From 309e30598b892300748e02975eb820c451d7663c Mon Sep 17 00:00:00 2001
From: Chorong0824 <124541156+sjmun09@users.noreply.github.com>
Date: Wed, 1 Oct 2025 00:29:44 +0900
Subject: [PATCH 1/8] docs : DNS
---
seongjun/DNS.md | 1 +
1 file changed, 1 insertion(+)
create mode 100644 seongjun/DNS.md
diff --git a/seongjun/DNS.md b/seongjun/DNS.md
new file mode 100644
index 0000000..8b13789
--- /dev/null
+++ b/seongjun/DNS.md
@@ -0,0 +1 @@
+
From 63074437ed001c47d596657eba0cdf9dfe2c114b Mon Sep 17 00:00:00 2001
From: Chorong0824 <124541156+sjmun09@users.noreply.github.com>
Date: Thu, 9 Oct 2025 18:33:19 +0900
Subject: [PATCH 2/8] =?UTF-8?q?docs=20:=20=EB=8F=99=EA=B8=B0=EC=99=80=20?=
=?UTF-8?q?=EB=B9=84=EB=8F=99=EA=B8=B0=20=EC=B0=A8=EC=9D=B4?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
...0_353円271円204円353円217円231円352円270円260円.md" | 300 ++++++++++++++++++
1 file changed, 300 insertions(+)
create mode 100644 "seongjun/353円217円231円352円270円260円_353円271円204円353円217円231円352円270円260円.md"
diff --git "a/seongjun/353円217円231円352円270円260円_353円271円204円353円217円231円352円270円260円.md" "b/seongjun/353円217円231円352円270円260円_353円271円204円353円217円231円352円270円260円.md"
new file mode 100644
index 0000000..c444775
--- /dev/null
+++ "b/seongjun/353円217円231円352円270円260円_353円271円204円353円217円231円352円270円260円.md"
@@ -0,0 +1,300 @@
+
+
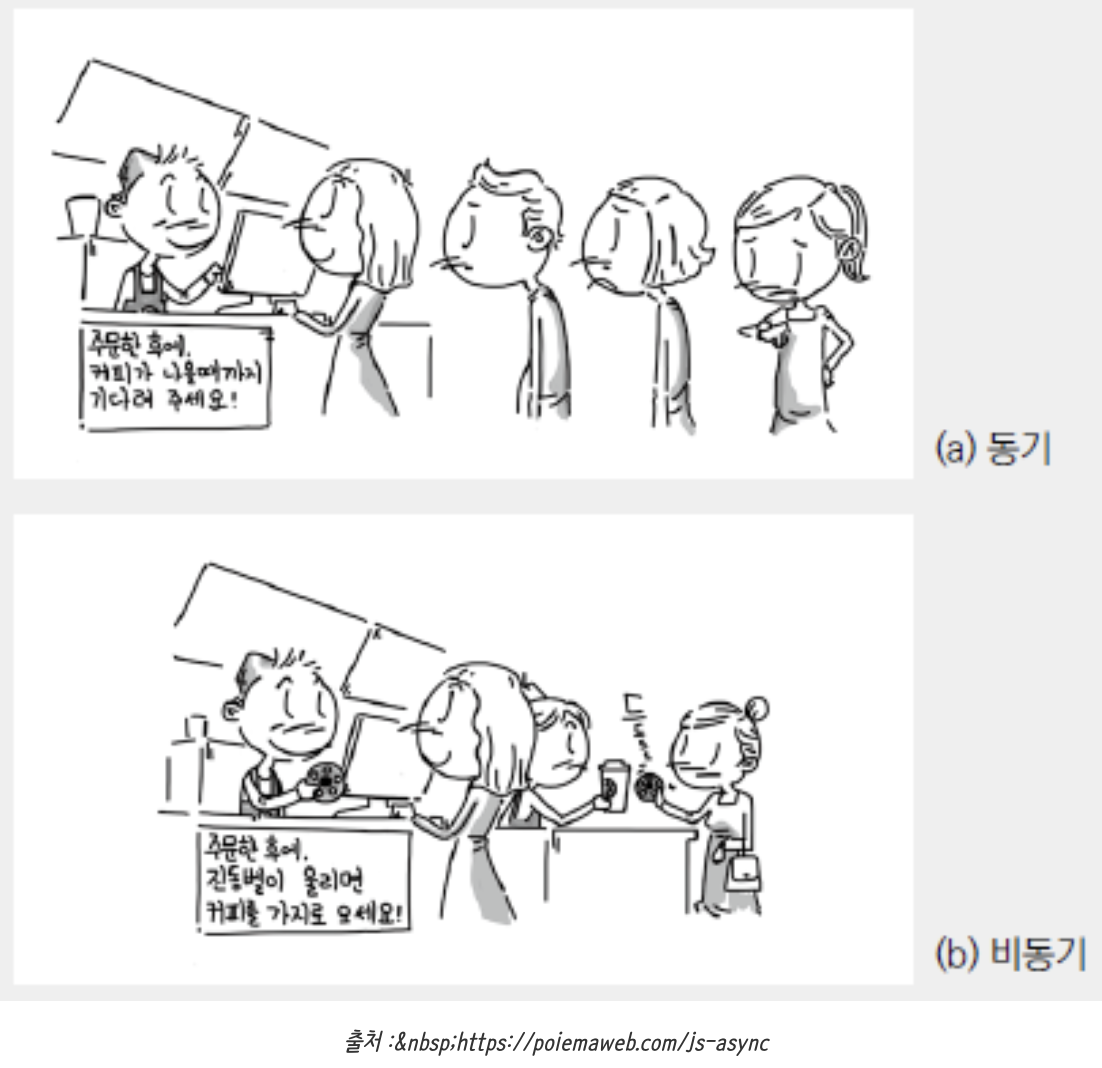
+### 1. 동기(Synchronous : 동시에 일어나는)
+#### Synch = 동시에, 동기화 (보통 Sync로 표현함)
+를 알아두면 좋다.
+
+- 동기는 말 그대로 동시에 일어난다는 뜻이다. 요청과 그 결과가 동시에 일어난다는 약속이다.
+
+요청을 하면 시간이 얼마나 걸리던지 요청한 바로 그 자리에서 결과가 주어져야 한다.
+순서에 맞춰 진행된다는 장점이 있지만, 여러가지 요청을 동시에 처리할 수 없다.
+
+위 그림의 (a)처럼 커피 주문을 받고 나올 때까지 기다리는 것이 동기 방식의 대표적인 예시다.
+
+
+
+### 비동기(Asynchronous: 동시에 일어나지 않는)
+#### 보통 'async' 이런 식으로 짧게 표현한다.
+- 비동기는 동시에 일어나지 않는다를 의미한다. 즉, 요청과 결과가 동시에 일어나지 않을 것이라는 약속이다.
+
+하나의 요청에 따른 응답을 즉시 처리하지 않고, 그 대기 시간동안 또 다른 요청에 대해 처리 가능한 방식이다.
+여러 개의 요청을 동시에 처리할 수 있는 장점이 있지만 동기 방식보다 속도가 떨어질 수도 있다.
+
+위 그림의 (b)처럼 점원 한 명이 커피 주문을 받고 다른 점원이 커피를 건네주는 것이 비동기 방식의 예시다.
+
+> 우리는 일상에 생각보다 많이 동기/비동기적으로 살아가고 있다.
+카페, 식당이 비동기 처리의 대표적인 예시다.
+동기 처리는 편의점 계산이라고 보면 된다.
+내가 결제할 물품을 계산대에 올려 계산하기까지 그 결과를 기다리기 때문이다.
+
+#### 동기와 비동기는 상황에 따라서 각각의 장단점이 있다.
+
+정답은 없다.
+- 동기방식은 설계가 매우 간단하고 직관적이지만 결과가 주어질 때까지 아무것도 못하고 대기해야 하는 단점이 있고,
+- 비동기방식은 동기보다 복잡하지만 결과가 주어지는데 시간이 걸리더라도 그 시간 동안 작업을 할 수 있으므로 자원을 효율적으로 사용할 수 있는 장점이 있다.
+
+
+
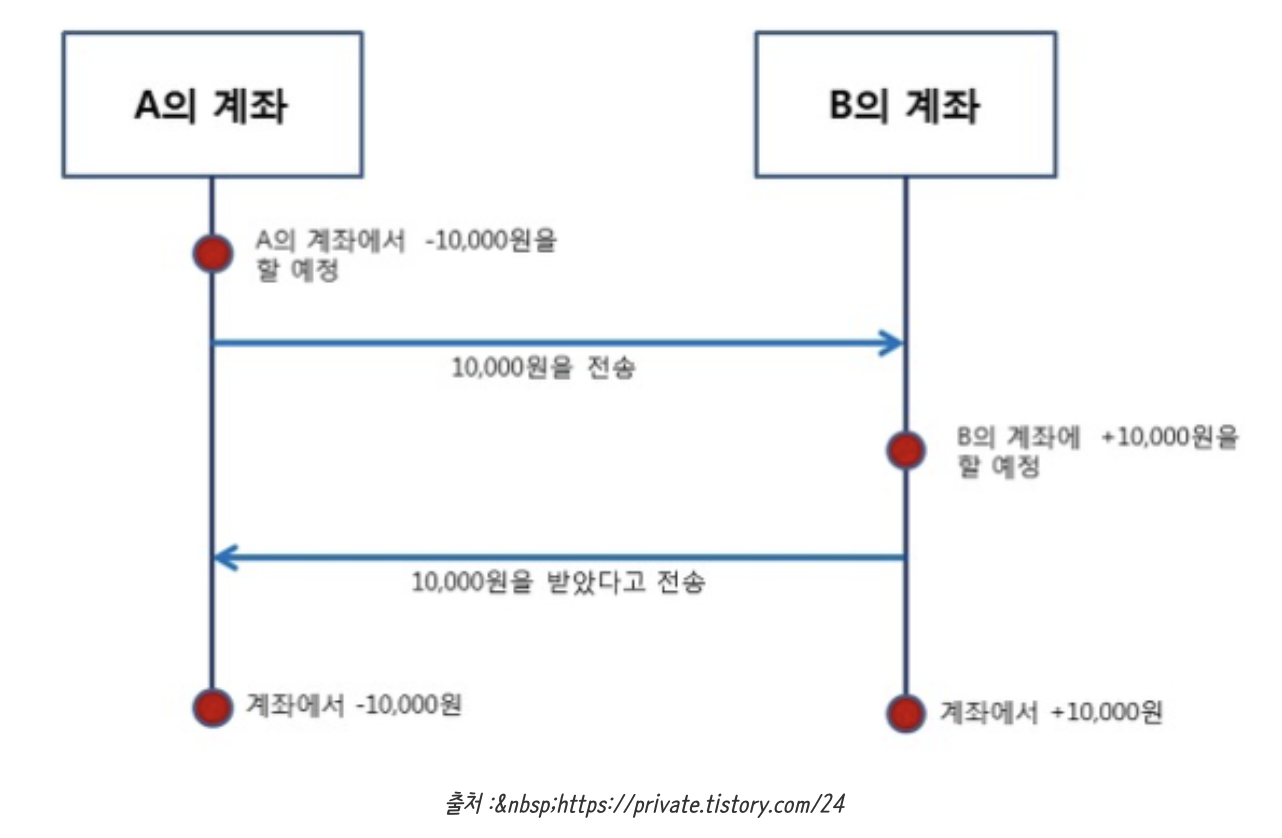
+
+
+1. A의 계좌는 10,000원을 뺄 생각을 하고 있다.
+2. A의 계좌가 B의 계좌에 10,000원을 송금한다.
+3. B의 계좌는 10,000원을 받았다는 걸 인지하고, A의 계좌에 10,000원을 받았다고 전송한다.
+4. A, B 계좌 각각 차감과 증가가 동시에 발생한다.
+
+- A의 계좌와 B의 계좌는 서로 요청과 응답(1~3번 과정)을 확인한 후 같은 일을 동시에 진행했다.(4번 과정)
+
+'계좌이체'같은 작업은 동기방식으로 처리해야 A에서 보냈는데 B에서 못 받는 상황이 없을 것이다.
+
+반대로 비동기 방식은 위의 예제처럼 노드 사이의 작업 처리 단위를 동시에 맞추지 않아도 된다.
