- * jdk8中:
- * -XX:MetaspaceSize=10m -XX:MaxMetaspaceSize=10m
- *
- * @author IceBlue
- * @create 2020 22:24
- */
-public class OOMTest extends ClassLoader {
- public static void main(String[] args) {
- int j = 0;
- try {
- for (int i = 0; i < 100000; i++) { - OOMTest test = new OOMTest(); - //创建ClassWriter对象,用于生成类的二进制字节码 - ClassWriter classWriter = new ClassWriter(0); - //指明版本号,修饰符,类名,包名,父类,接口 - classWriter.visit(Opcodes.V1_8, Opcodes.ACC_PUBLIC, "Class" + i, null, "java/lang/Object", null); - //返回byte[] - byte[] code = classWriter.toByteArray(); - //类的加载 - test.defineClass("Class" + i, code, 0, code.length);//Class对象 - test = null; - j++; - } - } finally { - System.out.println(j); - } - } -} -``` - -输出结果: - -``` -[GC (Metadata GC Threshold) [PSYoungGen: 10485K->1544K(152576K)] 10485K->1552K(500736K), 0.0011517 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
-[Full GC (Metadata GC Threshold) [PSYoungGen: 1544K->0K(152576K)] [ParOldGen: 8K->658K(236544K)] 1552K->658K(389120K), [Metaspace: 3923K->3320K(1056768K)], 0.0051012 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]
-[GC (Metadata GC Threshold) [PSYoungGen: 5243K->832K(152576K)] 5902K->1490K(389120K), 0.0009536 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
-
--------省略N行-------
-
-[Full GC (Last ditch collection) [PSYoungGen: 0K->0K(2427904K)] [ParOldGen: 824K->824K(5568000K)] 824K->824K(7995904K), [Metaspace: 3655K->3655K(1056768K)], 0.0041177 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
-Heap
- PSYoungGen total 2427904K, used 0K [0x0000000755f80000, 0x00000007ef080000, 0x00000007ffe00000)
- eden space 2426880K, 0% used [0x0000000755f80000,0x0000000755f80000,0x00000007ea180000)
- from space 1024K, 0% used [0x00000007ea180000,0x00000007ea180000,0x00000007ea280000)
- to space 1536K, 0% used [0x00000007eef00000,0x00000007eef00000,0x00000007ef080000)
- ParOldGen total 5568000K, used 824K [0x0000000602200000, 0x0000000755f80000, 0x0000000755f80000)
- object space 5568000K, 0% used [0x0000000602200000,0x00000006022ce328,0x0000000755f80000)
- Metaspace used 3655K, capacity 4508K, committed 9728K, reserved 1056768K
- class space used 394K, capacity 396K, committed 2048K, reserved 1048576K
-
-进程已结束,退出代码0
-
-```
-
-通过不断地动态生成类对象,输出GC日志
-
-根据GC日志我们可以看出当元空间容量耗尽时,会触发FullGC,而每次FullGC之前,至会进行一次MinorGC,而MinorGC只会回收新生代空间;
-
-只有在FullGC时,才会对新生代,老年代,永久代/元空间全部进行垃圾收集
\ No newline at end of file
diff --git "a/JDK/Java8347円274円226円347円250円213円346円234円200円344円275円263円345円256円236円350円267円265円/344円270円200円346円226円207円346円220円236円346円207円202円Java347円232円204円SPI346円234円272円345円210円266円.md" "b/JDK/Java8347円274円226円347円250円213円346円234円200円344円275円263円345円256円236円350円267円265円/344円270円200円346円226円207円346円220円236円346円207円202円Java347円232円204円SPI346円234円272円345円210円266円.md"
deleted file mode 100644
index 1c69b61c1e..0000000000
--- "a/JDK/Java8347円274円226円347円250円213円346円234円200円344円275円263円345円256円236円350円267円265円/344円270円200円346円226円207円346円220円236円346円207円202円Java347円232円204円SPI346円234円272円345円210円266円.md"
+++ /dev/null
@@ -1,63 +0,0 @@
-# 1 简介
-SPI,Service Provider Interface,一种服务发现机制。
-
-有了SPI,即可实现服务接口与服务实现的解耦:
-- 服务提供者(如 springboot starter)提供出 SPI 接口。身为服务提供者,在你无法形成绝对规范强制时,适度"放权" 比较明智,适当让客户端去自定义实现
-- 客户端(普通的 springboot 项目)即可通过本地注册的形式,将实现类注册到服务端,轻松实现可插拔
-
-## 缺点
-- 不能按需加载。虽然 ServiceLoader 做了延迟加载,但是只能通过遍历的方式全部获取。如果其中某些实现类很耗时,而且你也不需要加载它,那么就形成了资源浪费
-- 获取某个实现类的方式不够灵活,只能通过迭代器的形式获取
-
-> Dubbo SPI 实现方式对以上两点进行了业务优化。
-
-# 源码
-
-应用程序通过迭代器接口获取对象实例,这里首先会判断 providers 对象中是否有实例对象:
-- 有实例,那么就返回
-- 没有,执行类的装载步骤,具体类装载实现如下:
-
-LazyIterator#hasNextService 读取 META-INF/services 下的配置文件,获得所有能被实例化的类的名称,并完成 SPI 配置文件的解析
-
-
-LazyIterator#nextService 负责实例化 hasNextService() 读到的实现类,并将实例化后的对象存放到 providers 集合中缓存
-
-# 使用
-如某接口有3个实现类,那系统运行时,该接口到底选择哪个实现类呢?
-这时就需要SPI,**根据指定或默认配置,找到对应实现类,加载进来,然后使用该实现类实例**。
-
-如下系统运行时,加载配置,用实现A2实例化一个对象来提供服务:
-
-再如,你要通过jar包给某个接口提供实现,就在自己jar包的`META-INF/services/`目录下放一个接口同名文件,指定接口的实现是自己这个jar包里的某类即可:
-
-别人用这个接口,然后用你的jar包,就会在运行时通过你的jar包指定文件找到这个接口该用哪个实现类。这是JDK内置提供的功能。
-
-> 我就不定义在 META-INF/services 下面行不行?就想定义在别的地方可以吗?
-
-No!JDK 已经规定好配置路径,你若随便定义,类加载器可就不知道去哪里加载了
-
-假设你有个工程P,有个接口A,A在P无实现类,系统运行时怎么给A选实现类呢?
-可以自己搞个jar包,`META-INF/services/`,放上一个文件,文件名即接口名,接口A的实现类=`com.javaedge.service.实现类A2`。
-让P来依赖你的jar包,等系统运行时,P跑起来了,对于接口A,就会扫描依赖的jar包,看看有没有`META-INF/services`文件夹:
-- 有,再看看有无名为接口A的文件:
- - 有,在里面查找指定的接口A的实现是你的jar包里的哪个类即可
-# 适用场景
-## 插件扩展
-比如你开发了一个开源框架,若你想让别人自己写个插件,安排到你的开源框架里中,扩展功能时。
-
-如JDBC。Java定义了一套JDBC的接口,但并未提供具体实现类,而是在不同云厂商提供的数据库实现包。
-> 但项目运行时,要使用JDBC接口的哪些实现类呢?
-
-一般要根据自己使用的数据库驱动jar包,比如我们最常用的MySQL,其`mysql-jdbc-connector.jar` 里面就有:
-
-系统运行时碰到你使用JDBC的接口,就会在底层使用你引入的那个jar中提供的实现类。
-## 案例
-如sharding-jdbc 数据加密模块,本身支持 AES 和 MD5 两种加密方式。但若客户端不想用内置的两种加密,偏偏想用 RSA 算法呢?难道每加一种算法,sharding-jdbc 就要发个版本?
-
-sharding-jdbc 可不会这么蠢,首先提供出 EncryptAlgorithm 加密算法接口,并引入 SPI 机制,做到服务接口与服务实现分离的效果。
-客户端想要使用自定义加密算法,只需在客户端项目 `META-INF/services` 的路径下定义接口的全限定名称文件,并在文件内写上加密实现类的全限定名
-
-
-这就显示了SPI的优点:
-- 客户端(自己的项目)提供了服务端(sharding-jdbc)的接口自定义实现,但是与服务端状态分离,只有在客户端提供了自定义接口实现时才会加载,其它并没有关联;客户端的新增或删除实现类不会影响服务端
-- 如果客户端不想要 RSA 算法,又想要使用内置的 AES 算法,那么可以随时删掉实现类,可扩展性强,插件化架构
\ No newline at end of file
diff --git "a/JDK/345円271円266円345円217円221円347円274円226円347円250円213円/Java345円271円266円345円217円221円347円274円226円347円250円213円345円256円236円346円210円230円/Java345円271円266円345円217円221円347円274円226円347円250円213円345円256円236円346円210円230円347円263円273円345円210円227円(15)-345円216円237円345円255円220円351円201円215円345円216円206円344円270円216円351円235円236円351円230円273円345円241円236円345円220円214円346円255円245円346円234円272円345円210円266円.md" "b/JDK/345円271円266円345円217円221円347円274円226円347円250円213円/Java345円271円266円345円217円221円347円274円226円347円250円213円345円256円236円346円210円230円/Java345円271円266円345円217円221円347円274円226円347円250円213円345円256円236円346円210円230円347円263円273円345円210円22715円344円271円213円345円216円237円345円255円220円351円201円215円345円216円206円344円270円216円351円235円236円351円230円273円345円241円236円345円220円214円346円255円245円346円234円272円345円210円266円(Atomic-Variables-and-Non-blocking-Synchron.md"
similarity index 68%
rename from "JDK/345円271円266円345円217円221円347円274円226円347円250円213円/Java345円271円266円345円217円221円347円274円226円347円250円213円345円256円236円346円210円230円/Java345円271円266円345円217円221円347円274円226円347円250円213円345円256円236円346円210円230円347円263円273円345円210円227円(15)-345円216円237円345円255円220円351円201円215円345円216円206円344円270円216円351円235円236円351円230円273円345円241円236円345円220円214円346円255円245円346円234円272円345円210円266円.md"
rename to "JDK/345円271円266円345円217円221円347円274円226円347円250円213円/Java345円271円266円345円217円221円347円274円226円347円250円213円345円256円236円346円210円230円/Java345円271円266円345円217円221円347円274円226円347円250円213円345円256円236円346円210円230円347円263円273円345円210円22715円344円271円213円345円216円237円345円255円220円351円201円215円345円216円206円344円270円216円351円235円236円351円230円273円345円241円236円345円220円214円346円255円245円346円234円272円345円210円266円(Atomic-Variables-and-Non-blocking-Synchron.md"
index 5aece1fb28..13eabf7add 100644
--- "a/JDK/345円271円266円345円217円221円347円274円226円347円250円213円/Java345円271円266円345円217円221円347円274円226円347円250円213円345円256円236円346円210円230円/Java345円271円266円345円217円221円347円274円226円347円250円213円345円256円236円346円210円230円347円263円273円345円210円227円(15)-345円216円237円345円255円220円351円201円215円345円216円206円344円270円216円351円235円236円351円230円273円345円241円236円345円220円214円346円255円245円346円234円272円345円210円266円.md"
+++ "b/JDK/345円271円266円345円217円221円347円274円226円347円250円213円/Java345円271円266円345円217円221円347円274円226円347円250円213円345円256円236円346円210円230円/Java345円271円266円345円217円221円347円274円226円347円250円213円345円256円236円346円210円230円347円263円273円345円210円22715円344円271円213円345円216円237円345円255円220円351円201円215円345円216円206円344円270円216円351円235円236円351円230円273円345円241円236円345円220円214円346円255円245円346円234円272円345円210円266円(Atomic-Variables-and-Non-blocking-Synchron.md"
@@ -1,30 +1,32 @@
-非阻塞算法,用底层的原子机器指令代替锁,确保数据在并发访问中的一致性。
-非阻塞算法被广泛应用于OS和JVM中实现线程/进程调度机制和GC及锁,并发数据结构中。
+近年并发算法领域大多数研究都侧重非阻塞算法,这种算法用底层的原子机器指令代替锁来确保数据在并发访问中的一致性,非阻塞算法被广泛应用于OS和JVM中实现线程/进程调度机制和GC以及锁,并发数据结构中。
+
+与锁的方案相比,非阻塞算法都要复杂的多,他们在可伸缩性和活跃性上(避免死锁)都有巨大优势。
-与锁相比,非阻塞算法复杂的多,在可伸缩性和活跃性上(避免死锁)有巨大优势。
非阻塞算法,即多个线程竞争相同的数据时不会发生阻塞,因此能更细粒度的层次上进行协调,而且极大减少调度开销。
# 1 锁的劣势
独占,可见性是锁要保证的。
-许多JVM都对非竞争的锁获取和释放做了很多优化,性能很不错。
-但若一些线程被挂起然后稍后恢复运行,当线程恢复后还得等待其他线程执行完他们的时间片,才能被调度,所以挂起和恢复线程存在很大开销。
-其实很多锁的粒度很小,很简单,若锁上存在激烈竞争,那么 调度开销/工作开销 比值就会非常高,降低业务吞吐量。
+许多JVM都对非竞争的锁获取和释放做了很多优化,性能很不错了。
+
+但是如果一些线程被挂起然后稍后恢复运行,当线程恢复后还得等待其他线程执行完他们的时间片,才能被调度,所以挂起和恢复线程存在很大的开销,其实很多锁的力度很小的,很简单,如果锁上存在着激烈的竞争,那么多调度开销/工作开销比值就会非常高。
+
+与锁相比volatile是一种更轻量的同步机制,因为使用volatile不会发生上下文切换或者线程调度操作,但是volatile的指明问题就是虽然保证了可见性,但是原子性无法保证,比如i++的字节码就是N行。
-而与锁相比,volatile是一种更轻量的同步机制,因为使用volatile不会发生上下文切换或线程调度操作,但volatile的指明问题就是虽然保证了可见性,但是原子性无法保证。
+如果一个线程正在等待锁,它不能做任何事情,如果一个线程在持有锁的情况下呗延迟执行了,例如发生了缺页错误,调度延迟,那么就没法执行。如果被阻塞的线程优先级较高,那么就会出现priority invesion的问题,被永久的阻塞下去。
-- 若一个线程正在等待锁,它不能做任何事情
-- 若一个线程在持有锁情况下被延迟执行了,如发生缺页错误,调度延迟,就没法执行
-- 若被阻塞的线程优先级较高,就会出现priority invesion问题,被永久阻塞
# 2 硬件对并发的支持
-独占锁是悲观锁,对细粒度的操作,更高效的应用是乐观锁,这种方法需要借助**冲突监测机制,来判断更新过程中是否存在来自其他线程的干扰,若存在,则失败重试**。
-几乎所有现代CPU都有某种形式的原子读-改-写指令,如compare-and-swap等,JVM就是使用这些指令来实现无锁并发。
+独占锁是悲观所,对于细粒度的操作,更高效的应用是乐观锁,这种方法需要借助**冲突监测机制来判断更新过程中是否存在来自其他线程的干扰,如果存在则失败重试**。
+
+几乎所有的现代CPU都有某种形式的原子读-改-写指令,例如compare-and-swap等,JVM就是使用这些指令来实现无锁并发。
+
## 2.1 比较并交换
+
CAS(Compare and set)乐观的技术。Java实现的一个compare and set如下,这是一个模拟底层的示例:
+
```java
@ThreadSafe
public class SimulatedCAS {
-
@GuardedBy("this") private int value;
public synchronized int get() {
@@ -45,7 +47,9 @@ public class SimulatedCAS {
== compareAndSwap(expectedValue, newValue));
}
}
+
```
+
## 2.2 非阻塞的计数器
```java
public class CasCounter {
@@ -63,12 +67,14 @@ public class CasCounter {
return v + 1;
}
}
+
```
Java中使用AtomicInteger。
竞争激烈一般时,CAS性能远超基于锁的计数器。看起来他的指令更多,但无需上下文切换和线程挂起,JVM内部的代码路径实际很长,所以反而好些。
-但激烈程度较高时,开销还是较大,但会发生这种激烈程度非常高的情况只是理论,实际生产环境很难遇到。况且JIT很聪明,这种操作往往能非常大的优化。
+但激烈程度较高时,它的开销还是较大,但是你会发生这种激烈程度非常高的情况只是理论,实际生产环境很难遇到。
+况且JIT很聪明,这种操作往往能非常大的优化。
为确保正常更新,可能得将CAS操作放到for循环,从语法结构看,使用**CAS**比使用锁更加复杂,得考虑失败情况(锁会挂起线程,直到恢复)。
但基于**CAS**的原子操作,性能基本超过基于锁的计数器,即使只有很小的竞争或不存在竞争!
@@ -76,19 +82,37 @@ Java中使用AtomicInteger。
在轻度到中度争用情况下,非阻塞算法的性能会超越阻塞算法,因为 CAS 的多数时间都在第一次尝试时就成功,而发生争用时的开销也不涉及**线程挂起**和**上下文切换**,只多了几个循环迭代。
没有争用的 CAS 要比没有争用的锁轻量得多(因为没有争用的锁涉及 CAS 加上额外的处理,加锁至少需要一个CAS,在有竞争的情况下,需要操作队列,线程挂起,上下文切换),而争用的 CAS 比争用的锁获取涉及更短的延迟。
-CAS的缺点是,它使用调用者来处理竞争问题,通过重试、回退、放弃,而锁能自动处理竞争问题,例如阻塞。
+CAS的缺点是它使用调用者来处理竞争问题,通过重试、回退、放弃,而锁能自动处理竞争问题,例如阻塞。
-原子变量可看做更好的volatile类型变量。AtomicInteger在JDK8里面做了改动。
-
+原子变量可以看做更好的volatile类型变量。
+AtomicInteger在JDK8里面做了改动。
+```java
+public final int getAndIncrement() {
+ return unsafe.getAndAddInt(this, valueOffset, 1);
+}
+
+```
JDK7里面的实现如下:
-
-Unsafe是经过特殊处理的,不能理解成常规的Java代码,1.8在调用getAndAddInt时,若系统底层:
-- 支持fetch-and-add,则执行的就是native方法,使用fetch-and-add
-- 不支持,就按照上面getAndAddInt那样,以Java代码方式执行,使用compare-and-swap
+```java
+public final int getAndAdd(int delta) {
+ for(;;) {
+ intcurrent= get();
+ intnext=current+delta;
+ if(compareAndSet(current,next))
+ returncurrent;
+ }
+ }
+
+```
+Unsafe是经过特殊处理的,不能理解成常规的Java代码,区别在于:
+- 1.8在调用getAndAddInt的时候,如果系统底层支持fetch-and-add,那么它执行的就是native方法,使用的是fetch-and-add
+- 如果不支持,就按照上面的所看到的getAndAddInt方法体那样,以java代码的方式去执行,使用的是compare-and-swap
这也正好跟openjdk8中Unsafe::getAndAddInt上方的注释相吻合:
-以下包含在不支持本机指令的平台上使用的基于 CAS 的 Java 实现
-
+```java
+// The following contain CAS-based Java implementations used on
+// platforms not supporting native instructions
+```
# 3 原子变量类
J.U.C的AtomicXXX。
@@ -140,11 +164,18 @@ public class CasNumberRange {
}
}
}
+
```
+
+
# 4 非阻塞算法
+
Lock-free算法,可以实现栈、队列、优先队列或者散列表。
+
## 4.1 非阻塞的栈
-Trebier算法,1986年提出。
+
+Trebier算法,1986年提出的。
+
```java
public class ConcurrentStack
-## 4 目录结构
+## 4 目录结构(不断优化中)
| 数据结构与算法 | 操作系统 | 网络 | 面向对象 | 数据存储 | Java | 架构设计 | 框架 | 编程规范 | 职业规划 |
| :--------: | :---------: | :---------: | :---------: | :---------: | :---------:| :---------: | :-------: | :-------:| :------:|
@@ -83,6 +93,15 @@
### :memo: 职业规划
+## QQ 技术交流群
+
+为大家提供一个学习交流平台,在这里你可以自由地讨论技术问题。
+
+
+
+## 微信交流群
+
+
### 本人微信
@@ -95,17 +114,4 @@
### 绘图工具
- [draw.io](https://www.draw.io/)
-- keynote
-
-再分享我整理汇总的一些 Java 面试相关资料(亲自验证,严谨科学!别再看网上误导人的垃圾面试题!!!),助你拿到更多 offer!
-
-
-
-[点击获取更多经典必读电子书!](https://mp.weixin.qq.com/s?__biz=MzUzNTY5MzA3MQ==&mid=2247497273&idx=1&sn=b0f1e2e03cd7de3ce5d93cc8793d6d88&chksm=fa832459cdf4ad4fb046c0beb7e87ecea48f338278846679ef65238af45f0a135720e7061002&token=766333302&lang=zh_CN#rd)
-
-2023年最新Java学习路线一条龙:
-
-[](https://www.nowcoder.com/discuss/353159357007339520?sourceSSR=users)
-
-
-再给大家推荐一个学习 前后端软件开发 和准备Java 面试的公众号[【JavaEdge】](https://mp.weixin.qq.com/s?__biz=MzUzNTY5MzA3MQ==&mid=2247498257&idx=1&sn=b09d88691f9bfd715e000b69ef61227e&chksm=fa832871cdf4a1675d4491727399088ca488fa13e0a3cdf2ece3012265e5a3ef273dff540879&token=766333302&lang=zh_CN#rd)(强烈推荐!)
