange reason it runs faster on my laptop than that beautiful AVX2 code. \$\endgroup\$0xDEADFED5– 0xDEADFED52023年07月04日 10:36:54 +00:00Commented Jul 4, 2023 at 10:36
-
\$\begingroup\$ My comment was referring to the latest code on GitHub and seems to still be relevant. I will hold back from including this submission in the scores table until those issues are resolved \$\endgroup\$Omer Tuchfeld– Omer Tuchfeld2023年07月16日 10:37:45 +00:00Commented Jul 16, 2023 at 10:37
Ruby
Here's some refinements based on the initial solution by @lonelyelk. Tested using the now latest Ruby 3.3. His original five-liner gives ~70 MiB/s on my machine.
Step 1: Drop the each_slice iteration, using a simple loop:
# frozen_string_literal: true
FMT = "%d\n%d\nFizz\n%d\nBuzz\nFizz\n%d\n%d\nFizz\nBuzz\n%d\nFizz\n%d\n%d\nFizzBuzz\n"
i = 1
loop do
printf(FMT, i, i + 1, i + 3, i + 6, i + 7, i + 10, i + 12, i + 13)
i += 15
end
The result runs at 135 MiB/s, almost twice as fast.
Step 2: Create much longer (by x400) strings each iteration step, using some runtime-generated code.
# frozen_string_literal: true
MULT = 400
FMT = "%d\n%d\nFizz\n%d\nBuzz\nFizz\n%d\n%d\nFizz\nBuzz\n%d\nFizz\n%d\n%d\nFizzBuzz\n" * MULT
idxs = (0..MULT).flat_map do |i|
[0, 1, 3, 6, 7, 10, 12, 13].map { |j| j + i * 15 }
end
eval <<EOS
def run_loop
i = 1
loop do
printf(FMT, #{idxs.map { |n| "i + #{n}" }.join(', ') })
i += 15 * MULT
end
end
EOS
run_loop
This gets up to 180-200 MiB/s, overtaking the "naive C".
Finally, parallelize the computation using ractors (16 seems like the sweet spot on my 6-core machine). This chunk of work is big enough that message-passing overhead is not a problem.
# frozen_string_literal: true
MULT = 400
FMT = ("%d\n%d\nFizz\n%d\nBuzz\nFizz\n%d\n%d\nFizz\nBuzz\n%d\nFizz\n%d\n%d\nFizzBuzz\n" * MULT).freeze
WORKERS = 16
idxs = (0..MULT).flat_map do |i|
[0, 1, 3, 6, 7, 10, 12, 13].map { |j| j + i * 15 }
end
eval <<EOS
def spawn_worker
Ractor.new do
loop do
i = Ractor.receive
Ractor.yield format(FMT, #{idxs.map { |n| "i + #{n}" }.join(', ') }).freeze
end
end
end
EOS
workers = (1...WORKERS).map { spawn_worker }
ii = 1
loop do
workers.each do |worker|
worker.send(ii)
ii += 15 * MULT
end
workers.each { |worker| puts worker.take }
end
This gives ~400 MiB/s, with fluctuations 380-420.
A C++ program for Linux. I use the same method of arithmetic as in my C answer, but here I create a team of threads by hand rather than using OpenMP.
We divide the problem into ranges of numbers, so that we don't have to touch the low-order digits each iteration.
The workers are arranged in a circular chain, and each is responsible for a subrange. We do all our addition while other threads are writing, then take a turn at writing. In order to write an exact number of pages with each write, there's generally one write that straddles two workers, so we combine writes using writev(), temporarily blocking the other worker from beginning its arithmetic. The timing diagram looks like this:
+--------------------------------------------+
| |
| wait |
-------> |
| write (end of prev, start of this) | +--------------------------------------------+
<------- | | |
| write (just this one) | | wait |
| --------------------> |
| wait | | write (end of prev, start of this) |
| <-------------------- |
| update each number | | write (just this one) |
| | | ------+----->
+--------------------------------------------+ | wait |
| <------------
| update each number |
| |
+--------------------------------------------+
On my workstation (8 thread Ivybridge), I measured at around 90% the throughput of cat /dev/zero, or about 3⁄4 that of dd if=/dev/zero bs=64K.
#include <cassert>
#include <condition_variable>
#include <iostream>
#include <memory>
#include <mutex>
#include <thread>
#include <vector>
#include <unistd.h>
#include <sys/sysinfo.h>
#include <sys/uio.h>
// Select a number of decimal digits to use. If we produce one billion
// numbers per second, then we'll finish all the 18-digit numbers in
// just 30 years. 24 digits should suffice until the next geological
// epoch, at least.
static constexpr int numlen = 25; // 24 digits plus newline
static constexpr int write_size = 0x10000; // this is fastest on my system
static_assert('0' - '\n' > 1, "Character coding incompatible with the arithmetic");
#define unlikely(e) __builtin_expect((e), 0)
struct worker
{
// Storage for the character string we maintain
std::string lines{""};
// Iterators to each newline in 'lines'
std::vector<std::string::iterator> nl{};
int units_offset{}; // significant figures in the step
char digit{}; // the single non-zero digit of step
// We coordinate with the next and previous threads in the ring.
