+ 微信群 + 公众号 + B站 + 知乎 + CSDN + 头条 + 掘金 +
+ +## Python3 网络爬虫教程 2020 +| 文章 | 公众号 | 代码 | +| :------ | :--------: | :--------: | +| Python3 网络爬虫(一):初识网络爬虫之夜探老王家 | [公众号](https://mp.weixin.qq.com/s/1rcq9RQYuAuHFg1w1j8HXg "Python3 网络爬虫(一)") | no | +| Python3 网络爬虫(二):下载小说的正确姿势 | [公众号](https://mp.weixin.qq.com/s/5e2_r0QXUISVp9GdDsqbzg "Python3 网络爬虫(二)") | [Code](https://github.com/Jack-Cherish/python-spider/tree/master/2020/xbqg "Python3 网络爬虫(二)") | +| Python3 网络爬虫(三):漫画下载,动态加载、反爬虫这都不叫事!| [公众号](https://mp.weixin.qq.com/s/wyS-OP04K3Vs9arSelRlyA "Python3网络爬虫(三)") | [Code](https://github.com/Jack-Cherish/python-spider/tree/master/2020/dmzj "Python3 网络爬虫(三)") | +| Python3 网络爬虫(四):视频下载,那些事儿!| [公众号](https://mp.weixin.qq.com/s/_geNA6Dwo4kx25X7trJzlg "Python3 网络爬虫(四)") | [Code](https://github.com/Jack-Cherish/python-spider/tree/master/2020/zycjw "Python3 网络爬虫(四)") | +| Python3 网络爬虫(五):老板,需要特殊服务吗?| [公众号](https://mp.weixin.qq.com/s/PPTSnIHV71b-wB3oRiYnIA "Python3 网络爬虫(五)") | [Code](https://github.com/Jack-Cherish/python-spider/tree/master/2020/api "Python3 网络爬虫(五)") | +| Python3 网络爬虫(六):618,爱他/她,就清空他/她的购物车!| [公众号](https://mp.weixin.qq.com/s/lXXDfzyLVrf3f-aqJN1C3A "Python3 网络爬虫(六)") | [Code](https://github.com/Jack-Cherish/python-spider/tree/master/2020/taobao "Python3 网络爬虫(六)") | +| 宝藏B站UP主,视频弹幕尽收囊中!| [公众号](https://mp.weixin.qq.com/s/aWratg1j9RBAjIghoY66yQ "宝藏B站UP主,视频弹幕尽收囊中!") | [Code](https://github.com/Jack-Cherish/python-spider/tree/master/2020/bilibili "宝藏B站UP主,视频弹幕尽收囊中!") | + +更多精彩,敬请期待! + + + +[画像:wechat] diff --git a/2020/api/api.py b/2020/api/api.py new file mode 100644 index 00000000..4ed08497 --- /dev/null +++ b/2020/api/api.py @@ -0,0 +1,65 @@ +import requests +import base64 +import json +import cv2 +import numpy as np +import matplotlib.pyplot as plt +%matplotlib inline + + +beautify_url = "https://api-cn.faceplusplus.com/facepp/v2/beautify" +# 你创建的应用的 API Key 和 API Secret(也叫 Secret Key) +AK = '' +SK = '' + +# 可选参数,不填写,默认50 +# 美白程度 0 - 100 +whitening = 80 +# 磨皮程度 0 - 100 +smoothing = 80 +# 瘦脸程度 0 - 100 +thinface = 20 +# 小脸程度 0 - 100 +shrink_face = 50 +# 大眼程度 0 - 100 +enlarge_eye = 50 +# 去眉毛程度 0 - 100 +remove_eyebrow = 50 +# 滤镜名称,不填写,默认无滤镜 +filter_type = '' + +# 二进制方式打开图片 +img_name = 'test_1.png' +f = open(img_name, 'rb') +# 转 base64 +img_base64 = base64.b64encode(f.read()) + +# 使用 whitening、smoothing、thinface 三个可选参数,其他用默认值 +data = { + 'api_key': AK, + 'api_secret': SK, + 'image_base64': img_base64, + 'whitening': whitening, + 'smoothing': smoothing, + 'thinface': thinface, + } + +r = requests.post(url=beautify_url, data=data) +html = json.loads(r.text) + +# 解析base64图片 +base64_data = html['result'] +imgData = base64.b64decode(base64_data) +nparr = np.frombuffer(imgData, np.uint8) +img_res = cv2.imdecode(nparr, cv2.IMREAD_COLOR) +img_res_BGR = cv2.cvtColor(img_res, cv2.COLOR_RGB2BGR) + +# 原始图片 +img = cv2.imread(img_name) +img_BGR = cv2.cvtColor(img, cv2.COLOR_RGB2BGR) + +# 显示图片 +fig, axs = plt.subplots(nrows=1, ncols=2, sharex=False, sharey=False, figsize=(10,10)) +axs[0].imshow(img_BGR) +axs[1].imshow(img_res_BGR) +plt.show() diff --git a/2020/api/test_1.png b/2020/api/test_1.png new file mode 100644 index 00000000..38e8def3 Binary files /dev/null and b/2020/api/test_1.png differ diff --git a/2020/bilibili/download.py b/2020/bilibili/download.py new file mode 100644 index 00000000..b8aff376 --- /dev/null +++ b/2020/bilibili/download.py @@ -0,0 +1,120 @@ +# -*-coding:utf-8 -*- +# Website: https://cuijiahua.com +# Author: Jack Cui +# Date: 2020年07月22日 +import requests +import json +import re +import json +import math +import xml2ass +import time +from contextlib import closing + +from bs4 import BeautifulSoup + +import os +from win32com.client import Dispatch + +def addTasktoXunlei(down_url): + flag = False + o = Dispatch('ThunderAgent.Agent64.1') + try: + o.AddTask(down_url, "", "", "", "", -1, 0, 5) + o.CommitTasks() + flag = True + except Exception: + print(Exception.message) + print(" AddTask is fail!") + return flag + +def get_download_url(arcurl): + # 微信搜索 JackCui-AI 关注公众号,后台回复「B 站」获取视频解析地址 + jiexi_url = 'xxx' + payload = {'url': arcurl} + jiexi_req = requests.get(jiexi_url, params=payload) + jiexi_bf = BeautifulSoup(jiexi_req.text) + jiexi_dn_url = jiexi_bf.iframe.get('src') + dn_req = requests.get(jiexi_dn_url) + dn_bf = BeautifulSoup(dn_req.text) + video_script = dn_bf.find('script',src = None) + DPlayer = str(video_script.string) + download_url = re.findall('\'(http[s]?:(?:[a-zA-Z]|[0-9]|[$-_@.