People are always asking how the performance of COMSOL Multiphysics® simulation software will improve on a parallel system, especially now that large multi-core desktop computers are relatively inexpensive and it’s easy to rent time on cloud services like the Amazon Elastic Compute CloudTM. It turns out, though, that it’s not always possible to get faster performance just by throwing more hardware at the problem. To understand why, let’s take a conceptual look at computers and the algorithms COMSOL® software uses.
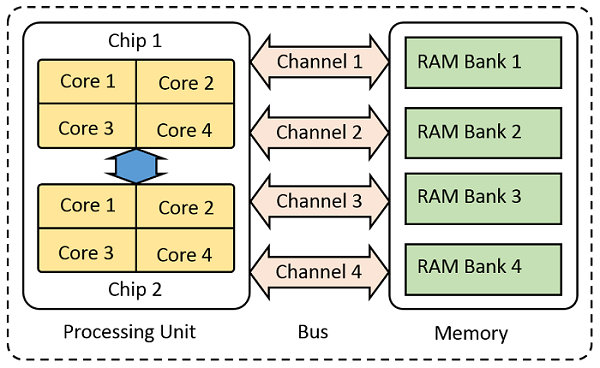
Let’s start by considering a very simplified model of a computer, composed of just three parts: random access memory (RAM), which is used to store information; a processing unit, which performs mathematical operations on the information; and a bus, which transfers the data between the two.
[画像:Design showing parallel computing in a typical desktop computer.]
Schematic of the key parts of a computer.
For the purposes of this blog post, let’s imagine that all of the data about the problem is sitting in the RAM and that this data gets moved over to the processing unit via the bus. The memory bus itself can be composed of several channels operating in parallel, effectively increasing throughput. The processing unit can be composed of several chips, each of which can have several computational cores that are able to work on data simultaneously, after it has been loaded from the memory via the bus. Let’s use this as our mental model of the computer sitting on our desktop.
Many problems in computer science can be thought of as games that we played as children. Let’s look at three of the classics.
First, let’s try to find a face in the crowd, á la Where’s Waldo?
[画像:A photo of attendees at the COMSOL Conference.]
A photo from the COMSOL Conference. Can you find me?
Suppose we have a photo with hundreds of people — what’s the fastest way of finding one person?
You could scan through the entire image by yourself, checking faces one by one to see if they match the person you are searching for. But, this can be quite slow. You can also invite your friends over to help. In this case, you would first subdivide the picture into smaller pieces. Each person can then independently work on one piece at a time.
In the language of computer science, we would say that this game is completely parallel.
Having two people working will halve the solution time, four people will cut the solution time in four, and so on. But, there is a limit — you can only have as many friends helping you as there are faces in the crowd. Beyond that point, inviting more people to help won’t speed up the process, and it may even slow things down.
Next, let’s try to solve a jigsaw puzzle.
[画像:An image of a jigsaw puzzle.]
Can you put together the image?
This is a bit more complicated — you can have multiple people working at once, but they cannot work independently. Each person will take a few dozen puzzle pieces for themselves from the main pile and try to fit them together with the pieces that their friends are putting together. People will try to fit their own pieces together. They will pass pieces back and forth, and they will be in constant communication with each other.
A computer scientist would call this a partially parallel game.
Although adding more people will decrease the solution time, it will not be a simple mathematical relationship. Suppose you have a 1,000-piece puzzle, and 10 people with 100 pieces each. They will spend relatively more time working on their own pieces and less time talking. On the other hand, if you have 100 people with 10 pieces each, there will be a lot more talking and moving pieces around. And what will happen when you have 1,000 people working on a puzzle with 1,000 pieces? Try that one at home!
You can probably see that for a puzzle of a certain size, there is some maximum number of people that can be working it. This number will be much lower than the number of puzzle pieces. Adding more people won’t speed things up noticeably.
Finally, let’s try to stack some blocks on top of each other to form a tower, and then raise the height of the tower by taking the blocks from the lower levels and adding them to the top without causing the structure to topple over.
[画像:A JENGA tower.]
How high can you stack the tower? (JENGA® tower standing on one tile. “Jenga distorted” by Guma89 — Own work. Licensed under Creative Commons Attribution-Share Alike 3.0 via Wikimedia Commons.)
In this game, only one person can play at a time, and we can say that the game is completely serial.
Playing with more people won’t finish the game any faster, and if you invite too many people to play, some of them will never get a chance to do anything. In fact, it’s probably fastest (albeit not very sociable) to play this game by yourself.
You can probably already see the relationships between playing these games and using COMSOL Multiphysics. How about we start classifying the problems you solve in COMSOL Multiphysics into these categories:
When solving, COMSOL Multiphysics is spending most of its time solving a partially parallel problem. So, what actually happens in the hardware?
The COMSOL software starts with the information about the loads, boundary conditions, material properties, and finite element mesh and generates data that is used during the solution process. Many gigabytes of memory are needed to store the system matrices, generate intermediate information, and compute the solution. Ideally, all of this information should be stored in the RAM.