+- keynote
\ No newline at end of file
diff --git "a/Spring/Spring RestTemplate344円270円272円344円275円225円345円277円205円351円241円273円346円220円255円351円205円215円MultiValueMap357円274円237円.md" "b/Spring/Spring RestTemplate344円270円272円344円275円225円345円277円205円351円241円273円346円220円255円351円205円215円MultiValueMap357円274円237円.md"
deleted file mode 100644
index 0281c13f2c..0000000000
--- "a/Spring/Spring RestTemplate344円270円272円344円275円225円345円277円205円351円241円273円346円220円255円351円205円215円MultiValueMap357円274円237円.md"
+++ /dev/null
@@ -1,53 +0,0 @@
-微服务之间的大多都是使用 HTTP 通信,这自然少不了使用 HttpClient。
-在不适用 Spring 前,一般使用 Apache HttpClient 和 Ok HttpClient 等,而一旦引入 Spring,就有了更好选择 - RestTemplate。
-
-接口:
-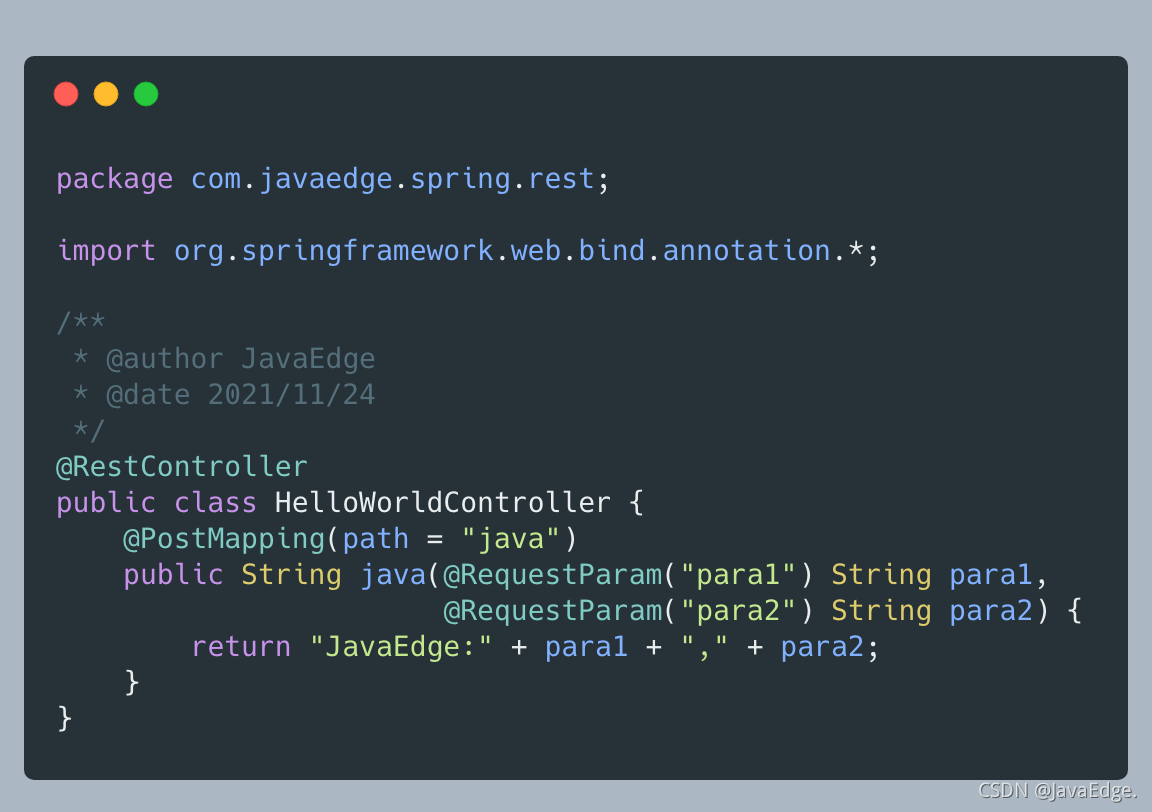
-想接受一个 Form 表单请求,读取表单定义的两个参数 para1 和 para2,然后作为响应返回给客户端。
-
-定义完接口后,使用 RestTemplate 来发送一个这样的表单请求,代码示例如下:
-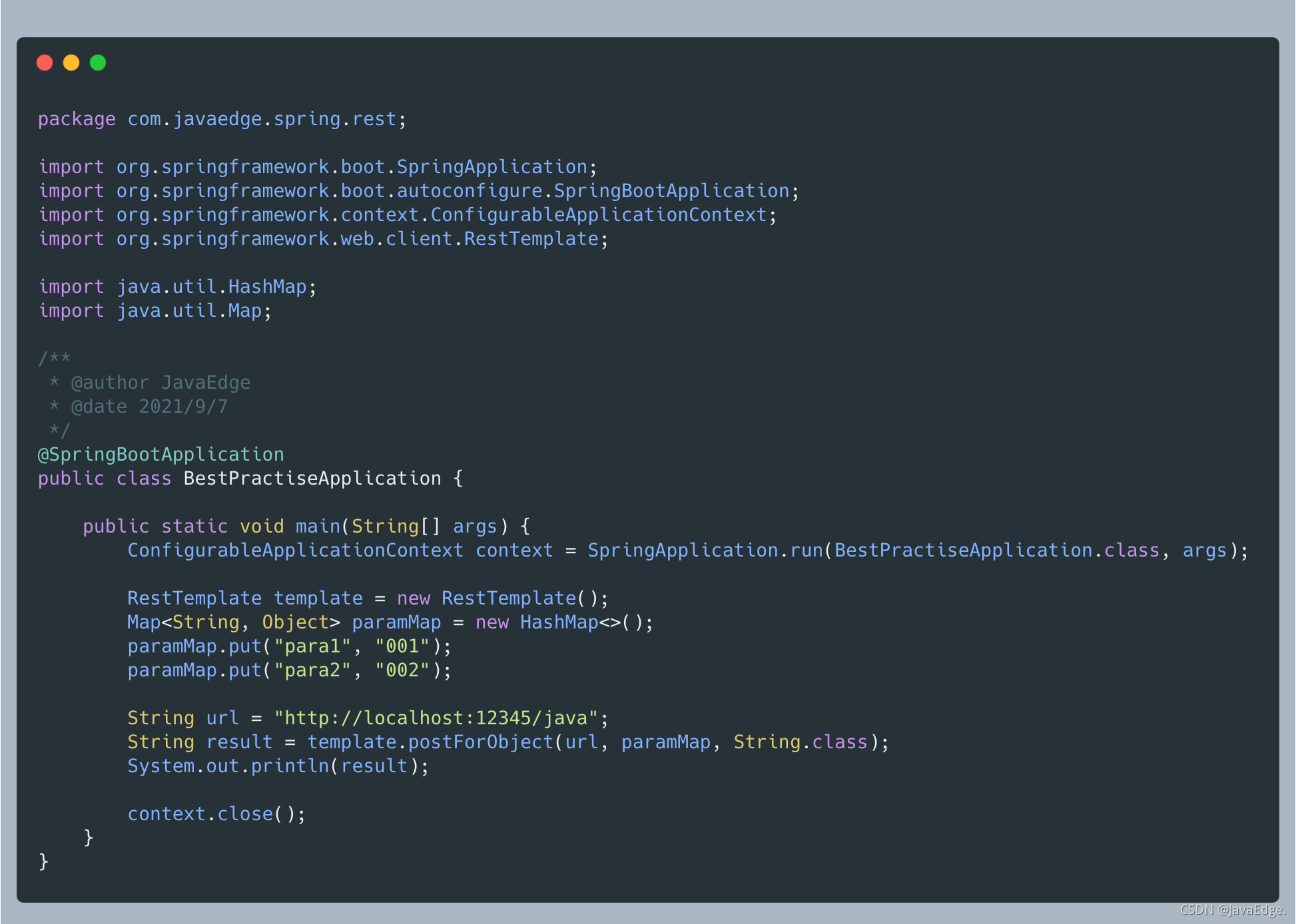
-上述代码定义了一个 Map,包含了 2 个表单参数,然后使用 RestTemplate 的 postForObject 提交这个表单。
-执行代码提示 400 错误,即请求出错:
-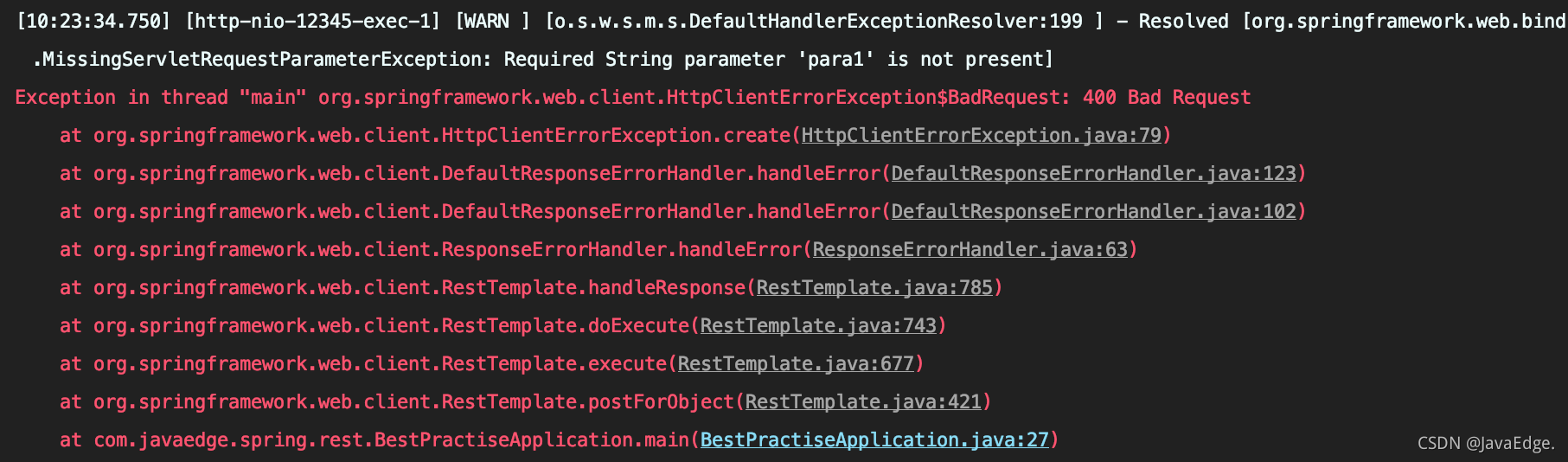
-就是缺少 para1 表单参数,why?
-# 解析
-RestTemplate 提交的表单,最后提交请求啥样?
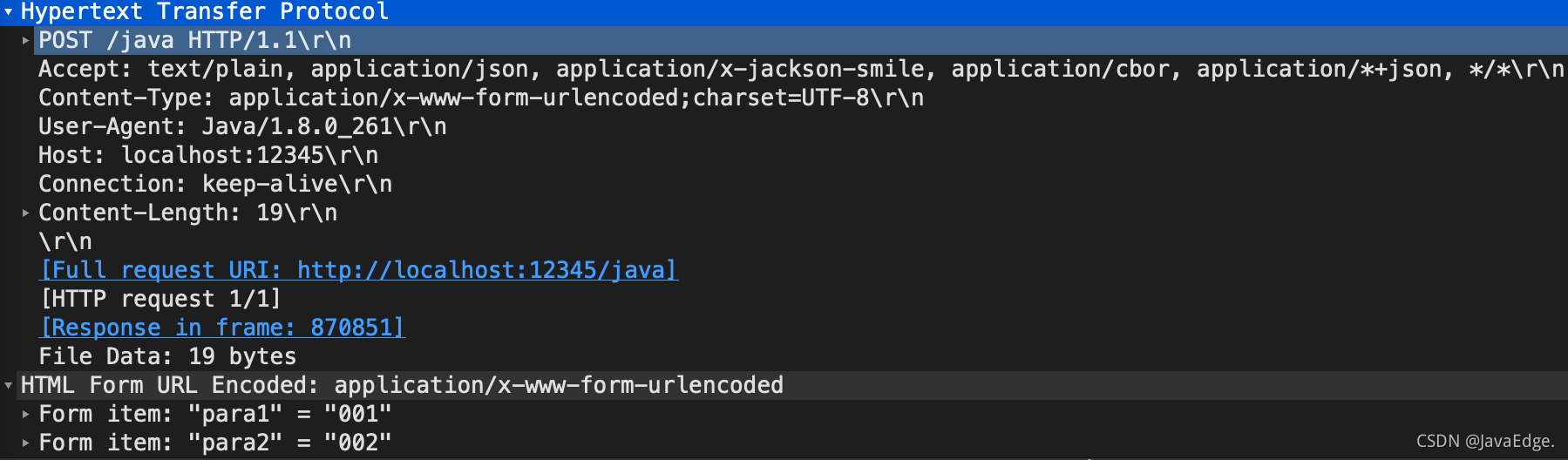
-Wireshark 抓包:
-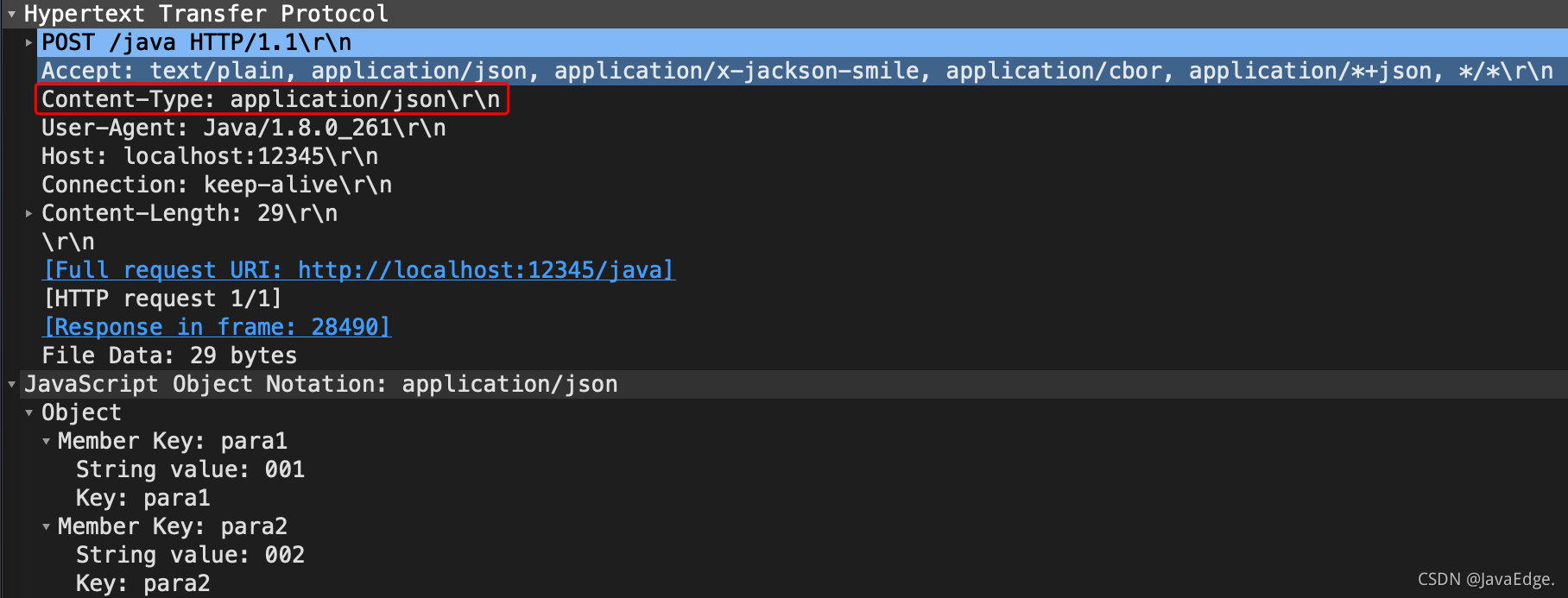
-实际上是将定义的表单数据以 JSON 提交过去了,所以我们的接口处理自然取不到任何表单参数。
-why?怎么变成 JSON 请求体提交数据呢?注意 RestTemplate 执行调用栈:
-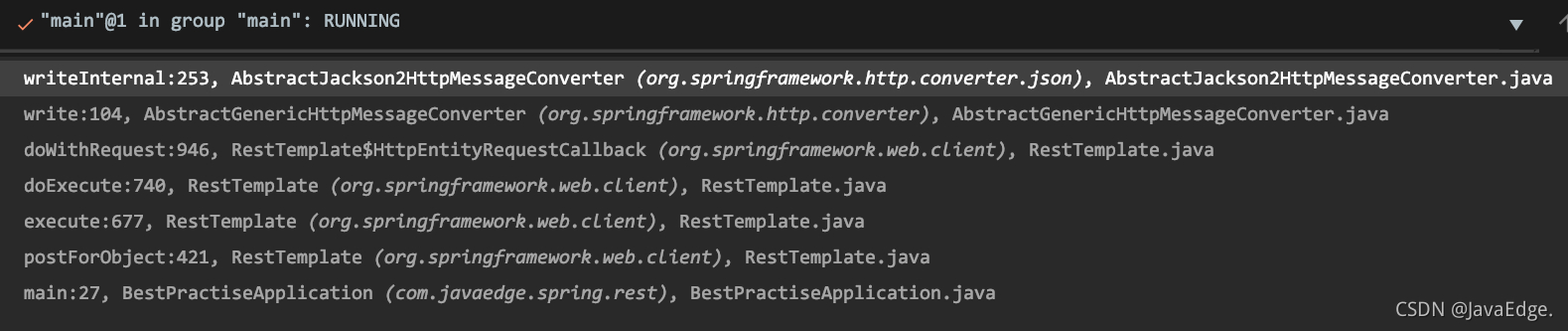
-最终使用的 Jackson 工具序列化了表单
-
-用到 JSON 的关键原因在
-### RestTemplate.HttpEntityRequestCallback#doWithRequest
-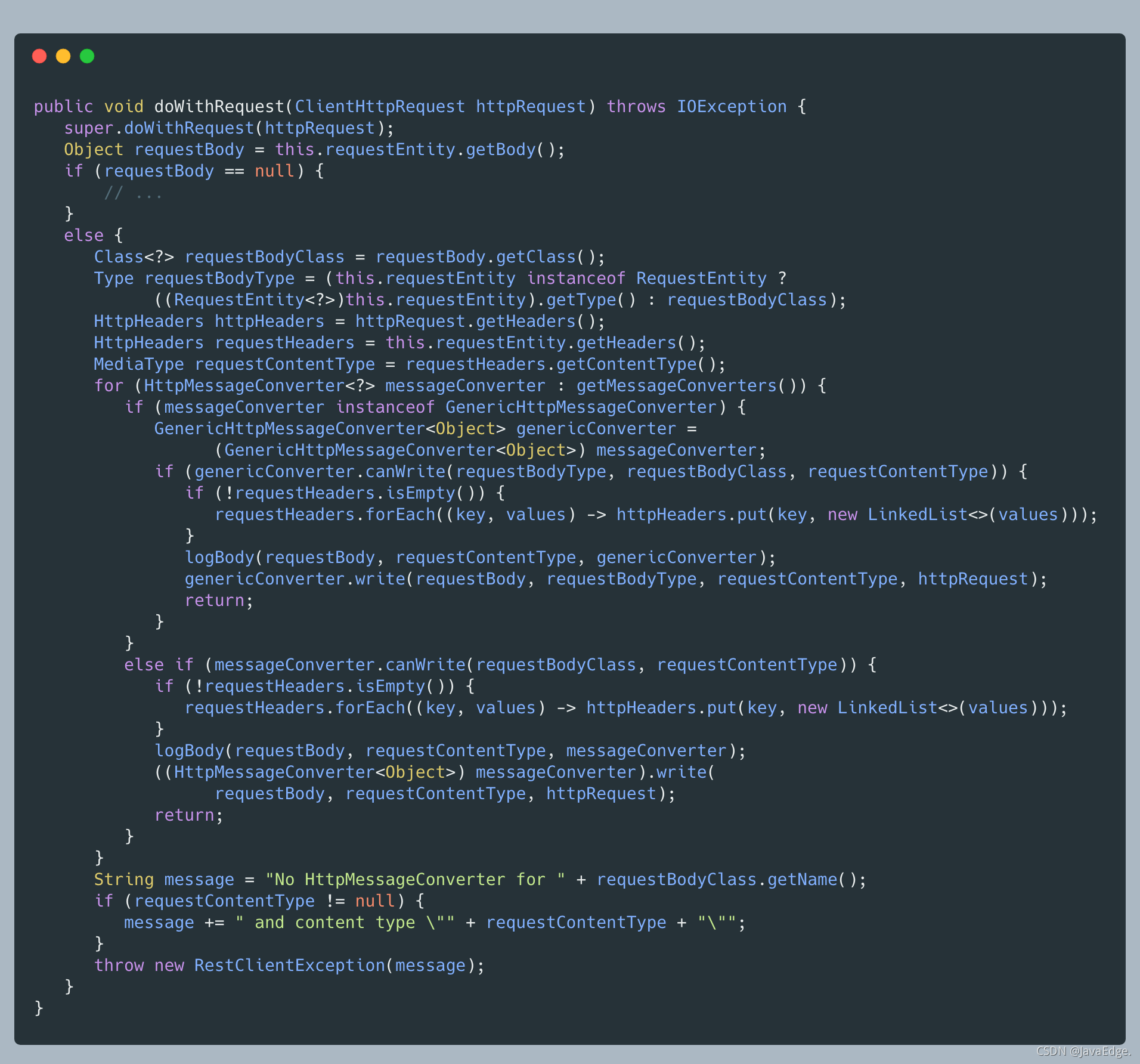
-根据当前要提交的 Body 内容,遍历当前支持的所有编解码器:
-- 若找到合适编解码器,用之完成 Body 转化
-
-看下 JSON 的编解码器对是否合适的判断
-### AbstractJackson2HttpMessageConverter#canWrite
-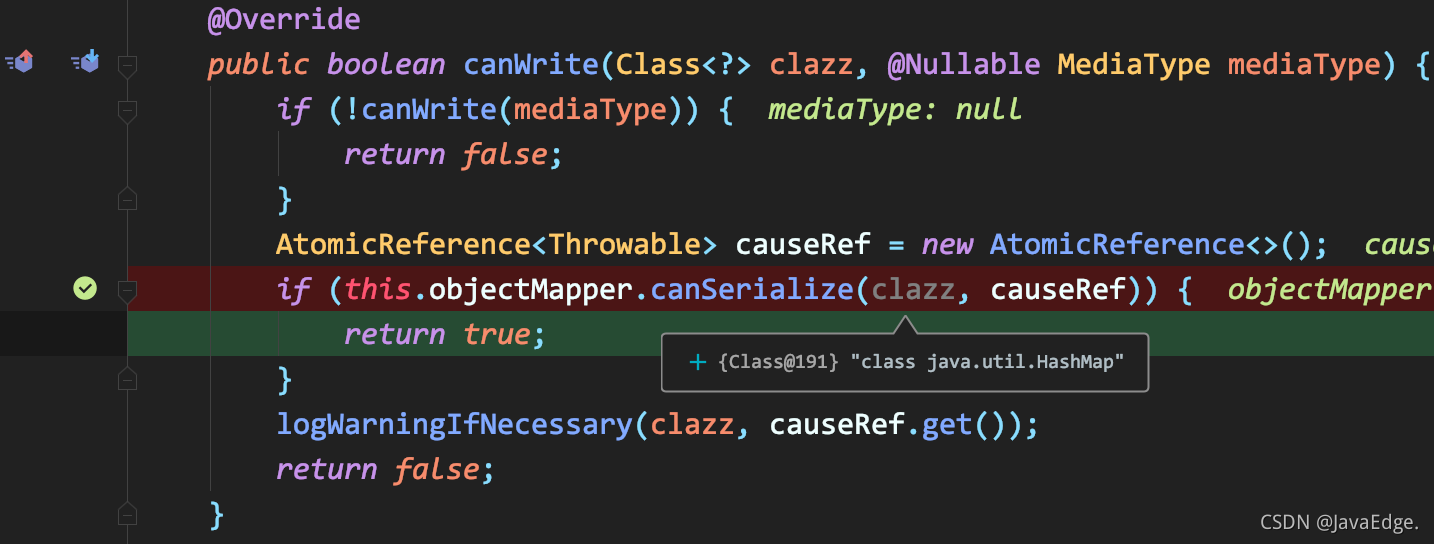
-可见,当使用的 Body 为 HashMap,是可完成 JSON 序列化的。
-所以后续将这个表单序列化为请求 Body了。
-
-但我还是疑问,为何适应表单处理的编解码器不行?