+
+
+
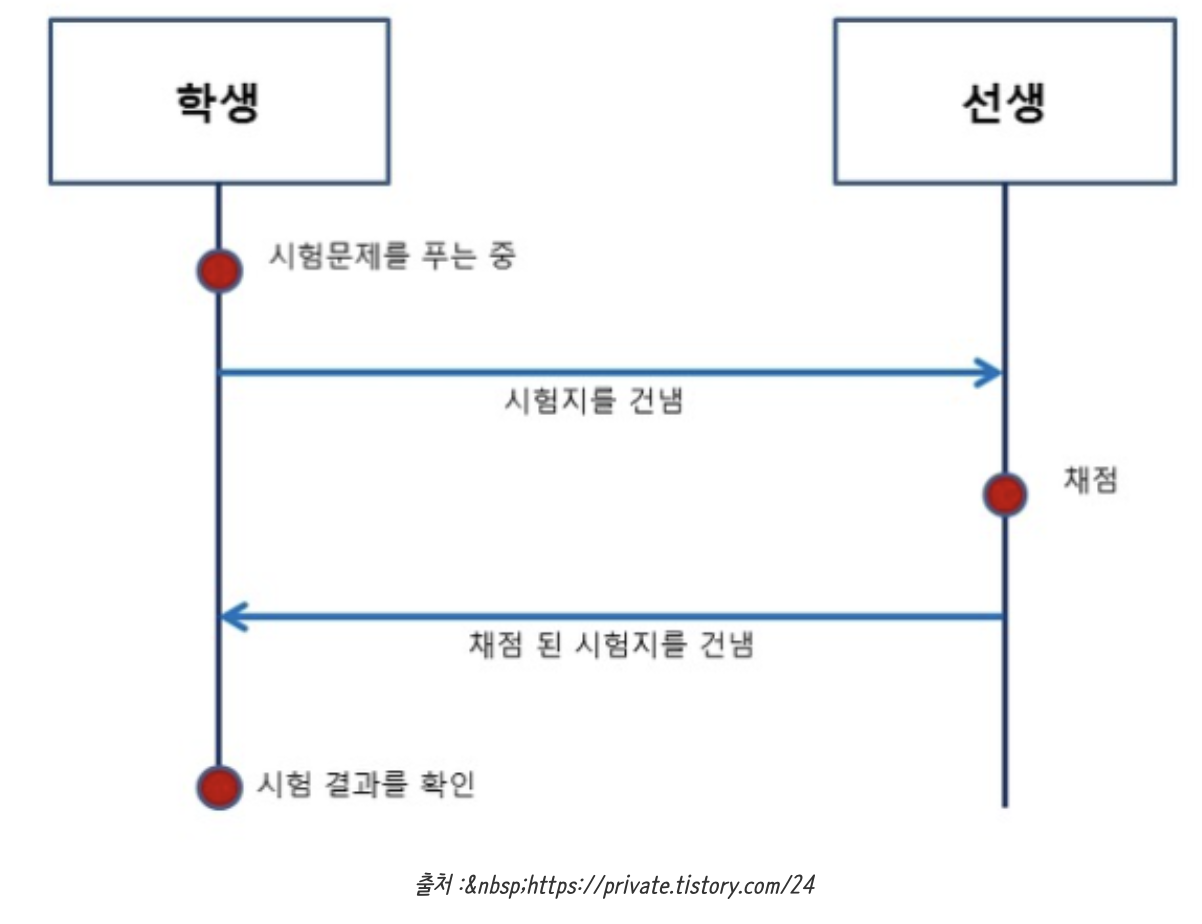
+비동기 방식의 예(시험날의 학생과 선생)
+
+
+1. 학생은 시험문제를 푼다.
+2. 시험문제를 모두 푼 학생은 선생에게 전송한다.
+3. 선생은 학생의 시험지를 채점한다.
+4. 채점이 다 된 시험지를 학생에게 전송한다.
+5. 학생은 선생이 전송한 시험지를 받아 결과를 확인한다.
+
+- 학생과 선생은 시험지라는 연결고리가 있지만 시험지에 행하는 행위(목적)는 서로 다르다.
+
+학생은 시험지를 푸는 역할을 하고 선생은 시험지를 채점하는 역할을 한다.
+서로의 행위(목적)가 다르기 때문에 둘의 작업 처리 시간은 일치하지 않고, 일치하지 않아도 된다.
+
+
+
+동기와 비동기는 어떤 작업 혹은 그와 연관된 작업을 처리하고자 하는 시각의 차이이다.
+
+동기는 추구하는 같은 행위(목적)가 동시에 이루어지며,
+비동기는 추구하는 행위(목적)가 다를 수도 있고, 동시에 이루어지지도 않는다.
+
+
+
+비동기 방식 예제를 통해 블록과 논 블록의 차이를 간략하게 설명하면,
+학생이 시험지를 선생에게 건넨 후 가만히 앉아 채점이 끝나 시험지를 돌려받기만을 기다린다면 학생은 블록 상태이다.
+하지만 학생이 시험지를 건넨 후 선생에게 채점이 완료되었다는 전송을 받기 전까지 다른 과목을 공부한다거나 게임을 한다거나 다른 일을 하게 되면 학생의 상태는 논 블록 상태이다.
+
+
+
+## 👇 추가 정리: 동기/비동기, 블로킹/논블로킹, 선택 기준 && 패턴
+### 1) 한 줄 핵심
+- **동기 vs 비동기**: "**결과를 언제 받는가**(응답 타이밍/흐름 제어)"
+- **블로킹 vs 논블로킹**: "**기다리는 동안 쓰레드가 묶이는가**(자원 사용 방식)"
+- 둘은 독립축이다. **동기-논블로킹** / **비동기-블로킹** 조합도 가능하다.
+
+---
+
+### 2) 일상 속 빠른 예시 8가지
+- **편의점 계산**: 줄 서서 결제 끝날 때까지 **동기·블로킹**.
+- **카페 진동벨**: 주문 후 벨 울릴 때 와서 수령 **비동기·논블로킹**.
+- **패스트푸드 키오스크 + 픽업번호**: 번호 호출 전까지 다른 일 가능 **비동기**.
+- **택시 호출 앱**: 배차 대기 중 다른 앱 사용 **비동기·논블로킹**.
+- **병원 접수표(대기번호)**: 내 차례 전까지 대기 **비동기**, 대기실에만 앉아 있으면 체감은 **블로킹**.
+- **세탁소 맡기고 문자 수령**: 처리 완료 후 알림 **비동기**.
+- **엘리베이터 호출**: 버튼 누르고 앞에서 기다리면 **동기·블로킹** 체감, 다른 층 다녀오면 **비동기**처럼 활용.
+- **택배 배송 조회**: 당장 결과 필요 없고 진행상황만 보면 됨 **비동기** 사용에 적합.
+
+---
+
+### 3) 블로킹 vs 논블로킹 (자원 사용 관점)
+- **블로킹**: 결과 대기 동안 **쓰레드/프로세스가 멈춤**. I/O 대기 시 빈 시간이 길어지면 비효율.
+- **논블로킹**: 결과 대기 동안 **쓰레드가 다른 일 수행**. 콜백/이벤트 루프/리액티브로 처리.
+```
+| | 블로킹 | 논블로킹 |
+|----------------|---------------------------------------------|----------------------------------------------------|
+| 쓰레드 상태 | 대기(Idle) | 다른 작업 수행 가능 |
+| 구현 난이도 | 낮음 | 중~상(콜백/스트림/리액티브 패러다임) |
+| 적합한 상황 | 짧고 확정적 I/O, 간단한 동기식 트랜잭션 | 고동시성 I/O, 외부 호출이 잦고 지연이 가변적일 때 |
+```
+
+> **주의**: "동기=블로킹, 비동기=논블로킹"이 **항상** 성립하는 건 아니다.
+
+---
+
+### 4) 동시성(Concurrency) vs 병렬성(Parallelism)
+- **동시성**: 논리적으로 동시에 보이게 **스케줄링**(빠르게 문맥 전환). 단일 코어도 가능.
+- **병렬성**: 물리적으로 **동시에 실행**(멀티코어/멀티머신).
+- 비동기/논블로킹은 **동시성 처리량**을 높이는 데 유리하지만, **병렬성**은 하드웨어/워크로드에 달려 있다.
+
+---
+
+### 5) 언제 동기? 언제 비동기? (선택 체크리스트)
+- **즉시 결과가 사용자 경험 핵심인가?** (로그인, 결제 승인 결과 등) → **동기 우선**, 타임아웃/폴백 설계.
+- **처리 시간이 길거나 외부 의존 지연이 큰가?** (인코딩, 썸네일, 이메일) → **비동기 큐/워커**.
+- **강한 일관(ACID) 트랜잭션의 경계 안에 있어야 하나?** → 해당 범위까진 **동기**.
+- **후속 시스템으로의 확산(알림/적립/로그)은 eventual OK?** → **비동기 이벤트 발행**.
+- **호출량/팬아웃이 큰가?** → 호출부 **비동기화 + 벌크/배치 + 서킷브레이커**.
+- **SLO가 p95/99에 민감한가?** → 비동기/논블로킹으로 **꼬리지연 완화 + 백프레셔**.
+
+---
+
+### 6) 아키텍처 패턴 (시나리오/다이어그램)
+
+#### 6-1. 동기식 요청-응답 (간단/즉시결과)
+```mermaid
+sequenceDiagram
+ participant Client
+ participant API
+ participant DB
+ Client->>API: POST /transfer {from,to,amount}
+ API->>DB: in Tx: debit(from), credit(to)
+ DB-->>API: commit OK
+ API-->>Client: 200 OK (result)
+```
+
+#### 6-2. 비동기식 처리 + 콜백/웹훅 (지연 OK, 확장성)
+
+```
+sequenceDiagram
+ participant Client
+ participant API
+ participant Queue
+ participant Worker
+ participant Webhook
+ Client->>API: POST /orders
+ API->>Queue: publish(orderCreated)
+ API-->>Client: 202 Accepted (trackingId)
+ Worker->>Queue: consume(orderCreated)
+ Worker->>Webhook: POST /notify (trackingId, status=Done)
+ Note over Client: 폴링(/status) 또는 웹훅으로 상태 갱신
+```
+
+#### 6-3. 결제(예시): 동기 승인 + 비동기 정산/알림
+- **주문 생성/승인**은 사용자 UX를 위해 **동기**(타임아웃/재시도 포함).
+- **영수증 발송, 포인트 적립, 대시보드 집계**는 **비동기 이벤트**로 확산.
+
+---
+
+### 7) 실무 필수 패턴(비동기)
+- **Idempotency Key**: 동일 요청 중복 도달에도 **한 번만** 효과 반영.
+- **Outbox 패턴**: 로컬 트랜잭션 내 **DB에 이벤트 기록 → 별 프로세스가 브로커로 전송**(분산 트랜잭션 없이 ‘정확히 한 번에 가까운’ 전달 보장).
+- **전달 보장**: 대부분 **at-least-once + 멱등 처리**가 현실적. exactly-once는 비용↑/제약↑.
+- **Retry & DLQ**: 지수 백오프, 최대 재시도 후 **사망 큐**로 격리/수동 복구.
+- **Ordering**: 파티션 키(예: userId)로 **순서 보존**, 병렬성-순서성 균형 설계.
+- **Backpressure**: 소비 속도 < 생산 속도일 때 **유량 제어**(버퍼, 드롭, 슬로우 스타트). +- **관찰가능성**: 상관관계 ID, 분산 트레이싱, 메트릭(p95/p99), 알람. + +--- + +### 8) 장단점 한눈에 +| 구분 | 동기 | 비동기 | +|---|---|---| +| 사용자 피드백 | 즉시 결과, UX 명확 | 즉시 완료가 아닐 수 있음(상태 조회/알림 필요) | +| 복잡도 | 낮음 | 큐/워커/상태관리/멱등성 등 설계 복잡 | +| 확장성/자원 효율 | 쓰레드 영걸림으로 한계 | 고동시성/자원 효율 우수 | +| 일관성 | 강한 일관성 범위 한정 쉬움 | 보통 최종 일관성(eventual) | +| 실패 처리 | 호출부에서 즉시 식별 | 재시도/보상/모니터링 체계 필수 | + +--- + +### 9) Java/Spring 예시 스니펫 + +#### 9-1. 동기·블로킹 호출 (간단/즉시 결과) +```java +// Spring 6: RestClient (블로킹) +RestClient client = RestClient.create("https://pay.example.com"); +PaymentResponse res = client.post() + .uri("/approve") + .body(request) + .retrieve() + .body(PaymentResponse.class); // 완료까지 현재 쓰레드 대기 +``` + +#### 9-2. 비동기·논블로킹 (리액티브 WebClient) +```java +// 논블로킹: 결과는 Mono로 비동기 전달 +WebClient webClient = WebClient.create("https://pay.example.com"); +Mono mono = webClient.post()
+ .uri("/approve")
+ .bodyValue(request)
+ .retrieve()
+ .bodyToMono(PaymentResponse.class);
+
+// 체이닝/조합 가능 (subscribe 시점에 실행)
+mono.timeout(Duration.ofSeconds(3))
+ .doOnError(e -> log.warn("timeout/retry"))
+ .retryWhen(Retry.backoff(3, Duration.ofMillis(200)));
+
+```
+#### 9-3. 메시징(카프카) 기반 비동기
+```java
+// 생산자
+kafkaTemplate.send("order.created", orderId, payload);
+
+// 소비자(멱등 처리)
+@KafkaListener(topics = "order.created")
+public void handle(String key, OrderCreated evt) {
+ if (processedRepo.exists(evt.id())) return; // 멱등
+ // 비즈 처리...