&~+]|[!*\(\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+)\'', DPlayer)[0] + download_url = download_url.replace('\\', '') + return download_url + +space_url = 'https://space.bilibili.com/280793434' +search_url = 'https://api.bilibili.com/x/space/arc/search' +mid = space_url.split('/')[-1] +sess = requests.Session() +search_headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.167 Safari/537.36', + 'Accept-Language': 'zh-CN,zh;q=0.9', + 'Accept-Encoding': 'gzip, deflate, br', + 'Accept': 'application/json, text/plain, */*'} + +# 获取视频个数 +ps = 1 +pn = 1 +search_params = {'mid': mid, + 'ps': ps, + 'tid': 0, + 'pn': pn} +req = sess.get(url=search_url, headers=search_headers, params=search_params, verify=False) +info = json.loads(req.text) +video_count = info['data']['page']['count'] + +ps = 10 +page = math.ceil(video_count/ps) +videos_list = [] +for pn in range(1, page+1): + search_params = {'mid': mid, + 'ps': ps, + 'tid': 0, + 'pn': pn} + req = sess.get(url=search_url, headers=search_headers, params=search_params, verify=False) + info = json.loads(req.text) + vlist = info['data']['list']['vlist'] + for video in vlist: + title = video['title'] + bvid = video['bvid'] + vurl = 'https://www.bilibili.com/video/' + bvid + videos_list.append([title, vurl]) +print('共 %d 个视频' % len(videos_list)) +all_video = {} +# 下载前 10 个视频 +for video in videos_list[:10]: + download_url = get_download_url(video[1]) + print(video[0] + ':' + download_url) + # 记录视频名字 + xunlei_video_name = download_url.split('?')[0].split('/')[-1] + filename = video[0] + for c in u' ́☆❤◦\/:*?"| ': + filename = filename.replace(c, '') + save_video_name = filename + '.mp4' + all_video[xunlei_video_name] = save_video_name + + addTasktoXunlei(download_url) + # 弹幕下载 + danmu_name = filename + '.xml' + danmu_ass = filename + '.ass' + oid = download_url.split('/')[6] + danmu_url = 'https://api.bilibili.com/x/v1/dm/list.so?oid={}'.format(oid) + danmu_header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.167 Safari/537.36', + 'Accept': '*/*', + 'Accept-Encoding': 'gzip, deflate, br', + 'Accept-Language': 'zh-CN,zh;q=0.9'} + with closing(sess.get(danmu_url, headers=danmu_header, stream=True, verify=False)) as response: + if response.status_code == 200: + with open(danmu_name, 'wb') as file: + for data in response.iter_content(): + file.write(data) + file.flush() + else: + print('链接异常') + time.sleep(0.5) + xml2ass.Danmaku2ASS(danmu_name, danmu_ass, 1280, 720) +# 视频重命名 +for key, item in all_video.items(): + while key not in os.listdir('./'): + time.sleep(1) + os.rename(key, item) diff --git a/2020/bilibili/xml2ass.py b/2020/bilibili/xml2ass.py new file mode 100644 index 00000000..eac3f861 --- /dev/null +++ b/2020/bilibili/xml2ass.py @@ -0,0 +1,802 @@ +# The original author of this program, Danmaku2ASS, is StarBrilliant. +# This file is released under General Public License version 3. +# You should have received a copy of General Public License text alongside with +# this program. If not, you can obtain it at http://gnu.org/copyleft/gpl.html . +# This program comes with no warranty, the author will not be resopnsible for +# any damage or problems caused by this program. + +import argparse +import calendar +import gettext +import io +import json +import logging +import math +import os +import random +import re +import sys +import time +import xml.dom.minidom + + +if sys.version_info < (3,): + raise RuntimeError('at least Python 3.0 is required') + +gettext.install('danmaku2ass', os.path.join(os.path.dirname(os.path.abspath(os.path.realpath(sys.argv[0] or 'locale'))), 'locale')) + +def SeekZero(function): + def decorated_function(file_): + file_.seek(0) + try: + return function(file_) + finally: + file_.seek(0) + return decorated_function + + +def EOFAsNone(function): + def decorated_function(*args, **kwargs): + try: + return function(*args, **kwargs) + except EOFError: + return None + return decorated_function + + +@SeekZero +@EOFAsNone +def ProbeCommentFormat(f): + tmp = f.read(1) + if tmp == '[': + return 'Acfun' + # It is unwise to wrap a JSON object in an array! + # See this: http://haacked.com/archive/2008/11/20/anatomy-of-a-subtle-json-vulnerability.aspx/ + # Do never follow what Acfun developers did! + elif tmp == '{': + tmp = f.read(14) + if tmp == '"status_code":': + return 'Tudou' + elif tmp == '"root":{"total': + return 'sH5V' + elif tmp == '<': + tmp = f.read(1) + if tmp == '?': + tmp = f.read(38) + if tmp == 'xml version="1.0" encoding="UTF-8"?>+ 微信群 + 公众号 + B站 + 知乎 + CSDN + 头条 + 掘金 +