-那就该看编解码器判断是否支持的实现:
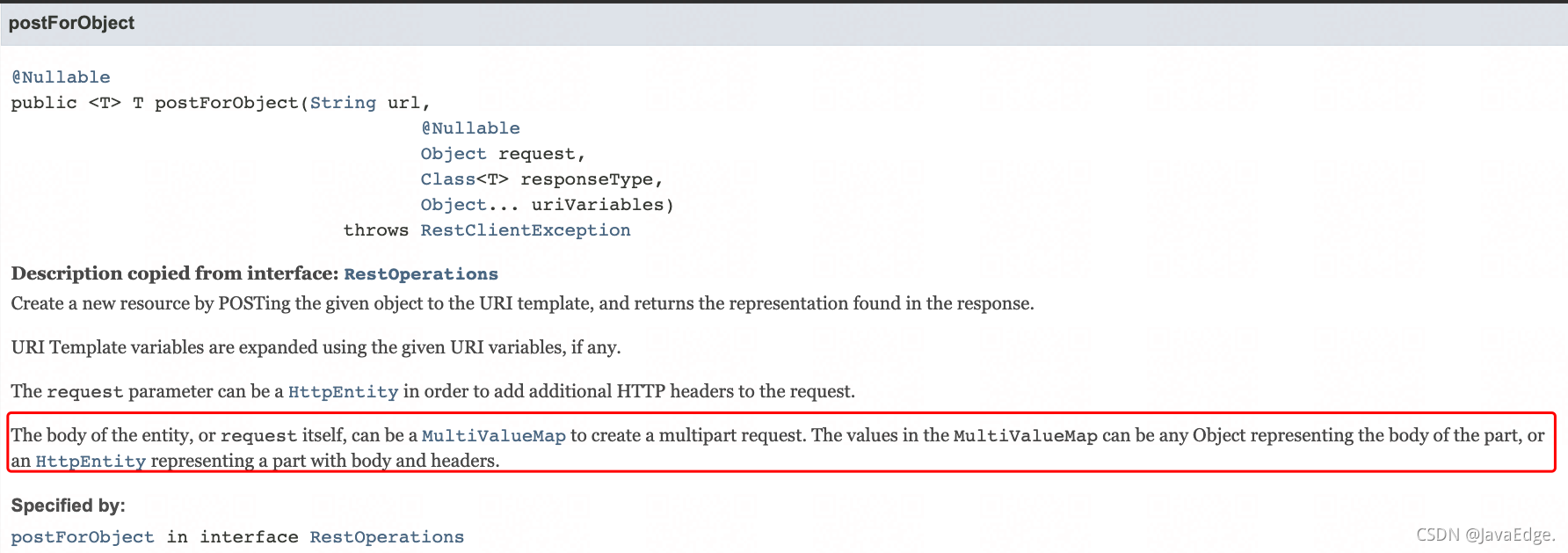
-### FormHttpMessageConverter#canWrite
-可见只有当我们发送的 Body 是 MultiValueMap 才能使用表单来提交。
-原来使用 RestTemplate 提交表单必须是 MultiValueMap!
-而我们案例定义的就是普通的 HashMap,最终是按请求 Body 的方式发送出去的。
-# 修正
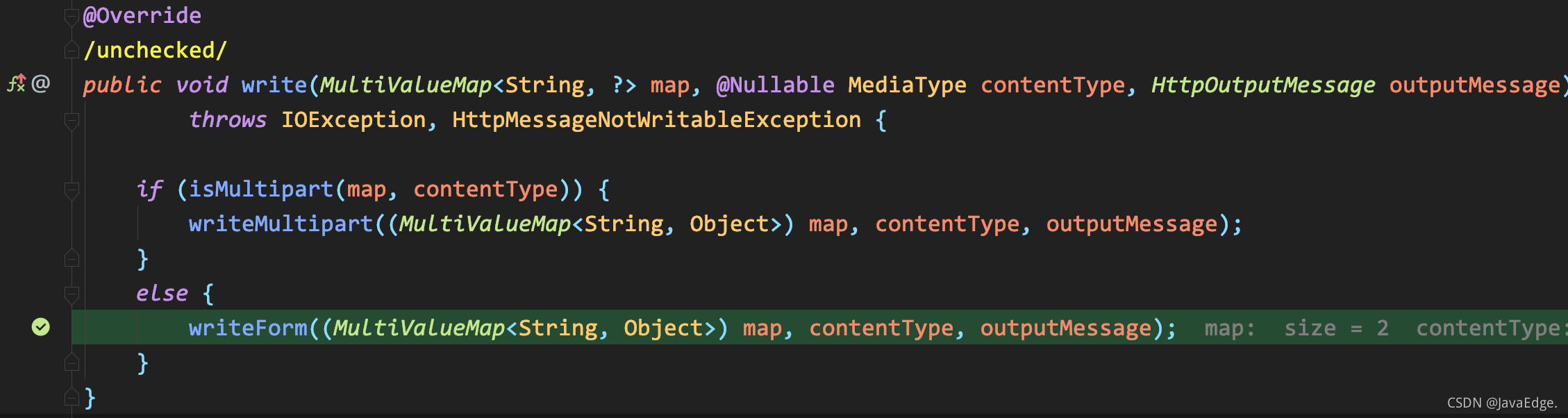
-换成 MultiValueMap 类型存储表单数据即可:
-
-修正后,表单数据最终使用下面的代码进行了编码:
-### FormHttpMessageConverter#write
-
-发送出的数据截图如下:
-
-这就对了!其实官方文档也说明了:
-
-
-> 参考:
-> - https://docs.spring.io/spring-framework/docs/current/javadoc-api/org/springframework/web/client/RestTemplate.html
\ No newline at end of file
diff --git "a/Spring/SpringFramework/Spring Bean347円224円237円345円221円275円345円221円250円346円234円237円347円256円241円347円220円206円.md" "b/Spring/SpringFramework/Spring Bean347円224円237円345円221円275円345円221円250円346円234円237円347円256円241円347円220円206円.md"
index 0f32a53bfe..29d9533994 100644
--- "a/Spring/SpringFramework/Spring Bean347円224円237円345円221円275円345円221円250円346円234円237円347円256円241円347円220円206円.md"
+++ "b/Spring/SpringFramework/Spring Bean347円224円237円345円221円275円345円221円250円346円234円237円347円256円241円347円220円206円.md"
@@ -59,10 +59,9 @@ public interface InitializingBean {
因其实现了InitializingBean接口,其中只有一个方法,且在Bean加载后就执行。该方法可被用来检查是否所有的属性都已设置好。
## 8 BeanPostProcess接口
-Spring将调用它们的postProcessAfterInitialization(后初始化)方法,作用与6一样,只不过6是在Bean初始化前执行,而这是在Bean初始化后执行。
+Spring将调用它们的postProcessAfterInitialization(后初始化)方法,作用与6的一样,只不过6是在Bean初始化前执行,而这个是在Bean初始化后执行。
-
-> 经过以上工作,Bean将一直驻留在应用上下文中给应用使用,直到应用上下文被销毁。
+经过以上工作,Bean将一直驻留在应用上下文中给应用使用,直到应用上下文被销毁。
## 9 DispostbleBean接口
- Spring将调用它的destory方法
@@ -259,28 +258,16 @@ public class GiraffeService implements ApplicationContextAware,
}
```
### BeanPostProcessor
-允许自定义修改新 bean 实例的工厂钩子——如检查标记接口或用代理包装 bean。
-
-- 通过标记接口或类似方式填充bean的后置处理器将实现postProcessBeforeInitialization(java.lang.Object,java.lang.String)
-- 而用代理包装bean的后置处理器通常会实现postProcessAfterInitialization(java.lang.Object,java.lang.String)
-#### Registration
-一个ApplicationContext可在其 Bean 定义中自动检测 BeanPostProcessor Bean,并将这些后置处理器应用于随后创建的任何 Bean。
-普通的BeanFactory允许对后置处理器进行编程注册,将它们应用于通过Bean工厂创建的所有Bean。
-#### Ordering
-在 ApplicationContext 中自动检测的 OrderBeanPostProcessor Bean 将根据 PriorityOrdered 和 Ordered 语义进行排序。
-相比之下,在BeanFactory以编程方式注册的BeanPostProcessor bean将按注册顺序应用
-对于以编程方式注册的后处理器,通过实现 PriorityOrdered 或 Ordered 接口表达的任何排序语义都将被忽略。
-对于 BeanPostProcessor bean,并不考虑 **@Order** 注解。
-
Aware接口是针对某个 **实现这些接口的Bean** 定制初始化的过程,
-Spring还可针对容器中 **所有Bean** 或 **某些Bean** 定制初始化过程,只需提供一个实现BeanPostProcessor接口的实现类。
+Spring同样还可针对容器中 **所有Bean**,或 **某些Bean** 定制初始化过程,只需提供一个实现BeanPostProcessor接口的类即可。
-该接口包含如下方法:
+该接口中包含两个方法:
- postProcessBeforeInitialization
在容器中的Bean初始化之前执行
- postProcessAfterInitialization
在容器中的Bean初始化之后执行
-#### 实例
+
+例子如下:
```java
public class CustomerBeanPostProcessor implements BeanPostProcessor {
@@ -296,10 +283,13 @@ public class CustomerBeanPostProcessor implements BeanPostProcessor {
}
}
```
+
要将BeanPostProcessor的Bean像其他Bean一样定义在配置文件中
+
```xml
-
"},{"parent":"5351911e121f","children":[],"id":"d16b9b53101f","title":"ArrayList线程不安全,线程安全版本的数组容器是Vector
"},{"parent":"5351911e121f","children":[],"id":"5eb59595d8fd","title":"与LinkedList遍历效率对比,性能高很多,ArrayList遍历最大的优势在于内存的连续性,CPU的内部缓存结构会缓存连续的内存片段,可以大幅降低读取内存的性能开销
"}],"id":"5351911e121f","title":"ArrayList"},{"parent":"36d002b102e2","children":[{"parent":"f817a30f5e08","children":[],"id":"e3e17fe90642","title":"数据结构: 双向链表"},{"parent":"f817a30f5e08","children":[],"id":"3846d194c83e","title":"适合插入删除频繁的情况 内部维护了链表的长度
"}],"id":"f817a30f5e08","title":"LinkedList
"}],"id":"36d002b102e2","title":"List"},{"parent":"800ecb4c0776","children":[{"parent":"24f4a3146f29","children":[{"parent":"f4b8a675a029","children":[{"parent":"2353a0a1da34","children":[],"id":"8838e06b887a","title":"数据结构: 数组+链表
"},{"parent":"2353a0a1da34","children":[],"id":"7a82749e87f8","title":"头插法: 新来的值会取代原有的值,原有的值就顺推到链表中去
"},{"parent":"2353a0a1da34","children":[],"id":"c1c3800b1ead","title":"Java7在多线程操作HashMap时可能引起死循环,原因是扩容转移后前后链表顺序倒置,在转移过程中修改了原来链表中节点的引用关系, 可能形成环形链表
"}],"id":"2353a0a1da34","title":"1.7"},{"parent":"f4b8a675a029","children":[{"parent":"cb2e0e4bf56a","children":[],"id":"a743dde50473","title":"数据结构: 数组+链表+红黑树
"},{"parent":"cb2e0e4bf56a","children":[{"parent":"4bb6868f0cc3","children":[],"id":"4753ca9df7aa","title":"根据泊松分布,在负载因子默认为0.75的时候,单个hash槽内元素个数为8的概率小于百万分之一,所以将7作为一个分水岭,等于7的时候不转换,大于等于8的时候才进行转换,小于等于6的时候就化为链表
"}],"id":"4bb6868f0cc3","title":"Hashmap中的链表大小超过八个时会自动转化为红黑树,当删除小于六时重新变为链表
"},{"parent":"cb2e0e4bf56a","children":[],"id":"1c07c2a415b7","title":"尾插法
"},{"parent":"cb2e0e4bf56a","children":[],"id":"94b8ffa2573f","title":"Java8在同样的前提下并不会引起死循环,原因是扩容转移后前后链表顺序不变,保持之前节点的引用关系
"}],"id":"cb2e0e4bf56a","title":"1.8"},{"parent":"f4b8a675a029","children":[{"parent":"6d54a11adce4","children":[],"id":"210d702bbf4a","title":"LoadFactory 默认0.75
"},{"parent":"6d54a11adce4","children":[],"id":"e4055d669e46","title":"
"},{"parent":"6d54a11adce4","children":[{"parent":"af3ec421dc31","children":[],"id":"0c6cfee11d49","title":"因为长度扩大以后,Hash的规则也随之改变
"},{"parent":"af3ec421dc31","children":[],"id":"316f5ac25324","title":"Hash的公式---> index = HashCode(Key) & (Length - 1)
原来长度(Length)是8你位运算出来的值是2 ,新的长度是16位运算出来的值不同
"},{"parent":"af3ec421dc31","children":[],"id":"ff2cf93209dc","title":"HashMap是通过key的HashCode去寻找index的, 如果不进行重写,会出现在一个index中链表的HashCode相等情况,所以要确保相同的对象返回相同的hash值,不同的对象返回不同的hash值,必须要重写equals
"}],"id":"af3ec421dc31","title":"为什么要ReHash而不进行复制?
"}],"id":"6d54a11adce4","title":"扩容机制"},{"parent":"f4b8a675a029","children":[{"parent":"c6437e8e4f45","children":[],"id":"cb7132ed82f1","title":"HashMap源码中put/get方法都没有加同步锁, 无法保证上一秒put的值,下一秒get的时候还是原值,所以线程安全无法保证
"},{"parent":"c6437e8e4f45","children":[{"parent":"9d6423986311","children":[],"id":"b40b3d560950","title":"Collections.synchronizedMap(Map)"},{"parent":"9d6423986311","children":[{"parent":"cdcaf61438fc","children":[{"parent":"404e074072c9","children":[{"parent":"b926b8dd14c9","children":[],"id":"6bf370941ab4","title":"安全失败机制: 这种机制会使你此次读到的数据不一定是最新的数据。
如果你使用null值,就会使得其无法判断对应的key是不存在还是为空,因为你无法再调用一次contain(key)来对key是否存在进行判断,ConcurrentHashMap同理"}],"id":"b926b8dd14c9","title":"Hashtable 是不允许键或值为 null 的,HashMap 的键值则都可以为 null"},{"parent":"404e074072c9","children":[],"id":"c4669cca3ca2","title":"Hashtable 继承了 Dictionary类,而 HashMap 继承的是 AbstractMap 类"},{"parent":"404e074072c9","children":[],"id":"63a75cf7717b","title":"HashMap 的初始容量为:16,Hashtable 初始容量为:11,两者的负载因子默认都是:0.75"},{"parent":"404e074072c9","children":[],"id":"8e6e339c6351","title":"当现有容量大于总容量 * 负载因子时,HashMap 扩容规则为当前容量翻倍,Hashtable 扩容规则为当前容量翻倍 + 1"},{"parent":"404e074072c9","children":[{"parent":"13aa27708fb1","children":[],"id":"e72d018a877c","title":"快速失败(fail—fast)是java集合中的一种机制, 在用迭代器遍历一个集合对象时,如果遍历过程中对集合对象的内容进行了修改(增加、删除、修改),则会抛出ConcurrentModificationException"}],"id":"13aa27708fb1","title":"HashMap 中的 Iterator 迭代器是 fail-fast 的,而 Hashtable 的 Enumerator 不是 fail-fast 的. 所以,当其他线程改变了HashMap 的结构,如:增加、删除元素,将会抛出ConcurrentModificationException 异常,而 Hashtable 则不会"}],"id":"404e074072c9","title":"与HahsMap的区别"}],"id":"cdcaf61438fc","title":"Hashtable"},{"parent":"9d6423986311","children":[],"id":"3aa13f74a283","title":"ConcurrentHashMap"}],"id":"9d6423986311","title":"确保线程安全的方式"}],"id":"c6437e8e4f45","title":"线程不安全
"},{"parent":"f4b8a675a029","children":[{"parent":"83e802bbbf44","children":[],"id":"6689f5a28d8d","title":"创建HashMap时最好赋初始值, 而且最好为2的幂,为了位运算的方便
"},{"parent":"83e802bbbf44","children":[{"parent":"33f1a38f62cd","children":[],"id":"245253ad18f8","title":"实现均匀分布, 在使用不是2的幂的数字的时候,Length-1的值是所有二进制位全为1,这种情况下,index的结果等同于HashCode后几位的值,只要输入的HashCode本身分布均匀,Hash算法的结果就是均匀的
"}],"id":"33f1a38f62cd","title":"默认初始化大小为16
"}],"id":"83e802bbbf44","title":"初始化
"},{"parent":"f4b8a675a029","children":[],"id":"1bf62446136a","title":"重写equals必须重写HashCode
"}],"id":"f4b8a675a029","title":"HashMap
"},{"parent":"24f4a3146f29","children":[{"parent":"099533450f79","children":[{"parent":"6c4d02753b0b","children":[],"id":"1bf9ad750241","title":"这种机制会使你此次读到的数据不一定是最新的数据。如果你使用null值,就会使得其无法判断对应的key是不存在还是为空,因为你无法再调用一次contain(key)来对key是否存在进行判断,HashTable同理
"}],"id":"6c4d02753b0b","title":"安全失败机制
"},{"parent":"099533450f79","children":[{"parent":"238f89a01639","children":[],"id":"9a49309bdc28","title":"数据结构: 数组+链表 (Segment 数组、HashEntry 组成)
"},{"parent":"238f89a01639","children":[{"parent":"940aa3e4031c","children":[],"id":"6d0c1ad1257f","title":"HashEntry跟HashMap差不多的,但是不同点是,他使用volatile去修饰了他的数据Value还有下一个节点next
"}],"id":"940aa3e4031c","title":"HashEntry
"},{"parent":"238f89a01639","children":[{"parent":"214133bb3335","children":[{"parent":"c94b076d3d2d","children":[],"id":"ccbe178d4298","title":"继承了ReentrantLock
"},{"parent":"c94b076d3d2d","children":[],"id":"8e8ef1826155","title":"每当一个线程占用锁访问一个 Segment 时,不会影响到其他的 Segment。
如果容量大小是16他的并发度就是16,可以同时允许16个线程操作16个Segment而且还是线程安全的。
"}],"id":"c94b076d3d2d","title":"segment分段锁
"},{"parent":"214133bb3335","children":[{"parent":"d93302980fe7","children":[],"id":"26bfa3a12ad8","title":"尝试自旋获取锁,如果获取失败肯定就有其他线程存在竞争,则利用 scanAndLockForPut() 自旋获取锁
"},{"parent":"d93302980fe7","children":[],"id":"b933436ce63c","title":"如果重试的次数达到了 MAX_SCAN_RETRIES 则改为阻塞锁获取,保证能获取成功
"}],"id":"d93302980fe7","title":"put
"},{"parent":"214133bb3335","children":[{"parent":"e791448ffbae","children":[],"id":"65b8e0356631","title":"由于 HashEntry 中的 value 属性是用 volatile 关键词修饰的,保证了内存可见性,所以每次获取时都是最新值
"},{"parent":"e791448ffbae","children":[],"id":"1748a490b610","title":"ConcurrentHashMap 的 get 方法是非常高效的,因为整个过程都不需要加锁
"}],"id":"e791448ffbae","title":"get
"}],"id":"214133bb3335","title":"并发度高的原因
"}],"id":"238f89a01639","title":"1.7
"},{"parent":"099533450f79","children":[{"parent":"bb9fcd3cdf24","children":[],"id":"cefe93491aa8","title":"数组+链表+红黑树
"},{"parent":"bb9fcd3cdf24","children":[{"parent":"7f1ff4d86665","children":[],"id":"122b03888ad2","title":"抛弃了原有的 Segment 分段锁,而采用了 CAS + synchronized 来保证并发安全性
"}],"id":"7f1ff4d86665","title":"区别
"},{"parent":"bb9fcd3cdf24","children":[{"parent":"292fc2483f4c","children":[],"id":"1181a0ece609","title":"根据 key 计算出 hashcode
"},{"parent":"292fc2483f4c","children":[],"id":"17e33984c1e5","title":"判断是否需要进行初始化
"},{"parent":"292fc2483f4c","children":[],"id":"d0bfa1371c32","title":"即为当前 key 定位出的 Node,如果为空表示当前位置可以写入数据,利用 CAS 尝试写入,失败则自旋保证成功
"},{"parent":"292fc2483f4c","children":[],"id":"1ddaa88f7963","title":"如果当前位置的 hashcode == MOVED == -1,则需要进行扩容
"},{"parent":"292fc2483f4c","children":[],"id":"5735982de5ef","title":"如果都不满足,则利用 synchronized 锁写入数据
"},{"parent":"292fc2483f4c","children":[],"id":"4e006a2b0550","title":"如果数量大于 TREEIFY_THRESHOLD 则要转换为红黑树
"}],"id":"292fc2483f4c","title":"put操作
"},{"parent":"bb9fcd3cdf24","children":[{"parent":"92654a95d638","children":[],"id":"02394dd149e1","title":"根据计算出来的 hashcode 寻址,如果就在桶上那么直接返回值
"},{"parent":"92654a95d638","children":[],"id":"d7b487f3b69b","title":"如果是红黑树那就按照树的方式获取值
"},{"parent":"92654a95d638","children":[],"id":"1c6f9d2d5016","title":"就不满足那就按照链表的方式遍历获取值
"}],"id":"92654a95d638","title":"get操作
"}],"collapsed":false,"id":"bb9fcd3cdf24","title":"1.8
"}],"id":"099533450f79","title":"ConcurrentHashMap
"}],"collapsed":false,"id":"24f4a3146f29","title":"Map"},{"parent":"800ecb4c0776","children":[{"parent":"e7046be1aafc","children":[{"parent":"bb49195cb4a7","children":[],"link":{"title":"https://mp.weixin.qq.com/s/0cMrE87iUxLBw_qTBMYMgA","type":"url","value":"https://mp.weixin.qq.com/s/0cMrE87iUxLBw_qTBMYMgA"},"id":"5448b1ead28d","title":"同步容器(如Vector)的所有操作一定是线程安全的吗?"}],"id":"bb49195cb4a7","title":"相关文档"}],"id":"e7046be1aafc","title":"Vector"},{"parent":"800ecb4c0776","children":[{"parent":"6062a460b43c","children":[{"parent":"d695fc5d8846","children":[],"id":"84bbc18befc1","title":"底层实现的就是HashMap,所以是根据HashCode来判断是否是重复元素
"},{"parent":"d695fc5d8846","children":[],"id":"27e06a58782e","title":"初始化容量是:16, 因为底层实现的是HashMap。加载因子是0.75
"},{"parent":"d695fc5d8846","children":[],"id":"dbcb9b76077a","title":"无序的
"},{"parent":"d695fc5d8846","children":[],"id":"2c468ef34635","title":"HashSet不能根据索引去数据,所以不能用普通的for循环来取出数据,应该用增强for循环,查询性能不好
"}],"id":"d695fc5d8846","title":"HashSet
"},{"parent":"6062a460b43c","children":[{"parent":"3e5fc407007b","children":[],"id":"34347150ba65","title":"底层是实现的TreeMap
"},{"parent":"3e5fc407007b","children":[],"id":"3ead4a788049","title":"元素不能够重复,可以有一个null值,并且这个null值一直在第一个位置上
"},{"parent":"3e5fc407007b","children":[],"id":"432c37f69b42","title":"默认容量:16,加载因子是0.75
"},{"parent":"3e5fc407007b","children":[],"id":"1bf8f3a4b2c3","title":"TreeMap是有序的,这个有序不是存入的和取出的顺序是一样的,而是根据自然规律拍的序
"}],"id":"3e5fc407007b","title":"TreeSet
"}],"id":"6062a460b43c","title":"Set"}],"collapsed":true,"id":"800ecb4c0776","title":"集合"},{"parent":"root","lineStyle":{"randomLineColor":"#F4325C"},"children":[],"id":"ef690530e935","title":"基础"},{"parent":"root","lineStyle":{"randomLineColor":"#A04AFB"},"children":[{"parent":"d61da867cb10","children":[{"parent":"c56b85ccc7f0","children":[],"id":"cd07e14ad850","title":"虚拟机堆
"},{"parent":"c56b85ccc7f0","children":[],"id":"5f3d1d3f67c2","title":"虚拟机栈
"},{"parent":"c56b85ccc7f0","children":[],"id":"b44fa08a79e3","title":"方法区
"},{"parent":"c56b85ccc7f0","children":[],"id":"38e4ffe62590","title":"本地方法栈
"},{"parent":"c56b85ccc7f0","children":[],"id":"6b76f89e7451","title":"程序计数器
"}],"id":"c56b85ccc7f0","title":"Java内存区域
"},{"parent":"d61da867cb10","children":[{"parent":"08f416fb625f","children":[],"id":"95995454f91e","title":"加载->验证->准备->解析->初始化->使用->卸载
"},{"parent":"08f416fb625f","children":[{"parent":"28edebbeb4d6","children":[],"id":"fddd8578d67e","title":"父类加载 不重复加载
"}],"id":"28edebbeb4d6","title":"双亲委派原则
"},{"parent":"08f416fb625f","children":[{"parent":"ff18f9026678","children":[],"id":"ea8db2744206","title":"第一次,在JDK1.2以前,双亲委派模型在JDK1.2引入,ClassLoder在最初已经存在了,为了兼容已有代码,添加了findClass()方法,如果父类加载失败会自动调用findClass()来完成加载
"},{"parent":"ff18f9026678","children":[],"id":"5c240d502f24","title":"第二次,由双亲委派模型缺陷导致,由于双亲委派越基础的类由越上层的加载器进行加载,如果有基础类型调回用户代码回无法解决而产生,出现线程上下文类加载器,会出现父类加载器请求子类加载器完成类加载的行为
"},{"parent":"ff18f9026678","children":[],"id":"5d62862bf3e0","title":"第三次,代码热替换、模块热部署,典型:OSGi每一个程序模块都有一个自己的类加载器
"}],"id":"ff18f9026678","title":"破坏双亲委派模型
"}],"id":"08f416fb625f","title":"类得加载机制"},{"parent":"d61da867cb10","children":[{"parent":"52bb18b06c6e","children":[],"id":"f61579e4d22a","title":"新生代/年轻代
"},{"parent":"52bb18b06c6e","children":[],"id":"72db835ecada","title":"老年代
"},{"parent":"52bb18b06c6e","children":[{"parent":"559cb847a3c3","children":[{"parent":"48946b525dfd","children":[],"id":"b7b6b8d8f03d","title":"字符串存在永久代中,容易出现性能问题和内存溢出
"},{"parent":"48946b525dfd","children":[],"id":"2f7df7f20543","title":"类及方法的信息等比较难确定其大小,因此对于永久代的大小指定比较困难,太小容易出现永久代溢出,太大则容易导致老年代溢出
"},{"parent":"48946b525dfd","children":[],"id":"5439cd0f53c8","title":"永久代会为 GC 带来不必要的复杂度,并且回收效率偏低
"},{"parent":"48946b525dfd","children":[],"id":"9c36c0817672","title":"将 HotSpot 与 JRockit 合二为一
"}],"id":"48946b525dfd","title":"为什么要使用元空间取代永久代的实现?