+ processedRepo.save(evt.id());
+}
+```
+
+---
+### 10) 계좌이체 비유, 조금 더 정확히
+- "A 차감과 B 가산"은 **같은 트랜잭션 경계**에 있으면 동기·원자적으로 처리 가능.
+- 다만 **타 시스템 통합/정산/알림**은 대개 **비동기**(최종 일관성).
+ 즉, **핵심 잔액 갱신은 동기**, **주변 효과는 비동기**가 실무에서 흔한 분리다.
+
+---
+
+### 11) 실패/타임아웃/회복 전략
+- **타임아웃**: 외부 호출은 반드시 설정(서비스 SLO에 맞춤).
+- **서킷브레이커**: 연쇄 실패/폭주 방지.
+- **재시도 정책**: 지수 백오프 + 재시도 한도 + 재시도 안전성(멱등).
+- **보상 트랜잭션(Saga/TCC)**: 분산 작업 일부 실패 시 **보상 단계**로 롤백/보정.
+
+---
+
+### 12) 면접/리뷰 포인트(요약)
+- "동기/비동기와 블로킹/논블로킹의 **차이**를 설명해보라."
+- "왜 비동기가 항상 더 빠른 게 아닌가? (**지연 vs 처리량**, 컨텍스트 스위칭/큐잉 지연/오버헤드)."
+- "비동기에서 **멱등성/재시도/순서/중복**을 어떻게 보장하나?"
+- "동기 핵심 트랜잭션 + 비동기 사이드 이펙트로 **경계**를 나눈 사례는?"
+
+---
+
+### 13) TL;DR
+- **즉시 결과 필요/범위 좁은 트랜잭션** → 동기(간단, 확실).
+- **지연 허용/고동시성/외부 의존 많음** → 비동기(확장, 자원 효율) + 멱등/재시도/관찰가능성.
+
+---
+
+## (부록) 비동기 심화 정리
+
+### A. 전달 보장 & 멱등성
+- 현실적인 기본값: **at-least-once + 멱등한 소비자**.
+- 요청마다 **Idempotency-Key**(헤더/키-밸류)로 중복 방지.
+- 중복/순서 보존 필요 시 **파티션 키** 설계(예: accountId).
+
+---
+
+### B. Outbox & 트랜잭션 경계
+- 로컬 DB 트랜잭션 안에 **비즈 + outbox insert**를 함께 커밋.
+- 별 프로세스가 outbox를 읽어 브로커로 전송(전송 실패 시 재시도).
+- 분산 트랜잭션 없이 "**한 번만 처리한 것 같은**" 효과.
+
+---
+
+### C. Saga/TCC 개요
+- **Saga(오케스트레이션/코레오그래피)**: 단계별 커밋 + **보상 단계**로 롤백.
+- **TCC**: Try(예약) → Confirm(확정) / Cancel(취소).
+ **Confirm 직전 장애**는 **재시도/타임아웃/보상**으로 수렴.
+ 설계 핵심은 **멱등, 타임아웃, 상태전이 FSM**,
+ 운영 핵심은 **모니터링 + 수동 정리 경로**.
+
+---
+
+### D. 백프레셔 & 흐름 제어
+- 프로듀서 속도> 컨슈머 속도 → **큐 길이, 처리 지연, 메모리 증가**.
+- 해결: **버퍼 한도/드롭 정책/속도 조절/스케일 아웃**.
+
+---
+
+### E. 관찰가능성 & 운영
+- **코릴레이션ID**로 요청-이벤트-로그 연결.
+- **지표**: 큐 적재/소비율, 체류시간, 재시도 수, DLQ, p95/p99.
+- **경보**: 지표 임계 초과 + DLQ 발생 + 처리 정체.
From 151612c625fc8df9d3df1f110a2112a3e46dfe4d Mon Sep 17 00:00:00 2001
From: Chorong0824 <124541156+sjmun09@users.noreply.github.com>
Date: Thu, 9 Oct 2025 19:02:19 +0900
Subject: [PATCH 3/8] =?UTF-8?q?docs=20:=20=EB=B9=84=EB=8F=99=EA=B8=B0=20?=
=?UTF-8?q?=ED=86=B5=EC=8B=A0=20=ED=8C=A8=ED=84=B4=20=EC=84=A4=EB=AA=85=20?=
=?UTF-8?q?=EC=B6=94=EA=B0=80?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
...0_353円271円204円353円217円231円352円270円260円.md" | 63 ++++++++++++++++++-
1 file changed, 61 insertions(+), 2 deletions(-)
diff --git "a/seongjun/353円217円231円352円270円260円_353円271円204円353円217円231円352円270円260円.md" "b/seongjun/353円217円231円352円270円260円_353円271円204円353円217円231円352円270円260円.md"
index c444775..31a2259 100644
--- "a/seongjun/353円217円231円352円270円260円_353円271円204円353円217円231円352円270円260円.md"
+++ "b/seongjun/353円217円231円352円270円260円_353円271円204円353円217円231円352円270円260円.md"
@@ -156,12 +156,71 @@ sequenceDiagram
participant Webhook
Client->>API: POST /orders
API->>Queue: publish(orderCreated)
- API-->>Client: 202 Accepted (trackingId)
+ API-->>Client: 202 Accepted (trackingId 반환)
Worker->>Queue: consume(orderCreated)
Worker->>Webhook: POST /notify (trackingId, status=Done)
- Note over Client: 폴링(/status) 또는 웹훅으로 상태 갱신
+ Note over Client: 폴링(/status) 또는 웹훅으로 상태 갱신 => 즉, Client는 polling or webhook으로 완료 상태 확인한다는 것임.
```
+#### ⚙️ 흐름 상세 해설
+
+1. **Client → API 요청**
+ - 클라이언트가 "주문 요청", "영상 인코딩", "메일 발송" 등 작업을 요청.
+ - 이때 결과가 바로 필요하지는 않음.
+
+2. **API → Queue로 메시지 발행**
+ - API 서버는 "작업 수락" 후 요청을 큐(Kafka, RabbitMQ, SQS 등)에 넣고
+ 바로 `202 Accepted` 응답을 반환.
+ - 이때 "trackingId"나 "jobId"를 같이 줘서 클라이언트가 상태를 추적 가능하게 함.
+
+3. **Worker가 Queue를 소비(Consume)**
+ - 백그라운드의 Worker가 큐에서 메시지를 꺼내 실제 작업 수행.
+ - 예: 이메일 전송, 영상 인코딩, 결제 정산 등
+
+4. **Webhook(또는 Polling)**
+ - 작업 완료 후 Worker는 클라이언트가 등록한 `callbackUrl`로 결과를 전송하거나,
+ 클라이언트가 직접 `/status/{trackingId}`를 주기적으로 조회(polling)함.
+
+5. **Client가 결과 수신 및 표시**
+ - 클라이언트는 결과를 비동기적으로 확인하고 사용자에게 보여줌.
+
+
+> "비동기 통신 구조에서 응답을 나중에 받는 패턴"을 설명한 거.
+즉, "요청은 바로 끝나지만 실제 처리는 나중에 백그라운드에서 진행되는 구조"
+
+이 구조는 요청자가 **즉시 응답("요청을 받았다")만 받고**,
+실제 작업은 **백엔드의 큐나 워커(Worker)**가 **나중에 비동기로 처리하는 방식**이다.
+
+즉,
+> 요청자(Client)는 "결과를 지금 바로 받지 않아도 된다."
+> 대신, "작업이 끝나면 나중에 알려줘" 하는 패턴이지.
+
+#### 🧠 동기식과 비교해보면
+| 구분 | 동기식 요청-응답 | 비동기식 요청-응답(콜백/웹훅) |
+|------|--------------------|------------------------------|
+| 처리 방식 | API가 모든 작업을 끝내고 응답 | 요청만 받고 작업은 나중에 |
+| 응답 시점 | 작업이 완료된 뒤 | 작업을 큐에 넣은 즉시("Received") |
+| 응답 내용 | 최종 결과 | 처리 중임(Tracking ID 등) |
+| 확장성 | 낮음 (요청 지속 유지) | 높음 (비동기 큐로 부하 완화) |
+| 예시 | 계좌이체 승인, 로그인 등 | 이메일 전송, 이미지 변환, 결제 정산 등 |
+
+
+#### 🪄 실제 비유로 보면
+- 카페에서 **진동벨 시스템**이 바로 이 구조야.
+ - 고객: "커피 주세요!"
+ - 점원: "알겠습니다 (진동벨 드림)" → 즉시 응답
+ - 커피 제조기(Worker)가 실제 작업 수행
+ - 커피 완성 시 진동벨(웹훅)이 울림
+
+이게 **비동기 + 콜백 알림(Webhook)** 구조와 완전히 동일한 형태야.
+
+
+
+
+
+
+
+
#### 6-3. 결제(예시): 동기 승인 + 비동기 정산/알림
- **주문 생성/승인**은 사용자 UX를 위해 **동기**(타임아웃/재시도 포함).
- **영수증 발송, 포인트 적립, 대시보드 집계**는 **비동기 이벤트**로 확산.
From 8a7945d87c0504ecf4740af9bb57f3e48d2751be Mon Sep 17 00:00:00 2001
From: Chorong0824 <124541156+sjmun09@users.noreply.github.com>
Date: Thu, 9 Oct 2025 19:05:37 +0900
Subject: [PATCH 4/8] =?UTF-8?q?docs:=20=EC=8B=9C=ED=80=80=EC=8A=A4=20?=
=?UTF-8?q?=EB=8B=A4=EC=9D=B4=EC=96=B4=EA=B7=B8=EB=9E=A8=20=EC=A0=81?=
=?UTF-8?q?=EC=9A=A9?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
...217231円352円270円260円_353円271円204円353円217円231円352円270円260円.md" | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git "a/seongjun/353円217円231円352円270円260円_353円271円204円353円217円231円352円270円260円.md" "b/seongjun/353円217円231円352円270円260円_353円271円204円353円217円231円352円270円260円.md"
index 31a2259..a7a3d42 100644
--- "a/seongjun/353円217円231円352円270円260円_353円271円204円353円217円231円352円270円260円.md"
+++ "b/seongjun/353円217円231円352円270円260円_353円271円204円353円217円231円352円270円260円.md"
@@ -147,7 +147,7 @@ sequenceDiagram
#### 6-2. 비동기식 처리 + 콜백/웹훅 (지연 OK, 확장성)
-```
+```mermaid
sequenceDiagram
participant Client
participant API
From bf967e8e1465c555a709ea6d9d482555a661c365 Mon Sep 17 00:00:00 2001
From: Chorong0824 <124541156+sjmun09@users.noreply.github.com>
Date: Thu, 9 Oct 2025 19:56:21 +0900
Subject: [PATCH 5/8] =?UTF-8?q?docs=20:=20=EC=98=B5=ED=8B=B0=EB=A7=88?=
=?UTF-8?q?=EC=9D=B4=EC=A0=80=EC=99=80=20=ED=9E=8C=ED=8A=B8(mysql,=20oracl?=
=?UTF-8?q?e=20=EB=B9=84=EA=B5=90)?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
..._354円231円200円_355円236円214円355円212円270円.md" | 279 ++++++++++++++++++
1 file changed, 279 insertions(+)
create mode 100644 "seongjun/354円230円265円355円213円260円353円247円210円354円235円264円354円240円200円_354円231円200円_355円236円214円355円212円270円.md"
diff --git "a/seongjun/354円230円265円355円213円260円353円247円210円354円235円264円354円240円200円_354円231円200円_355円236円214円355円212円270円.md" "b/seongjun/354円230円265円355円213円260円353円247円210円354円235円264円354円240円200円_354円231円200円_355円236円214円355円212円270円.md"
new file mode 100644
index 0000000..14c128d
--- /dev/null
+++ "b/seongjun/354円230円265円355円213円260円353円247円210円354円235円264円354円240円200円_354円231円200円_355円236円214円355円212円270円.md"
@@ -0,0 +1,279 @@
+사실 나는 옵티마이저를 리마큐 1권을 통해 학습하여서,
+리마큐와 중복된 정리 내용이 있을 수 있음을 양해부탁드립니다!