// The iovec is used for writing a block of lines that straddles
// the previous thread and this one.
std::mutex mutex{};
std::condition_variable cv{};
struct iovec iov[2] = { { 0, 0 }, { 0, 0 } };
worker *next{};
// The functions
worker(std::size_t first, std::size_t count, std::size_t step);
worker(const worker&) = delete;
worker& operator=(const worker&) = delete;
void loop();
};
static constexpr auto buf_len(std::size_t digits, std::size_t count)
{
// each group of 15 lines has 8 numbers and 39 chars of Fizz and Buzz
return (8 * digits + 39) * count / 15;
}
static constexpr std::size_t optimal_step(long thread_count)
{
// We need each thread to produce at least write_size each iteration
for (std::size_t tens = 1000; tens < 10'000'000; tens *= 10) {
auto const digits = std::snprintf(0, 0, "%zu", tens);
for (std::size_t digit = 3; digit < 10; digit += 3) {
if (buf_len(digits, digit * tens) / thread_count > write_size) {
return digit * tens;
}
}
}
return 9'000'000; // fallback (perhaps we should limit thread count?)
}
int main()
{
// How many threads will we have?
auto const nprocs = get_nprocs();
auto const step = optimal_step(nprocs);
// Write output the slow way, until we have enough digits for the
// format strings.
auto n = 1;
const auto step_len = std::to_string(step).size();
// Finish the loop just before a FizzBuzz, so that the lines buffer
// doesn't start with a number (we need a newline preceding for it
// to overflow correctly).
for (; std::to_string(n).size() <= step_len; ++n) {
if ((n % 15) == 0) {
std::cout << "FizzBuzz\n";
} else if ((n % 5) == 0) {
std::cout << "Buzz\n";
} else if ((n % 3) == 0) {
std::cout << "Fizz\n";
} else {
std::cout << n << '\n';
}
}
std::cout.flush(); // use Unix write() from here on
// create the workers
auto workers = std::vector<std::unique_ptr<worker>>{};
workers.reserve(nprocs);
for (int i = 0; i < nprocs; ++i) {
auto const a = i * step / nprocs;
auto const z = (i+1) * step / nprocs;
workers.emplace_back(std::make_unique<worker>(n + a, z - a, step));
}
// and connect them in a loop
workers.back()->next = workers.front().get();
for (int i = 1; i < nprocs; ++i) {
workers[i-1]->next = workers[i].get();
}
// a thread for each worker
auto threads = std::vector<std::unique_ptr<std::thread>>{};
threads.reserve(nprocs);
auto const loop = [](worker *w) { w->loop(); };
for (auto const& w: workers) {
threads.emplace_back(std::make_unique<std::thread>(loop, w.get()));
}
// start them writing
auto &first = workers.front();
{
std::unique_lock lock{first->mutex};
first->iov[0] = { &first->lines.front(), 0 };
}
first->cv.notify_one();
threads.front()->join();
}
worker::worker(std::size_t first, std::size_t count, std::size_t step)
{
auto s = std::to_string(step);
units_offset = s.size() + 1;
digit = s.front() - '0';
lines.reserve(buf_len(numlen, count) + 1);
nl.reserve(count);
assert(lines.capacity() >= write_size);
for (auto n = first; n < first + count; ++n) {
if ((n % 15) == 0) {
lines += "FizzBuzz\n";
} else if ((n % 5) == 0) {
lines += "Buzz\n";
} else if ((n % 3) == 0) {
lines += "Fizz\n";
} else {
lines += std::to_string(n) + '\n';
}
nl.push_back(lines.end());
}
assert(lines.size() >= write_size);
// Second half of a straddle write is always from the beginning of our buffer.
iov[1].iov_base = &lines.front();
}
void worker::loop()
{
assert(next);
for (;;) {
{
// We can write when the previous thread passes its buffer offcut.
std::unique_lock lock{mutex};
cv.wait(lock, [this]{ return iov[0].iov_base; });
iov[1].iov_len = write_size - iov[0].iov_len;
assert(iov[1].iov_len < lines.size());
writev(1, iov, 2);
// Tell the previous thread that we've finished with its buffer.