"},{"parent":"559cb847a3c3","children":[{"parent":"1d6773397050","children":[],"id":"c33f0e9fe53f","title":"元空间并不在虚拟机中,而是使用本地内存。因此默认情况下,元空间的大小仅受本地内存限制
"}],"id":"1d6773397050","title":"元空间与永久代区别
"},{"parent":"559cb847a3c3","children":[{"parent":"afb5323c83d0","children":[],"id":"fbf6f9baf099","title":"-XX:MetaspaceSize:初始空间大小,达到该值会触发垃圾收集进行类型卸载,同时GC会对该值进行调整:如果释放了大量的空间,就适当降低该值;如果释放了很少的空间,那么在不超过MaxMetaspaceSize时,适当提高该值
"},{"parent":"afb5323c83d0","children":[],"id":"8e0c80084aef","title":"-XX:MaxMetaspaceSize:最大空间,默认是没有限制的
"}],"id":"afb5323c83d0","title":"元空间空间大小设置
"}],"id":"559cb847a3c3","title":"永久代/元空间
"},{"parent":"52bb18b06c6e","children":[{"parent":"34170f8e7332","children":[],"id":"9d5df7c5e2eb","title":"根据存活时间
"}],"id":"34170f8e7332","title":"晋升机制
"}],"id":"52bb18b06c6e","title":"分代回收
"},{"parent":"d61da867cb10","children":[{"parent":"c465e3a953e3","children":[{"parent":"2e9e41cbb0e4","children":[],"id":"6ff93afab3be","title":"绝大多数对象都是朝生熄灭的
"}],"id":"2e9e41cbb0e4","title":"弱分代假说
"},{"parent":"c465e3a953e3","children":[{"parent":"759979ad09cd","children":[],"id":"a152f857c10b","title":"熬过越多次垃圾收集过程的对象就越难以消亡
"}],"id":"759979ad09cd","title":"强分代假说
"},{"parent":"c465e3a953e3","children":[{"parent":"4843a46b8196","children":[],"id":"6481cbce8487","title":"跨代引用相对于同代引用来说仅占极少数
"}],"id":"4843a46b8196","title":"跨代引用假说
"}],"id":"c465e3a953e3","title":"分代收集理论
"},{"parent":"d61da867cb10","children":[{"parent":"85ab22cf15b4","children":[],"id":"0c42af972e09","title":""GC Roots"的根对象作为起始节点集,从这些节点开始,根据引用关系向下搜索,如果某个对象到GC Roots间没有任何引用链相连接,则证明此对象是不可能再被使用的
"}],"id":"85ab22cf15b4","title":"可达性分析算法
"},{"parent":"d61da867cb10","children":[{"parent":"133b15c6580f","children":[{"parent":"9bd71d4114f3","children":[],"id":"e602b5dbf42a","title":"强引用是使用最普遍的引用。如果一个对象具有强引用,那垃圾回收器绝不会回收它; 当内存空间不足时,Java虚拟机宁愿抛出OutOfMemoryError错误,使程序异常终止,也不会靠随意回收具有强引用的对象来解决内存不足的问题。
"}],"id":"9bd71d4114f3","title":"强引用 (StrongReference)
"},{"parent":"133b15c6580f","children":[{"parent":"a4d69c685996","children":[],"id":"aaedb29f6e8f","title":"如果一个对象只具有软引用,则内存空间充足时,垃圾回收器就不会回收它;如果内存空间不足了,就会回收这些对象的内存。
"}],"id":"a4d69c685996","title":"软引用 (SoftReference)
"},{"parent":"133b15c6580f","children":[{"parent":"6cdc46b73fd3","children":[],"id":"7acc452f65ab","title":"在垃圾回收器线程扫描它所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。
"}],"id":"6cdc46b73fd3","title":"弱引用 (WeakReference)
"},{"parent":"133b15c6580f","children":[{"parent":"5f58e345e898","children":[],"id":"d189c9591839","title":"如果一个对象仅持有虚引用,那么它就和没有任何引用一样,在任何时候都可能被垃圾回收器回收
"}],"id":"5f58e345e898","title":"虚引用 (PhantomReference)
"}],"id":"133b15c6580f","title":"引用
"},{"parent":"d61da867cb10","children":[{"parent":"7a6e56139d11","children":[{"parent":"39f66c681caf","children":[{"parent":"5303c5abf34b","children":[],"id":"e983d3f5fd4a","title":"对象存活较多情况
"},{"parent":"5303c5abf34b","children":[],"id":"b9065a228c05","title":"老年代
"}],"id":"5303c5abf34b","title":"适用场景
"},{"parent":"39f66c681caf","children":[{"parent":"733f3bc0b7ab","children":[],"id":"4f9fdc7ae82e","title":"内存空间碎片化
"},{"parent":"733f3bc0b7ab","children":[],"id":"2a97115e02e3","title":"由于空间碎片导致的提前GC
"},{"parent":"733f3bc0b7ab","children":[{"parent":"706cff5bc691","children":[],"id":"7a5e8f6db9e2","title":"标记需清除或存货对象
"},{"parent":"706cff5bc691","children":[],"id":"3da1d4f2af71","title":"清除标记或未标记对象
"}],"id":"706cff5bc691","title":"扫描了两次
"}],"id":"733f3bc0b7ab","title":"缺点
"}],"id":"39f66c681caf","title":"标记请除
"},{"parent":"7a6e56139d11","children":[{"parent":"463d39f131e0","children":[{"parent":"cc3d3a846262","children":[],"id":"ad8382025fe4","title":"存活对象少比较高效
"},{"parent":"cc3d3a846262","children":[],"id":"fb2a5786103c","title":"扫描了整个空间(标记存活对象并复制移动)
"},{"parent":"cc3d3a846262","children":[],"id":"efebc696f64e","title":"年轻代
"}],"id":"cc3d3a846262","title":"适用场景
"},{"parent":"463d39f131e0","children":[{"parent":"4a07efc633b8","children":[],"id":"ca57a2a2591a","title":"需要空闲空间
"},{"parent":"4a07efc633b8","children":[],"id":"74b68744b877","title":"老年代作为担保空间
"},{"parent":"4a07efc633b8","children":[],"id":"9a2b53e3948c","title":"复制移动对象
"}],"id":"4a07efc633b8","title":"缺点
"}],"id":"463d39f131e0","title":"标记复制
"},{"parent":"7a6e56139d11","children":[{"parent":"6e91691d76fb","children":[{"parent":"ca79fb0161d2","children":[],"id":"3093a8344bf8","title":"对象存活较多情况
"},{"parent":"ca79fb0161d2","children":[],"id":"171500353dee","title":"老年代
"}],"id":"ca79fb0161d2","title":"适用场景
"},{"parent":"6e91691d76fb","children":[{"parent":"2e00b69db6db","children":[],"id":"9cc7fd616235","title":"移动存活对象并更新对象引用
"},{"parent":"2e00b69db6db","children":[],"id":"9f173f5f0a02","title":"Stop The World
"}],"id":"2e00b69db6db","title":"缺点
"}],"id":"6e91691d76fb","title":"标记整理
"},{"parent":"7a6e56139d11","children":[{"parent":"873b4393cb04","children":[],"id":"e55f55cabd04","title":"没办法解决循环引用的问题
"}],"id":"873b4393cb04","title":"引用计数
"}],"id":"7a6e56139d11","title":"垃圾回收机制
"},{"parent":"d61da867cb10","children":[{"parent":"94c48a9cef88","children":[{"parent":"1871a079226a","children":[{"parent":"ec2e2387d0dc","children":[{"parent":"1e82c0b474da","children":[],"id":"4ae444f631e6","title":"Eden
"},{"parent":"1e82c0b474da","children":[],"id":"2e6db7cc3c33","title":"Survivor1
"},{"parent":"1e82c0b474da","children":[],"id":"c07a1cd16c8f","title":"Survivor2
"},{"parent":"1e82c0b474da","children":[{"parent":"150da6938c96","children":[],"id":"79ab826115b2","title":"通过阈值晋升
"}],"id":"150da6938c96","title":"Minor GC
"}],"id":"1e82c0b474da","title":"年轻代"},{"parent":"ec2e2387d0dc","children":[{"parent":"c2b0ef70d896","children":[],"id":"69438d9521b8","title":"Major GC 等价于 Full GC
"}],"id":"c2b0ef70d896","title":"老年代
"},{"parent":"ec2e2387d0dc","children":[],"id":"bb363f2d06eb","title":"永久"}],"id":"ec2e2387d0dc","title":"分代情况
"},{"parent":"1871a079226a","children":[{"parent":"ef9b2adfad54","children":[],"id":"f8a938786281","title":"对CPU资源敏感
"},{"parent":"ef9b2adfad54","children":[],"id":"f34402ad150a","title":"无法处理浮动垃圾
"},{"parent":"ef9b2adfad54","children":[],"id":"1b39a82e9c8c","title":"基于标记清除算法 大量空间碎片
"}],"id":"ef9b2adfad54","title":"缺点
"}],"id":"1871a079226a","title":"CMS
"},{"parent":"94c48a9cef88","children":[{"parent":"9b2c5a694136","children":[],"id":"d3247834f765","title":"分区概念 弱化分代
"},{"parent":"9b2c5a694136","children":[{"parent":"0ac46d282191","children":[],"id":"1eba7428e805","title":"不会产生碎片空间,分配大对象不会提前Full GC
"}],"id":"0ac46d282191","title":"标记整理算法
"},{"parent":"9b2c5a694136","children":[{"parent":"20775041ea09","children":[],"id":"df43ec84ba90","title":"使用参数-XX:MaxGCPauseMills,默认为200毫秒,优先处理回收价值收集最大的Region
"}],"id":"20775041ea09","title":"允许用户设置收集的停顿时间
"},{"parent":"9b2c5a694136","children":[],"id":"0831e78ce2d4","title":"利用CPU多核条件,缩短STW时间
"},{"parent":"9b2c5a694136","children":[],"id":"00fc277cb4e8","title":"原始快照算法(SATB)保证收集线程与用户线程互不干扰,避免标记结果出错
"},{"parent":"9b2c5a694136","children":[{"parent":"64ddc0929330","children":[{"parent":"6bda8393ce9e","children":[],"id":"2194b30b8023","title":"标记STW从GC Roots开始直接可达的对象,借用Minor GC时同步完成
"}],"id":"6bda8393ce9e","title":"初始标记
"},{"parent":"64ddc0929330","children":[{"parent":"8954c96bf47e","children":[],"id":"11402483ace1","title":"从GC Roots开始对堆对象进行可达性分析,找出要回收的对象,与用户程序并发执行,重新处理SATB记录下的并发时引用变动对象
"}],"id":"8954c96bf47e","title":"并发标记
"},{"parent":"64ddc0929330","children":[{"parent":"dcca5f39bc8c","children":[],"id":"2044b2d42f4a","title":"处理并发阶段结束后遗留下来的少量SATB记录
"}],"id":"dcca5f39bc8c","title":"最终标记
"},{"parent":"64ddc0929330","children":[{"parent":"32a05d0acfd4","children":[],"id":"1c5bed528018","title":"根据用户期待的GC停顿时间制定回收计划
"}],"id":"32a05d0acfd4","title":"筛选回收
"}],"id":"64ddc0929330","title":"收集步骤
"},{"parent":"9b2c5a694136","children":[{"parent":"144086fdf009","children":[{"parent":"70dcc7b7411a","children":[{"parent":"bf3ba1d7ab1a","children":[],"id":"6d91b336c4b7","title":"复制一些存活对象到Old区、Survivor区
"}],"id":"bf3ba1d7ab1a","title":"回收所有Eden、Survivor区
"}],"id":"70dcc7b7411a","title":"Minor GC/Young GC
"},{"parent":"144086fdf009","children":[],"id":"44c8c447963a","title":"Mixed GC
"}],"id":"144086fdf009","title":"回收模式
"}],"id":"9b2c5a694136","title":"G1
"},{"parent":"94c48a9cef88","children":[{"parent":"8e74a22eafd1","children":[],"id":"642ff9bd8dbb","title":"G1分区域 每个区域是有老年代概念的,但是收集器以整个区域为单位收集
"},{"parent":"8e74a22eafd1","children":[],"id":"affafbc6a4da","title":"G1回收后马上合并空闲内存,而CMS会在STW的时候合并
"}],"id":"8e74a22eafd1","title":"CMS与G1的区别
"}],"id":"94c48a9cef88","title":"垃圾回收器
"},{"parent":"d61da867cb10","children":[{"parent":"1dfd2da1ccb2","children":[],"id":"09de7462c062","title":"老年代空间不足
"},{"parent":"1dfd2da1ccb2","children":[],"id":"7681c3724945","title":"system.gc()通知JVM进行Full GC
"},{"parent":"1dfd2da1ccb2","children":[],"id":"d1038ecedd23","title":"持久代空间不足
"}],"id":"1dfd2da1ccb2","title":"Full GC
"},{"parent":"d61da867cb10","children":[{"parent":"a7686c6448fb","children":[],"id":"750a3f631db0","title":"在执行垃圾收集算法时,Java应用程序的其他所有线程都被挂起。是Java中一种全局暂停现象,全局停顿,所有Java代码停止,Native代码可以执行,但不能与JVM交互
"}],"id":"a7686c6448fb","title":"STW(Stop The World)
"},{"parent":"d61da867cb10","children":[{"parent":"a7d301228e2a","children":[],"id":"92f20719ac8a","title":"设置堆的最大最小值 -xms -xmx
"},{"parent":"a7d301228e2a","children":[{"parent":"0715cab0f70c","children":[{"parent":"59b27c4fd939","children":[],"id":"e21f787b02c5","title":"防止年轻代堆收缩:老年代同理
"}],"id":"59b27c4fd939","title":"-XX:newSize设置绝对大小
"}],"id":"0715cab0f70c","title":"调整老年和年轻代的比例
"},{"parent":"a7d301228e2a","children":[],"id":"ff8918fe5f06","title":"主要看是否存在更多持久对象和临时对象
"},{"parent":"a7d301228e2a","children":[],"id":"24446fac73b9","title":"观察一段时间 看峰值老年代如何 不影响gc就加大年轻代
"},{"parent":"a7d301228e2a","children":[],"id":"9204d8b66e5f","title":"配置好的机器可以用 并发收集算法
"},{"parent":"a7d301228e2a","children":[],"id":"b58af9729fb9","title":"每个线程默认会开启1M的堆栈 存放栈帧 调用参数 局部变量 太大了 500k够了
"},{"parent":"a7d301228e2a","children":[],"id":"c001d0fcef30","title":"原则 就是减少GC STW
"}],"id":"a7d301228e2a","title":"性能调优
"},{"parent":"d61da867cb10","children":[{"parent":"febcbf010f6e","children":[],"id":"0e938c11383a","title":"jasvism
"},{"parent":"febcbf010f6e","children":[],"id":"64f7c1d4e0c1","title":"dump
"},{"parent":"febcbf010f6e","children":[],"id":"3ae88d77a8e0","title":"监控配置 自动dump
"}],"id":"febcbf010f6e","title":"FullGC 内存泄露排查
"},{"parent":"d61da867cb10","children":[{"parent":"163f2b3e6279","children":[{"parent":"341ea9d0a8b1","children":[{"parent":"7b2c9c719a5b","children":[],"id":"52bb357adfd0","title":"开启逃逸分析:-XX:+DoEscapeAnalysis
关闭逃逸分析:-XX:-DoEscapeAnalysis
显示分析结果:-XX:+PrintEscapeAnalysis
"}],"id":"7b2c9c719a5b","title":"Java Hotspot 虚拟机可以分析新创建对象的使用范围,并决定是否在 Java 堆上分配内存的一项技术
"}],"id":"341ea9d0a8b1","title":"概念
"},{"parent":"163f2b3e6279","children":[{"parent":"2951be8a5ab7","children":[{"parent":"19414f3dfc6b","children":[],"id":"b8919c87025b","title":"即一个对象的作用范围逃出了当前方法或者当前线程
"},{"parent":"19414f3dfc6b","children":[{"parent":"f3f5a4d41ca7","children":[],"id":"78e7003b3c6c","title":"对象是一个静态变量
"},{"parent":"f3f5a4d41ca7","children":[],"id":"57d7fe2eba87","title":"对象是一个已经发生逃逸的对象
"},{"parent":"f3f5a4d41ca7","children":[],"id":"f72de2af0484","title":"对象作为当前方法的返回值
"}],"id":"f3f5a4d41ca7","title":"场景
"}],"id":"19414f3dfc6b","title":"全局逃逸
"},{"parent":"2951be8a5ab7","children":[{"parent":"078cd7effe02","children":[],"id":"c4a9820ede62","title":"即一个对象被作为方法参数传递或者被参数引用,但在调用过程中不会发生全局逃逸
"}],"id":"078cd7effe02","title":"参数级逃逸
"},{"parent":"2951be8a5ab7","children":[{"parent":"dfb6626fa13e","children":[],"id":"a1f76aa518e6","title":"即方法中的对象没有发生逃逸
"}],"id":"dfb6626fa13e","title":"没有逃逸
"}],"id":"2951be8a5ab7","title":"逃逸状态
"},{"parent":"163f2b3e6279","children":[{"parent":"74538b6f0667","children":[{"parent":"22052ecf3777","children":[],"id":"1bb3c11ad593","title":"开启锁消除:-XX:+EliminateLocks
关闭锁消除:-XX:-EliminateLocks
"}],"id":"22052ecf3777","title":"锁消除
"},{"parent":"74538b6f0667","children":[{"parent":"d19fda364ab3","children":[],"id":"618f15119b55","title":"开启标量替换:-XX:+EliminateAllocations
关闭标量替换:-XX:-EliminateAllocations
显示标量替换详情:-XX:+PrintEliminateAllocations
"}],"id":"d19fda364ab3","title":"标量替换
"},{"parent":"74538b6f0667","children":[{"parent":"58e0672d4093","children":[],"id":"852d0a874d5c","title":"当对象没有发生逃逸时,该对象就可以通过标量替换分解成成员标量分配在栈内存中,和方法的生命周期一致,随着栈帧出栈时销毁,减少了 GC 压力,提高了应用程序性能
"}],"id":"58e0672d4093","title":"栈上分配
"}],"id":"74538b6f0667","title":"逃逸分析优化
"},{"parent":"163f2b3e6279","children":[{"parent":"0c9fe2ae4750","children":[],"id":"d4e70d6dd352","title":"在平时开发过程中尽可能的控制变量的作用范围了,变量范围越小越好,让虚拟机尽可能有优化的空间
"}],"id":"0c9fe2ae4750","title":"结论
"}],"id":"163f2b3e6279","title":"逃逸分析
"},{"parent":"d61da867cb10","children":[{"parent":"f01a444aff49","children":[{"parent":"e5b794712d9f","children":[{"parent":"69d4722f6204","children":[],"id":"9058d548b851","title":"当堆内存(Heap Space)没有足够空间存放新创建的对象时,会抛出
"},{"parent":"69d4722f6204","children":[{"parent":"82077529709e","children":[],"id":"e5efc4b324bd","title":"请求创建一个超大对象,通常是一个大数组
"},{"parent":"82077529709e","children":[],"id":"f6c6d999b2e2","title":"超出预期的访问量/数据量,通常是上游系统请求流量飙升,常见于各类促销/秒杀活动,可以结合业务流量指标排查是否有尖状峰值
"},{"parent":"82077529709e","children":[],"id":"810ed21d175e","title":"过度使用终结器(Finalizer),该对象没有立即被 GC
"},{"parent":"82077529709e","children":[],"id":"12f8716631c0","title":"内存泄漏(Memory Leak),大量对象引用没有释放,JVM 无法对其自动回收,常见于使用了 File 等资源没有回收
"}],"id":"82077529709e","title":"场景
"},{"parent":"69d4722f6204","children":[{"parent":"bb0032b74d7a","children":[],"id":"4508b1e1415b","title":"针对大部分情况,通常只需要通过 -Xmx 参数调高 JVM 堆内存空间即可
"},{"parent":"bb0032b74d7a","children":[],"id":"8a21793fb810","title":"如果是超大对象,可以检查其合理性,比如是否一次性查询了数据库全部结果,而没有做结果数限制
"},{"parent":"bb0032b74d7a","children":[],"id":"7970de1c13ce","title":"如果是业务峰值压力,可以考虑添加机器资源,或者做限流降级
"},{"parent":"bb0032b74d7a","children":[],"id":"61721dad15fd","title":"如果是内存泄漏,需要找到持有的对象,修改代码设计,比如关闭没有释放的连接
"}],"id":"bb0032b74d7a","title":"解决方案
"}],"id":"69d4722f6204","title":"Java heap space
"},{"parent":"e5b794712d9f","children":[{"parent":"16ea8d379757","children":[],"id":"089b25ad7859","title":"当 Java 进程花费 98% 以上的时间执行 GC,但只恢复了不到 2% 的内存,且该动作连续重复了 5 次,就会抛出
"},{"parent":"16ea8d379757","children":[],"id":"4cccd7722816","title":"场景与解决方案与Java heap space类似
"}],"id":"16ea8d379757","title":"GC overhead limit exceeded
"},{"parent":"e5b794712d9f","children":[{"parent":"27f250898d47","children":[],"id":"b5735a767281","title":"该错误表示永久代(Permanent Generation)已用满,通常是因为加载的 class 数目太多或体积太大
"},{"parent":"27f250898d47","children":[{"parent":"7adba9e7ee50","children":[],"id":"f92f654bc6f2","title":"程序启动报错,修改 -XX:MaxPermSize 启动参数,调大永久代空间
"},{"parent":"7adba9e7ee50","children":[],"id":"a1ba084f84ae","title":"应用重新部署时报错,很可能是没有应用没有重启,导致加载了多份 class 信息,只需重启 JVM 即可解决
"},{"parent":"7adba9e7ee50","children":[],"id":"ac1dd7e1efe5","title":"运行时报错,应用程序可能会动态创建大量 class,而这些 class 的生命周期很短暂,但是 JVM 默认不会卸载 class,可以设置 -XX:+CMSClassUnloadingEnabled 和 -XX:+UseConcMarkSweepGC这两个参数允许 JVM 卸载 class
"},{"parent":"7adba9e7ee50","children":[],"id":"9908b8d183cb","title":"如果上述方法无法解决,可以通过 jmap 命令 dump 内存对象 jmap-dump:format=b,file=dump.hprof<process-id> ,然后利用 Eclipse MAT功能逐一分析开销最大的 classloader 和重复 class