+
+
+# 📘 옵티마이저(Optimizer)와 힌트(Hint)
+
+## 📖 목차
+1. 옵티마이저 개요
+2. 옵티마이저의 역할과 종류
+3. 옵티마이저의 실행 계획 결정 흐름 (시퀀스 다이어그램)
+4. 옵티마이저가 고려하는 요소
+5. 옵티마이저 힌트(Hint) 개념 및 사용 목적
+6. 주요 옵티마이저 힌트 예시
+7. 옵티마이저 튜닝 포인트 예시
+8. 면접/스터디용 핵심 정리
+
+---
+
+## 1️⃣ 옵티마이저 개요
+- **Optimizer**는 SQL을 **가장 효율적으로 실행할 방법(Execution Plan)** 을 결정하는 **DB 내부의 "두뇌"** 역할을 한다.
+- SQL 자체는 "무엇을 조회할지(What)"만 표현하고,
+ "어떻게 조회할지(How)"는 옵티마이저가 판단한다.
+
+> 💡 개발자는 "무엇(SELECT ~)"만 쓰고, DB가 "어떻게(인덱스/조인순서/조인방식)"를 자동으로 결정한다.
+
+---
+
+## 2️⃣ 옵티마이저의 역할과 종류
+
+| 구분 | 설명 | 대표 DB |
+|------|------|----------|
+| **규칙 기반 옵티마이저 (RBO, Rule-Based Optimizer)** | 정해진 규칙/우선순위에 따라 실행계획 결정 (예: 인덱스가 있으면 무조건 인덱스 사용) | Oracle 8 이전 |
+| **비용 기반 옵티마이저 (CBO, Cost-Based Optimizer)** | 통계 정보(카디널리티, I/O 비용 등)를 기반으로 최적의 실행계획 선택 | Oracle 9↑, MySQL, MariaDB, PostgreSQL |
+
+🔹 **MySQL / MariaDB / PostgreSQL** → 전부 **CBO 기반**
+통계정보(`ANALYZE TABLE`, `ANALYZE VERBOSE`)가 매우 중요하다.
+
+---
+
+## 3️⃣ 옵티마이저 실행계획 결정 흐름
+
+아래 시퀀스 다이어그램은 옵티마이저의 의사결정 과정을 나타낸다.
+
+```mermaid
+sequenceDiagram
+ participant User as 사용자(SQL 작성)
+ participant Parser as SQL Parser
+ participant Optimizer as 옵티마이저
+ participant Executor as 실행기(Executor)
+ participant Storage as 스토리지 엔진
+
+ User->>Parser: SQL 전달 (예: SELECT * FROM orders WHERE user_id=10)
+ Parser->>Parser: 구문 분석 / 파싱 트리 생성
+ Parser->>Optimizer: 파싱 트리 전달
+ Optimizer->>Optimizer: 통계정보 수집 (테이블/인덱스/카디널리티)
+ Optimizer->>Optimizer: 가능한 실행계획 후보 생성
+ Optimizer->>Optimizer: 각 후보별 비용 계산 (CPU, I/O, 메모리)
+ Optimizer->>Optimizer: 최소 비용의 계획 선택
+ Optimizer->>Executor: 실행계획 전달
+ Executor->>Storage: 인덱스 탐색 or 테이블 스캔 수행
+ Storage-->>Executor: 데이터 반환
+ Executor-->>User: 결과셋 반환
+```
+
+📍 **핵심 포인트**
+- 옵티마이저는 **비용 모델(cost model)** 기반으로 후보 계획을 평가한다.
+- **통계 정보가 부정확하면 비효율적인 실행계획**이 선택될 수 있다.
+ → 따라서 `ANALYZE TABLE` 주기적 수행이 중요하다.
+
+---
+
+## 4️⃣ 옵티마이저가 고려하는 요소
+
+| 항목 | 설명 |
+|------|------|
+| **통계정보** | 행 개수, 인덱스 선택도, 카디널리티 등 |
+| **조인 순서** | 어떤 테이블을 먼저 조인할지 (드라이빙 테이블) |
+| **조인 방식** | NL Join, Hash Join, Sort-Merge Join 등 |
+| **인덱스 존재 여부** | 인덱스 탐색 비용 vs 풀스캔 비용 비교 |
+| **필터 조건 선택도** | WHERE 조건으로 얼마나 줄일 수 있는가 |
+| **LIMIT / ORDER BY / GROUP BY 유무** | 정렬/집계 필요 여부 |
+
+---
+
+## 5️⃣ 옵티마이저 힌트(Hint) 개념 및 사용 목적
+
+- 옵티마이저의 **자동 선택이 비효율적일 때**, 개발자가 **직접 의사결정 방향을 강제**하기 위해 사용.
+- 즉, **"이 SQL은 이렇게 실행하라"**는 명시적 지시문이다.
+- 힌트는 SQL 문 안에 주석 형태로 작성한다.
+
+📌 **MySQL 예시**
+```sql
+SELECT /*+ INDEX(o idx_user_id) */ *
+FROM orders o
+WHERE user_id = 10;
+```
+
+📌 Oracle / MariaDB 예시
+```sql
+SELECT /*+ USE_NL(a b) LEADING(a b) INDEX(b idx_user_id) */ *
+FROM users a
+JOIN orders b ON a.id = b.user_id;
+```
+
+---
+
+## 6️⃣ 주요 옵티마이저 힌트 예시
+
+| 힌트 | 의미 | 비고 |
+|------|------|------|
+| **USE_INDEX / INDEX** | 특정 인덱스 사용 | MySQL, Oracle 공통 |
+| **IGNORE_INDEX** | 특정 인덱스 무시 | MySQL |
+| **FORCE_INDEX** | 인덱스 강제 사용 | MySQL |
+| **USE_NL / USE_HASH / USE_MERGE** | 조인 방식 지정 | Oracle / MariaDB |
+| **LEADING(a b)** | 조인 순서 강제 | Oracle / MariaDB |
+| **STRAIGHT_JOIN** | FROM 순서대로 조인 | MySQL |
+| **OPTIMIZER_FEATURES_ENABLE** | 옵티마이저 버전별 동작 모드 | Oracle |
+
+---
+
+## 7️⃣ 옵티마이저 튜닝 포인트 예시
+
+✅ **1. 실행계획(Explain) 확인**
+```sql
+EXPLAIN FORMAT=JSON
+SELECT * FROM orders WHERE user_id=10;
+```
+
+- key / key_len / rows / filtered / Extra 등을 주의 깊게 본다.
+
+✅ **2. 통계정보 최신화**
+```sql
+ANALYZE TABLE orders;
+```
+
+✅ **3. 힌트는 "임시 방편"으로만**
+
+- 힌트는 옵티마이저의 진화에 역행할 수 있다.
+- 근본 원인은 인덱스 설계/쿼리 구조일 수 있다.
+
+✅ **4. 조인 순서/조인 방식은 SQL 구조 변경으로도 개선 가능**
+```sql
+-- 비효율적인 예시
+SELECT * FROM orders o
+JOIN users u ON o.user_id = u.id
+WHERE u.status = 'ACTIVE';
+
+-- 개선된 예시 (선택도 높은 조건 먼저)
+SELECT * FROM users u
+JOIN orders o ON o.user_id = u.id
+WHERE u.status = 'ACTIVE';
+```
+
+---
+
+## 8️⃣ 면접/스터디 핵심 정리
+
+| 질문 | 핵심 요약 |
+|------|------------|
+| **Q. 옵티마이저란?** | SQL을 효율적으로 실행하기 위해 최적의 실행계획을 선택하는 DB 엔진의 두뇌 |
+| **Q. CBO가 RBO보다 나은 이유는?** | 통계 기반으로 상황별 최적화 가능 (동적, 환경 변화 대응) |
+| **Q. 힌트는 언제 사용하는가?** | 옵티마이저의 판단이 비효율적이거나 통계정보 갱신이 불가할 때 임시 조치 |
+| **Q. 옵티마이저 성능 튜닝 방법은?** | 실행계획 분석, 통계정보 갱신, 인덱스 구조 점검, 조인 순서 개선 |
+
+---
+
+## 💡 확장 주제
+
+### 1️⃣ 옵티마이저의 **비용 계산(Cost Model)** 내부 구조
+
+옵티마이저는 실행계획 후보마다 다음 세 가지 비용 요소를 합산하여 비교합니다.
+
+| 비용 요소 | 설명 | 대표 항목 |
+|------------|------|------------|
+| **I/O Cost** | 디스크 접근 횟수, 페이지 읽기/쓰기 비용 | 테이블 스캔, 인덱스 탐색 |
+| **CPU Cost** | 연산 및 비교, 정렬, 조인 계산 비용 | 필터링, 정렬, 집계 연산 |
+| **Memory Cost** | 버퍼/임시영역 사용량 | Hash Join, Temp Table |
+
+**총비용(Cost)**
+```text
+Total Cost = I/O Cost + CPU Cost + Memory Cost
+```
+> 옵티마이저는 여러 실행계획 후보를 시뮬레이션하고,
+그 중 총 비용이 가장 낮은 실행계획을 실제로 선택합니다.
+
+예시 (MySQL EXPLAIN JSON 일부)
+```json
+"cost_info": {
+ "query_cost": "45.20",
+ "read_cost": "40.00",
+ "eval_cost": "5.20"
+}
+```
+→ I/O(40.0) + CPU(5.2) = 45.2의 총 비용이 계산됨.
+
+---
+
+### 2️⃣ **카디널리티(Cardinality) 추정 오차와 해결법**
+
+- **카디널리티**: 특정 조건에 대해 예상되는 결과 행(row)의 개수
+ → 예: `WHERE gender='M'`일 때 남성 사용자의 비율
+
+| 원인 | 설명 | 해결책 |
+|------|------|--------|
+| **통계정보 오래됨** | 실제 데이터 분포와 불일치 | `ANALYZE TABLE`, `OPTIMIZE TABLE` 주기적 실행 |
+| **히스토그램 부재** | 값의 분포가 균등하지 않음 | MariaDB 10.4+, MySQL 8.0+의 히스토그램 사용 |
+| **복합 조건** | 다중 칼럼 조건 간 상관관계 무시 | 가상 컬럼, Functional Index 고려 |
+
+📌 **MySQL 히스토그램 예시**
+```sql
+ANALYZE TABLE users UPDATE HISTOGRAM ON gender, country WITH 10 BUCKETS;
+```
+
+히스토그램을 통해 "값의 분포"를 정밀하게 반영함으로써
+옵티마이저의 선택도 추정 정확도를 높인다.
+
+---
+
+### 3️⃣ **MySQL vs Oracle 옵티마이저 비교**
+
+| 구분 | MySQL | Oracle |
+|------|--------|--------|
+| **옵티마이저 유형** | CBO (Cost-Based Only) | CBO + Adaptive Optimization |
+| **통계정보 수집** | `ANALYZE TABLE` / 히스토그램 | `DBMS_STATS.GATHER_TABLE_STATS` |
+| **조인 방식** | Nested Loop / Hash Join / Block Nested Loop | NL / Hash / Sort Merge |
+| **힌트 문법** | `/*+ HINT */` 단순 구조 | 다중 힌트 조합 가능 (LEADING, PQ_DISTRIBUTE 등) |
+| **실행계획 확인 방법** | `EXPLAIN`, `EXPLAIN FORMAT=JSON` | `EXPLAIN PLAN FOR`, `AUTOTRACE`, `SQL Monitor` |
+| **비용 계산 방식** | 단순 비용 모델 (I/O 중심) | 다차원 비용 모델 (CPU, I/O, 병렬도 고려) |
+| **최적화 기능** | 옵티마이저 트레이스(`OPTIMIZER_TRACE`) | Adaptive Plan, SQL Profile, SQL Baseline |
+
+> 🔸 MySQL은 단순하고 직관적이며 빠르게 실행계획을 결정하는 반면,
+> Oracle은 **동적 적응(Adaptive Optimization)** 을 통해 실행 중에도 계획을 변경할 수 있다.
+> 실무에서는 **통계의 정확도와 SQL 구조 단순화**가 가장 큰 성능 요인이다.
