|
| 1 | +### python高级爬虫实战之Headers信息校验-User-Agent |
| 2 | + |
| 3 | + User-agent 是当前网站反爬策略中最基础的一种反爬技术,服务器通过接收请求头中的user-agen的值来判断是否为正常用户访问还是爬虫程序。 |
| 4 | + |
| 5 | + 下面举一个简单的例子 爬取我们熟悉的豆瓣网: |
| 6 | + |
| 7 | +```python |
| 8 | +import requests |
| 9 | +url='https://movie.douban.com/' |
| 10 | +resp=requests.get(url) |
| 11 | +print(resp.status_code) |
| 12 | +``` |
| 13 | + |
| 14 | +运行结果得到status_code:418 |
| 15 | + |
| 16 | +说明我们爬虫程序已经被服务器所拦截,无法正常获取相关网页数据。 |
| 17 | + |
| 18 | +我们可以通过返回的状态码来了解服务器的相应情况 |
| 19 | + |
| 20 | +- 100–199:信息反馈 |
| 21 | +- 200–299:成功反馈 |
| 22 | +- 300–399:重定向消息 |
| 23 | +- 400–499:客户端错误响应 |
| 24 | +- 500–599:服务器错误响应 |
| 25 | + |
| 26 | +现在我们利用google chrome浏览器来打开豆瓣网,查看下网页。 |
| 27 | + |
| 28 | +正常打开网页后,我们在页面任意地方右击"检查" 打开开发者工具。 |
| 29 | + |
| 30 | +<img src="https://s2.loli.net/2024/03/01/ime1CM9vWIGAU2D.png" alt="image-20240301205014592" style="zoom:50%;" /> |
| 31 | + |
| 32 | + |
| 33 | + |
| 34 | +选择:Network-在Name中随便找一个文件点击后,右边Headers显示内容,鼠标拉到最下面。 |
| 35 | + |
| 36 | +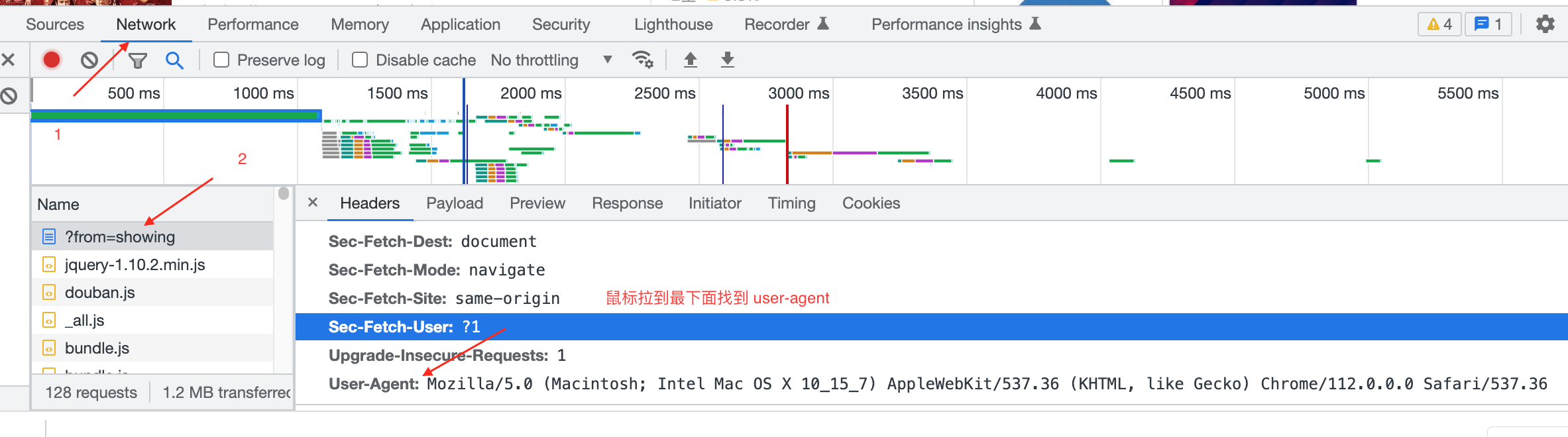 |
| 37 | + |
| 38 | +User-Agent: |
| 39 | + |
| 40 | +Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36 |
| 41 | + |
| 42 | +我们把这段带到程序中再试下看效果如何。 |
| 43 | + |
| 44 | +```python |
| 45 | +import requests |
| 46 | +url='https://movie.douban.com/' |
| 47 | +headers={ |
| 48 | +"user-agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36" |
| 49 | +} |
| 50 | +resp=requests.get(url,headers=headers) |
| 51 | +print(resp.status_code) |
| 52 | +``` |
| 53 | + |
| 54 | +完美,执行后返回状态码200 ,说明已经成功骗过服务器拿到了想要的数据。 |
| 55 | + |
| 56 | + 对于User-agent 我们可以把它当做一个身份证,这个身份证中会包含很多信息,通过这些信息可以识别出访问者。所以当服务器开启了user-agent认证时,就需要像服务器传递相关的信息进行核对。核对成功,服务器才会返回给用户正确的内容,否则就会拒绝服务。 |
| 57 | + |
| 58 | +当然,对于Headers的相关信息还有很多,后续我们再一一讲解,下期见。 |
| 59 | + |
| 60 | + |
| 61 | + |
0 commit comments