"}],"id":"7adba9e7ee50","title":"解决方案
"}],"id":"27f250898d47","title":"Permgen space
"},{"parent":"e5b794712d9f","children":[{"parent":"5d9794eb44e3","children":[],"id":"ff167c68cd26","title":"该错误表示 Metaspace 已被用满,通常是因为加载的 class 数目太多或体积太大
"},{"parent":"5d9794eb44e3","children":[],"id":"9e30222f9cdd","title":"场景与解决方案与Permgen space类似,需注意调整元空间大小参数为 -XX:MaxMetaspaceSize
"}],"id":"5d9794eb44e3","title":"Metaspace(元空间)
"},{"parent":"e5b794712d9f","children":[{"parent":"88733d6fd9e1","children":[],"id":"4b3170dc49e7","title":"当 JVM 向底层操作系统请求创建一个新的 Native 线程时,如果没有足够的资源分配就会报此类错误
"},{"parent":"88733d6fd9e1","children":[{"parent":"2de99f106fd9","children":[],"id":"d2894deebffe","title":"线程数超过操作系统最大线程数 ulimit 限制
"},{"parent":"2de99f106fd9","children":[],"id":"6b4a4957f1f7","title":"线程数超过 kernel.pid_max(只能重启)
"},{"parent":"2de99f106fd9","children":[],"id":"697aa13d5593","title":"Native 内存不足
"}],"id":"2de99f106fd9","title":"场景
"},{"parent":"88733d6fd9e1","children":[{"parent":"d6e225b4cdbd","children":[],"id":"8f7d0718c783","title":"升级配置,为机器提供更多的内存
"},{"parent":"d6e225b4cdbd","children":[],"id":"fd893dac8e71","title":"降低 Java Heap Space 大小
"},{"parent":"d6e225b4cdbd","children":[],"id":"96d3dc50bfcf","title":"修复应用程序的线程泄漏问题
"},{"parent":"d6e225b4cdbd","children":[],"id":"0ab47fa12a24","title":"限制线程池大小
"},{"parent":"d6e225b4cdbd","children":[],"id":"28f3069b69cc","title":"使用 -Xss 参数减少线程栈的大小
"},{"parent":"d6e225b4cdbd","children":[],"id":"5b123c27cf17","title":"调高 OS 层面的线程最大数:执行 ulimia-a 查看最大线程数限制,使用 ulimit-u xxx 调整最大线程数限制
"}],"id":"d6e225b4cdbd","title":"解决方案
"}],"id":"88733d6fd9e1","title":"Unable to create new native thread
"},{"parent":"e5b794712d9f","children":[{"parent":"a207e8502e59","children":[],"id":"ee75aeab507e","title":"虚拟内存(Virtual Memory)由物理内存(Physical Memory)和交换空间(Swap Space)两部分组成。当运行时程序请求的虚拟内存溢出时就会报 Outof swap space? 错误
"},{"parent":"a207e8502e59","children":[{"parent":"e9aff14f85ee","children":[],"id":"f5d926e1a54d","title":"地址空间不足
"},{"parent":"e9aff14f85ee","children":[],"id":"0ab3e7bd4ce0","title":"物理内存已耗光
"},{"parent":"e9aff14f85ee","children":[],"id":"a719e6915e62","title":"应用程序的本地内存泄漏(native leak),例如不断申请本地内存,却不释放
"},{"parent":"e9aff14f85ee","children":[],"id":"95178fc0d9c2","title":"执行 jmap-histo:live<pid> 命令,强制执行 Full GC;如果几次执行后内存明显下降,则基本确认为 Direct ByteBuffer 问题
"}],"id":"e9aff14f85ee","title":"场景
"},{"parent":"a207e8502e59","children":[{"parent":"69838d20af49","children":[],"id":"f6eb75443db8","title":"升级地址空间为 64 bit
"},{"parent":"69838d20af49","children":[],"id":"4c2d62f88cd0","title":"使用 Arthas 检查是否为 Inflater/Deflater 解压缩问题,如果是,则显式调用 end 方法
"},{"parent":"69838d20af49","children":[],"id":"8149b8d47a40","title":"Direct ByteBuffer 问题可以通过启动参数 -XX:MaxDirectMemorySize 调低阈值
"},{"parent":"69838d20af49","children":[],"id":"67cf9ef9b29d","title":"升级服务器配置/隔离部署,避免争用
"}],"id":"69838d20af49","title":"解决方案
"}],"id":"a207e8502e59","title":"Out of swap space?
"},{"parent":"e5b794712d9f","children":[{"parent":"fc5d0b351a1a","children":[],"id":"dcbc57e34a45","title":"有一种内核作业(Kernel Job)名为 Out of Memory Killer,它会在可用内存极低的情况下"杀死"(kill)某些进程。OOM Killer 会对所有进程进行打分,然后将评分较低的进程"杀死",Killprocessorsacrifice child 错误不是由 JVM 层面触发的,而是由操作系统层面触发的
"},{"parent":"fc5d0b351a1a","children":[{"parent":"959ac5e8a270","children":[],"id":"a97b65d73f88","title":"默认情况下,Linux 内核允许进程申请的内存总量大于系统可用内存,通过这种"错峰复用"的方式可以更有效的利用系统资源。
然而,这种方式也会无可避免地带来一定的"超卖"风险。例如某些进程持续占用系统内存,然后导致其他进程没有可用内存。此时,系统将自动激活 OOM Killer,寻找评分低的进程,并将其"杀死",释放内存资源
"}],"id":"959ac5e8a270","title":"场景
"},{"parent":"fc5d0b351a1a","children":[{"parent":"a7ada05bbd00","children":[],"id":"2b1d922217cf","title":"升级服务器配置/隔离部署,避免争用
"},{"parent":"a7ada05bbd00","children":[],"id":"b9502a1fe60b","title":"OOM Killer 调优
"}],"id":"a7ada05bbd00","title":"解决方案
"}],"id":"fc5d0b351a1a","title":"Kill process or sacrifice child
"},{"parent":"e5b794712d9f","children":[{"parent":"4dfd99c9bc90","children":[],"id":"52471cca5e33","title":"JVM 限制了数组的最大长度,该错误表示程序请求创建的数组超过最大长度限制
"},{"parent":"4dfd99c9bc90","children":[{"parent":"7a7846a84d01","children":[],"id":"ef42a376573a","title":"检查代码,确认业务是否需要创建如此大的数组,是否可以拆分为多个块,分批执行
"}],"id":"7a7846a84d01","title":"解决方案
"}],"id":"4dfd99c9bc90","title":"Requested array size exceeds VM limit
"},{"parent":"e5b794712d9f","children":[{"parent":"926260b12712","children":[],"id":"7deb1188a580","title":"Direct ByteBuffer 的默认大小为 64 MB,一旦使用超出限制,就会抛出 Directbuffer memory 错误
"},{"parent":"926260b12712","children":[{"parent":"c8bb4e5de982","children":[],"id":"558937529cce","title":"Java 只能通过 ByteBuffer.allocateDirect 方法使用 Direct ByteBuffer,因此,可以通过 Arthas 等在线诊断工具拦截该方法进行排查
"},{"parent":"c8bb4e5de982","children":[],"id":"04d0566021d0","title":"检查是否直接或间接使用了 NIO,如 netty,jetty 等
"},{"parent":"c8bb4e5de982","children":[],"id":"a5ff4af8fc72","title":"通过启动参数 -XX:MaxDirectMemorySize 调整 Direct ByteBuffer 的上限值
"},{"parent":"c8bb4e5de982","children":[],"id":"eb97fd5380b3","title":"检查 JVM 参数是否有 -XX:+DisableExplicitGC 选项,如果有就去掉,因为该参数会使 System.gc()失效
"},{"parent":"c8bb4e5de982","children":[],"id":"e19382936700","title":"检查堆外内存使用代码,确认是否存在内存泄漏;或者通过反射调用 sun.misc.Cleaner 的 clean() 方法来主动释放被 Direct ByteBuffer 持有的内存空间
"},{"parent":"c8bb4e5de982","children":[],"id":"b338bbfe6fec","title":"内存容量确实不足,升级配置
"}],"id":"c8bb4e5de982","title":"解决方案
"}],"id":"926260b12712","title":"Direct buffer memory
"}],"collapsed":false,"id":"e5b794712d9f","title":"OOM
"},{"parent":"f01a444aff49","children":[],"id":"4fca236e0053","title":"内存泄露"},{"parent":"f01a444aff49","children":[],"id":"31b72a753814","title":"线程死锁
"},{"parent":"f01a444aff49","children":[],"id":"f5310ade47dc","title":"锁争用
"},{"parent":"f01a444aff49","children":[],"id":"be43a23fb08e","title":"Java进程消耗CPU过高
"}],"id":"f01a444aff49","title":"JVM调优
"},{"parent":"d61da867cb10","children":[{"parent":"5c6067b84b1e","children":[],"id":"03fed9bf17f7","title":"Jconsole"},{"parent":"5c6067b84b1e","children":[],"id":"b0ec90eb542b","title":"Jprofiler"},{"parent":"5c6067b84b1e","children":[],"id":"baa86063ec3e","title":"jvisualvm"},{"parent":"5c6067b84b1e","children":[],"id":"c7c342ec412e","title":"MAT"}],"id":"5c6067b84b1e","title":"JVM性能检测工具"},{"parent":"d61da867cb10","children":[{"parent":"9a58c2256f22","children":[],"id":"541fa6a430b7","title":"help dump"},{"parent":"9a58c2256f22","children":[],"id":"63ed06e60104","title":"生产机 dump"},{"parent":"9a58c2256f22","children":[],"id":"29df5ce1b166","title":"mat"},{"parent":"9a58c2256f22","children":[],"id":"a2815d62f70f","title":"jmap"},{"parent":"9a58c2256f22","children":[],"id":"aa872dbc3855","title":"-helpdump"}],"id":"9a58c2256f22","title":"内存泄露"},{"parent":"d61da867cb10","children":[{"parent":"dbe9489e1531","children":[],"id":"30af4ef10e6d","title":"topc -c"},{"parent":"dbe9489e1531","children":[],"id":"f413c8870538","title":"top -Hp pid"},{"parent":"dbe9489e1531","children":[{"parent":"d7a7bb2d1ce7","children":[],"id":"3d609323d047","title":"进制转换"}],"id":"d7a7bb2d1ce7","title":"jstack"},{"parent":"dbe9489e1531","children":[],"id":"28dc67e9bcc8","title":"cat
"}],"id":"dbe9489e1531","title":"CPU100%"}],"collapsed":true,"id":"d61da867cb10","title":"JVM"},{"parent":"root","lineStyle":{"randomLineColor":"#FF8502"},"children":[],"id":"ecbf53fba47d","title":"多线程"},{"parent":"root","lineStyle":{"randomLineColor":"#F5479C"},"children":[{"parent":"d1383b5af44b","children":[{"parent":"6846db773567","children":[{"parent":"9cfcc064de09","children":[],"id":"3cc1cea3b5d2","title":"Spring 中的 Bean 默认都是单例的"}],"id":"9cfcc064de09","title":"单例模式"},{"parent":"6846db773567","children":[{"parent":"70e04d48b002","children":[],"id":"79b9ad909b14","title":"Spring使用工厂模式通过 BeanFactory、ApplicationContext 创建 bean 对象"}],"id":"70e04d48b002","title":"工厂模式"},{"parent":"6846db773567","children":[{"parent":"18539d17e1a2","children":[],"id":"f10b087651f0","title":"Spring AOP 的增强或通知(Advice)使用到了适配器模式、spring MVC 中也是用到了适配器模式适配Controller"}],"id":"18539d17e1a2","title":"适配器模式
"},{"parent":"6846db773567","children":[{"parent":"aa0d772a111e","children":[],"id":"458c4c117473","title":"Spring AOP 功能的实现"}],"id":"aa0d772a111e","title":"代理设计模式
"},{"parent":"6846db773567","children":[{"parent":"cf993fcce1fa","children":[],"id":"5a9fd93671a5","title":"Spring 事件驱动模型就是观察者模式很经典的一个应用"}],"id":"cf993fcce1fa","title":"观察者模式
"},{"parent":"6846db773567","children":[],"id":"4761f7394f26","title":"... ..."}],"id":"6846db773567","title":"设计模式"},{"parent":"d1383b5af44b","children":[{"parent":"6be9b379c857","children":[{"image":{"w":721,"h":306,"url":"http://cdn.processon.com/60d5841c07912920c8095f17?e=1624609325&token=trhI0BY8QfVrIGn9nENop6JAc6l5nZuxhjQ62UfM:vvIb8jvxokB9aizRUTjAy8Dz4NI="},"parent":"8218ea06bbce","children":[{"parent":"f7aea39c3b24","children":[],"id":"408ac2ef4844","title":"Bean 容器找到配置文件中 Spring Bean 的定义"},{"parent":"f7aea39c3b24","children":[],"id":"34992c358614","title":"Bean 容器利用 Java Reflection API 创建一个Bean的实例"},{"parent":"f7aea39c3b24","children":[],"id":"e7981f427e63","title":"如果涉及到一些属性值 利用 set()方法设置一些属性值"},{"parent":"f7aea39c3b24","children":[],"id":"dbf75a139571","title":"如果 Bean 实现了 BeanNameAware 接口,调用 setBeanName()方法,传入Bean的名字"},{"parent":"f7aea39c3b24","children":[],"id":"787517f23307","title":"如果 Bean 实现了 BeanClassLoaderAware 接口,调用 setBeanClassLoader()方法,传入 ClassLoader对象的实例"},{"parent":"f7aea39c3b24","children":[],"id":"6466197a3ddf","title":"如果Bean实现了 BeanFactoryAware 接口,调用 setBeanClassLoader()方法,传入 ClassLoader 对象的实例"},{"parent":"f7aea39c3b24","children":[],"id":"feac889b1b8d","title":"与上面的类似,如果实现了其他 *.Aware接口,就调用相应的方法"},{"parent":"f7aea39c3b24","children":[],"id":"91b027b10223","title":"如果有和加载这个 Bean 的 Spring 容器相关的 BeanPostProcessor 对象,执行postProcessBeforeInitialization() 方法"},{"parent":"f7aea39c3b24","children":[],"id":"b1af63401bf5","title":"如果Bean实现了InitializingBean接口,执行afterPropertiesSet()方法
"},{"parent":"f7aea39c3b24","children":[],"id":"37fa23a9c16a","title":"如果 Bean 在配置文件中的定义包含 init-method 属性,执行指定的方法"},{"parent":"f7aea39c3b24","children":[],"id":"b57d01a401e0","title":"如果有和加载这个 Bean的 Spring 容器相关的 BeanPostProcessor 对象,执行postProcessAfterInitialization() 方法"},{"parent":"f7aea39c3b24","children":[],"id":"baf7bd961172","title":"当要销毁 Bean 的时候,如果 Bean 实现了 DisposableBean 接口,执行 destroy() 方法"},{"parent":"f7aea39c3b24","children":[],"id":"da536275f445","title":"当要销毁 Bean 的时候,如果 Bean 在配置文件中的定义包含 destroy-method 属性,执行指定的方法"}],"style":{"text-align":"center"},"id":"f7aea39c3b24","title":"Spring Bean 生命周期"}],"id":"8218ea06bbce","title":"生命周期"},{"parent":"6be9b379c857","children":[{"parent":"780f6b30ba11","children":[{"parent":"69fa69a6315a","children":[],"id":"847478f4b37e","title":"唯一 bean 实例,Spring 中的 bean 默认都是单例的
"}],"id":"69fa69a6315a","title":"singleton
"},{"parent":"780f6b30ba11","children":[{"parent":"61779d764f15","children":[],"id":"1b7c8dc3e783","title":"每次请求都会创建一个新的 bean 实例
"}],"id":"61779d764f15","title":"prototype
"},{"parent":"780f6b30ba11","children":[{"parent":"b84f40579383","children":[],"id":"a2c0221f2a17","title":"每一次HTTP请求都会产生一个新的bean,该bean仅在当前HTTP request内有效
"}],"id":"b84f40579383","title":"request
"},{"parent":"780f6b30ba11","children":[{"parent":"2980654747ac","children":[],"id":"df20b0568d9b","title":"每一次HTTP请求都会产生一个新的 bean,该bean仅在当前 HTTP session 内有效
"}],"id":"2980654747ac","title":"session
"}],"id":"780f6b30ba11","title":"作用域"},{"parent":"6be9b379c857","children":[{"parent":"94d2392b941d","children":[],"id":"f6facb5c7bdf","title":"单例 bean 存在线程问题,主要是因为当多个线程操作同一个对象的时候,对这个对象的非静态成员变量的写操作会存在线程安全问题
"},{"parent":"94d2392b941d","children":[{"parent":"c50f84f9dd07","children":[],"id":"6a052cae7ac3","title":"在Bean对象中尽量避免定义可变的成员变量(不太现实)"},{"parent":"c50f84f9dd07","children":[],"id":"be83d8ee0d9c","title":"在类中定义一个ThreadLocal成员变量,将需要的可变成员变量保存在 ThreadLocal 中(推荐的一种方式)"}],"id":"c50f84f9dd07","title":"解决方案"}],"id":"94d2392b941d","title":"单例Bean线程不安全"}],"id":"6be9b379c857","title":"Bean"},{"parent":"d1383b5af44b","children":[{"parent":"2bd94a15f271","children":[{"parent":"db24e1d06ef6","children":[],"id":"c975e1461b17","title":"循环依赖其实就是循环引用,一个或多个对象实例之间存在直接或间接的依赖关系,这种依赖关系构成了构成一个环形调用"}],"id":"db24e1d06ef6","title":"定义"},{"parent":"2bd94a15f271","children":[{"parent":"6429ee8470d0","children":[{"parent":"b444d530df33","children":[],"id":"fe4447498b81","title":"可以解决"}],"id":"b444d530df33","title":"单例setter注入
"},{"parent":"6429ee8470d0","children":[{"parent":"a628a0c088fe","children":[],"id":"7d2affdf5098","title":"不能解决"}],"id":"a628a0c088fe","title":"多例setter注入"},{"parent":"6429ee8470d0","children":[{"parent":"52ccb73aaa1c","children":[],"id":"c5d72e9224fc","title":"不能解决"}],"id":"52ccb73aaa1c","title":"构造器注入"},{"parent":"6429ee8470d0","children":[{"parent":"e0ddcb98872d","children":[],"id":"8bc315c0e4f4","title":"有可能解决"}],"id":"e0ddcb98872d","title":"单例的代理对象注入
"},{"parent":"6429ee8470d0","children":[{"parent":"c1883b1d1d04","children":[],"id":"30c4d71d67b7","title":"不能解决"}],"id":"c1883b1d1d04","title":"DependOn循环依赖
"}],"id":"6429ee8470d0","title":"主要场景"},{"parent":"2bd94a15f271","children":[{"parent":"34656efe2153","children":[],"id":"07eedf3c5055","title":"一级缓存: 用于保存实例化、注入、初始化完成的bean实例
"},{"parent":"34656efe2153","children":[],"id":"5389148434c4","title":"二级缓存: 用于保存实例化完成的bean实例"},{"parent":"34656efe2153","children":[],"id":"de57eefcdc3f","title":"三级缓存: 用于保存bean创建工厂,以便于后面扩展有机会创建代理对象"}],"id":"34656efe2153","title":"三级缓存"},{"parent":"2bd94a15f271","children":[{"image":{"w":720,"h":309,"url":"http://cdn.processon.com/60d58be3e0b34d7f1166296f?e=1624611315&token=trhI0BY8QfVrIGn9nENop6JAc6l5nZuxhjQ62UfM:Szb4rjzK4-RP973_dTYTIc1x1yg="},"parent":"7537dcdb4537","children":[],"style":{"text-align":"center"},"id":"813c5d07800b","title":"Spring解决循环依赖"}],"id":"7537dcdb4537","title":"Spring如何解决循环依赖?"},{"parent":"2bd94a15f271","children":[{"parent":"6809a28c84fb","children":[{"parent":"0b65efef98be","children":[],"id":"edb8657d8633","title":"使用@Lazy注解,延迟加载
"},{"parent":"0b65efef98be","children":[],"id":"713bcafda8f8","title":"使用@DependsOn注解,指定加载先后关系
"},{"parent":"0b65efef98be","children":[],"id":"ecde0ac2eff5","title":"修改文件名称,改变循环依赖类的加载顺序
"}],"id":"0b65efef98be","title":"生成代理对象产生的循环依赖
"},{"parent":"6809a28c84fb","children":[{"parent":"19fc35c94a10","children":[],"id":"a898194da78e","title":"找到@DependsOn注解循环依赖的地方,迫使它不循环依赖
"}],"id":"19fc35c94a10","title":"使用@DependsOn产生的循环依赖