+
+
+---
+
+### 4️⃣ **Explain Plan 필드별 상세 분석**
+
+MySQL의 `EXPLAIN` 결과를 해석하는 핵심 필드는 다음과 같다.
+
+| 필드 | 의미 | 설명 |
+|------|------|------|
+| **id** | 실행 순서 | 숫자가 높을수록 먼저 실행되는 서브쿼리 |
+| **select_type** | 쿼리 유형 | SIMPLE / PRIMARY / DERIVED / SUBQUERY |
+| **table** | 액세스 대상 테이블 | 실제 접근하는 테이블명 |
+| **type** | 접근 방식 | ALL, index, range, ref, eq_ref, const (왼쪽일수록 느림) |
+| **key** | 사용 인덱스 | 옵티마이저가 선택한 인덱스 |
+| **rows** | 예상 접근 행 수 | 옵티마이저의 카디널리티 예측 결과 |
+| **filtered** | 필터링 비율(%) | WHERE 조건으로 남는 비율 |
+| **Extra** | 부가 정보 | Using index, Using filesort, Using temporary 등 |
+
+📘 **예시**
+```sql
+EXPLAIN FORMAT=TRADITIONAL
+SELECT *
+FROM users u
+JOIN orders o
+ON u.id = o.user_id
+WHERE u.status = 'ACTIVE';
+```
+| id | select_type | table | type | key | rows | Extra |
+|----|--------------|--------|------|-----|------|-------|
+| 1 | SIMPLE | u | ref | idx_status | 500 | Using index |
+| 1 | SIMPLE | o | ref | idx_user_id | 1000 | Using where |
+
+→ **의미 요약**
+- `u` 테이블에서 `status` 조건으로 먼저 필터링
+- `o` 테이블을 `user_id` 기준으로 조인 (인덱스 활용)
+- 전체 조인 비용은 **(rows_u ×ばつ rows_o)** 로 추정되며, 필터링 비율이 낮을수록 효율적이다.
+
+---
+
+## 🚀 요약 정리
+
+- 옵티마이저는 **비용 기반(CBO)** 으로 실행계획을 선택한다.
+- **정확한 통계정보**가 SQL 성능의 핵심이다.
+- **힌트**는 "임시 응급조치"일 뿐, 구조적 개선이 우선이다.
+- `EXPLAIN`과 `ANALYZE`는 옵티마이저의 동작을 이해하는 최고의 도구다.
From aef7bd18ca87867d021ca9695181ce0528b4553f Mon Sep 17 00:00:00 2001
From: Chorong0824 <124541156+sjmun09@users.noreply.github.com>
Date: Thu, 9 Oct 2025 21:10:23 +0900
Subject: [PATCH 6/8] =?UTF-8?q?docs:=20Stateless=EC=99=80Stateful=20?=
=?UTF-8?q?=EC=A0=95=EB=A6=AC?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
"seongjun/Stateless_354円231円200円_Stateful.md" | 620 ++++++++++++++++++
1 file changed, 620 insertions(+)
create mode 100644 "seongjun/Stateless_354円231円200円_Stateful.md"
diff --git "a/seongjun/Stateless_354円231円200円_Stateful.md" "b/seongjun/Stateless_354円231円200円_Stateful.md"
new file mode 100644
index 0000000..94f0077
--- /dev/null
+++ "b/seongjun/Stateless_354円231円200円_Stateful.md"
@@ -0,0 +1,620 @@
+# 🌐 무상태(Stateless) 설계의 핵심 정리
+
+## 1️⃣ 개요
+웹 애플리케이션에서 **Stateless(무상태)** 란,
+서버가 **이전 요청의 상태나 컨텍스트를 저장하지 않는 설계 방식**을 말한다.
+즉, **각 요청(Request)** 은 서로 완전히 **독립적**이며,
+서버는 매번 "처음 보는 요청"처럼 처리한다.
+
+> 💡 REST, HTTP, MSA 구조 모두 이 ‘무상태성’을 기반으로 한다.
+
+---
+
+## 2️⃣ 상태(State)란?
+- **State(상태)**: 클라이언트와 서버 간의 ‘대화 맥락’ 또는 ‘세션 정보’
+- 예를 들어 로그인 후 사용자 정보를 유지하는 세션, 장바구니 내역, 진행 중인 트랜잭션 등이 상태 정보에 해당한다.
+
+| 구분 | Stateful | Stateless |
+|------|-----------|------------|
+| 요청 간 맥락 | 유지됨 (세션/쿠키 등) | 없음 (독립 요청) |
+| 서버 부하 | 높음 (메모리 관리 필요) | 낮음 (단순 처리) |
+| 확장성 | 낮음 (세션 공유 필요) | 높음 (로드밸런싱 용이) |
+| 장애 복구 | 어려움 (세션 일관성 문제) | 쉬움 (무상태 서버 교체 가능) |
+
+---
+
+## 3️⃣ 무상태(Stateless) 설계 원리
+
+### (1) 요청은 항상 ‘완전해야 한다’
+> 요청 하나로 서버가 필요한 모든 정보를 알아야 한다.
+
+예
+```http
+GET /api/user/profile
+Authorization: Bearer eyJhbGciOiJIUzI1NiIs...
+```
+- JWT를 이용해 클라이언트가 인증 정보를 직접 담아 보낸다.
+- 서버는 이전 세션을 기억하지 않고, 토큰만으로 인증을 수행한다.
+
+### (2) 서버는 ‘세션’을 저장하지 않는다
+- 로그인 상태를 서버 메모리에 저장하지 않고,
+ **토큰 기반 인증(JWT)** 으로 대체한다.
+- 장바구니, 임시 데이터 등은 **Redis 같은 외부 저장소**에 위임한다.
+
+> 💬 즉, 서버는 오직 "입력 → 처리 → 응답"만 담당하며,
+> 상태관리는 외부로 위임한다.
+
+---
+
+### (3) 클라이언트 중심 설계
+- 상태 유지는 클라이언트가 담당하거나,
+- 필요 시 서버 간 공유 가능한 **Session Store (예: Redis)** 를 사용한다.
+
+---
+
+## 4️⃣ 동작 예시 (Stateless vs Stateful 시퀀스 다이어그램)
+
+### 🧩 Stateful 구조 — 세션 기반 로그인
+
+```mermaid
+sequenceDiagram
+ participant Client as 클라이언트
+ participant LB as 로드 밸런서
+ participant ServerA as 서버 A
+ participant ServerB as 서버 B
+
+ Client->>LB: 로그인 요청 (/login)
+ LB->>ServerA: 요청 전달
+ ServerA->>ServerA: 사용자 인증 후 세션 생성 (sessionId=abc123)
+ ServerA-->>Client: 세션 쿠키 발급 (Set-Cookie: JSESSIONID=abc123)
+
+ Note over Client,ServerA: 이후 요청에서 쿠키(JSESSIONID=abc123)를 포함
+
+ Client->>LB: 프로필 요청 (/profile, 쿠키 포함)
+ LB->>ServerA: 세션이 존재하는 서버로 라우팅됨
+ ServerA->>ServerA: 세션 정보 조회
+ ServerA-->>Client: 사용자 프로필 응답
+
+ Note over LB,ServerB: 만약 LB가 ServerB로 보낸다면?
+ Client->>LB: 프로필 요청 (/profile, 쿠키 포함)
+ LB->>ServerB: 요청 전달
+ ServerB->>ServerB: ❌ 세션 정보 없음
+ ServerB-->>Client: 401 Unauthorized (로그인 만료)
+```
+
+> 요약
+서버가 세션을 메모리에 저장하므로, 요청이 항상 같은 서버로 가야 정상 처리됨.
+서버 A가 죽거나 LB가 Server B로 라우팅하면 세션 일관성 깨짐.
+확장성 낮고, Sticky Session 필요.
+
+### 🧩 Stateless 구조 — JWT 기반 로그인
+```mermaid
+sequenceDiagram
+ participant Client as 클라이언트
+ participant LB as 로드 밸런서
+ participant ServerA as 서버 A
+ participant ServerB as 서버 B
+
+ Client->>LB: 로그인 요청 (/login)
+ LB->>ServerA: 요청 전달
+ ServerA->>ServerA: 사용자 인증 후 JWT 생성 (서명 포함)
+ ServerA-->>Client: JWT 반환 (Authorization: Bearer eyJhbGciOiJIUzI1Ni...)
+
+ Note over Client: 이후 요청마다 JWT를 헤더에 포함시킴
+
+ Client->>LB: 프로필 요청 (/profile, Authorization 헤더 포함)
+ LB->>ServerB: 요청 전달 (무작위 라우팅 가능)
+ ServerB->>ServerB: JWT 서명 검증 (서버 상태 필요 없음)
+ ServerB-->>Client: 사용자 프로필 응답 (정상 처리)
+
+ Note over Client,ServerB: 모든 서버가 같은 JWT 서명 키를 공유하므로, 서버 간 상태 공유 불필요
+
+```
+>요약
+서버는 세션을 전혀 저장하지 않음.
+클라이언트가 JWT로 상태를 직접 유지하므로,
+요청이 어느 서버로 가든 인증 가능하고 수평 확장(Scale-out)에 유리하다.
+
+
+✅ 요청 간 맥락이 없어도, 토큰 기반으로 어디서나 처리 가능
+✅ 서버 간 세션 공유나 Sticky Session이 필요 없음
+
+
+#### ⚖️ 구조적 비교 요약
+
+| 항목 | Stateful (세션 기반) | Stateless (JWT 기반) |
+|------|----------------------|----------------------|
+| 상태 저장 위치 | 서버 메모리 | 클라이언트(JWT) |
+| 요청 독립성 | 낮음 | 높음 |
+| 확장성 | 세션 공유 필요 → 낮음 | 서버 간 독립 → 높음 |
+| 장애 복구 | 세션 유실 위험 | 즉시 처리 가능 |
+| REST 철학 부합 | ❌ | ✅ |
+| 적용 예시 | 전통적인 JSP/Servlet, Spring Session | REST API, MSA, Serverless, Gateway |
+
+---
+
+> 🌐 **핵심 정리**
+> Stateless 구조는 요청 간 독립성을 유지하고,
+> 서버를 ‘기억하지 않아도 되는 노드’로 만들어
+> 확장성과 복원력을 극대화한다.
+
+
+
+---
+
+## 5️⃣ 왜 중요한가? (Stateless의 가치)
+
+| 항목 | 설명 |
+|------|------|
+| 🔁 **확장성(Scalability)** | 서버 간 세션 공유 필요가 없어 수평 확장(Scale-out)에 유리 |
+| 💥 **복원력(Fault Tolerance)** | 서버 다운 시에도 다른 인스턴스가 즉시 요청 처리 가능 |
+| 🚀 **성능(Performance)** | 세션 조회나 복제 비용이 없음 |
+| 🧩 **단순성(Simplicity)** | 요청-응답 구조 단순, 유지보수 용이 |
+| 🧱 **표준성(RESTful)** | REST API의 근간이자 HTTP의 본래 철학에 부합 |
+
+---
+
+## 6️⃣ 실무 적용 포인트
+
+| 상황 | 권장 설계 |
+|------|------------|
+| 인증 유지 | JWT + Refresh Token |
+| 로그인 상태 표시 | 클라이언트에서 상태 관리 (e.g. localStorage) |
+| 장바구니, 임시 데이터 | Redis, DB 등 외부 저장소 활용 |
+| 서버 확장 | 무상태 서버로 구성, Sticky Session 피하기 |
+| MSA 간 인증 | Access Token 공유 or API Gateway 단에서 검증 |
+
+---
+
+## 7️⃣ 주의할 점 (Stateless의 오해)
+
+| 오해 | 올바른 이해 |
+|------|--------------|
+| "무상태면 로그인 못한다" | ❌ → 상태를 서버가 아닌 **클라이언트/외부 저장소**에 둔다 |
+| "모든 상태는 제거해야 한다" | ❌ → 단, **서버가 상태를 ‘기억하지 않는다’**가 핵심 |
+| "Stateful이 나쁘다" | ❌ → 일부 실시간 서비스(게임, 트레이딩)는 상태 필요 |
+
+---
+
+## 8️⃣ 확장 개념 (더 깊게 가보자)
+
+| 주제 | 설명 |
+|------|------|
+| 🧩 **Session Clustering** | 상태를 공유하기 위해 여러 서버가 세션 복제하는 구조 (비추천) |
+| 🪶 **Sticky Session** | 같은 클라이언트를 항상 같은 서버로 라우팅하는 방식 |
+| 🧱 **Token-based Auth (JWT)** | 클라이언트가 상태 정보를 포함해 요청 (무상태 핵심 구현체) |
+| 🧭 **Idempotency (멱등성)** | 무상태 API의 중요한 속성, 같은 요청은 항상 같은 결과 |
+| 🧰 **MSA 설계 원칙 중 Stateless** | 마이크로서비스 간 독립 배포·확장을 위한 핵심 원칙 |
+
+---
+
+## 9️⃣ 면접/스터디에서 자주 묻는 질문
+
+| 질문 | 핵심 답변 |
+|------|------------|
+| "왜 Stateless가 중요한가요?" | 서버 확장성과 복원력을 높이고, RESTful 원칙을 유지하기 위해 |
+| "로그인 상태를 Stateless하게 어떻게 유지하나요?" | JWT를 통해 클라이언트가 상태를 직접 전달 |
+| "Stateful과 Stateless의 중간 설계가 가능한가요?" | 가능함. 외부 세션 스토리지(Redis)를 통한 하이브리드 구조 |
+| "Sticky Session은 왜 피해야 하나요?" | 서버 간 부하 불균형 및 확장성 저하 유발 |
+
+### 💬 Q1. "왜 Stateless가 중요한가요?"