iov[0].iov_base = 0;
}
cv.notify_one();
auto p = lines.begin() + iov[1].iov_len;
while (unlikely(p + write_size < lines.end())) {
::write(1, &*p, write_size);
p += write_size;
}
{
// Tell the next thread that we have leftover data for it to write.
std::unique_lock lock{next->mutex};
next->iov[0] = { &*p, static_cast<std::size_t>(lines.end() - p) };
}
next->cv.notify_one();
{
// Now wait until next worker has written, and released buffer back to us.
std::unique_lock lock{next->mutex};
next->cv.wait(lock, [this]{ return !next->iov[0].iov_base; });
}
// Update the numbers in the buffer.
auto rollover = 0u;
for (auto const& i: nl) {
if (i[-2] == 'z') {
// fizz and/or buzz - not a number
continue;
}
// else add 'step' to the number
auto p = i - units_offset;
*p += digit;
while (*p > '9') {
*p-- -= 10;
++*p;
}
if (unlikely(*p == '\n'+1)) {
// digit rollover
++rollover;
}
}
if (unlikely(rollover)) {
// Add a leading one to each overflowing number.
auto nlp = nl.end();
auto p = lines.end();
assert(lines.size() + rollover < lines.capacity());
lines.resize(lines.size() + rollover);
auto dest = lines.end();
while (--p < --dest) {
if (*p == '\n'+1) {
--*p;
*dest-- = '1';
}
if (*p == '\n') {
*nlp-- = dest + 1;
}
*dest = *p;
}
}
}
}
Compile using g++-10 -std=c++2a -Wall -Wextra -Weffc++ -DNDEBUG -O3 -march=native -fno-exceptions -lpthread. No special arguments or environment are needed when running.
-
\$\begingroup\$ Neil + Kamila generates fizzbuzz About 50% faster than the kernel generates 0's on my machine (9 vs 6 gib/s, approx), so I wouldn't consider
/dev/zeroan upper limit. An interesting reference point, maybe. In any case, tried running your new code - optimal when I fake nproc to be 4 - but it just yields results as fast as your previous submission with only 1 core. \$\endgroup\$Omer Tuchfeld– Omer Tuchfeld2021年01月22日 16:42:31 +00:00Commented Jan 22, 2021 at 16:42 -
\$\begingroup\$ That's a shame - unmodified, it runs about 50% faster than my other one here. I really expected to come out ahead on your system too. \$\endgroup\$Toby Speight– Toby Speight2021年01月22日 20:11:04 +00:00Commented Jan 22, 2021 at 20:11
-
3\$\begingroup\$ I've now spent far longer than I should on this. Time to bow out gracefully. \$\endgroup\$Toby Speight– Toby Speight2021年01月22日 20:12:56 +00:00Commented Jan 22, 2021 at 20:12
C++
I’m not sure how you did the benchmarking but would appreciate it if you can run my naïve solution through it.
PS, sorry for being late for the party.
#include <vector>
#include <thread>
#include <iostream>
#include <unistd.h>
class worker
{
public:
worker(size_t size)
{
workersize = size;
buf = new char[workersize * 40];
}
~worker()
{
delete buf;
}
void run()
{
char thisMod = 0;
char ibMod;
char ib[20];
size_t ibStart;
size_t s;
size_t last_ib = -100;
char* ptr = buf;
for (size_t i = start; i < end; i++)
{
size_t m3 = i % 3;
size_t m5 = i % 5;
if (m3 == 0 && m5 == 0)
{
*ptr++ = 'F';
*ptr++ = 'i';
*ptr++ = 'z';
*ptr++ = 'z';
*ptr++ = 'B';
*ptr++ = 'u';
*ptr++ = 'z';
*ptr++ = 'z';
}
else if (m3 == 0)
{
*ptr++ = 'F';
*ptr++ = 'i';
*ptr++ = 'z';
*ptr++ = 'z';
}
else if (m5 == 0)
{
*ptr++ = 'B';
*ptr++ = 'u';
*ptr++ = 'z';
*ptr++ = 'z';
}
else
{
if (i - last_ib < 10 && ibMod + thisMod < 10)
{
// uses previous ib
for (s = ibStart; s <= 14; s++)
*ptr++ = ib[s];
*ptr++ = ib[s] + thisMod - ibMod;
}
else
{
// calc new ib
size_t x = i;
size_t s = 15;
ibMod = x % 10;
ib[s--] = ibMod + '0';
x /= 10;
while (x > 0)
{
ib[s--] = (x % 10) + '0';
x /= 10;
}
ibStart = ++s;
for (ibStart; s <= 15; s++)
*ptr++ = ib[s];
last_ib = i;
}
}
*ptr++ = '\n';
thisMod++;
if (thisMod > 9)