"},{"parent":"6809a28c84fb","children":[{"parent":"67569155e5e1","children":[],"id":"fbefaf05f15b","title":"把bean改成单例"}],"id":"67569155e5e1","title":"多例循环依赖"},{"parent":"6809a28c84fb","children":[{"parent":"d1721015c62e","children":[],"id":"086c2cf4a1f1","title":"使用@Lazy注解解决"}],"id":"d1721015c62e","title":"构造器循环依赖"}],"id":"6809a28c84fb","title":"Spring无法解决的循环依赖怎么解决?"}],"id":"2bd94a15f271","title":"循环依赖"},{"parent":"d1383b5af44b","children":[{"parent":"7525c1be5308","children":[],"id":"2efd2dd7603f","title":"Spring是父容器,SpringMVC是子容器,Spring父容器中注册的Bean对SpringMVC子容器是可见的,反之则不行"}],"id":"7525c1be5308","title":"父子容器"},{"parent":"d1383b5af44b","children":[{"parent":"2d661386d933","children":[],"id":"9dedda0f87c3","title":"采用不同的连接器"},{"parent":"2d661386d933","children":[{"parent":"9478703f6033","children":[],"id":"906c6c2186d9","title":"共享链接"}],"id":"9478703f6033","title":"用AOP 新建立了一个 链接"},{"parent":"2d661386d933","children":[],"id":"c0c888325014","title":"ThreadLocal 当前事务"},{"parent":"2d661386d933","children":[],"id":"cdf3bf19398a","title":"前提是 关闭AutoCommit"}],"id":"2d661386d933","title":"事务实现原理"},{"parent":"d1383b5af44b","children":[{"parent":"3fc3209ef908","children":[{"parent":"00348542df62","children":[{"parent":"7e65680e758d","children":[],"id":"9d4a3af2166d","title":"如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务"}],"id":"7e65680e758d","title":"PROPAGATION_REQUIRED"},{"parent":"00348542df62","children":[{"parent":"fbcd20add78f","children":[],"id":"bb981fa897b5","title":"如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行"}],"id":"fbcd20add78f","title":"PROPAGATION_SUPPORTS"},{"parent":"00348542df62","children":[{"parent":"fa9c9e3e91b3","children":[],"id":"f0bd2ab03cb3","title":"如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。(mandatory:强制性)"}],"id":"fa9c9e3e91b3","title":"PROPAGATION_MANDATORY"}],"id":"00348542df62","title":"支持当前事务的情况"},{"parent":"3fc3209ef908","children":[{"parent":"be43db2ade73","children":[{"parent":"274fe413f9a9","children":[],"id":"a9835b9de879","title":"创建一个新的事务,如果当前存在事务,则把当前事务挂起"}],"id":"274fe413f9a9","title":"PROPAGATION_REQUIRES_NEW"},{"parent":"be43db2ade73","children":[{"parent":"6de124ee0323","children":[],"id":"73808be05652","title":"以非事务方式运行,如果当前存在事务,则把当前事务挂起"}],"id":"6de124ee0323","title":"PROPAGATION_NOT_SUPPORTED"},{"parent":"be43db2ade73","children":[{"parent":"b7f5bd597d94","children":[],"id":"aade3bc122d2","title":"以非事务方式运行,如果当前存在事务,则抛出异常"}],"id":"b7f5bd597d94","title":"PROPAGATION_NEVER"}],"id":"be43db2ade73","title":"不支持当前事务的情况"},{"parent":"3fc3209ef908","children":[{"parent":"c633fc129e54","children":[{"parent":"7f933d08995d","children":[],"id":"29d2241160ac","title":"如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;如果当前没有事务,则该取值等价于PROPAGATION_REQUIRED"}],"id":"7f933d08995d","title":"PROPAGATION_NESTED"}],"id":"c633fc129e54","title":"其他情况"}],"id":"3fc3209ef908","title":"事务的传播行为"},{"parent":"d1383b5af44b","children":[{"parent":"d09326c239bc","children":[{"parent":"0ddcc4fc0973","children":[],"id":"2b143ba58aa6","title":"实现类"}],"id":"0ddcc4fc0973","title":"静态代理"},{"parent":"d09326c239bc","children":[{"parent":"e88e55b4f4a1","children":[{"parent":"93e7c1779448","children":[{"parent":"2b790def7035","children":[{"parent":"8aadeb882937","children":[],"id":"b8325d0d990f","title":"调用具体方法的时候调用invokeHandler"}],"id":"8aadeb882937","title":"java反射机制生成一个代理接口的匿名类"}],"id":"2b790def7035","title":"实现接口"}],"id":"93e7c1779448","title":"JDK动态代理"},{"parent":"e88e55b4f4a1","children":[{"parent":"ad4aa9aa8708","children":[{"parent":"d62f18134c3b","children":[],"id":"f4f870f8a078","title":"修改字节码生成子类去处理"}],"id":"d62f18134c3b","title":"asm字节码编辑技术动态创建类 基于classLoad装载"}],"id":"ad4aa9aa8708","title":"cglib"}],"id":"e88e55b4f4a1","title":"动态代理"}],"id":"d09326c239bc","title":"AOP"},{"parent":"d1383b5af44b","children":[],"id":"321b75efaafa","title":"IOC"}],"collapsed":true,"id":"d1383b5af44b","title":"Spring
"},{"parent":"root","lineStyle":{"randomLineColor":"#4D69FD"},"children":[{"parent":"93b7f849fef3","children":[{"parent":"2d833717c2db","children":[{"parent":"688bd93ca78f","children":[{"parent":"adb794ebf462","children":[],"id":"28b48a3fc7d9","title":"MVCC支持高并发、四个隔离级别(默认为可重复读)、支持事务操作、聚簇索引
"}],"id":"adb794ebf462","title":"InnoDB
"},{"parent":"688bd93ca78f","children":[{"parent":"9851e7c98465","children":[],"id":"6cda6ad38022","title":"全文索引、压缩、空间函数、崩溃后无法安全恢复
"}],"id":"9851e7c98465","title":"MyISAM
"}],"id":"688bd93ca78f","title":"常见"},{"parent":"2d833717c2db","children":[{"parent":"259d8b591849","children":[{"parent":"8af8eb9d1749","children":[],"id":"faac28b5b4bf","title":"只支持insert、select操作,适合日志和数据采集
"}],"id":"8af8eb9d1749","title":"Archive
"},{"parent":"259d8b591849","children":[{"parent":"246578695747","children":[],"id":"6b252c309014","title":"会丢弃所有插入数据,不做保存,记录Blackhole日志,可以用于复制数据库到备份库
"}],"id":"246578695747","title":"Blackhole
"},{"parent":"259d8b591849","children":[{"parent":"22c9f95864a3","children":[],"id":"c91fe24e6951","title":"可以将CSV文件作为MySQL表处理,不支持索引
"}],"id":"22c9f95864a3","title":"CSV
"},{"parent":"259d8b591849","children":[{"parent":"4c62ccaebd05","children":[],"id":"1707d3b04d53","title":"访问MySQL服务器的一个代理,创建远程到MySQL服务器的客户端连接,默认禁用
"}],"id":"4c62ccaebd05","title":"Federated
"},{"parent":"259d8b591849","children":[{"parent":"7c87e4ff16d1","children":[],"id":"66796cc84a6b","title":"数据保存在内存中,不需要磁盘I/O,重启后数据会丢失但是表结构会保留
"}],"id":"7c87e4ff16d1","title":"Memory
"},{"parent":"259d8b591849","children":[{"parent":"7e8ec900b7d9","children":[],"id":"260f221a82a2","title":"MyISAM变种,可以用于日志或数据仓库,已被放弃
"}],"id":"7e8ec900b7d9","title":"Merge
"},{"parent":"259d8b591849","children":[{"parent":"deaf720f74d6","children":[],"id":"f24022cd65fd","title":"集群引擎
"}],"id":"deaf720f74d6","title":"NDB
"}],"id":"259d8b591849","title":"其他(可做了解)"}],"collapsed":false,"id":"2d833717c2db","title":"存储引擎"},{"parent":"93b7f849fef3","children":[{"parent":"a5966d5788f2","children":[{"parent":"7adc8a1c18d2","children":[],"id":"a4370f67b89b","title":"binlog记录了数据库表结构和表数据变更,比如update/delete/insert/truncate/create
"},{"parent":"7adc8a1c18d2","children":[],"id":"4aade95fc08c","title":"主要用来复制和恢复数据"}],"id":"7adc8a1c18d2","title":"binlog
"},{"parent":"a5966d5788f2","children":[{"parent":"7577f673f85c","children":[],"id":"31aeaae43467","title":"在写入内存后会产生redo log,记录本次在某个页上做了什么修改
"},{"parent":"7577f673f85c","children":[],"id":"142d34087f0c","title":"恢复写入内存但数据还没真正写到磁盘的数据,redo log记载的是物理变化,文件的体积很小,恢复速度很快
"}],"id":"7577f673f85c","title":"redo log
"},{"parent":"a5966d5788f2","children":[{"parent":"4814832d3190","children":[],"id":"c90806ae3f83","title":"undo log是逻辑日志,存储着修改之前的数据,相当于一个前版本
"},{"parent":"4814832d3190","children":[],"id":"99805bbdffab","title":"用来回滚和多版本控制"}],"id":"4814832d3190","title":"undo log
"},{"parent":"a5966d5788f2","children":[{"parent":"5dfacdc162c1","children":[],"id":"8d3250892fd5","title":"redo log 记录的是数据的物理变化,binlog 记录的是数据的逻辑变化"},{"parent":"5dfacdc162c1","children":[],"id":"42cefe6fd536","title":"redo log的作用是为持久化而生的,仅存储写入内存但还未刷到磁盘的数据;binlog的作用是复制和恢复而生的,保持主从数据库的一致性,如果整个数据库的数据都被删除了,可以通过binlog恢复,而redo log则不能
"},{"parent":"5dfacdc162c1","children":[],"id":"5590b5b15841","title":"redo log是MySQL的InnoDB引擎所产生的;binlog无论MySQL用什么引擎,都会有的"},{"parent":"5dfacdc162c1","children":[{"parent":"fa7e2894f9c9","children":[{"parent":"b2f9cb6a36f3","children":[{"parent":"be9575df9c26","children":[],"id":"8b3e3c83afb7","title":"如果写redo log失败了,那我们就认为这次事务有问题,回滚,不再写binlog"},{"parent":"be9575df9c26","children":[],"id":"a1220b7a6966","title":"如果写redo log成功了,写binlog,写binlog写一半了,但失败了怎么办?我们还是会对这次的事务回滚,将无效的binlog给删除(因为binlog会影响从库的数据,所以需要做删除操作)"},{"parent":"be9575df9c26","children":[],"id":"122c9e026c22","title":"如果写redo log和binlog都成功了,那这次算是事务才会真正成功"}],"id":"be9575df9c26","title":"解析"},{"parent":"b2f9cb6a36f3","children":[{"parent":"be4d6b8613d4","children":[{"parent":"b17221822991","children":[],"id":"9383dc884572","title":"如果redo log写失败了,而binlog写成功了。那假设内存的数据还没来得及落磁盘,机器就挂掉了。那主从服务器的数据就不一致了。(从服务器通过binlog得到最新的数据,而主服务器由于redo log没有记载,没法恢复数据)"},{"parent":"b17221822991","children":[],"id":"4f824c63c2b0","title":"如果redo log写成功了,而binlog写失败了。那从服务器就拿不到最新的数据了"}],"id":"b17221822991","title":"MySQL需要保证redo log和binlog的数据是一致的"}],"id":"be4d6b8613d4","title":"结论"},{"parent":"b2f9cb6a36f3","children":[{"parent":"4c6de79ecd53","children":[{"parent":"9f54d23f7748","children":[{"parent":"4387d2b41401","children":[],"id":"a4c2899d7ffa","title":"阶段1:InnoDBredo log 写盘,InnoDB 事务进入 prepare(做好准备) 状态"},{"parent":"4387d2b41401","children":[],"id":"05dea48990c1","title":"阶段2:binlog 写盘,InooDB 事务进入 commit(提交) 状态"},{"parent":"4387d2b41401","children":[],"id":"7e939c251666","title":"每个事务binlog的末尾,会记录一个 XID event,标志着事务是否提交成功,也就是说,恢复过程中,binlog 最后一个 XID event 之后的内容都应该被 purge(清除)"}],"id":"4387d2b41401","title":"过程"}],"id":"9f54d23f7748","title":"MySQL通过两阶段提交来保证redo log和binlog的数据是一致的"}],"id":"4c6de79ecd53","title":"保持一致性的方法"}],"id":"b2f9cb6a36f3","title":"引申问题:在写入某一个log,失败了,那会怎么办?比如先写redo log,再写binlog"}],"id":"fa7e2894f9c9","title":"redo log事务开始的时候,就开始记录每次的变更信息,而binlog是在事务提交的时候才记录"}],"id":"5dfacdc162c1","title":"binlog与redo log的区别"},{"parent":"a5966d5788f2","children":[{"parent":"cea3499ae4ce","children":[{"parent":"e50c2afacca9","children":[],"id":"18fce611a383","title":"默认不开启,需要手动将参数设置为ON"}],"id":"e50c2afacca9","title":"慢查询日志,记录所有执行时间超过long_query_time的所有查询或不使用索引的查询
"}],"id":"cea3499ae4ce","title":"slow log
"}],"collapsed":false,"id":"a5966d5788f2","title":"log"},{"parent":"93b7f849fef3","children":[{"parent":"5210cc3e2201","children":[{"parent":"9901dd2630fa","children":[{"parent":"f2714fc25cf8","children":[{"parent":"72e55f7388bc","children":[],"id":"efa64c497a6e","title":"B树在提高了IO性能的同时并没有解决元素遍历的效率低下的问题,为了解决这个问题产生了B+树。B+树只需要去遍历叶子节点就可以实现整棵树的遍历。而在数据库中基于范围的查询是非常频繁的,但B树不支持这样的操作或者说效率太低"}],"id":"72e55f7388bc","title":"为什么选用B+Tree不选择B-Tree?"},{"parent":"f2714fc25cf8","children":[{"parent":"118574a529fa","children":[{"parent":"e98c2b0bce63","children":[],"id":"70ba3b2ec259","title":"和索引中的所有列进行匹配"}],"id":"e98c2b0bce63","title":"全值匹配"},{"parent":"118574a529fa","children":[{"parent":"f6fe4bbe8879","children":[],"id":"6650dea74984","title":"只使用索引的第一列"}],"id":"f6fe4bbe8879","title":"匹配最左前缀"},{"parent":"118574a529fa","children":[{"parent":"a8e32170dad9","children":[],"id":"0736d8171b6b","title":"只匹配某一列值的开头部分"}],"id":"a8e32170dad9","title":"匹配列前缀"},{"parent":"118574a529fa","children":[{"parent":"c3ecae94375c","children":[],"id":"d6ce88217808","title":"查找范围区间"}],"id":"c3ecae94375c","title":"匹配范围值"},{"parent":"118574a529fa","children":[{"parent":"f7a85f0b29a2","children":[],"id":"f2c263321a5b","title":"第一列全匹配,第二列匹配范围区间"}],"id":"f7a85f0b29a2","title":"精确匹配某一列并范围匹配另外一列"},{"parent":"118574a529fa","children":[{"parent":"00e02f358513","children":[],"id":"7eaacfcc4407","title":"覆盖索引"}],"id":"00e02f358513","title":"只访问索引的查询"}],"id":"118574a529fa","title":"适用范围"}],"id":"f2714fc25cf8","title":"B+Tree 索引"},{"parent":"9901dd2630fa","children":[{"parent":"079407222137","children":[{"parent":"2961e3444d75","children":[],"id":"9d63f5055547","title":"只有精确匹配索引所有列的查询才有效"}],"id":"2961e3444d75","title":"等值查询"}],"id":"079407222137","title":"Hash 索引"},{"parent":"9901dd2630fa","children":[{"parent":"ac2bb051dc41","children":[],"id":"b1fc3ee864fd","title":"MyISAM表支持,可以用作地理数据存储"}],"id":"ac2bb051dc41","title":"R- Tree 索引(空间数据索引)"},{"parent":"9901dd2630fa","children":[{"parent":"98bc7018f2e8","children":[],"id":"74d8f80862a6","title":"MyISAM表支持,查找文本中的关键字"}],"id":"98bc7018f2e8","title":"全文索引"}],"id":"9901dd2630fa","title":"常见索引"},{"parent":"5210cc3e2201","children":[{"parent":"eb2a05c840d5","children":[],"id":"38870688a881","title":"InnoDB通过主键聚集数据,若没有主键则会选择一个唯一非空索引代替,若都不存在则会隐式定义一个主键来作为聚簇索引"}],"id":"eb2a05c840d5","title":"聚簇索引"},{"parent":"5210cc3e2201","children":[{"parent":"c1563189924d","children":[],"id":"13d6a347d2e2","title":"会多进行一次扫描(回表操作)"}],"id":"c1563189924d","title":"非聚簇索引"},{"parent":"5210cc3e2201","children":[{"parent":"1c121f6da170","children":[{"parent":"e0e8ecd756d7","children":[],"id":"f3837dae5ad5","title":"索引不能是表达式的一部分,也不能是函数的参数
"}],"id":"e0e8ecd756d7","title":"独立的列"},{"parent":"1c121f6da170","children":[{"parent":"a3bd55e14de1","children":[],"id":"043d3ebd14c6","title":"在需要使用多列作为查询条件时,联合索引比使用多个单列索引性能更好
"}],"id":"a3bd55e14de1","title":"多列索引"},{"parent":"1c121f6da170","children":[{"parent":"d28f309facf7","children":[],"id":"cf867ae6885b","title":"将选择行最强的索引列放在最前面
"},{"parent":"d28f309facf7","children":[],"id":"977d01e8182f","title":"索引的选择性:不重复的索引值和记录总数的对比
"}],"id":"d28f309facf7","title":"索引列的顺序"},{"parent":"1c121f6da170","children":[{"parent":"6ed32658245b","children":[],"id":"a735cff03984","title":"对BLOG、TEXT、VARCHAR类型的列,使用前缀索引,索引开始的部分字符
"},{"parent":"6ed32658245b","children":[],"id":"9af199030361","title":"前缀索引的长度选取,需根据索引的选择性来确定
"}],"id":"6ed32658245b","title":"前缀索引"},{"parent":"1c121f6da170","children":[{"parent":"861978fd7ef6","children":[],"id":"94eacfaadf23","title":"索引包含所有需要查询的字段值"},{"parent":"861978fd7ef6","children":[{"parent":"5d4e9d8774fd","children":[],"id":"5d9d32175efc","title":"索引远小于数据行的大小,只读取索引能够减少数据访问量
"},{"parent":"5d4e9d8774fd","children":[],"id":"858036b36f18","title":"不用回表"}],"id":"5d4e9d8774fd","title":"优点"}],"id":"861978fd7ef6","title":"覆盖索引"}],"id":"1c121f6da170","title":"索引优化"},{"parent":"5210cc3e2201","children":[{"parent":"a88af8d55657","children":[],"id":"d05b0626264c","title":"大大减少了服务器需要扫描的数据行数"},{"parent":"a88af8d55657","children":[],"id":"f685636c3846","title":"帮助服务器避免进行排序和分组,以及避免创建临时表"},{"parent":"a88af8d55657","children":[],"id":"3df58d5d4a3b","title":"将随机 I/O 变为顺序 I/O"}],"id":"a88af8d55657","title":"索引的优点"},{"parent":"5210cc3e2201","children":[{"parent":"1792cb752801","children":[{"parent":"cef88efe00e5","children":[],"id":"c1e59b66fefb","title":"因为如果不是覆盖索引需要回表"}],"id":"cef88efe00e5","title":"对于非常小的表、大部分情况下简单的全表扫描比建立索引更高效"},{"parent":"1792cb752801","children":[],"id":"64956008bace","title":"对于中到大型的表,索引非常有效"},{"parent":"1792cb752801","children":[],"id":"4070060fdb7d","title":"对于特大型的表,建立和维护索引的代价将会随之增长。这种情况下,需要用到一种技术可以直接区分出需要查询的一组数据,而不是一条记录一条记录地匹配,例如可以使用分区技术"}],"id":"1792cb752801","title":"使用条件"}],"collapsed":false,"id":"5210cc3e2201","title":"索引"},{"parent":"93b7f849fef3","children":[{"parent":"1a7dcec2ca47","children":[{"parent":"85c67aaf34a6","children":[{"parent":"35c936f7bdfa","children":[],"id":"a596da0b2488","title":"SIMPLE 简单查询"},{"parent":"35c936f7bdfa","children":[],"id":"f4b9fe60c553","title":"UNION 联合查询"},{"parent":"35c936f7bdfa","children":[],"id":"5f4c581eaea4","title":"SUBQUERY 子查询"}],"id":"35c936f7bdfa","title":"select_type"},{"parent":"85c67aaf34a6","children":[{"parent":"46d559313322","children":[],"id":"c4ee393f6a07","title":"查询的表"}],"id":"46d559313322","title":"table"},{"parent":"85c67aaf34a6","children":[{"parent":"a7b85d2883a5","children":[],"id":"b616d85f45b2","title":"system"},{"parent":"a7b85d2883a5","children":[{"parent":"35007f4ba57f","children":[],"id":"f1988a49fc81","title":"只有一条查询结果&主键/唯一索引"}],"id":"35007f4ba57f","title":"const"},{"parent":"a7b85d2883a5","children":[{"parent":"ad8c20fd30de","children":[],"id":"96881f188e51","title":"链接查询&主键/唯一索引&只有一条查询结果"}],"id":"ad8c20fd30de","title":"eq_ref"},{"parent":"a7b85d2883a5","children":[{"parent":"f42e8c179697","children":[],"id":"f02141ac36a6","title":"非唯一索引"}],"id":"f42e8c179697","title":"ref"},{"parent":"a7b85d2883a5","children":[{"parent":"43897738682a","children":[],"id":"910cd850cb27","title":"使用索引进行范围查询时"}],"id":"43897738682a","title":"range"},{"parent":"a7b85d2883a5","children":[{"parent":"8fef129a816a","children":[],"id":"200bdd342f1e","title":"查询的字段时索引的一部分,覆盖索引"},{"parent":"8fef129a816a","children":[],"id":"462b089e56d4","title":"使用主键排序"}],"id":"8fef129a816a","title":"index"},{"parent":"a7b85d2883a5","children":[{"parent":"1bb5aaa0dd0d","children":[],"id":"764244bd2a17","title":"全表扫描"}],"id":"1bb5aaa0dd0d","title":"all"}],"id":"a7b85d2883a5","title":"type"},{"parent":"85c67aaf34a6","children":[{"parent":"b31b3a54b63b","children":[],"id":"dde0162686c2","title":"可选择的索引"}],"id":"b31b3a54b63b","title":"possible_keys"},{"parent":"85c67aaf34a6","children":[{"parent":"81ad0f7b17de","children":[],"id":"905080a6f852","title":"实际使用的索引"}],"id":"81ad0f7b17de","title":"key"},{"parent":"85c67aaf34a6","children":[{"parent":"e313359e3213","children":[],"id":"9094ee686fb6","title":"扫描的行数"}],"id":"e313359e3213","title":"rows"}],"id":"85c67aaf34a6","title":"使用 Explain 分析 Select 查询语句