- 第三方依赖库安装: +## 声明 - pip3 install beautifulsoup4 +* 代码、教程**仅限于学习交流,请勿用于任何商业用途!** - 使用方法: +## 目录 - python biqukan.py +* [爬虫小工具](#爬虫小工具) + * [文件下载小助手](https://github.com/Jack-Cherish/python-spider/blob/master/downloader.py "悬停显示") +* [爬虫实战](#爬虫实战) + * [笔趣看小说下载](https://github.com/Jack-Cherish/python-spider/blob/master/biqukan.py "悬停显示") + * [百度文库免费文章下载助手_rev1](https://github.com/Jack-Cherish/python-spider/blob/master/baiduwenku.py "悬停显示") + * [百度文库免费文章下载助手_rev2](https://github.com/Jack-Cherish/python-spider/blob/master/baiduwenku_pro_1.py "悬停显示") + * [《帅啊》网帅哥图片下载](https://github.com/Jack-Cherish/python-spider/blob/master/shuaia.py "悬停显示") + * [构建代理IP池](https://github.com/Jack-Cherish/python-spider/blob/master/daili.py "悬停显示") + * [《火影忍者》漫画下载](https://github.com/Jack-Cherish/python-spider/tree/master/cartoon "悬停显示") + * [财务报表下载小助手](https://github.com/Jack-Cherish/python-spider/blob/master/financical.py "悬停显示") + * [一小时入门网络爬虫](https://github.com/Jack-Cherish/python-spider/tree/master/one_hour_spider "悬停显示") + * [抖音App视频下载](https://github.com/Jack-Cherish/python-spider/tree/master/douyin "悬停显示") + * [GEETEST验证码识别](https://github.com/Jack-Cherish/python-spider/blob/master/geetest.py "悬停显示") + * [12306抢票小助手](https://github.com/Jack-Cherish/python-spider/blob/master/12306.py "悬停显示") + * [百万英雄答题辅助系统](https://github.com/Jack-Cherish/python-spider/tree/master/baiwan "悬停显示") + * [网易云音乐免费音乐批量下载](https://github.com/Jack-Cherish/python-spider/tree/master/Netease "悬停显示") + * [B站免费视频和弹幕批量下载](https://github.com/Jack-Cherish/python-spider/tree/master/bilibili "悬停显示") + * [京东商品晒单图下载](https://github.com/Jack-Cherish/python-spider/tree/master/dingdong "悬停显示") + * [正方教务管理系统个人信息查询](https://github.com/Jack-Cherish/python-spider/tree/master/zhengfang_system_spider "悬停显示") +* [其它](#其它) -* video_downloader: 爱奇艺等主流视频网站的VIP视频破解助手(暂只支持PC和手机在线观看VIP视频!) +## 爬虫小工具 - 感谢Python3二维码生成器作者:https://github.com/sylnsfar/qrcode - - 编译好的软件下载连接:http://pan.baidu.com/s/1eR4Y7aM 解压密码:`c406495762` - - 无需Python3环境,在Windows下,解压即用 +* downloader.py:文件下载小助手 + + 一个可以用于下载图片、视频、文件的小工具,有下载进度显示功能。稍加修改即可添加到自己的爬虫中。 - 源码可查看`video_downloader`,运行源码需要搭建Python3环境,并安装相应第三方依赖库: + 动态示意图: - 在`video_downloader`文件夹下,安装第三方依赖库: + 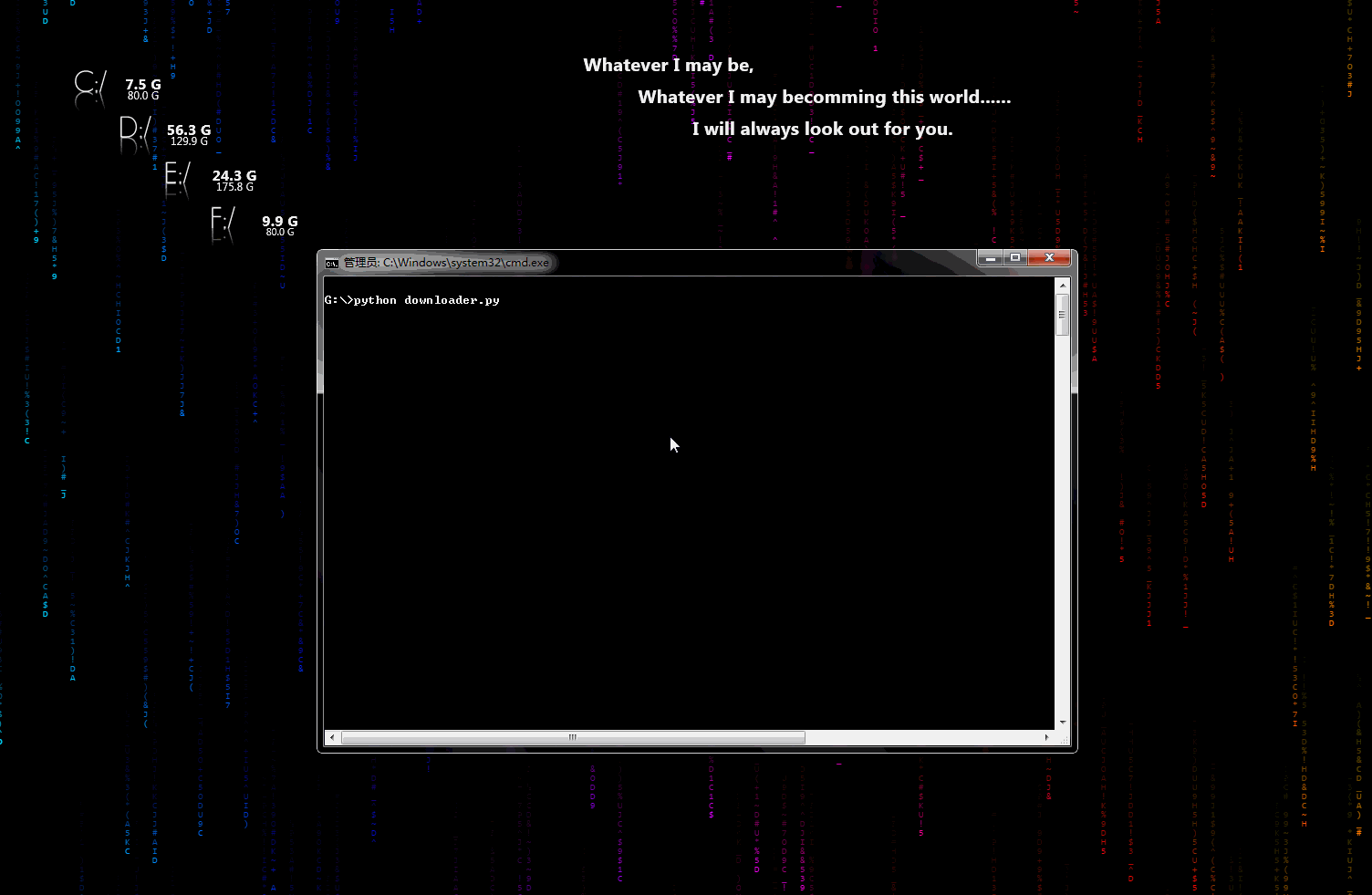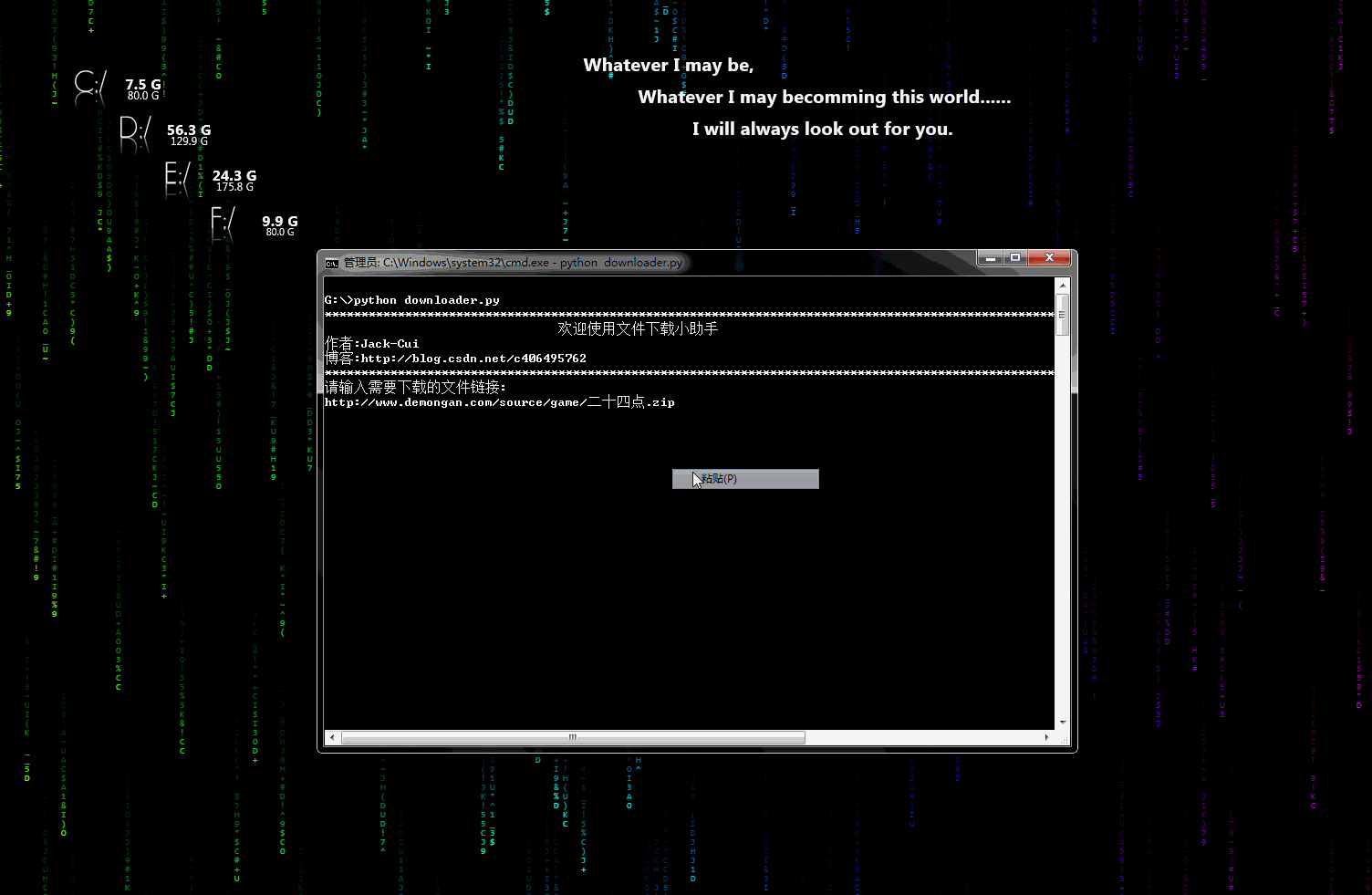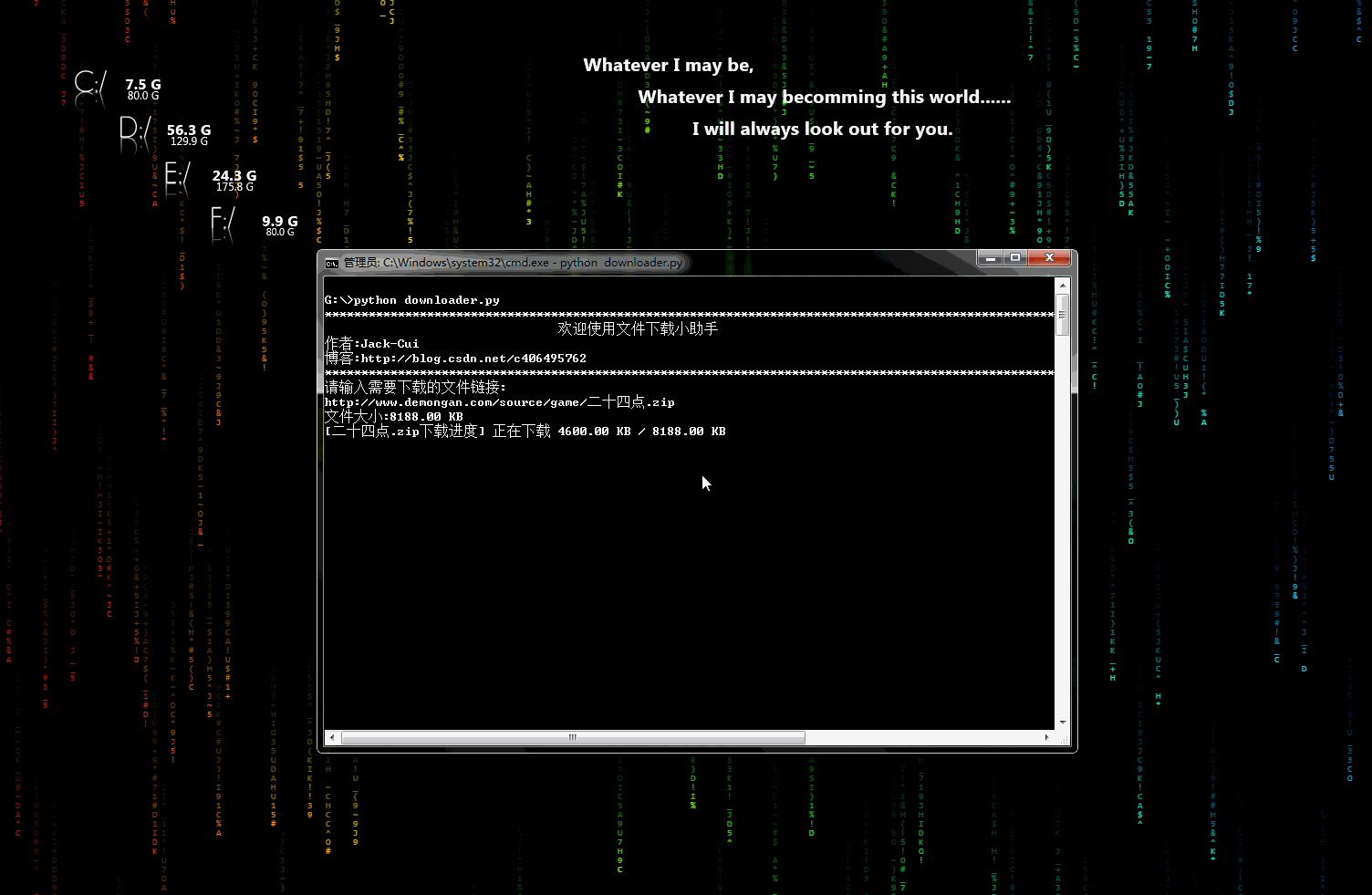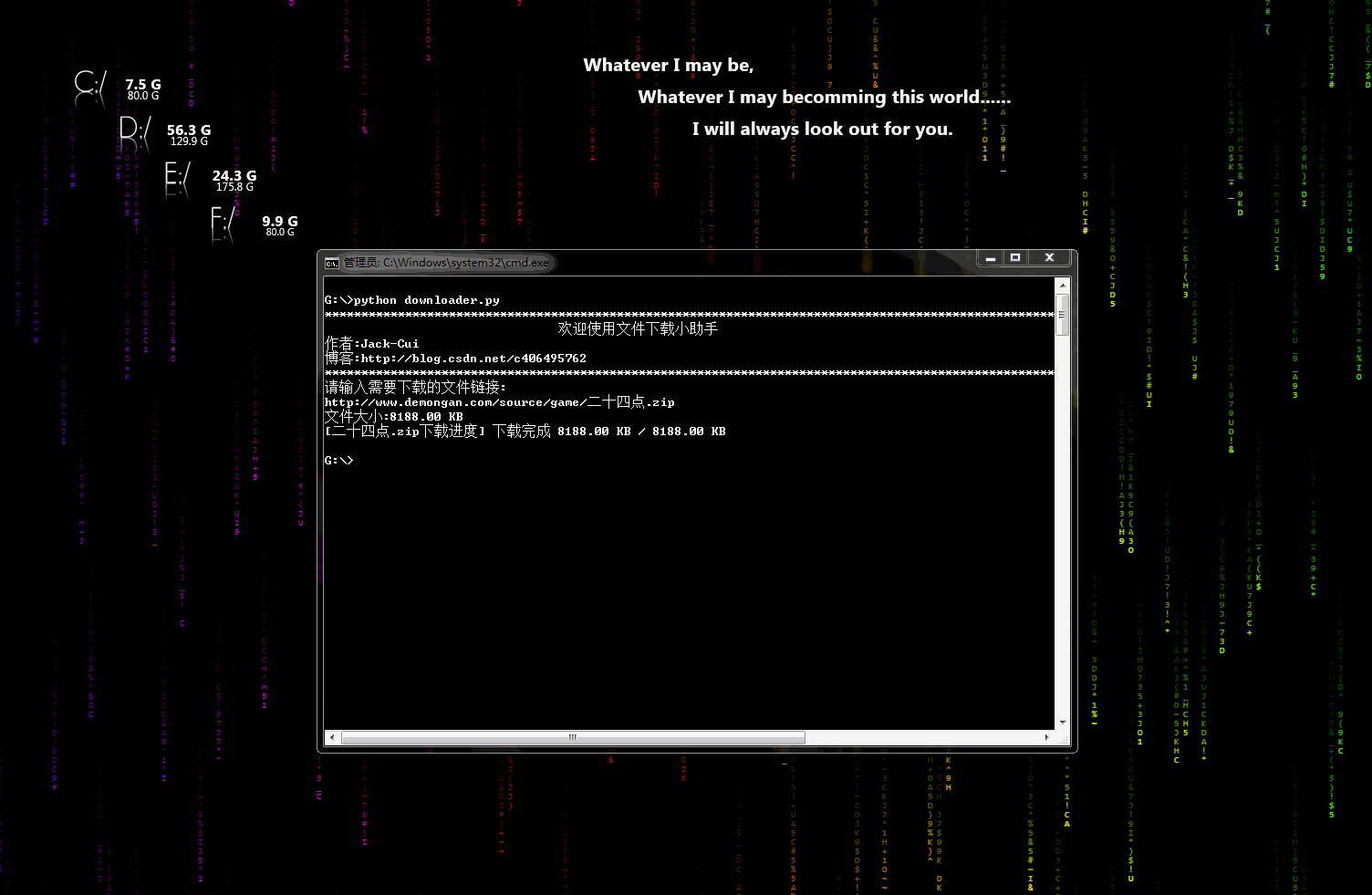 + +## 爬虫实战 + + * biqukan.py:《笔趣看》盗版小说网站,爬取小说工具 + + 第三方依赖库安装: - pip3 install -r requirements.txt + pip3 install beautifulsoup4 使用方法: - - python movie_downloader.py - 运行环境: - - Windows, Python3 - - Linux, Python3 - - Mac, Python3 + python biqukan.py -* baiduwenku.py: 百度文库word文章爬取 + * baiduwenku.py: 百度文库word文章爬取 原理说明:http://blog.csdn.net/c406495762/article/details/72331737 - 代码不完善,没有进行打包,不具通用性,纯属娱乐,以后有时间会完善。 + 代码不完善,没有进行打包,不具通用性,纯属娱乐。 -* shuaia.py: 爬取《帅啊》网,帅哥图片 + * shuaia.py: 爬取《帅啊》网,帅哥图片 《帅啊》网URL:http://www.shuaia.net/index.html @@ -64,12 +85,12 @@ pip3 install requests beautifulsoup4 -* daili.py: 构建代理IP池 + * daili.py: 构建代理IP池 原理说明:http://blog.csdn.net/c406495762/article/details/72793480 -* carton: 使用Scrapy爬取《火影忍者》漫画 + * carton: 使用Scrapy爬取《火影忍者》漫画 代码可以爬取整个《火影忍者》漫画所有章节的内容,保存到本地。更改地址,可以爬取其他漫画。保存地址可以在settings.py中修改。 @@ -77,10 +98,165 @@ 原理说明:http://blog.csdn.net/c406495762/article/details/72858983 + * hero.py: 《王者荣耀》推荐出装查询小助手 + + 网页爬取已经会了,想过爬取手机APP里的内容吗? + + 原理说明:http://blog.csdn.net/c406495762/article/details/76850843 + + * financical.py: 财务报表下载小助手 + + 爬取的数据存入数据库会吗?《跟股神巴菲特学习炒股之财务报表入库(MySQL)》也许能给你一些思路。 + + 原理说明:http://blog.csdn.net/c406495762/article/details/77801899 + 动态示意图: +  + * one_hour_spider:一小时入门Python3网络爬虫。 + + 原理说明: + + * 知乎:https://zhuanlan.zhihu.com/p/29809609 + * CSDN:http://blog.csdn.net/c406495762/article/details/78123502 + + 本次实战内容有: + + * 网络小说下载(静态网站)-biqukan + * 优美壁纸下载(动态网站)-unsplash + * 视频下载 + + * douyin.py:抖音App视频下载 + + 抖音App的视频下载,就是普通的App爬取。 + 原理说明: + * 个人网站:http://cuijiahua.com/blog/2018/03/spider-5.html + + * douyin_pro:抖音App视频下载(升级版) + + 抖音App的视频下载,添加视频解析网站,支持无水印视频下载,使用第三方平台解析。 + + 原理说明: + + * 个人网站:http://cuijiahua.com/blog/2018/03/spider-5.html + + * douyin:抖音App视频下载(升级版2) + + 抖音App的视频下载,添加视频解析网站,支持无水印视频下载,通过url解析,无需第三方平台。 + + 原理说明: + + * 个人网站:http://cuijiahua.com/blog/2018/03/spider-5.html + + 动态示意图: + +  + + * geetest.py:GEETEST验证码识别 + + 原理说明: + + 无 + + * 12306.py:用Python抢火车票简单代码 + + 可以自己慢慢丰富,蛮简单,有爬虫基础很好操作,没有原理说明。 + + * baiwan:百万英雄辅助答题 + + 效果图: + +  + + 原理说明: + + * 个人网站:http://cuijiahua.com/blog/2018/01/spider_3.html + + 功能介绍: + + 服务器端,使用Python(baiwan.py)通过抓包获得的接口获取答题数据,解析之后通过百度知道搜索接口匹配答案,将最终匹配的结果写入文件(file.txt)。 + + 手机抓包不会的朋友,可以看下我的早期[手机APP抓包教程](http://blog.csdn.net/c406495762/article/details/76850843 "悬停显示")。 + + Node.js(app.js)每隔1s读取一次file.txt文件,并将读取结果通过socket.io推送给客户端(index.html)。 + + 亲测答题延时在3s左右。 + + 声明:没做过后端和前端,花了一天时间,现学现卖弄好的,javascript也是现看现用,百度的程序,调试调试而已。可能有很多用法比较low的地方,用法不对,请勿见怪,有大牛感兴趣,可以自行完善。 + + * Netease:根据歌单下载网易云音乐 + + 效果图: + +  + + 原理说明: + + 暂无 + + 功能介绍: + + 根据music_list.txt文件里的歌单的信息下载网易云音乐,将自己喜欢的音乐进行批量下载。 + + * bilibili:B站视频和弹幕批量下载 + + 原理说明: + + 暂无 + + 使用说明: + + python bilibili.py -d 猫 -k 猫 -p 10 + + 三个参数: + -d 保存视频的文件夹名 + -k B站搜索的关键字 + -p 下载搜索结果前多少页 + + * jingdong:京东商品晒单图下载 + + 效果图: + +  + + 原理说明: + + 暂无 + + 使用说明: + + python jd.py -k 芒果 + + 三个参数: + -d 保存图片的路径,默认为fd.py文件所在文件夹 + -k 搜索关键词 + -n 下载商品的晒单图个数,即n个商店的晒单图 + + * zhengfang_system_spider:对正方教务管理系统个人课表,个人学生成绩,绩点等简单爬取 + + 效果图: + +  + + 原理说明: + + 暂无 + + 使用说明: + + cd zhengfang_system_spider + pip install -r requirements.txt + python spider.py + +## 其它 + + * 欢迎 Pull requests,感谢贡献。 + + 更多精彩,敬请期待! + +[画像:wechat] diff --git a/baiduwenku_pro_1.py b/baiduwenku_pro_1.py new file mode 100644 index 00000000..18a79459 --- /dev/null +++ b/baiduwenku_pro_1.py @@ -0,0 +1,101 @@ +import requests +import re +import json +import os + +session = requests.session() + + +def fetch_url(url): + return session.get(url).content.decode('gbk') + + +def get_doc_id(url): + return re.findall('view/(.*).html', url)[0] + + +def parse_type(content): + return re.findall(r"docType.*?\:.*?\'(.*?)\',円", content)[0] + + +def parse_title(content): + return re.findall(r"title.*?\:.*?\'(.*?)\',円", content)[0] + + +def parse_doc(content): + result = '' + url_list = re.findall('(https.*?0.json.*?)\\\\x22}', content) + url_list = [addr.replace("\\\\\\/", "/") for addr in url_list] + for url in url_list[:-5]: + content = fetch_url(url) + y = 0 + txtlists = re.findall('"c":"(.*?)".*?"y":(.*?),', content) + for item in txtlists: + if not y == item[1]: + y = item[1] + n = '\n' + else: + n = '' + result += n + result += item[0].encode('utf-8').decode('unicode_escape', 'ignore') + return result + + +def parse_txt(doc_id): + content_url = 'https://wenku.baidu.com/api/doc/getdocinfo?callback=cb&doc_id=' + doc_id + content = fetch_url(content_url) + md5 = re.findall('"md5sum":"(.*?)"', content)[0] + pn = re.findall('"totalPageNum":"(.*?)"', content)[0] + rsign = re.findall('"rsign":"(.*?)"', content)[0] + content_url = 'https://wkretype.bdimg.com/retype/text/' + doc_id + '?rn=' + pn + '&type=txt' + md5 + '&rsign=' + rsign + content = json.loads(fetch_url(content_url)) + result = '' + for item in content: + for i in item['parags']: + result += i['c'].replace('\\r', '\r').replace('\\n', '\n') + return result + + +def parse_other(doc_id): + content_url = "https://wenku.baidu.com/browse/getbcsurl?doc_id=" + doc_id + "&pn=1&rn=99999&type=ppt" + content = fetch_url(content_url) + url_list = re.findall('{"zoom":"(.*?)","page"', content) + url_list = [item.replace("\\", '') for item in url_list] + if not os.path.exists(doc_id): + os.mkdir(doc_id) + for index, url in enumerate(url_list): + content = session.get(url).content + path = os.path.join(doc_id, str(index) + '.jpg') + with open(path, 'wb') as f: + f.write(content) + print("图片保存在" + doc_id + "文件夹") + + +def save_file(filename, content): + with open(filename, 'w', encoding='utf8') as f: + f.write(content) + print('已保存为:' + filename) + + +# test_txt_url = 'https://wenku.baidu.com/view/cbb4af8b783e0912a3162a89.html?from=search' +# test_ppt_url = 'https://wenku.baidu.com/view/2b7046e3f78a6529657d5376.html?from=search' +# test_pdf_url = 'https://wenku.baidu.com/view/dd6e15c1227916888586d795.html?from=search' +# test_xls_url = 'https://wenku.baidu.com/view/eb4a5bb7312b3169a551a481.html?from=search' +def main(): + url = input('请输入要下载的文库URL地址') + content = fetch_url(url) + doc_id = get_doc_id(url) + type = parse_type(content) + title = parse_title(content) + if type == 'doc': + result = parse_doc(content) + save_file(title + '.txt', result) + elif type == 'txt': + result = parse_txt(doc_id) + save_file(title + '.txt', result) + else: + parse_other(doc_id) + + +if __name__ == "__main__": + main() diff --git a/baiwan/app.js b/baiwan/app.js new file mode 100644 index 00000000..9220fc16 --- /dev/null +++ b/baiwan/app.js @@ -0,0 +1,52 @@ +var http = require('http'); +var fs = require('fs'); +var schedule = require("node-schedule"); +var message = {}; +var count = 0; +var server = http.createServer(function (req,res){ + fs.readFile('./index.html',function(error,data){ + res.writeHead(200,{'Content-Type':'text/html'}); + res.end(data,'utf-8'); + }); +}).listen(80); +console.log('Server running!'); +var lineReader = require('line-reader'); +function messageGet(){ + lineReader.eachLine('file.txt', function(line, last) { + count++; + var name = 'line' + count; + console.log(name); + console.log(line); + message[name] = line; + }); + if(count == 25){ + count = 0; + } + else{ + for(var i = count+1; i <= 25; i++){ + var name = 'line' + i; + message[name] = 'f'; + } + count = 0; + } +} +var io = require('socket.io').listen(server); +var rule = new schedule.RecurrenceRule(); +var times = []; +for(var i=1; i<1800; i++){ + times.push(i); +} +rule.second = times; +schedule.scheduleJob(rule, function(){ + messageGet(); +}); +io.sockets.on('connection',function(socket){ + // console.log('User connected' + count + 'user(s) present'); + socket.emit('users',message); + socket.broadcast.emit('users',message); + + socket.on('disconnect',function(){ + console.log('User disconnected'); + //socket.broadcast.emit('users',message); + }); +}); diff --git a/baiwan/baiwan.py b/baiwan/baiwan.py new file mode 100644 index 00000000..50d0ec18 --- /dev/null +++ b/baiwan/baiwan.py @@ -0,0 +1,169 @@ +# -*-coding:utf-8 -*- +import requests +from lxml import etree +from bs4 import BeautifulSoup +import urllib +import time, re, types, os + + +""" +代码写的匆忙,本来想再重构下,完善好注释再发,但是比较忙,想想算了,所以自行完善吧!写法很不规范,勿见怪。 + +作者: Jack Cui +Website:http://cuijiahua.com +注: 本软件仅用于学习交流,请勿用于任何商业用途! +""" + +class BaiWan(): + def __init__(self): + # 百度知道搜索接口 + self.baidu = 'http://zhidao.baidu.com/search?' + # 百万英雄及接口,每个人的接口都不一样,里面包含的手机信息,因此不公布,请自行抓包,有疑问欢迎留言:http://cuijiahua.com/liuyan.html + self.api = 'https://api-spe-ttl.ixigua.com/xxxxxxx={}'.format(int(time.time()*1000)) + + # 获取答案并解析问题 + def get_question(self): + to = True + while to: + list_dir = os.listdir('./') + if 'question.txt' not in list_dir: + fw = open('question.txt', 'w') + fw.write('百万英雄尚未出题请稍后!') + fw.close() + go = True + while go: + req = requests.get(self.api, verify=False) + req.encoding = 'utf-8' + html = req.text + + print(html) + if '*' in html: + question_start = html.index('*') + try: + + question_end = html.index('?') + except: + question_end = html.index('?') + question = html[question_start:question_end][2:] + if question != None: + fr = open('question.txt', 'r') + text = fr.readline() + fr.close() + if text != question: + print(question) + go = False + with open('question.txt', 'w') as f: + f.write(question) + else: + time.sleep(1) + else: + to = False + else: + to = False + + temp = re.findall(r'[\u4e00-\u9fa5a-zA-Z0-9\+\-\*/]', html[question_end+1:]) + b_index = [] + print(temp) + + for index, each in enumerate(temp): + if each == 'B': + b_index.append(index) + elif each == 'P' and (len(temp) - index) <= 3 : + b_index.append(index) + break + + if len(b_index) == 4: + a = ''.join(temp[b_index[0] + 1:b_index[1]]) + b = ''.join(temp[b_index[1] + 1:b_index[2]]) + c = ''.join(temp[b_index[2] + 1:b_index[3]]) + alternative_answers = [a,b,c] + + if '下列' in question: + question = a + ' ' + b + ' ' + c + ' ' + question.replace('下列', '') + elif '以下' in question: + question = a + ' ' + b + ' ' + c + ' ' + question.replace('以下', '') + else: + alternative_answers = [] + # 根据问题和备选答案搜索答案 + self.search(question, alternative_answers) + time.sleep(1) + + def search(self, question, alternative_answers): + print(question) + print(alternative_answers) + infos = {"word":question} + # 调用百度接口 + url = self.baidu + 'lm=0&rn=10&pn=0&fr=search&ie=gbk&' + urllib.parse.urlencode(infos, encoding='GB2312') + print(url) + headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.86 Safari/537.36', + } + sess = requests.Session() + req = sess.get(url = url, headers=headers, verify=False) + req.encoding = 'gbk' + # print(req.text) + bf = BeautifulSoup(req.text, 'lxml') + answers = bf.find_all('dd',class_='dd answer') + for answer in answers: + print(answer.text) + + # 推荐答案 + recommend = '' + if alternative_answers != []: + best = [] + print('\n') + for answer in answers: + # print(answer.text) + for each_answer in alternative_answers: + if each_answer in answer.text: + best.append(each_answer) + print(each_answer,end=' ') + # print(answer.text) + print('\n') + break + statistics = {} + for each in best: + if each not in statistics.keys(): + statistics[each] = 1 + else: + statistics[each] += 1 + errors = ['没有', '不是', '不对', '不正确','错误','不包括','不包含','不在','错'] + error_list = list(map(lambda x: x in question, errors)) + print(error_list) + if sum(error_list)>= 1: + for each_answer in alternative_answers: + if each_answer not in statistics.items(): + recommend = each_answer + print('推荐答案:', recommend) + break + elif statistics != {}: + recommend = sorted(statistics.items(), key=lambda e:e[1], reverse=True)[0][0] + print('推荐答案:', recommend) + + # 写入文件 + with open('file.txt', 'w') as f: + f.write('问题:' + question) + f.write('\n') + f.write('*' * 50) + f.write('\n') + if alternative_answers != []: + f.write('选项:') + for i in range(len(alternative_answers)): + f.write(alternative_answers[i]) + f.write(' ') + f.write('\n') + f.write('*' * 50) + f.write('\n') + f.write('参考答案:\n') + for answer in answers: + f.write(answer.text) + f.write('\n') + f.write('*' * 50) + f.write('\n') + if recommend != '': + f.write('最终答案请自行斟酌!\t') + f.write('推荐答案:' + sorted(statistics.items(), key=lambda e:e[1], reverse=True)[0][0]) + + +if __name__ == '__main__': + bw = BaiWan() + bw.get_question() \ No newline at end of file diff --git a/baiwan/file.txt b/baiwan/file.txt new file mode 100644 index 00000000..2f1d34a3 --- /dev/null +++ b/baiwan/file.txt @@ -0,0 +1,21 @@ +���⣺�������Ǽ��1⁄4��� +************************************************** +ѡ�7��23�� 8��1�� 10��1�� +************************************************** +�ο��𰸣� + +�Ƽ����� +��������8��1�� ÿ���İ���һ�����й��������ž����������գ�����Ҳ�С���һ�������ڡ� August 1, anniversary of the founding of the Chinese People's Liberation Army��֪�������Ⱦ��������뵽���http://baike.baidu.com/view/23211.htm +[��ϸ] + +�������ã��й��������ž��Ľ�������ÿ���İ���һ�գ����ư�һ�����ڣ������İ�һ�պ����������� +�𣺽�������8��1�գ���������7��1�ա� ÿ����8��1�����й��������ž����������գ��׳ơ���һ�������ڡ�1927��8��1�գ��й����������챱�����������x����ܶ��� ������ ��Ҷͦ ������ ����е��쵼�£��ڽ����ς�������װ���壬���췴�Թ�������... +������7��30�� +�𣺰���һ���ǽ����ڣ�ǰһ�첻��7��31��ô +����1927��8��1������һ���ς�����,�������й���������װ�����������ɵĵ�һǹ,��־���й��������й������������쵼��װ��������ɦ��,��־���й����͵��������ӵĵ�����ÿ���İ���һ�����й��������ž����������� +��������Դ���й�����������������ɦ���й����������쵼���ς����塣1927��8��1�յ��ς����壬�������й���������װ�����������ɵĵ�һǹ����־���й��������й������������쵼��װ��������ɦ�ڣ���־���й����͵��������ӵĵ����� 1933��7�£�... +����Ԫ��1��1��������8��1��������10��1�� +�𣺰���һ�Ž����� +���������� 2015��8��1�� ũ�� ����ʮ�� ������ 2016��8��1�� ũ�� ����إ�� ������ ÿ���İ���һ�����й��������ž����������գ�����Ҳ�С���һ�������ڡ�1933��7��11�գ��л���ά��������ɦ������������������������ίԱ��6��30�յĽ��飬����8��1... +************************************************** +���մ������������ã� �Ƽ��𰸣�8��1�� \ No newline at end of file diff --git a/baiwan/index.html b/baiwan/index.html new file mode 100644 index 00000000..4625d193 --- /dev/null +++ b/baiwan/index.html @@ -0,0 +1,219 @@ + + + + + +(.+?)<\/p>')
+ nickname = _nickname_re.search(share_user.text).group(1)
+ data = {
+ 'tac': tac.split('|')[0],
+ 'user_id': user_id,
+ }
+ req = requests.post(sign_api, data=data)
+ while req.status_code != 200:
+ req = requests.post(sign_api, data=data)