thisMod = 0;
}
buflen = ptr - buf;
}
size_t start;
size_t end;
size_t workersize;
char* buf;
size_t buflen;
};
void task(worker* w)
{
w->run();
}
int main()
{
size_t workercount = std::thread::hardware_concurrency();
size_t workersize = 10000000;
// create workers
std::vector<worker*> workers;
for (size_t i = 0; i < workercount; i++)
workers.push_back(new worker(workersize));
// main loop
size_t cur = 0;
for (;;)
{
// init workers
for (worker* worker : workers)
{
worker->start = cur;
cur += workersize;
worker->end = cur;
}
std::vector<std::thread> threads;
for (worker* worker : workers)
threads.emplace_back(task, worker);
for (std::thread& thread : threads)
thread.join();
// write output
for (worker* worker : workers)
write(1, worker->buf, worker->buflen);
// write progress to cerr
std::cerr << cur << "\n";
}
}
-
\$\begingroup\$ Not bad. Seems to fluctuate between 4GiB/s to 5.5GiB/s. Compiled with
g++ a.cpp -lpthread -o Johan -O3. When I run it all my 32 cores are about 20-40% busy \$\endgroup\$Omer Tuchfeld– Omer Tuchfeld2021年10月08日 14:27:14 +00:00Commented Oct 8, 2021 at 14:27 -
\$\begingroup\$ Using
clang++ a.cpp -lpthread -o Johanclang -O3didn't make much of a difference \$\endgroup\$Omer Tuchfeld– Omer Tuchfeld2021年10月08日 14:34:44 +00:00Commented Oct 8, 2021 at 14:34 -
\$\begingroup\$ @OmerTuchfeld, thank you very much for testing!! Can you perhaps run my latest code when you get a chance? \$\endgroup\$jdt– jdt2021年10月08日 17:28:32 +00:00Commented Oct 8, 2021 at 17:28
-
\$\begingroup\$ No noticeable difference in throughput \$\endgroup\$Omer Tuchfeld– Omer Tuchfeld2021年10月08日 21:53:23 +00:00Commented Oct 8, 2021 at 21:53
-
\$\begingroup\$ @OmerTuchfeld Oh well, thanks anyway! I think that is as far as I can push it. I got an average of about 4 GB/s on my 6 core i7-9850H with the following TIO and was hoping that running it on your 32-core monster would have made a big difference. \$\endgroup\$jdt– jdt2021年10月08日 23:58:58 +00:00Commented Oct 8, 2021 at 23:58
There's plenty room for improvement here and I'll try to update when I can. (Most of the optimizations above will also be applicable):
A simple Powershell solution:
$i = 1
#While ($i -gt 0){
While ($i -lt 100000){ # Limiting to 100k for testing
if ((($i % 5) -eq 0) -and (($i % 3) -eq 0)){Write-Host "FizzBuzz"}
elseif (($i % 3) -eq 0) {Write-Host "Fizz"}
elseif (((($i -split "" | Select-Object -SkipLast 1) |
Select-Object -Last 1) - eq 0) -or ((($i -split "" |
Select-Object -SkipLast 1) | Select-Object -Last 1) -eq 5)){Write-Host "Buzz"}
else {Write-Host $i}
$i++}
-
\$\begingroup\$ Tried running it with
podman run -it --rm --name powershell --volume $PWD:/root mcr.microsoft.com/powershell /usr/bin/pwsh /root/fizz.ps1without success:Line | 7 | Select-Object -Last 1) - eq 0) -or ((($i -split "" | | ~ | You must provide a value expression following the '-' operator.\$\endgroup\$Omer Tuchfeld– Omer Tuchfeld2021年12月10日 21:05:22 +00:00Commented Dec 10, 2021 at 21:05
I'm surprised there is no JavaScript answer here.
But when I try to write a solution, I think I understand why.
JavaScript's score are pretty bad, and the very uncertainty.
But anyway, I want to release my solution first.
It's AMD Ryzen 5 3400G (2.6GHz) using Node v16.13.1 on Ubuntu 18.04.5, Linux 5.6.19.
main.js
let buffer = "";
for (i = 0; i < 1e7; i += 15) {
buffer += `${i+1}\n${i+2}\nfizz\n${i+4}\nbuzz\nfizz\n${i+7}\n${i+8}\nfizz\nbuzz\n${i+11}\nfizz\n${i+13}\n${i+14}\nfizzbuzz\n`;
if(buffer.length > 40000) {
process.stdout.write(buffer);
buffer = "";
}
}
process.stdout.write(buffer);
Because of the high uncertainty, I will test 10 times in a row.