It is worth noting that COMSOL Multiphysics does offer hard-disk based solvers as well, but these will be slower than when data is accessed directly from the RAM. Their advantage is that they allow you to solve larger problems.
Of course, this data has to be operated on by the processors, so it turns out that the bottleneck in the solution on a desktop computer is actually the bandwidth of the memory bus — much more so than the processor speed, or even the number of processor cores.
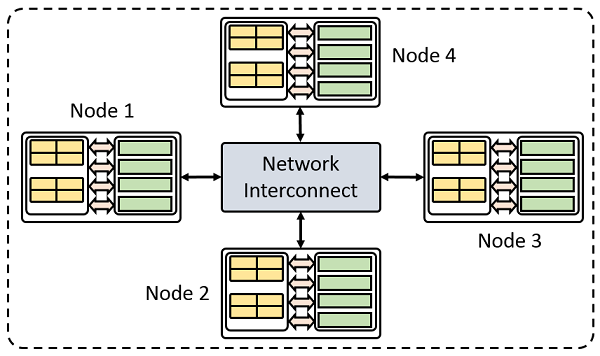
Cluster computers are really nothing more than ordinary computers, or nodes, connected with an additional communication layer.
Let’s assume that we are working with a cluster where each node is equivalent in performance to that of our single computer. Data passes between the nodes via the interconnect hardware. The interconnect speed is dependent upon not just the type of hardware, but also the physical configuration. In sum, it is usually slower than the memory bus speed on any individual node. This introduces an additional consideration.
[画像:A model of cluster with four computer nodes.]
A simple model of a cluster with four compute nodes.
We have already seen that the partially parallelizable case is the most important to understand, so we’ll focus on that.
On a cluster, we would say that we are solving this problem in a distributed parallel sense. In the context of our game of putting together a puzzle, we can think of this as grouping several of our friends in different rooms of our house, and giving them each a stack of pieces. You would now additionally need to send pieces and information back and forth between different rooms.
COMSOL Multiphysics adjusts the solution algorithm to maximize the amount of work done locally and minimize the amount of data that is passed back and forth. These distributed parallel solvers, which are available when you use the Floating Network License, adjust the solution algorithm to efficiently split the problem up onto the different nodes of the cluster. Again, we can see that there is a limit. If there are too many nodes involved, we will just be communicating data back and forth all the time. So, for each particular problem, there is some number of nodes beyond which solution speed will not improve.
Now, if you have a completely parallel problem, such as a parametric sweep, where each step in the sweep can be solved entirely within the RAM available on one node, then a cluster is an almost perfect way to speed up your modeling. You could use up to as many nodes as there are parameter values that you want to sweep over.
You should now have an understanding of the different types of problems that COMSOL Multiphysics solves, in terms of parallelization and how these relate to performance.
When working on a single computer, the performance bottleneck is the bus speed rather than the clock speed and number of processors. For desktop machines, we also publish some more specific hardware purchasing guidelines in our Knowledge Base. For cluster computers, performance can be much more variable, depending on problem size, cluster architecture, and the type of problem being solved. If you want more technical details about clusters, please see this series of blogs on hybrid parallel computing.
Amazon Web Services, the "Powered by Amazon Web Services" logo, and Amazon Elastic Compute Cloud are trademarks of Amazon.com, Inc. or its affiliates in the United States and/or other countries.
JENGA® is a registered trademark owned by Pokonobe Associates.
By providing your email address, you consent to receive emails from COMSOL AB and its affiliates about the COMSOL Blog, and agree that COMSOL may process your information according to its Privacy Policy. This consent may be withdrawn.
Hi,
I think this blog post is a bit misleading. There are still ways to parrallelise the computations. For instance deal.II numbers all of the mesh elements and then splits up the domain so that the computer nodes know what information to pass back and forth. Considering comsol’s poor parrallelisation, is this something that you will look at utilising in the future?
https://www.dealii.org/current/doxygen/deal.II/group__distributed.html
Hello Declan,
There is nothing misleading about this post, it primarily presents a concept fundamental to parallel computing: that algorithms can be classified as either completely, partially, or not-at-all parallelizable. Many people are not fully aware of this distinction. As such, it is really a COMSOL-independent article.
Now, COMSOL is always working on improving the performance of those algorithms that are partially parallel, and there have been some significant improvements in this regard since this article was written (5+ years ago…) and you will see more such improvements in the future, so stay tuned!
Hello Walter
Your article is very helpful to understand COMSOL parallel runs.
we’re looking for a cost-effective platform to solve our models.
Here’s an example setup for our case.
