You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
Running this Script would allow the user to scrape any number of articles from [dev.to](https://dev.to/) from any category as per the user's choice
3
+
4
+
## Setup instructions
5
+
In order to run this script, you need to have Python and pip installed on your system. After you're done installing Python and pip, run the following command from your terminal to install the requirements from the same folder (directory) of the project.
6
+
```
7
+
pip install -r requirements.txt
8
+
```
9
+
As this script uses selenium, you will need to install the chrome webdriver from [this link](https://sites.google.com/a/chromium.org/chromedriver/downloads)
10
+
11
+
After satisfying all the requirements for the project, Open the terminal in the project folder and run
12
+
```
13
+
python scraper.py
14
+
```
15
+
or
16
+
```
17
+
python3 scraper.py
18
+
```
19
+
depending upon the python version. Make sure that you are running the command from the same virtual environment in which the required modules are installed.
20
+
21
+
## Output
22
+
The user needs to enter Category and Number of articles
23
+
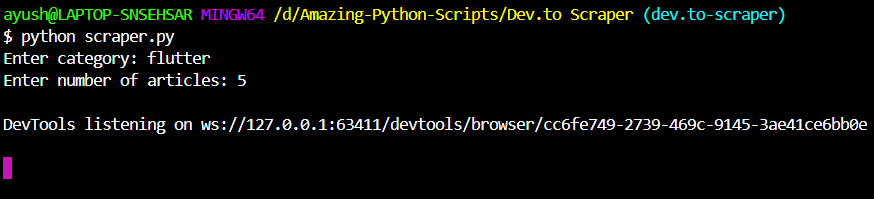
24
+
25
+
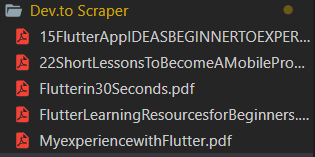
The scraped pdf files get saved in the folder in which the script is run
26
+
0 commit comments