run.sh
#!/bin/bash
for ((i=1; i<=10; i++)); do
node main.js | pv -ab > /dev/null
done
And the result is:
64.9MiB [47.8MiB/s]
64.9MiB [ 150MiB/s]
64.9MiB [ 150MiB/s]
64.9MiB [ 149MiB/s]
64.9MiB [ 151MiB/s]
64.9MiB [ 149MiB/s]
64.9MiB [ 150MiB/s]
64.9MiB [ 153MiB/s]
64.9MiB [78.8MiB/s]
64.9MiB [ 149MiB/s]
-
2\$\begingroup\$ Thank you for your submission. Submissions must go at least as high as 2^63 to be considered correct \$\endgroup\$Omer Tuchfeld– Omer Tuchfeld2022年06月17日 20:54:10 +00:00Commented Jun 17, 2022 at 20:54
Node JS (v18.1.0)
let i = 1;
let str = '';
const resume = () => {
while (true) {
if (i % (2 << 11) === 0) {
const success = process.stdout.write(str);
str = '';
if (!success) {
process.stdout.once('drain', resume);
break;
}
}
if (i % 3 === 0 && i % 5 === 0) {
str += 'FizzBuzz\n'
} else if (i % 3 === 0) {
str += 'Fizz\n'
} else if (i % 5 === 0) {
str += 'Buzz\n'
} else {
str += i + '\n';
}
i++;
}
}
resume();
The command node main.js | pv > /dev/null gave me about 150MiB/s (for comparison the example shown in the OP ran at about 200 MiB/s on my machine, an Intel i7-9700K)
-
1\$\begingroup\$ Welcome to Code Golf! \$\endgroup\$2022年06月23日 17:43:36 +00:00Commented Jun 23, 2022 at 17:43
Python
Here is my humble attempt. It seems to out-perform the other python alternatives on my machine. I'm getting a sustained ~=330-367 MiB/s.
Run with python3, and tested with pypy3 (which seems to be little bit slower 320-360 MiB/s).
from sys import stdout
from io import StringIO
fz = "Fizz"
bz = "Buzz"
nl = "\n"
def fizzbuzz():
num = 1
while True:
nf = True
if num % 3 == 0:
nf = False
yield fz
if num % 5 == 0:
nf = False
yield bz
if nf:
yield str(num)
yield nl
num += 1
output = StringIO()
for a in fizzbuzz():
output.write(a)
stdout.write(output.getvalue())
output.truncate(0)
It uses a StringIO object which, as far as I understand, is implemented in a more efficient way, together with stdout.write, which again, seems to perform better than print and os.write.
I'm also storing the string-parts as variables. It seems to perform better, but that might be just placebo.
I have made a few variations on this with bulking, and writing more numbers/fizzbuzz to the output-parameter before writing to stdout, but it only seems to slow it down. I'm not sure why that is, but perhaps I get more lucky with L1/L2 cache with the current approach.
-
\$\begingroup\$ I see @janfrode 's answer now which, on my machine, runs at a similar speed, nice job! \$\endgroup\$Automatico– Automatico2023年07月03日 11:23:20 +00:00Commented Jul 3, 2023 at 11:23
Just normal Go
package main
import (
"bufio"
"fmt"
"os"
)
var writer *bufio.Writer = bufio.NewWriter(os.Stdout)
func printf(f string, a ...interface{}) { fmt.Fprintf(writer, f, a...) }
func main() {
defer writer.Flush()
for i := 1; i < 1000000000; i++ {
if (i % 3 == 0) && (i % 5 == 0) {
printf("FizzBuzz\n")
} else if i % 3 == 0 {
printf("Fizz\n")
} else if i % 5 == 0 {
printf("Buzz\n")
} else {
printf("%d\n",i)
}
}
}
Unrolled output version:
package main
import (
"bufio"
"fmt"
"os"
)
var writer *bufio.Writer = bufio.NewWriter(os.Stdout)
// or: bufio.NewWriterSize(os.Stdout, 400 * 1024 * 1024)
func printf(f string, a ...interface{}) { fmt.Fprintf(writer, f, a...) }
func main() {
const FMT = "%d\n%d\nFizz\n%d\nBuzz\nFizz\n%d\n%d\nFizz\nBuzz\n%d\nFizz\n%d\n%d\nFizzBuzz"
defer writer.Flush()
for i := 1; i < 1000000000; i += 15 {
printf(FMT, i, i+1, i+3, i+6, i+7, i+10, i+12, i+13)
}
}
Unbuffered output version:
package main
import "fmt"
func main() {
for i := 1; i < 1000000000; i++ {
if (i % 3 == 0) && (i % 5 == 0) {
fmt.Println("FizzBuzz")
} else if i % 3 == 0 {
fmt.Println("Fizz")
} else if i % 5 == 0 {
fmt.Println("Buzz")
} else {
fmt.Printf("%d\n",i)
}
}
}
On my machine:
gcc version 11.3.0 (Ubuntu 11.3.0-1ubuntu1~22.04.1)
gcc a.c && ./a.out | pv > /dev/null
go version go1.20.5 linux/amd64
go build a.go && ./a | pv > /dev/null
- C example:
7.33GiB 0:00:26 [ 282MiB/s] - Go:
7.33GiB 0:00:56 [ 133MiB/s] - Go (400MB buffer):
7.33GiB 0:00:49 [ 151MiB/s] - Unrolled Go:
7.27GiB 0:00:32 [ 229MiB/s] - Unrolled Go (400MB buffer):
7.27GiB 0:00:25 [ 291MiB/s] - unbuffered Go:
7.33GiB 0:05:50 [21.4MiB/s]
This probably won't be the fastest, but I am curious how it performs compared to a naive stdio-based fizzbuzz. I created this to illustrate the approach I suggested in the comments of using an array of fixed-length regions to format the output, and filtering out null padding before printing the output. I didn't do any multithreading, either, this could probably be improved by using multiple buffers and doing the writing on another thread.