"},{"parent":"1a7dcec2ca47","children":[{"parent":"766730b3f63f","children":[{"parent":"e4c6eb7dee1d","children":[],"id":"f00841c92b2d","title":"只查询必要的列,对使用*永远持怀疑态度"},{"parent":"e4c6eb7dee1d","children":[],"id":"6396af513501","title":"只返回必要的行,使用Limit限制返回行数"},{"parent":"e4c6eb7dee1d","children":[],"id":"e69aa7cfb00a","title":"缓存重复查询的数据,例如使用redis"}],"id":"e4c6eb7dee1d","title":"减少请求的数据量"},{"parent":"766730b3f63f","children":[{"parent":"64889a19144a","children":[],"id":"e3d6b04e7263","title":"使用索引覆盖查询"}],"id":"64889a19144a","title":"减少数据库扫描的行数"}],"id":"766730b3f63f","title":"优化数据访问"},{"parent":"1a7dcec2ca47","children":[{"parent":"879ad88fe515","children":[],"id":"4fcee3d0c287","title":"有时候一个复杂的查询并没有多个简单查询执行迅速"},{"parent":"879ad88fe515","children":[],"id":"344a37829ef0","title":"对于大查询,可以使用切分查询,每次只返回一小部分"},{"parent":"879ad88fe515","children":[],"id":"fd9207da3a3a","title":"对于关联查询,可根据情况进行分解,在应用程序中进行关联"},{"parent":"879ad88fe515","children":[],"id":"27dc6dbe2891","title":"对于大分页等场景, 可采用延迟关联
"}],"id":"879ad88fe515","title":"重构查询方式"}],"collapsed":false,"id":"1a7dcec2ca47","title":"查询性能优化"},{"parent":"93b7f849fef3","children":[{"parent":"f349bf5b5c84","children":[{"parent":"8a0fefaa1a67","children":[],"id":"9efbed658957","title":"原子性
"},{"parent":"8a0fefaa1a67","children":[],"id":"1fa9df39ec26","title":"一致性"},{"parent":"8a0fefaa1a67","children":[],"id":"814aae5b441a","title":"隔离性"},{"parent":"8a0fefaa1a67","children":[],"id":"98bb1a37de0d","title":"持久性"}],"collapsed":false,"id":"8a0fefaa1a67","title":"ACID"},{"parent":"f349bf5b5c84","children":[{"parent":"d4c5e6c7b97d","children":[{"parent":"46a0e40a540b","children":[],"id":"97fc28724d63","title":"事务读取未提交的数据"}],"id":"46a0e40a540b","title":"脏读"},{"parent":"d4c5e6c7b97d","children":[{"parent":"0a6b6f451a92","children":[],"id":"80ae6dfb6f8c","title":"一个事务内,多次读同一数据。A事务未结束,B事务访问同一数据,A事务读取两次可能不一致
"}],"id":"0a6b6f451a92","title":"不可重复读"},{"parent":"d4c5e6c7b97d","children":[{"parent":"c653b25154d9","children":[],"id":"dd1fc239cca6","title":"一个事务在前后两次查询同一范围的时候,后一次查询看到了前一次查询没有看到的行。事务A 按照一定条件进行数据读取, 期间事务B 插入了相同搜索条件的新数据,事务A再次按照原先条件进行读取时,发现了事务B 新插入的数据
"}],"id":"c653b25154d9","title":"幻读"},{"parent":"d4c5e6c7b97d","children":[{"parent":"ca82f84e0c45","children":[],"id":"0bae386e19f5","title":"一个事务的更新操作会被另一个事务的更新操作所覆盖"},{"parent":"ca82f84e0c45","children":[],"id":"b317c67d4337","title":"例如:T1 和 T2 两个事务都对一个数据进行修改,T1 先修改,T2 随后修改,T2 的修改覆盖了 T1 的修改"}],"id":"ca82f84e0c45","title":"丢失更新"}],"collapsed":false,"id":"d4c5e6c7b97d","title":"脏读、不可重复读、幻读、丢失更新
"},{"parent":"f349bf5b5c84","children":[{"parent":"54cad68df1e1","children":[{"parent":"187fad689217","children":[],"id":"40001f009aca","title":"事务可以读取未提交数据(脏读)
"},{"parent":"187fad689217","children":[],"id":"74d2f0b7e8ff","title":"存在脏读、不可重复读、幻读"}],"id":"187fad689217","title":"读未提交
"},{"parent":"54cad68df1e1","children":[{"parent":"831af13c1fe3","children":[],"id":"7e9293ed801e","title":"事务只可以读取已经提交的事务所做的修改
"},{"parent":"831af13c1fe3","children":[],"id":"7214bb4bdc0e","title":"存在不可重复读、幻读"}],"id":"831af13c1fe3","title":"读已提交
"},{"parent":"54cad68df1e1","children":[{"parent":"ddabe3557266","children":[],"id":"a6098ce57c11","title":"同一个事务多次读取同样记录结果一致
"},{"parent":"ddabe3557266","children":[],"id":"82158205dff5","title":"存在幻读"},{"parent":"ddabe3557266","children":[],"id":"2d11fbd7845e","title":"InnoDB默认级别
"}],"id":"ddabe3557266","title":"可重复读
"},{"parent":"54cad68df1e1","children":[{"parent":"329045116b43","children":[],"id":"f201ca426fb5","title":"读取每一行数据上都加锁
"},{"parent":"329045116b43","children":[],"id":"9040c49f6995","title":"存在加锁读"}],"id":"329045116b43","title":"可串行化
"}],"collapsed":false,"id":"54cad68df1e1","title":"事务隔离级别"},{"parent":"f349bf5b5c84","children":[{"parent":"0c3fe336f085","children":[{"parent":"e1911d4cb48b","children":[{"parent":"010c32dd6618","children":[],"id":"7abe6c3095a9","title":"允许事务读一行数据"}],"id":"010c32dd6618","title":"共享锁(读锁)"},{"parent":"e1911d4cb48b","children":[{"parent":"e440236253d1","children":[],"id":"27e41f2eeea3","title":"允许事务删除或更新一行数据"}],"id":"e440236253d1","title":"排他锁(写锁)"},{"parent":"e1911d4cb48b","children":[{"parent":"ae79dcf5ed09","children":[],"id":"b09a0093dd92","title":"事务想要获取一张表中某几行的共享锁
"}],"id":"ae79dcf5ed09","title":"意向共享锁"},{"parent":"e1911d4cb48b","children":[{"parent":"a843c2d1177e","children":[],"id":"470c8fe9653b","title":"事务想要获取一张表中某几行的排他锁"}],"id":"a843c2d1177e","title":"意向排他锁"}],"id":"e1911d4cb48b","title":"锁类型
"},{"parent":"0c3fe336f085","children":[{"parent":"3a31e35e17d1","children":[{"parent":"8458c31623f5","children":[],"id":"2fb5f24d4ca4","title":"锁定整张表,是开销最小的策略"},{"parent":"8458c31623f5","children":[],"id":"fc59fa7dd010","title":"开销小,加锁快;无死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低"}],"id":"8458c31623f5","title":"表锁"},{"parent":"3a31e35e17d1","children":[{"parent":"85be4bb1b97c","children":[],"id":"7a8a1338b899","title":"行级锁只对用户正在访问的行进行锁定"},{"parent":"85be4bb1b97c","children":[],"id":"1fe3439f48cb","title":"开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高"},{"parent":"85be4bb1b97c","children":[{"parent":"767fe9aba9f7","children":[],"id":"e87c3357ae96","title":"当行锁涉及到索引失效的时候,会触发表锁的行为"}],"id":"767fe9aba9f7","title":"升级行为"}],"id":"85be4bb1b97c","title":"行锁"},{"parent":"3a31e35e17d1","children":[],"id":"30d6e73385cf","title":"间隙锁"}],"id":"3a31e35e17d1","title":"锁粒度"}],"id":"0c3fe336f085","title":"锁"},{"parent":"f349bf5b5c84","children":[{"parent":"eed5a9459b5a","children":[{"parent":"ce09c69be50f","children":[{"parent":"eed8dbe525bf","children":[],"id":"8e7afdfa1b51","title":"像select lock in share mode(共享锁), select for update ; update, insert ,delete(排他锁)这些操作都是一种当前读。它读取的是记录的最新版本,读取时还要保证其他并发事务不能修改当前记录,会对读取的记录进行加锁"}],"id":"eed8dbe525bf","title":"当前读"},{"parent":"ce09c69be50f","children":[{"parent":"64325b6f0da8","children":[],"id":"2025e92bff9a","title":"不加锁的select操作就是快照读。快照读的前提是隔离级别不是串行级别,串行级别下的快照读会退化成当前读。快照读基于MVCC,为了提高并发性能的考虑
"}],"id":"64325b6f0da8","title":"快照读"}],"id":"ce09c69be50f","title":"当前读与快照读"},{"parent":"eed5a9459b5a","children":[{"parent":"287cd593da0c","children":[{"parent":"9d63e35bb5f6","children":[],"id":"2c3c0a528cb3","title":"存储的每次对某条聚簇索引记录进行修改的时候的事务id"}],"id":"9d63e35bb5f6","title":"trx_id"},{"parent":"287cd593da0c","children":[{"parent":"01688368c063","children":[],"id":"1a6030a34904","title":"一个指针,它指向这条聚簇索引记录的上一个版本的位置
"}],"id":"01688368c063","title":"roll_pointer
"}],"id":"287cd593da0c","title":"聚簇索引中的隐藏列"},{"parent":"eed5a9459b5a","children":[{"parent":"629025098291","children":[],"id":"fd5bc24b1ab0","title":"Read View 保存了当前事务开启时所有活跃的事务列表"}],"id":"629025098291","title":"ReadView
"},{"parent":"eed5a9459b5a","children":[{"parent":"0a9f4b6b3fd8","children":[],"id":"2fda9cd25a51","title":"获取事务自己的版本号,即 事务ID
"},{"parent":"0a9f4b6b3fd8","children":[],"id":"69d637f03ec4","title":"获取 ReadView
"},{"parent":"0a9f4b6b3fd8","children":[{"parent":"d234974b39a2","children":[{"parent":"00c306141cc3","children":[],"id":"6793592fd10e","title":"直接读取最新版本ReadView
"}],"id":"00c306141cc3","title":"读未提交
"},{"parent":"d234974b39a2","children":[{"parent":"cd3375057c84","children":[],"id":"d9b62e5bee77","title":"每次查询的开始都会生成一个独立的ReadView
"}],"id":"cd3375057c84","title":"读已提交
"},{"parent":"d234974b39a2","children":[{"parent":"b9c1beaa17b7","children":[],"id":"37c1b07a6706","title":"可重复读隔离级别则在第一次读的时候生成一个ReadView,之后的读都复用之前的ReadView
"}],"id":"b9c1beaa17b7","title":"可重复读
"}],"id":"d234974b39a2","title":"查询得到的数据,然后与 ReadView 中的事务版本号进行比较
"},{"parent":"0a9f4b6b3fd8","children":[],"id":"0931e9c7e939","title":"如果不符合 ReadView 规则, 那么就需要 UndoLog 中历史快照
"},{"parent":"0a9f4b6b3fd8","children":[],"id":"ed2a683bfd62","title":"最后返回符合规则的数据
"}],"id":"0a9f4b6b3fd8","title":"实现原理"}],"id":"eed5a9459b5a","title":"MVCC"}],"collapsed":false,"id":"f349bf5b5c84","title":"事务"},{"parent":"93b7f849fef3","children":[{"parent":"7bb42e3d47e8","children":[{"parent":"f04740c1a26a","children":[{"parent":"6344bab34462","children":[],"id":"e844fe3ee99d","title":"借助第三方工具pt-online-schema-change"}],"id":"6344bab34462","title":"修改为bigint"},{"parent":"f04740c1a26a","children":[],"id":"c9cc52e3755f","title":"一般用不完就分库分表了, 使用全局唯一id"}],"id":"f04740c1a26a","title":"自增id用完了"},{"parent":"7bb42e3d47e8","children":[{"parent":"827ace408eb2","children":[],"id":"0662d7098e60","title":"设置 binlog_group_commit_sync_delay 和 binlog_group_commit_sync_no_delay_count参数,减少binlog的写盘次数。这个方法是基于"额外的故意等待"来实现的,因此可能会增加语句的响应时间,但没有丢失数据的风险。
将sync_binlog 设置为大于1的值(比较常见是100~1000)。这样做的风险是,主机掉电时会丢binlog日志。
将innodb_flush_log_at_trx_commit设置为2。这样做的风险是,主机掉电的时候会丢数据。"}],"id":"827ace408eb2","title":"IO性能瓶颈"}],"id":"7bb42e3d47e8","title":"常见问题"}],"collapsed":true,"id":"93b7f849fef3","title":"MySQL"},{"parent":"root","lineStyle":{"randomLineColor":"#F5479C"},"children":[{"parent":"68e2d53f78c0","children":[{"parent":"a2ba7f2839e7","children":[],"id":"332a1e1ff9de","title":"秒杀的库存扣减"},{"parent":"a2ba7f2839e7","children":[],"id":"fdc0cda55b5c","title":"APP首页的访问流量高峰"},{"parent":"a2ba7f2839e7","children":[],"id":"235928a55a4d","title":"避免数据库打崩"}],"id":"a2ba7f2839e7","title":"为什么使用Redis"},{"parent":"68e2d53f78c0","children":[{"parent":"1bbcd515493d","children":[{"parent":"d6e64200f130","children":[{"parent":"c1b235ccc3a0","children":[],"id":"af253a7e312d","title":"key-value,类似ArrayList"}],"id":"c1b235ccc3a0","title":"String"},{"parent":"d6e64200f130","children":[],"id":"805ec0ae37ce","title":"Hash"},{"parent":"d6e64200f130","children":[],"id":"18c40debca54","title":"set"},{"parent":"d6e64200f130","children":[],"id":"5aba119e78a1","title":"zset"},{"parent":"d6e64200f130","children":[],"id":"466e3ae93922","title":"List"}],"id":"d6e64200f130","title":"必会项"},{"parent":"1bbcd515493d","children":[{"parent":"e08a90c96b17","children":[{"parent":"aac9ee1c9de2","children":[],"id":"6529bc24a01c","title":"统计网站UV(独立访客,每个用户每天只记录一次)"}],"id":"aac9ee1c9de2","title":"HyperLogLog
"},{"parent":"e08a90c96b17","children":[{"parent":"e9b70d2f5e4a","children":[],"id":"09ba2789d093","title":"计算地理位置,类似功能附近的人"}],"id":"e9b70d2f5e4a","title":"Geo"},{"parent":"e08a90c96b17","children":[{"parent":"36770e0d1f7f","children":[],"id":"951025427dd0","title":"消息的多播,发布/订阅,无法持久化"}],"id":"36770e0d1f7f","title":"Pub/Sub"},{"parent":"e08a90c96b17","children":[{"parent":"504b0480286f","children":[],"id":"ff3c30b3b218","title":"用户签到,短视频属性(特效,加锁),用户在线状态,活跃状态
"}],"id":"504b0480286f","title":"BitMap"},{"parent":"e08a90c96b17","children":[{"parent":"750183397ab0","children":[{"parent":"d912173e6c29","children":[],"id":"c0d25c9698a3","title":"缓存穿透"},{"parent":"d912173e6c29","children":[],"id":"cea22ee9fb6b","title":"海量数据去重"}],"id":"d912173e6c29","title":"使用场景"},{"parent":"750183397ab0","children":[{"parent":"d1cce1828064","children":[{"parent":"1c2955281250","children":[],"id":"ebe498b35f4e","title":"可以通过建立一个白名单来存储可能会误判的元素"}],"id":"1c2955281250","title":"存在误判"},{"parent":"d1cce1828064","children":[{"parent":"e4d933c94529","children":[],"id":"0f690c41bf85","title":"可以采用Counting Bloom Filter"}],"id":"e4d933c94529","title":"删除困难"}],"id":"d1cce1828064","title":"缺点"},{"parent":"750183397ab0","children":[{"parent":"3ee30b7a6a80","children":[],"id":"c672a0977842","title":"redisson"},{"parent":"3ee30b7a6a80","children":[],"id":"3525627855c4","title":"guava"}],"id":"3ee30b7a6a80","title":"现成的轮子"},{"parent":"750183397ab0","children":[{"parent":"e23b985c75be","children":[{"parent":"015aee9efba2","children":[],"id":"7a36e20faba7","title":"可进行设置, 默认值为0.03"}],"id":"015aee9efba2","title":"预估数据量n以及期望的误判率fpp"},{"parent":"e23b985c75be","children":[{"parent":"2aa25fd1f61c","children":[{"parent":"2b742b98e5af","children":[],"style":{"font-size":19},"id":"6e1979c1417e","title":""}],"id":"2b742b98e5af","title":"Bit数组大小"},{"parent":"2aa25fd1f61c","children":[{"parent":"744b38ebf3de","children":[],"style":{"font-size":20},"id":"19690dd504f2","title":""}],"id":"744b38ebf3de","title":"哈希函数选择"}],"id":"2aa25fd1f61c","title":"hash函数的选取以及bit数组的大小"}],"id":"e23b985c75be","title":"实现"}],"id":"750183397ab0","title":"BloomFilter (布隆过滤器)"},{"parent":"e08a90c96b17","children":[{"parent":"a3817cda1299","children":[],"id":"74b95271d80f","title":"可持久化的消息队列,支持多播"}],"id":"a3817cda1299","title":"Stream"}],"id":"e08a90c96b17","title":"加分项"}],"id":"1bbcd515493d","title":"数据结构"},{"parent":"68e2d53f78c0","children":[{"parent":"7742814a28a8","children":[{"parent":"a5a4136392f3","children":[{"parent":"dac8a72c8af3","children":[],"id":"2e0bddd4ebac","title":"Redis中大量key同一时间失效, 导致大量请求落库
"}],"id":"dac8a72c8af3","title":"概念"},{"parent":"a5a4136392f3","children":[{"parent":"4f3f99b22654","children":[{"parent":"cae81e94657c","children":[],"id":"f458c0739724","title":"加随机过期时间, 避免大量key同时失效"},{"parent":"cae81e94657c","children":[],"id":"daaa9f606c2b","title":"设置热点数据永不过期
"},{"parent":"cae81e94657c","children":[],"id":"1d88c6e21c3c","title":"如果Redis是集群部署, 将热点数据均匀分布在不同的Redis库中也能避免全部失效的问题"}],"id":"cae81e94657c","title":"预防方案"},{"parent":"4f3f99b22654","children":[{"parent":"c3bea9f91a7e","children":[],"id":"a7313b4d8479","title":"设置本地缓存(ehcache)+限流(hystrix),尽量避免请求过多打入数据库导致数据库宕机
"}],"id":"c3bea9f91a7e","title":"万一发生"},{"parent":"4f3f99b22654","children":[{"parent":"88f98afe7a1c","children":[],"id":"921be9f40b92","title":"redis持久化,重启后自动从磁盘上加载数据,快速恢复缓存数据
"}],"id":"88f98afe7a1c","title":"挂掉以后"}],"id":"4f3f99b22654","title":"解决方案"}],"id":"a5a4136392f3","title":"缓存雪崩"},{"parent":"7742814a28a8","children":[{"parent":"16f48041dfe8","children":[{"parent":"18dad091e32b","children":[],"id":"d4a29ef74f33","title":"缓存和数据库中都没有的数据,而用户不断发起请求, 导致数据库压力过大,严重会击垮数据库
"}],"id":"18dad091e32b","title":"概念"},{"parent":"16f48041dfe8","children":[{"parent":"c83b9f04cec3","children":[{"parent":"f1ca0b7df56c","children":[],"id":"06abfdcea127","title":"接口层增加校验,比如用户鉴权校验,参数做校验,存在不合法的参数直接做短路操作"},{"parent":"f1ca0b7df56c","children":[{"parent":"0a8f16c78524","children":[],"id":"77c829f772d4","title":"不存在则不请求"}],"id":"0a8f16c78524","title":"布隆过滤器"}],"id":"f1ca0b7df56c","title":"过滤方式"},{"parent":"c83b9f04cec3","children":[{"parent":"e9827ebf2fbc","children":[],"id":"f58a9e45bbfb","title":"将对应Key的Value对写为null、或其他提示信息,缓存有效时间可以设置短点,如30秒"}],"id":"e9827ebf2fbc","title":"临时返回"}],"id":"c83b9f04cec3","title":"解决方案"}],"id":"16f48041dfe8","title":"缓存穿透"},{"parent":"7742814a28a8","children":[{"parent":"89e2121fac66","children":[{"parent":"72782b925676","children":[],"id":"ccdc7563e860","title":"一个非常热点的Key,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个Key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库