+**핵심 답변**
+Stateless는 서버 확장성과 복원력을 높이고, RESTful 원칙을 유지하기 위해 필요하다.
+
+**설명**
+- **확장성(Scalability)**: 요청에 세션 의존이 없으므로 서버를 여러 대로 쉽게 나눌 수 있다.
+ 예를 들어, 트래픽 증가 시 인스턴스를 추가해도 세션 공유가 필요 없어 바로 부하분산이 가능하다.
+- **복원력(Fault Tolerance)**: 특정 서버가 장애를 일으켜도, 다른 서버가 동일 요청을 바로 처리할 수 있다.
+- **유지보수성(Maintainability)**: 상태 관리 로직이 없으므로 서버 코드는 단순해지고, 배포 시에도 세션 데이터 손실 우려가 없다.
+- **REST 철학 부합**: REST는 HTTP 프로토콜의 기본 특성인 Stateless를 기반으로 한다.
+ "서버는 요청 간 컨텍스트를 기억하지 않는다"가 핵심 원리다.
+
+---
+
+### 💬 Q2. "로그인 상태를 Stateless하게 어떻게 유지하나요?"
+**핵심 답변**
+서버가 세션을 저장하지 않고, **JWT(Json Web Token)** 을 이용해 클라이언트가 인증 상태를 직접 유지한다.
+
+**설명**
+- 로그인 시 서버는 사용자 정보를 기반으로 JWT를 생성해 클라이언트에게 전달한다.
+- 이후 요청마다 `Authorization: Bearer ` 형태로 토큰을 함께 보낸다.
+- 서버는 토큰을 검증해 유효하면 해당 사용자를 인증한다.
+ (이때 DB 접근 없이 토큰 서명만으로 인증 가능)
+- 토큰 만료 시 **Refresh Token** 으로 재발급하는 구조를 사용하면, 보안성과 유연성을 동시에 확보할 수 있다.
+
+> 💡 이 구조 덕분에 서버는 로그인 상태를 기억할 필요가 없으며,
+> 수평 확장 시에도 인증 정보가 서버 간에 공유될 필요가 없다.
+
+---
+
+### 💬 Q3. "Stateful과 Stateless의 중간 설계가 가능한가요?"
+**핵심 답변**
+가능하다. 대표적인 방법은 **외부 세션 스토리지(Redis 등)** 를 사용하는 **하이브리드 구조**다.
+
+**설명**
+- 완전 Stateless로 설계하기 어려운 경우(예: 장바구니, 결제 과정, 트랜잭션 세션 등),
+ 세션 데이터를 서버 메모리가 아닌 **Redis** 같은 외부 인메모리 DB에 저장한다.
+- 이 방식은 클라이언트 요청이 어느 서버로 가든 동일한 세션 데이터를 조회할 수 있어,
+ **확장성과 일관성의 균형**을 맞춘다.
+- 예시
+```
+[Client] → [LoadBalancer]
+├─▶ [Server A] → Redis에서 세션 조회
+└─▶ [Server B] → 동일 세션 Redis에서 공유
+```
+
+> ⚙️ 실무에서는 "Stateless 서버 + Stateful 외부 저장소"로 혼합 설계하는 경우가 많다.
+
+---
+
+### 💬 Q4. "Sticky Session은 왜 피해야 하나요?"
+**핵심 답변**
+Sticky Session은 **확장성 저하**와 **장애 복원성 저하**를 유발하기 때문에 지양해야 한다.
+
+**설명**
+- **Sticky Session**: 클라이언트가 항상 같은 서버로 라우팅되도록 하는 방식
+(예: A 서버에서 로그인하면, 이후 요청도 항상 A 서버로 감)
+- 단점:
+1. 특정 서버에 트래픽이 몰려 **부하 불균형**이 발생한다.
+2. 해당 서버가 장애를 일으키면 세션이 사라져 사용자 로그인이 풀린다.
+3. 서버 추가 시 새로운 노드는 기존 세션을 모름 → 확장성 저하.
+- 반면 Stateless는 모든 서버가 동일하게 요청을 처리하므로,
+장애 복구 및 오토스케일링이 훨씬 간단하다.
+
+> 💬 Sticky Session은 "임시방편"으로만 쓰며,
+> 장기적으로는 세션 스토리지나 JWT로 전환하는 것이 이상적이다.
+
+---
+
+### 💬 Q5. "Stateless 설계 시 보안 문제는 없나요?"
+**핵심 답변**
+있다. 특히 토큰 탈취, 재사용 공격 등에 대비해야 한다.
+
+**설명**
+- **토큰 탈취**: 클라이언트 저장소(localStorage, sessionStorage)에 저장된 JWT가 노출될 위험
+→ 해결: HttpOnly 쿠키 사용, 토큰 암호화, 만료시간 단축
+- **토큰 위조**: 서명 검증 미흡 시 위조된 JWT로 인증 가능
+→ 해결: 공개키-비공개키(Public/Private Key) 기반 검증
+- **Refresh Token 도난**: 장기 토큰이 탈취되면 지속 인증 가능
+→ 해결: Refresh Token Rotation (재발급 시 이전 토큰 폐기)
+
+> 🔒 Stateless 구조는 보안 로직을 토큰 단에서 강화해야 한다.
+
+---
+
+### 💬 Q6. "Stateless가 항상 옳은가요?"
+**핵심 답변**
+아니다. 무상태는 대부분의 웹 서비스에 유리하지만, **실시간 연결이나 상태 기반 로직**에는 Stateful이 필요하다.
+
+**설명**
+- **Stateful이 필요한 경우**
+- 실시간 게임, 채팅, 트레이딩 시스템 등 "연결 지속성"이 중요한 서비스
+- 세션 단위로 지속적인 데이터 교환이 필요한 경우
+- **Stateless가 유리한 경우**
+- REST API, 웹 백엔드, 인증 서버, API Gateway, 배치 등
+- 실제로는 **Stateless + 일부 Stateful**을 혼합해 설계한다.
+
+---
+
+## 10️⃣ 요약
+
+> 🌐 **Stateless = 요청 간 독립성 보장 + 서버의 단순화 + 확장성 극대화**
+
+- 요청 하나로 완결되어야 한다.
+- 상태는 클라이언트나 외부 스토리지로 옮긴다.
+- 서버는 언제든 교체·확장 가능한 ‘가벼운 노드’로 설계한다.
+
+---
+
+## 💡 다음 확장 학습 주제 추천
+1. **Idempotency (멱등성)** – 무상태 API에서 왜 중요한가
+2. **JWT vs Session 비교** – 인증의 상태 관리 차이
+3. **Sticky Session과 Redis 세션 클러스터링**
+4. **API Gateway의 Stateless 인증 흐름 설계**
+5. **서버리스(Serverless) 아키텍처에서의 무상태 개념**
+
+---
+
+
+# 📌 확장 학습 주제 심화
+## 1) Idempotency(멱등성) — 무상태 API에서 재시도 안전성 보장
+
+### 한 줄 정의
+**같은 요청을 여러 번 보내도 최종 결과가 동일**하도록 만드는 속성.
+네트워크 재시도·중복 전송·타임아웃 재요청 상황에서도 **중복 부작용**(이중 결제, 이중 발송 등)을 막는다.
+
+### 왜 중요한가?
+- **무상태 서버**는 요청 간 맥락을 기억하지 않으므로, **클라이언트/중간자(게이트웨이/리트라이러)** 가 재시도할 때도 **안전해야 함**.
+- 클라우드/분산 환경의 기본 전달 보장(at-least-once, 중복 가능)과 **자연스럽게 상호 보완**.
+
+### HTTP 메서드와 멱등성
+| 메서드 | 표준상 멱등성 | 비고 |
+|---|---|---|
+| GET/HEAD | ✅ | 조회만 수행해야 함 |
+| PUT | ✅ | "리소스를 이 값으로 만들어라(Upsert)" 의미일 때 |
+| DELETE | ✅ | 여러 번 호출해도 최종 상태는 "없음" |
+| OPTIONS | ✅ | 프리플라이트 조회 |
+| POST | ❌(기본) | **Idempotency-Key**로 멱등화 가능 |
+| PATCH | ❌(기본) | 조건부 갱신(ETag/If-Match)로 멱등화 가능 |
+
+### 멱등화 핵심 패턴
+1. **리소스 키 기반(자연/비즈니스 키) Upsert**
+ - `PUT /users/42` : "항상 42번 사용자를 이 본문으로 만든다"
+ - DB 유니크 제약 + UPSERT로 중복을 구조적으로 제거
+
+2. **POST + Idempotency-Key 헤더**
+ - 클라이언트가 **요청 단위의 전역 고유키**를 생성: `Idempotency-Key: 7f2c-...`
+ - 서버/게이트웨이는 (엔드포인트, 키) 조합으로 **처리 기록 + 응답 캐시** 저장
+ - **동일 키 + 동일 페이로드** 재요청 → **이전 응답 재생산**(200/201 등)
+ - **동일 키 + 상이한 페이로드** → **409 Conflict**(정책적으로 거부)
+
+3. **조건부 갱신(Optimistic Locking)**
+ - `If-Match: `를 이용한 **버전 충돌 방지**
+ - 실패 시 412 Precondition Failed → 재시도 루프에서 안전
+
+4. **멱등 컨슈머(메시지 처리)**
+ - 메시지/이벤트마다 **Message-ID** 저장("inbox table")
+ - 이미 처리한 ID면 스킵(또는 안전한 재실행)
+ - **Transactional Outbox/Inbox** 패턴으로 **정확히 한 번처럼** 보이게
+
+### 구현 로드맵(POST 결제 예)
+1) 스키마(예시)
+```sql
+CREATE TABLE idempotency (
+ endpoint VARCHAR(120) NOT NULL,
+ idem_key VARCHAR(64) NOT NULL,
+ request_hash CHAR(64) NOT NULL,
+ response_status SMALLINT NOT NULL,
+ response_body TEXT NOT NULL,
+ created_at TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
+ PRIMARY KEY (endpoint, idem_key)
+);
+```
+
+2) 처리 알고리즘
+- 요청 진입 → `(endpoint, idem_key)` 조회
+ - **없음** → 처리 시작 전 **행 선점(INSERT)** 후 실제 비즈니스 수행 → **응답 저장**
+ - **있음** → `request_hash` 같으면 **캐시된 응답 반환**, 다르면 **409 Conflict**
+- **TTL/보존 기간** 운영(예: 결제·주문은 24h~72h, 일반 POST는 수 시간)
+
+3) 동시성/경쟁 해결
+- **DB 유니크키** + 트랜잭션으로 "이 키는 내가 먼저 잡았다" 보장
+- 분산락(필요 시)보다 **단일 DB 제약**이 간단·견고
+
+### 멱등화 체크리스트
+- [ ] 클라이언트가 **Idempotency-Key** 생성/전달
+- [ ] 서버가 키별 **요청 해시/응답** 저장 및 **동일 응답 리턴**
+- [ ] 키 재사용 정책(동일/상이한 페이로드 처리 기준) 명시
+- [ ] 키 **보존 기간/정리 배치** 운영
+- [ ] 외부 부작용(이메일, 푸시, 결제 승인)도 **키 단위로 중복 방지**
+- [ ] 장애/타임아웃 재시도 경로에 모두 적용(게이트웨이, 워커, MQ 컨슈머)
+
+
+
+
+## 2) API Gateway 무상태 인증 흐름 설계 — "인증은 게이트웨이에서, 상태는 토큰에"
+
+### 목표
+- **게이트웨이 레벨에서 JWT 검증**으로 인증을 **완전 무상태**로 처리
+- 내부 서비스는 **신원/권한이 주입된 요청**만 신뢰하고 비즈니스에 집중
+
+### 역할 분담
+- **클라이언트**: Access Token(JWT) 보관·전달
+- **IdP/Auth 서버**: 로그인/권한 부여, **JWT 발급 + JWKS 공개**
+- **API Gateway**: 서명·클레임 검증, **정책/권한 결정(PDP/PEP)**, 컨텍스트 주입
+- **마이크로서비스**: 게이트웨이가 보장한 **주체/스코프** 신뢰, **세션 저장 없음**
+
+### 무상태 설계 키 포인트