+ sign = req.json().get('signature')
+ user_url_prefix = 'https://www.iesdouyin.com/web/api/v2/aweme/like' if type_flag == 'f' else 'https://www.iesdouyin.com/web/api/v2/aweme/post'
+ print('解析视频链接中')
+ while has_more != 0:
+ user_url = user_url_prefix + '/?user_id=%s&sec_uid=&count=21&max_cursor=%s&aid=1128&_signature=%s&dytk=%s' % (user_id, max_cursor, sign, dytk)
+ req = requests.get(user_url, headers=self.headers)
+ while req.status_code != 200:
+ req = requests.get(user_url, headers=self.headers)
+ html = json.loads(req.text)
+ for each in html['aweme_list']:
+ try:
+ url = 'https://aweme.snssdk.com/aweme/v1/play/?video_id=%s&line=0&ratio=720p&media_type=4&vr_type=0&improve_bitrate=0&is_play_url=1&is_support_h265=0&source=PackSourceEnum_PUBLISH'
+ vid = each['video']['vid']
+ video_url = url % vid
+ except:
+ continue
+ share_desc = each['desc']
+ if os.name == 'nt':
+ for c in r'\/:*?"|':
+ nickname = nickname.replace(c, '').strip().strip('\.')
+ share_desc = share_desc.replace(c, '').strip()
+ share_id = each['aweme_id']
+ if share_desc in ['抖音-原创音乐短视频社区', 'TikTok', '']:
+ video_names.append(share_id + '.mp4')
+ else:
+ video_names.append(share_id + '-' + share_desc + '.mp4')
+ share_url = 'https://www.iesdouyin.com/share/video/%s' % share_id
+ share_urls.append(share_url)
+ video_urls.append(video_url)
+ max_cursor = html['max_cursor']
+ has_more = html['has_more']
+
+ return video_names, video_urls, share_urls, nickname
+
+ def get_download_url(self, video_url, watermark_flag):
+ """
+ 获得带水印的视频播放地址
+ Parameters:
+ video_url:带水印的视频播放地址
+ Returns:
+ download_url: 带水印的视频下载地址
+ """
+ # 带水印视频
+ if watermark_flag == True:
+ download_url = video_url.replace('/play/', '/playwm/')
+ # 无水印视频
+ else:
+ download_url = video_url.replace('/playwm/', '/play/')
+
+ return download_url
+
+ def video_downloader(self, video_url, video_name, watermark_flag=False):
+ """
+ 视频下载
+ Parameters:
+ video_url: 带水印的视频地址
+ video_name: 视频名
+ watermark_flag: 是否下载带水印的视频
+ Returns:
+ 无
+ """
+ size = 0
+ video_url = self.get_download_url(video_url, watermark_flag=watermark_flag)
+ with closing(requests.get(video_url, headers=self.headers1, stream=True)) as response:
+ chunk_size = 1024
+ content_size = int(response.headers['content-length'])
+ if response.status_code == 200:
+ sys.stdout.write(' [文件大小]:%0.2f MB\n' % (content_size / chunk_size / 1024))
+
+ with open(video_name, 'wb') as file:
+ for data in response.iter_content(chunk_size = chunk_size):
+ file.write(data)
+ size += len(data)
+ file.flush()
+
+ sys.stdout.write(' [下载进度]:%.2f%%' % float(size / content_size * 100) + '\r')
+ sys.stdout.flush()
+
+ def run(self):
+ """
+ 运行函数
+ Parameters:
+ None
+ Returns:
+ None
+ """
+ self.hello()
+ print('UID取得方式:\n分享用户页面,用浏览器打开短链接,原始链接中/share/user/后的数字即是UID')
+ user_id = input('请输入UID (例如60388937600):')
+ user_id = user_id if user_id else '60388937600'
+ watermark_flag = input('是否下载带水印的视频 (0-否(默认), 1-是):')
+ watermark_flag = watermark_flag if watermark_flag!='' else '0'
+ watermark_flag = bool(int(watermark_flag))
+ type_flag = input('f-收藏的(默认), p-上传的:')
+ type_flag = type_flag if type_flag!='' else 'f'
+ save_dir = input('保存路径 (例如"E:/Download/", 默认"./Download/"):')
+ save_dir = save_dir if save_dir else "./Download/"
+ video_names, video_urls, share_urls, nickname = self.get_video_urls(user_id, type_flag)
+ nickname_dir = os.path.join(save_dir, nickname)
+ if not os.path.exists(save_dir):
+ os.makedirs(save_dir)
+ if nickname not in os.listdir(save_dir):
+ os.mkdir(nickname_dir)
+ if type_flag == 'f':
+ if 'favorite' not in os.listdir(nickname_dir):
+ os.mkdir(os.path.join(nickname_dir, 'favorite'))
+ print('视频下载中:共有%d个作品!\n' % len(video_urls))
+ for num in range(len(video_urls)):
+ print(' 解析第%d个视频链接 [%s] 中,请稍后!\n' % (num + 1, share_urls[num]))
+ if '\\' in video_names[num]:
+ video_name = video_names[num].replace('\\', '')
+ elif '/' in video_names[num]:
+ video_name = video_names[num].replace('/', '')
+ else:
+ video_name = video_names[num]
+ video_path = os.path.join(nickname_dir, video_name) if type_flag!='f' else os.path.join(nickname_dir, 'favorite', video_name)
+ if os.path.isfile(video_path):
+ print('视频已存在')
+ else:
+ self.video_downloader(video_urls[num], video_path, watermark_flag)
+ print('\n')
+ print('下载完成!')