Would you give us some guidance on which is the best for us?
we want to run the hundreds (can be thousands) of geometry parameters, which can be independently run for each. I think that is the case you mentioned at the end of the paragraph. —– now, if you have a completely parallel problem, such as a parametric sweep, ——
option 1
we build up a desktop computer.
two-64 core machine with a 2TB memory and run 8 models at the same time, each model use 16 cores and 200 GB memory.
this case needs only a single node COMSOL license.
option 2
Go with AWS EC2 service.
in this scenario, if we want to use 8 nodes at the same time do we need 8 FNL COMSOL licenses?
Thanks
Hello Jeong-woo,
The second option you describe, of using a parametric sweep on a cluster, would need just a single COMSOL FNL license, no matter how many cases of the parametric sweep you want to solve at once. See also: https://www.comsol.com/products/licensing
Best Regards,
Hello Walter
Thanks for the clarification about the FNL license.
So do you think AWS can be a more affordable way to go for our case?
our model mesh is around 20 million requiring a very large size of memory if I set up a direct solver – my preferrable option due to the robustness.
Do you think AWS node is large enough to handle this, otherwise if they go with a shared distributed memory option between the nodes that going to be very slow?
my understanding is correct?
Thanks
Hello Jeong-woo,
That is a question that is more the realm of technical support. I’d also recommend first, as general background, reading:
https://www.comsol.com/blogs/much-memory-needed-solve-large-comsol-models/
In particular, you may not want to use a direct solver. But than again, this question really needs to be addressed in the context of a specific model.
Best Regards,
Hi Walter,
Very helpful article! Thanks!
I am trying to run COMSOL on DelftBlue (https://www.tudelft.nl/dhpc/system) with cluster batch call from command line. However, I encountered errors that cannot open file for writing, and Error: Failed to start COMSOL…….Cannot open file for writing:
“`Cannot open file for writing.
Cannot open file for writing.
Cannot open file for writing.
/**/
/*Error****/
/**/
Cannot open file for writing.
/**/
/*Error****/
/**/
Cannot open file for writing.
/**/
/*Error****/
/**/
Cannot open file for writing.
Opening file: /scratch/wenluo/Test_comsol/2D_DAS.mph
Opening file: /scratch/wenluo/Test_comsol/2D_DAS.mph
Opening file: /scratch/wenluo/Test_comsol/2D_DAS.mph
Opening file: /scratch/wenluo/Test_comsol/2D_DAS.mph
Opening file: /scratch/wenluo/Test_comsol/2D_DAS.mph
Opening file: /scratch/wenluo/Test_comsol/2D_DAS.mph
ERROR: Failed to start COMSOL. For details, see the log file /home/wenluo/.comsol/v56/logs/batch9.log
ERROR: Additional information: Cannot open file for writing.
ERROR: Failed to start COMSOL. For details, see the log file /home/wenluo/.comsol/v56/logs/batch7.log
ERROR: Additional information: Cannot open file for writing.
ERROR: Failed to start COMSOL. For details, see the log file /home/wenluo/.comsol/v56/logs/batch3.log
ERROR: Additional information: Cannot open file for writing.
ERROR: Failed to start COMSOL. For details, see the log file /home/wenluo/.comsol/v56/logs/batch9.log
ERROR: Additional information: Cannot open file for writing.
ERROR: Failed to start COMSOL. For details, see the log file /home/wenluo/.comsol/v56/logs/batch6.log
ERROR: Additional information: Cannot open file for writing.
ERROR: Failed to start COMSOL. For details, see the log file /home/wenluo/.comsol/v56/logs/batch1.log
ERROR: Additional information: Cannot open file for writing.
ERROR: Failed to start COMSOL. For details, see the log file /home/wenluo/.comsol/v56/logs/batch1.log
ERROR: Additional information: Cannot open file for writing.
ERROR: Failed to start COMSOL. For details, see the log file /home/wenluo/.comsol/v56/logs/batch8.log
ERROR: Additional information: Cannot open file for writing.
ERROR: Failed to start COMSOL. For details, see the log file /home/wenluo/.comsol/v56/logs/batch9.log
ERROR: Additional information: Cannot open file for writing.
ERROR: Failed to start COMSOL. For details, see the log file /home/wenluo/.comsol/v56/logs/batch5.log
ERROR: Additional information: Cannot open file for writing.
!ENTRY com.comsol.util 4 0 2023年11月07日 15:51:16.410
!MESSAGE Failed to start COMSOL. Error: Cannot open file for writing.
!STACK 0
java.lang.RuntimeException: Cannot open file for writing.“`
Could you please kindly help me out with this? Thanks,
Wen
The script is:
#!/bin/sh
#
#SBATCH –job-name=”Test_comsol_login”
#SBATCH –time=00:10:00
#SBATCH –partition=compute
#SBATCH –nodes=1
#SBATCH –ntasks=16
#SBATCH –cpus-per-task=1
#SBATCH –mem-per-cpu=3GB
#SBATCH –account=innovation
module load 2022r2
module load comsol/5.6
srun comsol batch -inputfile 2D_DAS.mph -outputfile 2D_DAS_OUT.mph
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}