+- **서명 검증만으로 인증**: `iss/aud/exp/nbf` 체크 + **JWKS 캐시**
+- **Key Rotation**: `kid` 기반으로 **JWKS 자동 갱신**, 실패 시 **백오프 + 로컬 캐시 유지**
+- **Clock Skew** 허용(예: ±2분), 토큰 만료 오차 최소화
+- **Claims→권한 매핑**: `scope`, `roles`, `tenant`, `sub` 등으로 RBAC/ABAC
+- **컨텍스트 주입**: 내부로 **원본 JWT** 전달 또는 **정제된 헤더**(예: `X-User-Id`, `X-Scopes`)
+- **Opaque 토큰** 사용 시**만** IdP **Introspection**(네트워크 의존) — 가능하면 **JWT 권장**
+- **게이트웨이 측 상태 저장 금지**: 세션/로그인 컨텍스트 보관 ❌ (레이트리밋 카운터는 예외적 저장소 사용 가능)
+
+### 시퀀스(로그인 후 보호 API 호출)
+```mermaid
+sequenceDiagram
+ participant Client as 클라이언트
+ participant IdP as 인증 서버(IdP)
+ participant GW as API 게이트웨이
+ participant Svc as 내부 서비스
+
+ Client->>IdP: 로그인 (OIDC/OAuth 2.1)
+ IdP-->>Client: Access Token(JWT) 발급 + (선택)Refresh Token
+
+ Client->>GW: 보호 API 호출 (Authorization: Bearer )
+ GW->>GW: JWKS 캐시에서 kid로 공개키 가져와 JWT 서명 검증
+ GW->>GW: iss/aud/exp/nbf/Scope 등 클레임 검증 + 정책 평가(RBAC/ABAC)
+ alt 검증 성공
+ GW->>Svc: 요청 전달 (원본 JWT 또는 주입 헤더 포함)
+ Svc-->>GW: 비즈니스 응답
+ GW-->>Client: 200 OK (응답)
+ else 검증 실패
+ GW-->>Client: 401/403 에러
+ end
+```
+
+#### Spring Cloud Gateway 간단 예시(YAML)
+```yml
+spring:
+ cloud:
+ gateway:
+ default-filters:
+ - RemoveRequestHeader=Cookie
+ - DedupeResponseHeader=Access-Control-Allow-Origin Access-Control-Allow-Credentials
+ routes:
+ - id: user-api
+ uri: http://user-service
+ predicates:
+ - Path=/api/users/**
+ filters:
+ - name: JwtAuth
+ args:
+ jwk-set-uri: https://idp.example.com/.well-known/jwks.json
+ expected-issuer: https://idp.example.com
+ expected-audience: user-api
+ clock-skew: 120
+ inject-headers:
+ X-User-Id: "#{claims['sub']}"
+ X-Scopes: "#{claims['scope']}"
+
+```
+
+
+#### 운영시 체크하면 좋은 체크리스트
+- [ ] **JWKS 캐시** 및 **키 회전(kid)** 대응
+- [ ] **iss/aud/exp/nbf** 검증 + **leeway** 허용
+- [ ] **권한 정책**(경로/메서드/스코프) 중앙화
+- [ ] **멀티 테넌트**라면 `iss`/`aud` 테넌트별 매핑
+- [ ] **원본 JWT 전달/마스킹** 정책(PII 최소화)
+- [ ] **레이트리밋/서킷브레이커/CORS**는 게이트웨이에서 일괄 처리
+- [ ] **토큰 크기/헤더 크기 제한** 주의 (프록시/로드밸런서 설정 일치)
+
+
+
+### NGINX/OpenResty(Lua) 컨셉
+- `access_by_lua*`에서 **Authorization** 파싱 → **JWKS 캐시**로 서명 검증
+- 실패 시 즉시 **401 Unauthorized**, 성공 시 `X-User-*` 헤더 주입 후 **프록시 패스**
+
+
+
+
+좀더 상세히 들어간다면 ?
+
+## 🧩 NGINX / OpenResty(Lua) 기반 무상태 인증 게이트웨이 설계
+
+### 🎯 목적
+JWT 기반 인증을 **NGINX 레이어에서 직접 수행**해,
+내부 서비스에는 **검증된 요청만 전달**하고,
+서버 자체는 **완전 무상태(Stateless)** 로 유지한다.
+
+---
+
+### ⚙️ 구조 개요
+
+```mermaid
+sequenceDiagram
+ participant Client as 클라이언트
+ participant NGINX as NGINX(OpenResty + Lua)
+ participant JWKS as JWKS 서버 (Auth Provider)
+ participant Service as 내부 서비스
+
+ Client->>NGINX: Authorization: Bearer
+ NGINX->>NGINX: access_by_lua*에서 JWT 파싱
+ NGINX->>JWKS: kid 기반 JWKS 키 요청 (캐시 확인)
+ JWKS-->>NGINX: JWK 공개키 응답
+ NGINX->>NGINX: 서명 검증 + iss/aud/exp/nbf 검증
+ alt 성공
+ NGINX->>NGINX: X-User-Id, X-Scopes 등 헤더 주입
+ NGINX->>Service: 프록시 패스 (내부 API 전달)
+ Service-->>NGINX: 응답
+ NGINX-->>Client: 200 OK
+ else 실패
+ NGINX-->>Client: 401 Unauthorized
+ end
+
+```
+
+## 🧠 핵심 로직 (Lua 단계별 설명)
+
+1. Authorization 헤더 추출
+
+```lua
+local jwt_token = ngx.var.http_authorization
+if not jwt_token or not jwt_token:find("Bearer") then
+ return ngx.exit(ngx.HTTP_UNAUTHORIZED)
+end
+local token = jwt_token:gsub("Bearer ", "")
+```
+
+2. JWT 파싱 및 헤더 확인 (kid 확인)
+```lua
+local cjson = require "cjson"
+local jwt = require "resty.jwt"
+local jwt_obj = jwt:load_jwt(token)
+local kid = jwt_obj and jwt_obj.header and jwt_obj.header.kid
+if not kid then
+ ngx.log(ngx.ERR, "JWT kid not found")
+ return ngx.exit(ngx.HTTP_UNAUTHORIZED)
+end
+```
+
+3. JWKS 키 캐시 확인
+
+```lua
+local jwks_cache = ngx.shared.jwks_cache
+local jwk_key = jwks_cache:get(kid)
+if not jwk_key then
+ local http = require "resty.http"
+ local httpc = http.new()
+ local res, err = httpc:request_uri("https://idp.example.com/.well-known/jwks.json")
+ if not res or res.status ~= 200 then
+ ngx.log(ngx.ERR, "JWKS fetch failed: ", err)
+ return ngx.exit(ngx.HTTP_INTERNAL_SERVER_ERROR)
+ end
+ local jwks = cjson.decode(res.body)
+ for _, key in ipairs(jwks.keys) do
+ jwks_cache:set(key.kid, cjson.encode(key), 3600)
+ end
+ jwk_key = jwks_cache:get(kid)
+ if not jwk_key then
+ return ngx.exit(ngx.HTTP_UNAUTHORIZED)
+ end
+end
+```
+
+4. 서명 검증 및 클레임 유효성 검사
+
+```lua
+local key_obj = cjson.decode(jwk_key)
+local jwt = require "resty.jwt"
+local validators = require "resty.jwt-validators"
+
+local jwt_obj = jwt:verify_jwk_obj(key_obj, token, {
+ lifetime_grace_period = 120, -- exp 오차 허용
+ iss = "https://idp.example.com",
+ aud = "my-api"
+})
+
+if not jwt_obj.verified then
+ ngx.log(ngx.ERR, "JWT invalid: ", jwt_obj.reason)
+ return ngx.exit(ngx.HTTP_UNAUTHORIZED)
+end
+```
+
+5. 검증된 정보 헤더 주입 후 내부 서비스로 전달
+
+```lua
+ngx.req.set_header("X-User-Id", jwt_obj.payload.sub)
+ngx.req.set_header("X-Scopes", table.concat(jwt_obj.payload.scope or {}, " "))
+ngx.req.set_header("X-Tenant", jwt_obj.payload.tenant or "default")
+```
+
+### 🧩 캐싱 & 성능 전략
+| 항목 | 설명 |
+|------|------|
+| **JWKS 캐시** | `ngx.shared.DICT`에 `kid`별 JWK JSON 저장 (TTL: 1h~6h) |
+| **백오프 로직** | JWKS 서버 장애 시 기존 캐시 유지 (`ngx.timer.at` 비동기 갱신) |
+| **로컬 캐시 백업** | 초기 부팅 시 디스크 캐시 복원 (`lua-resty-lock` + 파일캐시) |
+| **서명 알고리즘 제한** | `RS256`만 허용 (HS256 금지) |
+| **exp/nbf/iat 오차 허용** | ±120초 leeway |
+
+---
+
+### 🔒 보안 포인트
+| 항목 | 설명 |
+|------|------|
+| **공개키 검증** | JWKS는 TLS 위에서만 요청, HTTP 비허용 |
+| **JWT 크기 제한** | `client_max_body_size`, `large_client_header_buffers` 설정 |
+| **PII 최소화** | 민감정보(`email`, `name`)는 X-User-* 헤더로 전달하지 않음 |
+| **CORS 정책 통합** | 게이트웨이에서 Origin/Headers/Methods 허용 제어 |
+| **Rate Limiting / Circuit Breaker** | Lua 모듈(`lua-resty-limit-traffic`, `lua-resty-circuit-breaker`)로 처리 |
+
+
+
+> 💡 **정리**
+> - OpenResty는 "NGINX + Lua" 조합으로 **무상태 인증 로직을 네트워크 계층에서 수행**할 수 있는 강력한 도구다.
+> - 서버 애플리케이션이 인증을 직접 처리하지 않아도, 게이트웨이 단에서 **JWT 검증, 클레임 주입, 접근 정책 결정**을 전부 수행할 수 있다.
+> - 이로써 전체 아키텍처가 **Stateless + Secure + Scalable** 해진다.