+
+ def hello(self):
+ """
+ 打印欢迎界面
+ Parameters:
+ None
+ Returns:
+ None
+ """
+ print('*' * 100)
+ print('\t\t\t\t抖音App视频下载小助手')
+ print('\t\t作者:Jack Cui、steven7851')
+ print('*' * 100)
+
+
+if __name__ == '__main__':
+ douyin = DouYin()
+ douyin.run()
diff --git a/douyin/fuck-byted-acrawler.js b/douyin/fuck-byted-acrawler.js
new file mode 100644
index 00000000..66be77c8
--- /dev/null
+++ b/douyin/fuck-byted-acrawler.js
@@ -0,0 +1,194 @@
+// Referer:https://raw.githubusercontent.com/loadchange/amemv-crawler/master/fuck-byted-acrawler.js
+function generateSignature(userId) {
+ this.navigator = {
+ userAgent: "Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1"
+ }
+ var e = {}
+
+ var r = (function () {
+ function e(e, a, r) {
+ return (b[e] || (b[e] = t("x,y", "return x " + e + " y")))(r, a)
+ }
+
+ function a(e, a, r) {
+ return (k[r] || (k[r] = t("x,y", "return new x[y](" + Array(r + 1).join(",x[++y]").substr(1) + ")")))(e, a)
+ }
+
+ function r(e, a, r) {
+ var n, t, s = {}, b = s.d = r ? r.d + 1 : 0;
+ for (s["$" + b] = s, t = 0; t < b; t++) s[n = "$" + t] = r[n]; + for (t = 0, b = s.length = a.length; t < b; t++) s[t] = a[t]; + return c(e, 0, s) + } + + function c(t, b, k) { + function u(e) { + v[x++] = e + } + + function f() { + return g = t.charCodeAt(b++) - 32, t.substring(b, b += g) + } + + function l() { + try { + y = c(t, b, k) + } catch (e) { + h = e, y = l + } + } + + for (var h, y, d, g, v = [], x = 0; ;) switch (g = t.charCodeAt(b++) - 32) { + case 1: + u(!v[--x]); + break; + case 4: + v[x++] = f(); + break; + case 5: + u(function (e) { + var a = 0, r = e.length; + return function () { + var c = a < r; + return c && u(e[a++]), c + } + }(v[--x])); + break; + case 6: + y = v[--x], u(v[--x](y)); + break; + case 8: + if (g = t.charCodeAt(b++) - 32, l(), b += g, g = t.charCodeAt(b++) - 32, y === c) b += g; else if (y !== l) return y; + break; + case 9: + v[x++] = c; + break; + case 10: + u(s(v[--x])); + break; + case 11: + y = v[--x], u(v[--x] + y); + break; + case 12: + for (y = f(), d = [], g = 0; g < y.length; g++) d[g] = y.charCodeAt(g) ^ g + y.length; + u(String.fromCharCode.apply(null, d)); + break; + case 13: + y = v[--x], h = delete v[--x][y]; + break; + case 14: + v[x++] = t.charCodeAt(b++) - 32; + break; + case 59: + u((g = t.charCodeAt(b++) - 32) ? (y = x, v.slice(x -= g, y)) : []); + break; + case 61: + u(v[--x][t.charCodeAt(b++) - 32]); + break; + case 62: + g = v[--x], k[0] = 65599 * k[0] + k[1].charCodeAt(g)>>> 0;
+ break;
+ case 65:
+ h = v[--x], y = v[--x], v[--x][y] = h;
+ break;
+ case 66:
+ u(e(t[b++], v[--x], v[--x]));
+ break;
+ case 67:
+ y = v[--x], d = v[--x], u((g = v[--x]).x === c ? r(g.y, y, k) : g.apply(d, y));
+ break;
+ case 68:
+ u(e((g = t[b++]) < "<" ? (b--, f()) : g + g, v[--x], v[--x])); + break; + case 70: + u(!1); + break; + case 71: + v[x++] = n; + break; + case 72: + v[x++] = +f(); + break; + case 73: + u(parseInt(f(), 36)); + break; + case 75: + if (v[--x]) { + b++; + break + } + case 74: + g = t.charCodeAt(b++) - 32 << 16>> 16, b += g;
+ break;
+ case 76:
+ u(k[t.charCodeAt(b++) - 32]);
+ break;
+ case 77:
+ y = v[--x], u(v[--x][y]);
+ break;
+ case 78:
+ g = t.charCodeAt(b++) - 32, u(a(v, x -= g + 1, g));
+ break;
+ case 79:
+ g = t.charCodeAt(b++) - 32, u(k["$" + g]);
+ break;
+ case 81:
+ h = v[--x], v[--x][f()] = h;
+ break;
+ case 82:
+ u(v[--x][f()]);
+ break;
+ case 83:
+ h = v[--x], k[t.charCodeAt(b++) - 32] = h;
+ break;
+ case 84:
+ v[x++] = !0;
+ break;
+ case 85:
+ v[x++] = void 0;
+ break;
+ case 86:
+ u(v[x - 1]);
+ break;
+ case 88:
+ h = v[--x], y = v[--x], v[x++] = h, v[x++] = y;
+ break;
+ case 89:
+ u(function () {
+ function e() {
+ return r(e.y, arguments, k)
+ }
+
+ return e.y = f(), e.x = c, e
+ }());
+ break;
+ case 90:
+ v[x++] = null;
+ break;
+ case 91:
+ v[x++] = h;
+ break;
+ case 93:
+ h = v[--x];
+ break;
+ case 0:
+ return v[--x];
+ default:
+ u((g << 16>> 16) - 16)
+ }
+ }
+
+ var n = this, t = n.Function, s = Object.keys || function (e) {
+ var a = {}, r = 0;
+ for (var c in e) a[r++] = c;
+ return a.length = r, a
+ }, b = {}, k = {};
+ return r
+ })()
+ ('gr$Daten Иb/s!l y͒yĹg,(lfi~ah`{mv,-n|jqewVxp{rvmmx,&effkx[!cs"l".Pq%widthl"@q&heightl"vr*getContextx$"2d[!cs#l#,*;?|u.|uc{uq$fontl#vr(fillTextx$$龘ฑภ경2<[#c}l#2q*shadowblurl#1q-shadowoffsetxl#$$limeq+shadowcolorl#vr#arcx88802[%c}l#vr&strokex[ c}l"v,)}eOmyoZB]mx[ cs!0s$l$Pb
||
')
+ rmtr = re.compile(' ||
{kind=link}
{kind=link}