This code does nothing to prevent unusual output after reaching ULONG_MAX. It might be able to be made faster by only supporting up to UINT_MAX, which would also allow more data to fit in a given size of intermediate buffer.
// sample outputs [space is null]
// 1\n
// Fizz \n
// Buzz \n
// FizzBuzz \n
// 18446744073709551614\n ULLONG_MAX-1 [ULLONG_MAX is FizzBuzz]
#define LEN 21
//#define NUM (200*15)
#define NUM (200*15)
#if defined(_POSIX_C_SOURCE)
#include <unistd.h>
#define WRITE(b,l) write(1,b,l)
#elif defined(_MSC_VER)
#include <io.h>
#define WRITE(b,l) write(1,b,l)
#else
#include <stdio.h>
#define WRITE(b,l) fwrite(b,1,l,stdout)
#endif
char buf[NUM*LEN] = {0}; // 63000
char buf2[NUM*LEN];
int flags[NUM];
int main() {
// pre-populate buffer
for(int i=0; i<NUM; i++) {
char *t = buf+i*LEN;
int f = flags[i] = i%3==0 | ((i%5==0)<<1);
if(f&1) { t[0]='F'; t[1]='i'; t[2]='z'; t[3]='z';}
if(f&2) { t[4]='B'; t[5]='u'; t[6]='z'; t[7]='z';}
t[LEN-1] = '\n';
}
int j=1; // position of current output within buffer
for(unsigned long long i=1;;i++) {
if(!flags[j]) {
char *t = buf+j*LEN+(LEN-2); // position of last digit
unsigned long long k = i;
while(k) {
*t-- = '0'+k%10;
k/=10;
}
}
if(++j == NUM) {
j=0;
char *p=buf;
char *q=buf2;
if(i == NUM-1) p+=LEN; // skip zero, there's probably a better way
while(p < buf+NUM*LEN) {
if(*p) *q++=*p;
p++;
}
WRITE(buf2, q-buf2);
}
}
}
-
\$\begingroup\$ I'm getting 0.5GiB/s \$\endgroup\$Omer Tuchfeld– Omer Tuchfeld2021年10月29日 21:58:10 +00:00Commented Oct 29, 2021 at 21:58
-
1\$\begingroup\$ yeah, once i posted it i realized that per-character branch inside the while loop is probably terrible for the performance, i'd been hoping it was optimized away to a conditional move or something - i can't find a way to get rid of it either. Ah well, it's at least useful as evidence this approach isn't worthwhile. \$\endgroup\$Random832– Random8322021年10月29日 22:01:10 +00:00Commented Oct 29, 2021 at 22:01
C99 (gcc)
#include <unistd.h>
#include <string.h>
#include <stdio.h>
#include <stdbool.h>
#define SIZE (1 << 16)
int main(void) {
char buffer[SIZE] = {};
char *buf = buffer;
unsigned long long int prev_n_3=0;
unsigned long long int prev_n_5=0;
for (unsigned long long int n=3; 3; n++) {
if ((buf - buffer) >= (SIZE-21)) {
write(1, buffer, buf-(buffer+1));
buf = buffer;
}
if (n-prev_n_3==3) {
buf[0] = 'F';
buf[1] = 'i';
buf[2] = 'z';
buf[3] = 'z';
buf += 4;
prev_n_3=n;
}
if (n-prev_n_5==5) {
buf[0] = 'B';
buf[1] = 'u';
buf[2] ='z';
buf[3] = 'z';
buf += 4;
prev_n_5=n;
}
if (!(prev_n_5==n) && !(prev_n_3==n)) {
buf += sprintf(buf,"%llu",n);
}
*buf='\n';
buf++;
}
return 0;
}
About 140 MiBs by my measurement. I measured using gcc -flto -Ofast, on a 2015 MacBook Air running Big Sur. I deleted my previous answer a while ago. This is a partial rewrite.