From f0faa2359f085db21789a94656c15c66b57cd908 Mon Sep 17 00:00:00 2001
From: Chorong0824 <124541156+sjmun09@users.noreply.github.com>
Date: 2025年10月10日 12:19:53 +0900
Subject: [PATCH 7/8] =?UTF-8?q?docs=20:=20=EB=A9=94=EC=8B=9C=EC=A7=80=20?=
=?UTF-8?q?=ED=81=90?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
...24354円213円234円354円247円200円355円201円220円.md" | 187 ++++++++++++++++++
1 file changed, 187 insertions(+)
create mode 100644 "seongjun/353円251円224円354円213円234円354円247円200円355円201円220円.md"
diff --git "a/seongjun/353円251円224円354円213円234円354円247円200円355円201円220円.md" "b/seongjun/353円251円224円354円213円234円354円247円200円355円201円220円.md"
new file mode 100644
index 0000000..6465680
--- /dev/null
+++ "b/seongjun/353円251円224円354円213円234円354円247円200円355円201円220円.md"
@@ -0,0 +1,187 @@
+# 🧱 RabbitMQ 이해를 위한 전제 지식 정리
+## 아키텍처
+```mermaid
+sequenceDiagram
+ autonumber
+ participant Client as 🧍 Client (사용자 요청)
+ participant API as 💻 API 서버 (Producer)
+ participant MQ as 📬 RabbitMQ (Broker)
+ participant Worker as ⚙️ Worker 서버 (Consumer)
+ participant DB as 🗄️ DB
+
+ Note over Client,DB: **비동기 메시지 처리 흐름**
+
+ Client->>API: 주문 요청 (POST /order)
+ API->>DB: 주문 데이터 저장
+ DB-->>API: 저장 완료 (Success)
+ API->>MQ: "주문 완료" 메시지 발행 (Publish)
+ MQ-->>API: 메시지 수신 확인 (ACK)
+ API-->>Client: 주문 성공 응답 (즉시 반환)
+
+ Note over API,Worker: 이후 비동기 처리 시작
+
+ MQ->>Worker: "주문 완료" 메시지 전달 (Consume)
+ Worker->>DB: 이메일 전송 이력 저장
+ Worker->>Client: (선택적으로) 이메일 발송 완료 알림
+```
+
+
+### 🔍 다이어그램 해석
+
+| 단계 | 설명 |
+|------|------|
+| **1.** Client가 주문 요청을 API 서버에 보냄 | 사용자는 단순히 "주문하기" 버튼을 클릭 |
+| **2.** API 서버는 DB에 주문 정보를 저장 | 핵심 트랜잭션은 즉시 완료되어야 함 |
+| **3.** DB에 저장 성공 후 RabbitMQ로 이벤트 발행 | `"order.created"` 같은 메시지를 MQ로 Publish |
+| **4.** RabbitMQ는 메시지를 Queue에 안전하게 저장 | ACK으로 API에 전달 완료 알림 |
+| **5.** API는 클라이언트에 빠르게 응답 | 비동기 처리이므로 기다리지 않음 |
+| **6.** Worker(Consumer)는 MQ에서 메시지를 꺼내 후속 작업 수행 | 예: 이메일, 포인트 적립, 알림 등 |
+| **7.** Worker가 처리 완료 후 DB에 결과 기록 | 재시도나 장애 대비 가능 |
+
+---
+
+#### 💡 핵심 요약
+
+- **동기식(요청-응답)** : Client ↔ API ↔ DB
+- **비동기식(이벤트 처리)** : API ↔ RabbitMQ ↔ Worker
+- **RabbitMQ 역할**
+ - 시스템 간 결합도 최소화 (Decoupling)
+ - 장애 시 메시지 유실 방지 (Persistent Queue)
+ - 처리량 폭주 시 버퍼링 역할
+
+---
+
+#### 🧭 흐름 시각적으로 정리하면
+```
+Client
+↓ (요청)
+API 서버
+↓ (DB 저장)
+데이터베이스
+↳ 성공
+↓
+RabbitMQ (메시지 브로커)
+↓
+Worker 서버 (Consumer)
+↓
+이메일 발송 / 포인트 적립 / 알림 처리
+```
+> 💬 즉, **RabbitMQ는 요청-응답 구조에서 벗어나, "이벤트 기반 비동기 흐름"을 가능하게 해주는 중개자**이다.
+
+
+## 1️⃣ 메시징 시스템의 기본 개념
+
+| 구성요소 | 설명 |
+|-----------|------|
+| **Producer** | 메시지를 생성해 보내는 주체. (예: 주문 완료 이벤트 발행) |
+| **Consumer** | 메시지를 받아서 처리하는 주체. (예: 이메일 발송 시스템) |
+| **Broker** | 메시지를 중개·저장·분배하는 서버 (RabbitMQ, Kafka 등) |
+| **Queue** | 메시지가 소비되기 전 임시로 저장되는 버퍼 공간 |
+| **Message** | 실제로 전달되는 데이터 단위 (JSON, 문자열, 객체 등) |
+
+> 💡 기본 흐름: **Producer → Broker → Consumer**
+
+---
+
+## 2️⃣ 비동기 통신 (RabbitMQ의 필요성)
+
+| 구분 | 동기(Synchronous) | 비동기(Asynchronous) |
+|------|--------------------|----------------------|
+| 방식 | 요청 후 응답까지 기다림 | 요청 후 바로 다음 작업 수행 |
+| 예시 | REST API 호출 (결과 기다림) | MQ에 이벤트를 넣고 나중에 처리 |
+| 장점 | 단순, 직관적 | 응답 지연 감소, 확장성 높음 |
+| 단점 | 느림, 병목 발생 | 복잡한 설계 필요 (큐 관리 등) |
+
+> 🚀 RabbitMQ는 비동기 이벤트 기반 아키텍처를 위한 메시지 브로커이다.
+
+---
+
+## 3️⃣ 메시지 큐(Message Queue)의 역할
+
+### ✅ 왜 필요한가?
+- 서비스 간 **결합도 낮추기 (Decoupling)**
+- **트래픽 폭주 제어 (Buffering)**
+- **비동기 처리**를 통한 **응답 시간 단축**
+- **신뢰성 보장 (ACK, 재시도, DLQ 등)**
+
+### 🧠 예시
+> 주문 시스템(Producer)이 ‘주문 완료’ 메시지를 MQ에 넣으면,
+> 이메일 시스템(Consumer)이 MQ에서 메시지를 꺼내 이메일을 발송한다.
+
+---
+
+## 4️⃣ 메시징 패턴의 기본 구조
+
+| 패턴 | 설명 | 예시 |
+|------|------|------|
+| **단순 큐(Simple Queue)** | 1:1 메시징 | 주문 → 이메일 발송 |
+| **Fanout (Pub/Sub)** | 1:N 메시징 (모든 Consumer에게 전달) | 알림 브로드캐스트 |
+| **Direct** | 라우팅키 기반으로 특정 Consumer에게 전달 | 로그 레벨별 큐 분리 |
+| **Topic** | 와일드카드 기반 라우팅 | `topic.key.*` 형태 |
+| **Header** | 헤더값 조건으로 라우팅 | 필터링 메시징 |
+
+---
+
+## 5️⃣ 전송 보장 수준 (Delivery Guarantee)
+
+| 수준 | 설명 |
+|------|------|
+| **At most once** | 최대 한 번 전달 (유실 가능) |
+| **At least once** | 최소 한 번 전달 (중복 가능) |
+| **Exactly once** | 정확히 한 번 전달 (복잡, 트랜잭션 기반) |
+
+> ⚙️ RabbitMQ는 보통 **At least once** 전략을 사용하며
+> ACK/NACK, 재전송(requeue) 메커니즘으로 이를 보장한다.
+
+---
+
+## 6️⃣ AMQP 프로토콜 (RabbitMQ의 핵심)
+
+RabbitMQ는 **AMQP (Advanced Message Queuing Protocol)** 기반으로 동작한다.
+
+| 구성요소 | 설명 |
+|-----------|------|
+| **Exchange** | 메시지를 받아 라우팅하는 분배기 |
+| **Queue** | 메시지를 임시 저장하는 버퍼 |
+| **Binding** | Exchange → Queue로 메시지를 연결하는 규칙 |
+| **Routing Key** | 어떤 Queue로 보낼지 결정하는 식별자 |
+| **Channel** | 하나의 TCP 연결 내에서의 논리적 세션 |
+| **Connection** | Producer/Consumer ↔ Broker 간 실제 TCP 연결 |
+
+> 🔄 **Exchange → (Binding Rule) → Queue → Consumer**
+
+---
+
+## 7️⃣ RabbitMQ vs Kafka 비교
+
+| 항목 | RabbitMQ | Kafka |
+|------|-----------|--------|
+| 목적 | 메시지 브로커 (즉시 처리 중심) | 로그 스트리밍 (대용량 이벤트 중심) |
+| 프로토콜 | **AMQP 표준** | 자체 프로토콜 |
+| 모델 | Queue 기반 (Push + Pull) | Log 기반 (Pull Only) |
+| 순서 보장 | Queue 단위 | 파티션 단위 |
+| 주요 사용처 | 이메일/결제/비동기 이벤트 | 로그 수집/실시간 데이터 파이프라인 |
+
+---
+
+## ✅ 다음 단계 제안
+
+이제 RabbitMQ 자체 구조로 들어가면 된다 👇
+
+### 📘 RabbitMQ 본격 정리 목차
+1. RabbitMQ란? (역사와 개요)
+2. AMQP 아키텍처 상세 구조
+3. Exchange 타입별 동작 (Direct, Topic, Fanout, Headers)
+4. 메시지 전달 보장 메커니즘 (ACK, DLQ, TTL 등)
+5. 클러스터링 & 고가용성 (HA Queue, Quorum Queue)
+6. 운영/모니터링 (Management UI, Channel 관리)
+7. Spring AMQP & Cloud Stream 연동 구조
+8. Kafka와 RabbitMQ 비교 (Use Case 중심)
+
+---
+
+> 💬 다음은 "📘 RabbitMQ 본격 정리 — 1️⃣ RabbitMQ란?" 부터 시작
+
+---
+
+
From 81a3133e0dc98585b97b709f8c67d0e5c4616ca0 Mon Sep 17 00:00:00 2001
From: tkdtn4657
Date: 2025年10月19日 23:50:34 +0900
Subject: [PATCH 8/8] =?UTF-8?q?docs:=20RAFT=20=ED=95=A9=EC=9D=98=20?=
=?UTF-8?q?=EC=95=8C=EA=B3=A0=EB=A6=AC=EC=A6=98=20=EB=AC=B8=EC=84=9C=20?=
=?UTF-8?q?=EC=9E=91=EC=84=B1?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
sangsu/RAFT_Algorithm.md | 46 ++++++++++++++++++++++++++++++++++++++++
1 file changed, 46 insertions(+)
create mode 100644 sangsu/RAFT_Algorithm.md
diff --git a/sangsu/RAFT_Algorithm.md b/sangsu/RAFT_Algorithm.md
new file mode 100644
index 0000000..6bf49fb
--- /dev/null
+++ b/sangsu/RAFT_Algorithm.md
@@ -0,0 +1,46 @@
+# RAFT
+
+## 클러스터란?
+
+RAFT에 설명하기에 앞서 클러스터 용어의 설명이 선행되어야 합니다. 클러스터(Cluster)는 여러 대의 서버(노드)가 하나의 시스템처럼 동작하도록 구성된 집합체입니다.
+
+이를 통해 시스템은 장애 발생 시에도 서비스를 지속할 수 있는 **고가용성(HA)** 과 **데이터 일관성**을 보장할 수 있습니다.
+
+## RAFT 란?
+
+**RAFT(Raft Consensus Algorithm)** 는 분산 시스템에서 **여러 노드 간 데이터 일관성과 합의를 유지하기 위한 리더 선출 기반의 합의 알고리즘**으로 리더 선출과 로그 복제를 통해 일관성을 확보합니다.
+
+클러스터 내 노드는 리더(Leader)와 팔로워(Follower)로 구분되며, 리더는 주기적으로 하트비트(Heartbeat) 신호를 전송하여 팔로워의 상태를 모니터링하고 클러스터의 정상 동작을 유지합니다.
+
+[画像:image]
+
+## 리더 선거
+
+리더는 주기적으로 하트비트를 전송하여 팔로워의 상태를 점검합니다.
+
+팔로워 노드는 리더로부터 일정 시간(ex: 150~300ms) 하트비트 메시지를 받지 못하면 **리더 장애로 판단**하고, 스스로 **후보자**(Candidate)로 전환한 뒤 새로운 리더를 선출하는 **텀**이 시행 됩니다.
+
+텀은 리더 선출하는 임의의 기간으로, 각 후보 노드 중 과반수 표를 받으면 리더 선출이 완료됩니다.
+
+리더 선출이 성공적으로 완료되면 새 리더가 조정하는 정상적인 운영을 진행합니다.
+
+[画像:image]
+
+## 로그 복제
+
+리더는 클라이언트의 요청을 로그 형태로 기록하고, 이를 모든 팔로워에게 복제합니다. 과반수의 팔로워가 로그를 수신·저장했다는 응답을 보내면 리더는 해당 로그를 **커밋(Commit)** 하며, 커밋된 로그는 모든 노드에 동일하게 적용되어 클러스터의 **데이터 일관성**을 유지합니다.
+
+## RAFT를 왜 사용하는가?
+
+RAFT를 사용하면 다중 환경 시스템에서 클러스터 내의 고가용성을 보장하기 편리하기 때문입니다.
+
+예를 들어 MongoDB의 Replica Set 구조에서는 데이터를 저장할 때 리더에 최초 저장, 이후 팔로워가 리더의 데이터를 참고해서 복제하는 방식으로 동작합니다. 이 때 팔로워는 복제(Replication)되었기 때문에 백업 서버로 활용될 수 있으며, 고가용성(High Availability)을 위한 교체 서버로 활용할 수 있기 때문입니다.
+
+## RAFT 합의 알고리즘 실 사용 사례
+
+다양한 곳에서 RAFT 합의 알고리즘을 활용함
+
+- IBM MQ
+- MongoDB
+- RabbitMQ
+- Apache Kafka (KRaft)