You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
1. fetcher.py - This script is used to scrape course data from udemy based on the category entered as input by the user
4
+
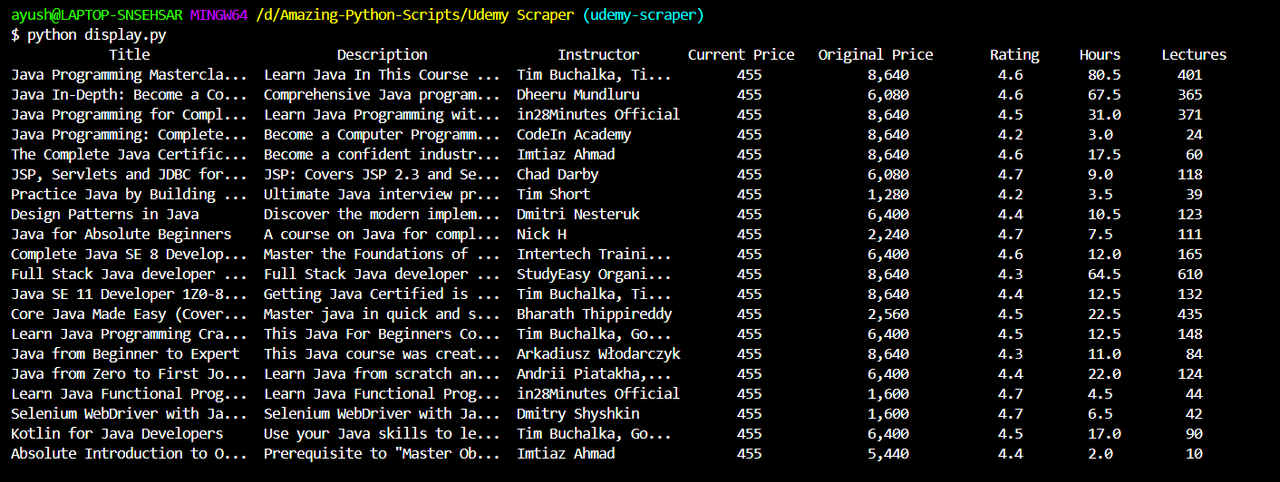
2. display.py - This script is used to display the scraped courses from the database to the terminal
5
+
6
+
## Setup instructions
7
+
In order to run this script, you need to have Python and pip installed on your system. After you're done installing Python and pip, run the following command from your terminal to install the requirements from the same folder (directory) of the project.
8
+
```
9
+
pip install -r requirements.txt
10
+
```
11
+
12
+
After satisfying all the requirements for the project, Open the terminal in the project folder and run
13
+
```
14
+
python fetcher.py
15
+
python display.py
16
+
```
17
+
or
18
+
```
19
+
python3 fetcher.py
20
+
python3 display.py
21
+
```
22
+
depending upon the python version. Make sure that you are running the command from the same virtual environment in which the required modules are installed.
23
+
24
+
## Output
25
+
26
+
27
+
0 commit comments