-
1\$\begingroup\$ Outputs junk
0円\$\endgroup\$Omer Tuchfeld– Omer Tuchfeld2021年12月23日 15:18:05 +00:00Commented Dec 23, 2021 at 15:18 -
1\$\begingroup\$ (Around
12322) \$\endgroup\$Omer Tuchfeld– Omer Tuchfeld2021年12月23日 15:25:18 +00:00Commented Dec 23, 2021 at 15:25 -
\$\begingroup\$ Fixed by using printf. Thanks! \$\endgroup\$Qaziquza– Qaziquza2021年12月23日 20:16:10 +00:00Commented Dec 23, 2021 at 20:16
-
1\$\begingroup\$ Fails pretty early (int overflow at ~2 billion) \$\endgroup\$Omer Tuchfeld– Omer Tuchfeld2021年12月23日 21:36:02 +00:00Commented Dec 23, 2021 at 21:36
-
2\$\begingroup\$ That's still very early, see the "very high astronomical number" requirement \$\endgroup\$Omer Tuchfeld– Omer Tuchfeld2021年12月24日 12:09:51 +00:00Commented Dec 24, 2021 at 12:09
PHP (simple)
<?php
ob_start(null, 32000);
for ($i = 0; $i < PHP_INT_MAX; $i++) {
$out = $i;
if ($i % 3 === 0) $out = 'fizz';
if ($i % 5 === 0) {
$out = 'buzz';
if ($i % 3 === 0) $out = 'fizzbuzz';
}
echo "$out\n";
}
PHP (optimized)
<?php
ob_start(null, 32000);
$a = [0, 1, 'fizz', 3, 'buzz', 'fizz',
6, 7, 'fizz', 'buzz', 10, 'fizz',
12, 13, 'fizzbuzz', ''];
for ($i = 1; $i < PHP_INT_MAX-15; $i+=15) {
$a[0] = $i;
$a[1] = $i+1;
$a[3] = $i+3;
$a[6] = $i+6;
$a[7] = $i+7;
$a[10] = $i+10;
$a[12] = $i+12;
$a[13] = $i+13;
echo join("\n", $a);
}
PHP (multithreaded)
<?php
$nWorkers = preg_match_all('/^processor\s/m', file_get_contents('/proc/cpuinfo'), $discard);
$iterationsPerFlush = 20000;
define('CHILD_TOKEN_KEY', 0);
//1 byte SHM segment holding the worker ID whose turn it is to write
//initialise to child 0.
$shm = shm_attach(1);
shm_put_var($shm, CHILD_TOKEN_KEY, 0);
//Semaphore to protect access to the SHM var
$key = ftok(__FILE__, 1);
$sem = sem_get($key);
$childPids = [];
pcntl_sigprocmask(SIG_BLOCK, [SIGTERM, SIGINT, SIGCHLD]);
for ($i=0; $i<$nWorkers; $i++){
if (!$pid = pcntl_fork()){
doWork($sem, $shm, $i, $nWorkers, $iterationsPerFlush);
exit;
}else{
$childPids[] = $pid;
}
}
//If we get killed or one of our children does, clean everything up
pcntl_sigwaitinfo([SIGTERM, SIGINT, SIGCHLD], $info);
foreach ($childPids as $pid){
posix_kill($pid, SIGKILL);
}
sem_remove($sem);
shm_remove($shm);
function doWork($sem, $shm, $childId, $nWorkers, $iterationsPerFlush){
$nextChildId = ($childId + 1) % $nWorkers;
$increment = ($nWorkers - 1) * $iterationsPerFlush * 15;
$startOffset = $childId * $iterationsPerFlush * 15;
$a = [-14 + $startOffset, -13 + $startOffset, "fizz", -11 + $startOffset, "buzz\nfizz",
-8 + $startOffset, -7 + $startOffset, "fizz\nbuzz", -4 + $startOffset, "fizz",
-2 + $startOffset, -1 + $startOffset, "fizzbuzz\n"];
ob_start();
while (true){
for ($i = 0; $i < $iterationsPerFlush; $i++){
$a[0] += 15;
$a[1] += 15;
$a[3] += 15;
$a[5] += 15;
$a[6] += 15;
$a[8] += 15;
$a[10] += 15;
$a[11] += 15;
echo join("\n", $a);
}
//Acquire the semaphore and check if it's our turn to flush. If not, repeat.
while (true){
sem_acquire($sem);
if (shm_get_var($shm, CHILD_TOKEN_KEY) === $childId){
break;
}
sem_release($sem);
}
ob_flush();
//Pass the token on to the next child and release the semaphore
shm_put_var($shm, CHILD_TOKEN_KEY, $nextChildId);
sem_release($sem);
//Skip over the numbers the other workers already handled
$a[0] += $increment;
$a[1] += $increment;
$a[3] += $increment;
$a[5] += $increment;
$a[6] += $increment;
$a[8] += $increment;
$a[10] += $increment;
$a[11] += $increment;
}
}
The multithreaded version is the result of this thread on Reddit:
https://old.reddit.com/r/PHP/comments/v94ly2/php_fizzbuzz/
It was mostly done by therealgaxbo.
-
\$\begingroup\$ Ends too quickly, see rules: "The output must go on forever (or a very high astronomical number)" \$\endgroup\$Omer Tuchfeld– Omer Tuchfeld2022年06月07日 21:06:40 +00:00Commented Jun 7, 2022 at 21:06
-
\$\begingroup\$ What is the definition of "very high astronomical number"? I think it would be cool to have this simple approach in the race and see if PHP already outperforms the other interpreted languages like Python and Ruby, even if they use more optimized approaches. This would limit the loop to PHP_INT_MAX which is 9223372036854775807. Would that be sufficient? \$\endgroup\$no_gravity– no_gravity2022年06月09日 06:59:16 +00:00Commented Jun 9, 2022 at 6:59
-
\$\begingroup\$ "What is the definition of "very high astronomical number"?" - I guess I would consider numbers 2^63 (PHP_INT_MAX) and higher astronomical. It would take the best submission here more than a hundred years to get to that number (357823770363079921209 digits between 1 and 2^63 with about 40% removed for fizzing and buzzing + 9223372036854775808 newlines is about 194 exabytes of characters at 50GiB/s). By the way PHP_INT_MAX is only 4 billion on 32-bit machines, but I guess it's fair to assume my machine / PHP executable is 64-bit. I'm getting 130MiB/s with your submission by the way \$\endgroup\$Omer Tuchfeld– Omer Tuchfeld2022年06月10日 08:37:12 +00:00Commented Jun 10, 2022 at 8:37
-
\$\begingroup\$ Ah, 130MiB/s is not that much. Then let's go for an optimized version. I just added one. On my laptop, it runs 5x faster than the simple one. \$\endgroup\$no_gravity– no_gravity2022年06月10日 17:17:22 +00:00Commented Jun 10, 2022 at 17:17
-
\$\begingroup\$ I see you added the results of the optimized version. Great. I now also added a multithreaded version. So far, it seems to scale about linearly with the number of cores. \$\endgroup\$no_gravity– no_gravity2022年06月16日 08:07:01 +00:00Commented Jun 16, 2022 at 8:07
awk
If modulo (%) ops are considered high cost, then here's one way to do handle all output scenarios with just 1 modulo, and 1 single copy of combined string.
jot 36 |
awk 'function ____(__,_,___){return(_^=_<_)-(__=int(___=__?__:$_)^++_^_++%(_++*++_))\
?substr("Fizz Buzz",++_^(_--<__),_*!__+--_):___}$NF=____()' ORS=', '
1, 2, Fizz, 4, Buzz, Fizz, 7, 8, Fizz, Buzz, 11, Fizz,
13, 14, Fizz Buzz, 16, 17, Fizz, 19, Buzz, Fizz, 22, 23, Fizz,
Buzz, 26, Fizz, 28, 29, Fizz Buzz, 31, 32, Fizz, 34, Buzz, Fizz,
But if I stupidly hard-encode every scenario into an array,
( time ( mawk2 ' BEGIN {
______ = 16
1ドル = (4ドル = 7ドル = 10ドル = 13ドル = "Fizz")" "(6ドル = 11ドル = "Buzz")
for (_____ ^= _ = (ORS = ", ")*(___ = (_+=++_)^++_^_); _++ < ___;)
$(_____ ^= ++_____ < ______) ? $_____ : _
printf("%d\n", ___) }' ) )
( mawk2 ; ) 7.07s user 0.03s system 99% cpu 7.102 total
1 134217728
echo '1148700297/7.102/32^4' | bc -l
154.25034785935389293948
Cycling through 2^0 - 2^27, mawk2 had an internal throughput rate of 154.25 MiB/sec, which is quite insane for a single-threaded shell scripting language invented 47 years ago. In this variant, all the thresholds appear to be upshifted by one, and that's by design, since I'm using exponentiation to handle mod 15.
i). But it still uses a slowdivfor int->string, and critically useswritefor each group of 15 output lines built up in a buffer. Full-on perf tuning would probably just unroll by 15, and of course use much bigger buffers. \$\endgroup\$