"}],"id":"72782b925676","title":"概念"},{"parent":"89e2121fac66","children":[{"parent":"f2b90513c9c0","children":[],"id":"48a839f3015b","title":"互斥锁"},{"parent":"f2b90513c9c0","children":[],"id":"217261d1bab5","title":"设置热点数据永不过期"}],"id":"f2b90513c9c0","title":"解决方案"}],"id":"89e2121fac66","title":"缓存击穿"},{"parent":"7742814a28a8","children":[{"parent":"796744a8869c","children":[{"parent":"9cb88abbc2df","children":[],"id":"d4df0f21db8b","title":"数据库与缓存内数据不一致问题"}],"id":"9cb88abbc2df","title":"定义"},{"parent":"796744a8869c","children":[{"parent":"cd7299545586","children":[{"parent":"2a161277de43","children":[],"id":"f7e64d411a34","title":"保持最终一致性, 当缓存中没有时会从数据库读取"}],"id":"2a161277de43","title":"设置过期时间"},{"parent":"cd7299545586","children":[{"parent":"787b437c7b36","children":[{"parent":"6a186a44f666","children":[],"id":"71f5b508690c","title":"第一步成功(操作数据库),第二步失败(删除缓存),会导致数据库里是新数据,而缓存里是旧数据"},{"parent":"6a186a44f666","children":[],"id":"26959b0b8788","title":"如果第一步(操作数据库)就失败了,直接返回错误(Exception),不会出现数据不一致
"},{"parent":"6a186a44f666","children":[{"parent":"2daec7e7e0d5","children":[{"parent":"cc61025444c8","children":[],"id":"27c9e98de34b","title":"不一致,但出现概率很低"}],"id":"cc61025444c8","title":"
"}],"id":"2daec7e7e0d5","title":"并发场景"}],"id":"6a186a44f666","title":"原子性被破坏情景"},{"parent":"787b437c7b36","children":[{"parent":"a9947ca1b3c6","children":[],"id":"221e14e48d66","title":"将需要删除的key发送到消息队列中
"},{"parent":"a9947ca1b3c6","children":[],"id":"d340f9c73068","title":"自己消费消息,获得需要删除的key
"},{"parent":"a9947ca1b3c6","children":[],"id":"cdd19d4a6cd3","title":"不断重试删除操作,直到成功
"}],"id":"a9947ca1b3c6","title":"删除缓存失败的解决思路"},{"parent":"787b437c7b36","children":[{"parent":"7b07db7a011b","children":[],"id":"51870fc09c5a","title":"高并发下表现优异,在原子性被破坏时表现不如意"}],"id":"7b07db7a011b","title":"结论"}],"id":"787b437c7b36","title":"先更新数据库,再删除缓存"},{"parent":"cd7299545586","children":[{"parent":"99a36d602e49","children":[{"parent":"42e69abbccbe","children":[],"id":"4d13edae29bf","title":"第一步成功(删除缓存),第二步失败(更新数据库),数据库和缓存的数据还是一致的
"},{"parent":"42e69abbccbe","children":[],"id":"362019fddab4","title":"如果第一步(删除缓存)就失败了,我们可以直接返回错误(Exception),数据库和缓存的数据还是一致的"},{"parent":"42e69abbccbe","children":[{"parent":"2217b4dc2182","children":[{"parent":"a9df8552a646","children":[],"id":"9d945a5b687c","title":"不一致"}],"id":"a9df8552a646","title":"
"}],"id":"bb57d06a2d89","title":"并发下解决数据库与缓存不一致的思路"},{"parent":"99a36d602e49","children":[{"parent":"db6def4c48a6","children":[],"id":"8def4023ab41","title":"高并发下表现不如意,在原子性被破坏时表现优异"}],"id":"db6def4c48a6","title":"结论"}],"id":"99a36d602e49","title":"先删除缓存,再更新数据库
"},{"parent":"cd7299545586","children":[{"parent":"f9b9c73e9e93","children":[{"parent":"f55f8ee1671a","children":[],"id":"626ca445c252","title":"先删除缓存
"},{"parent":"f55f8ee1671a","children":[],"id":"315c5d4f0763","title":"再写数据库"},{"parent":"f55f8ee1671a","children":[{"parent":"23aabe812e01","children":[],"id":"fae527875f52","title":"延时时间要大于数据库一次写操作的时间
"},{"parent":"23aabe812e01","children":[],"id":"774f81a5a8a0","title":"需要考虑Redis和数据库的主从同步时间
"}],"id":"23aabe812e01","title":"休眠一段时间"},{"parent":"f55f8ee1671a","children":[],"id":"10db51291f20","title":"再次删除缓存"}],"id":"f55f8ee1671a","title":"先删除缓存,再更新数据库"}],"id":"f9b9c73e9e93","title":"延时双删
"}],"id":"cd7299545586","title":"解决方案"}],"id":"796744a8869c","title":"双写一致性"},{"parent":"7742814a28a8","children":[{"parent":"13012e650d03","children":[{"parent":"66c624a52b7f","children":[{"parent":"3f21b7a753e0","children":[{"parent":"07452410b695","children":[],"id":"f1badcd09c76","title":"可重入锁"},{"parent":"07452410b695","children":[],"id":"e220542f12fa","title":"乐观锁
"},{"parent":"07452410b695","children":[],"id":"bd7cd43665fd","title":"公平锁"},{"parent":"07452410b695","children":[],"id":"28b6c9db34d6","title":"读写锁"},{"parent":"07452410b695","children":[],"id":"0f0046ee2fb4","title":"Redlock"},{"parent":"07452410b695","children":[],"id":"e3e5074fe0ee","title":"BloomFilter (布隆过滤器)"}],"id":"07452410b695","title":"功能概括"}],"id":"3f21b7a753e0","title":"Redisson"},{"parent":"66c624a52b7f","children":[{"parent":"c34fec094423","children":[{"parent":"d2c674dedd38","children":[],"id":"2b3737289a9b","title":"setnx key 不存在,才会设置它的值,否则什么也不做
"}],"id":"d2c674dedd38","title":"加锁"},{"parent":"c34fec094423","children":[{"parent":"5c1eb865ad35","children":[],"id":"8132cd2aac6c","title":"expire 设置过期时间
"}],"id":"5c1eb865ad35","title":"避免死锁"},{"parent":"c34fec094423","children":[{"parent":"6c746237d083","children":[],"id":"4cd136dcf59a","title":"Redis 2.6.12扩展了 set 命令
"}],"id":"6c746237d083","title":"保证setnx与expire的原子性
"}],"id":"c34fec094423","title":"操作"},{"parent":"66c624a52b7f","children":[{"parent":"3b3a67a4f68f","children":[{"parent":"945ee50567d1","children":[{"parent":"dfad1fb29323","children":[{"parent":"750122fd9d6d","children":[],"id":"2fce14e8226c","title":"加锁时,先设置一个过期时间,然后我们开启一个守护线程,定时去检测这个锁的失效时间,如果锁快要过期了,操作共享资源还未完成,那么就自动对锁进行续期,重新设置过期时间"},{"parent":"750122fd9d6d","children":[],"id":"c000eca69ea1","title":"Redisson的看门狗"}],"id":"750122fd9d6d","title":"评估操作共享资源的时间不准确"}],"id":"dfad1fb29323","title":"客户端 1 操作共享资源耗时太久,导致锁被自动释放,之后被客户端 2 持有"}],"id":"945ee50567d1","title":"锁过期"},{"parent":"3b3a67a4f68f","children":[{"parent":"bf25f0444016","children":[{"parent":"bbb2d7133150","children":[{"parent":"ea7ea3f77745","children":[{"parent":"fc68dca74343","children":[],"id":"6310889577fc","title":"UUID"},{"parent":"fc68dca74343","children":[],"id":"7462c19e34f5","title":"自己的线程 ID"}],"id":"fc68dca74343","title":"添加唯一标识"},{"parent":"ea7ea3f77745","children":[{"parent":"bb6006e00c6e","children":[{"parent":"6b33de287b91","children":[],"id":"37d6c65470fd","title":"Redis 处理每一个请求是单线程执行的,在执行一个 Lua 脚本时,其它请求必须等待"}],"id":"6b33de287b91","title":"Lua 脚本"}],"id":"bb6006e00c6e","title":"原子性"},{"parent":"ea7ea3f77745","children":[{"parent":"bbadb586bfed","children":[],"id":"59c6c1ed4a41","title":"唯一标识加锁"},{"parent":"bbadb586bfed","children":[],"id":"80b475a0dbea","title":"操作共享资源"},{"parent":"bbadb586bfed","children":[],"id":"b2b7aee63272","title":"释放锁:Lua 脚本,先 GET 判断锁是否归属自己,再 DEL 释放锁"}],"id":"bbadb586bfed","title":"严谨的流程"}],"id":"ea7ea3f77745","title":"没有检查这把锁是否归自己持有"}],"id":"bbb2d7133150","title":"客户端 1 操作共享资源过程中GC或因其他原因超时释放, 导致释放了客户端 2 的锁
"}],"id":"bf25f0444016","title":"释放别人的锁"},{"parent":"3b3a67a4f68f","children":[{"parent":"b05bbbfca458","children":[{"parent":"1e47c82d5213","children":[],"id":"d41070261ebd","title":"客户端 1 在主库上执行 SET 命令,加锁成功
"},{"parent":"1e47c82d5213","children":[],"id":"ff99a0fb95f0","title":"此时,主库异常宕机,SET 命令还未同步到从库上(主从复制是异步的)"},{"parent":"1e47c82d5213","children":[],"id":"b585e9c1979d","title":"从库被哨兵提升为新主库,这个锁在新的主库上,丢失了"}],"id":"1e47c82d5213","title":"场景"},{"parent":"b05bbbfca458","children":[{"parent":"6d09d47be5d2","children":[{"parent":"4cab76cdd425","children":[{"parent":"2a920be28d4e","children":[],"id":"f784806d22dc","title":"不再需要部署从库和哨兵实例,只部署主库
"},{"parent":"2a920be28d4e","children":[],"id":"5b380f8d976a","title":"但主库要部署多个,官方推荐至少 5 个实例"}],"id":"2a920be28d4e","title":"使用前提"},{"parent":"4cab76cdd425","children":[{"parent":"50ee74e743dd","children":[],"id":"964b265a6b2d","title":"客户端先获取「当前时间戳T1」"},{"parent":"50ee74e743dd","children":[],"id":"314294fbf295","title":"客户端依次向这 5 个 Redis 实例发起加锁请求(用前面讲到的 SET 命令),且每个请求会设置超时时间(毫秒级,要远小于锁的有效时间),如果某一个实例加锁失败(包括网络超时、锁被其它人持有等各种异常情况),就立即向下一个 Redis 实例申请加锁"},{"parent":"50ee74e743dd","children":[],"id":"ca66b200ce03","title":"如果客户端从 >=3 个(大多数)以上 Redis 实例加锁成功,则再次获取「当前时间戳T2」,如果 T2 - T1 < 锁的过期时间,此时,认为客户端加锁成功,否则认为加锁失败"},{"parent":"50ee74e743dd","children":[],"id":"6f679cab274f","title":"加锁成功,去操作共享资源"},{"parent":"50ee74e743dd","children":[],"id":"e71de8c8d3b3","title":"加锁失败,向「全部节点」发起释放锁请求( Lua 脚本)"}],"id":"50ee74e743dd","title":"使用流程"},{"parent":"4cab76cdd425","children":[{"parent":"c8b84a886178","children":[],"id":"0dca2da045c0","title":"网络延迟"},{"parent":"c8b84a886178","children":[],"id":"0794df0823fa","title":"进程暂停(GC)"},{"parent":"c8b84a886178","children":[],"id":"5485ba1922fd","title":"时钟漂移"}],"id":"c8b84a886178","title":"请考虑好分布式系统的NPC问题"}],"id":"4cab76cdd425","title":"Redlock"}],"id":"6d09d47be5d2","title":"解决方案"}],"id":"b05bbbfca458","title":"主从发生切换分布锁安全问题
"}],"id":"3b3a67a4f68f","title":"问题"}],"id":"66c624a52b7f","title":"分布式锁"}],"id":"13012e650d03","title":"并发竞争"},{"parent":"7742814a28a8","children":[{"parent":"b36a30a83fbc","children":[],"id":"65abd363741b","title":"bigkey命令 找到干掉"},{"parent":"b36a30a83fbc","children":[],"id":"e9ff6a38dec0","title":"Redis 4.0引入了memory usage命令和lazyfree机制"}],"id":"b36a30a83fbc","title":"大Key"},{"parent":"7742814a28a8","children":[{"parent":"c7346bf92b6a","children":[],"id":"e74b5d1c63a1","title":"设置缓存时间不失效"},{"parent":"c7346bf92b6a","children":[],"id":"69508638ffc6","title":"多级缓存"},{"parent":"c7346bf92b6a","children":[],"id":"bdc6ecf6b73c","title":"布隆过滤器"},{"parent":"c7346bf92b6a","children":[],"id":"30abdb86e98d","title":"读写分离"}],"id":"c7346bf92b6a","title":"热点key"},{"parent":"7742814a28a8","children":[{"parent":"29f0b4fd4759","children":[{"parent":"7ce1965bb4b7","children":[{"parent":"5d0a0294f45d","children":[],"id":"3367ed8b7920","title":"没有offset、limit参数,会一次查出全部"},{"parent":"5d0a0294f45d","children":[],"id":"47780bc0614e","title":"keys算法是遍历算法,复杂度为O(n),因为Redis单线程的特性,会顺序执行指令,其他指令必须等待keys执行结束才可以执行"}],"id":"5d0a0294f45d","title":"缺点"}],"id":"7ce1965bb4b7","title":"keys"},{"parent":"29f0b4fd4759","children":[{"parent":"b7569f19ae71","children":[{"parent":"c9d9d6881a2c","children":[],"id":"b5bc3f2b03ab","title":"同样可以正则表达式匹配,limit可控条数,游标分布进行不会阻塞"}],"id":"c9d9d6881a2c","title":"优点"},{"parent":"b7569f19ae71","children":[{"parent":"477b5ab0ad6c","children":[],"id":"bab36d1d140e","title":"返回结果会重复"},{"parent":"477b5ab0ad6c","children":[],"id":"8f7198524c90","title":"如果遍历过程出现数据修改,不能确定改动后的数据能不能遍历到"}],"id":"477b5ab0ad6c","title":"缺点"}],"id":"b7569f19ae71","title":"scan"}],"id":"29f0b4fd4759","title":"搜索海量key"}],"id":"7742814a28a8","title":"常见问题"},{"parent":"68e2d53f78c0","children":[{"parent":"3fd6a16f4f94","children":[{"parent":"10c0fbbaf18c","children":[],"id":"3ff27aab32ff","title":"zset滑动窗口实现"},{"parent":"10c0fbbaf18c","children":[],"id":"c2637409763a","title":"在量大时会消耗很多存储空间"}],"id":"10c0fbbaf18c","title":"简单限流"},{"parent":"3fd6a16f4f94","children":[{"parent":"f5de183ac704","children":[{"parent":"d5400b7edf80","children":[],"id":"b4fb7a7e554e","title":"漏斗Funnel、漏斗算法实现makeSpace"},{"parent":"d5400b7edf80","children":[],"id":"76106014ff32","title":"在每次灌水前调用makeSpace,给漏斗腾出空间,腾出的空间取决于水流的速度
"}],"id":"d5400b7edf80","title":"单体实现"},{"parent":"f5de183ac704","children":[{"parent":"d62e25e3e13c","children":[],"id":"b04c03869678","title":"将漏斗对象按字段存储到hash结构中,灌水时将hash结构字段去出进行逻辑运算后,再将新值重填到hash结构中,完成频度检测"},{"parent":"d62e25e3e13c","children":[{"parent":"6d2dccb3f68e","children":[],"id":"c6c702826f75","title":"加锁处理,如果失败重试会导致性能下降"},{"parent":"6d2dccb3f68e","children":[],"id":"a030aea687cd","title":"Redis4.0提供的Redis-Cell解决此问题"}],"id":"6d2dccb3f68e","title":"无法保证这三个操作的原子性"}],"id":"d62e25e3e13c","title":"分布式实现"}],"id":"f5de183ac704","title":"漏斗限流"}],"id":"3fd6a16f4f94","title":"限流操作"},{"parent":"68e2d53f78c0","children":[{"parent":"ada2330a2425","children":[{"parent":"668b1454d74f","children":[{"parent":"4d48d557b5e0","children":[],"id":"7fbadfbbcfcc","title":"5分钟一次"},{"parent":"4d48d557b5e0","children":[],"id":"d00795ceede8","title":"冷备"},{"parent":"4d48d557b5e0","children":[],"id":"f8401d16c024","title":"恢复的时候比较快"},{"parent":"4d48d557b5e0","children":[],"id":"3bbfd52a1687","title":"快照文件生成时间久,消耗cpu"},{"parent":"4d48d557b5e0","children":[],"id":"ccc6b9dcf9fb","title":"采用COW机制来实现持久化,fork进程处理"}],"id":"4d48d557b5e0","title":"RDB"},{"parent":"668b1454d74f","children":[{"parent":"9e12decdb68e","children":[],"id":"1d0805523949","title":"appendOnly"},{"parent":"9e12decdb68e","children":[],"id":"89f5517d6396","title":"数据齐全"},{"parent":"9e12decdb68e","children":[],"id":"7491a69d002c","title":"只对内存进行修改的指令记录,进行恢复时相当于‘重放’所有执行指令"},{"parent":"9e12decdb68e","children":[{"parent":"91d9756055c8","children":[],"id":"5d34419b1718","title":"定期做AOF瘦身"}],"id":"91d9756055c8","title":"回复慢文件大"}],"id":"9e12decdb68e","title":"AOF"},{"parent":"668b1454d74f","children":[{"parent":"0aa38f4c9668","children":[],"id":"7f7ef8d8748a","title":"同时将RDB与AOF存放在一起,AOF只存储自持久化开始到持久化结束期间的AOF日志"},{"parent":"0aa38f4c9668","children":[],"id":"a52194b87860","title":"在重启时先加载RDB的内容,然后重放AOF日志,提升效率"}],"id":"0aa38f4c9668","title":"混合持久化"}],"id":"668b1454d74f","title":"持久化"},{"parent":"ada2330a2425","children":[{"parent":"58b8b6e3fee6","children":[],"id":"b7cb33dbb795","title":"主从数据采取异步同步"},{"parent":"58b8b6e3fee6","children":[],"id":"f596df0cfe11","title":"保证最终一致性,从节点会努力追赶主节点,保证最终情况下从节点与主节点一致"},{"parent":"58b8b6e3fee6","children":[{"parent":"c9582a62c7b9","children":[{"parent":"09c563a5c389","children":[],"id":"b12a602a099d","title":"Redis将对自己状态产生修改影响的指令记录在本地内存buffer中,然后异步将buffer中的指令同步到从节点"},{"parent":"09c563a5c389","children":[],"id":"6985e3bc5bf5","title":"复制内存buffer是定长的环形数组,如果数组内容满了,就会从头开始覆盖"},{"parent":"09c563a5c389","children":[],"id":"e0065aa5e0d6","title":"在网络不好的情况下,可能导致无法通过指令流来同步"}],"id":"09c563a5c389","title":"增量同步"},{"parent":"c9582a62c7b9","children":[{"parent":"7e28cef0ac53","children":[],"id":"923021194d4e","title":"快照同步十分耗费资源"},{"parent":"7e28cef0ac53","children":[],"id":"b6a46fbc2eea","title":"首先在主节点进行bgsave,将当前内存快照到磁盘文件,然后再将快照传送到从节点"},{"parent":"7e28cef0ac53","children":[],"id":"19da982e6ab9","title":"快照文件接受完毕后,先将当前内存数据清空,然后执行全量加载,加载后通知主节点进行增量同步"},{"parent":"7e28cef0ac53","children":[],"id":"4954c29c2a50","title":"在此期间buffer依旧向前移动,如果快照同步时间过长或复制buffer太小,就会导致快照同步后依旧无法增量同步,导致死循环"},{"parent":"7e28cef0ac53","children":[],"id":"d4a0e45138a3","title":"所以务必要配置合适的复制buffer大小,避免快照复制死循环"}],"id":"7e28cef0ac53","title":"快照同步"}],"id":"c9582a62c7b9","title":"同步方式"}],"id":"58b8b6e3fee6","title":"数据同步机制"},{"parent":"ada2330a2425","children":[{"parent":"14d4ebf6fb81","children":[],"id":"6d287264815f","title":"哨兵负责监控主从节点健康,当主节点挂掉时,自动选择最优节点成为主节点,原主节点恢复后会变为从节点"},{"parent":"14d4ebf6fb81","children":[{"parent":"22cf1ee3be06","children":[],"id":"0ec54367a481","title":"Redis采用异步复制,所以当主节点挂掉,从节点可能没有收到全部的同步消息,产生消息丢失"},{"parent":"22cf1ee3be06","children":[{"parent":"fea18cac6d2a","children":[],"id":"bb55da53f849","title":"表示主节点必须至少有一个从节点在进行正常复制,否则就停止对外写服务"}],"id":"fea18cac6d2a","title":"min-slaves-to-write 1"},{"parent":"22cf1ee3be06","children":[{"parent":"9d3ebc781908","children":[],"id":"85f361fff22e","title":"表示如果10s内没有收到从节点的反馈,就意味着同步不正常"}],"id":"9d3ebc781908","title":"min-slaves-max-lag 10"}],"id":"22cf1ee3be06","title":"消息丢失"}],"id":"14d4ebf6fb81","title":"哨兵"},{"parent":"ada2330a2425","children":[],"id":"6a204b455e04","title":"集群"}],"id":"ada2330a2425","title":"高可用"},{"parent":"68e2d53f78c0","children":[{"parent":"0bbbfddb1bdf","children":[],"id":"1c62574854ce","title":"合并读、写命令,减少网络开销"}],"id":"0bbbfddb1bdf","title":"管道"},{"parent":"68e2d53f78c0","children":[{"parent":"550cc736d1a3","children":[{"parent":"27b517127004","children":[],"id":"697a6405075e","title":"创建一个定时器,当key设置有过期时间,且到达过期时间,由定时器任务立即删除"},{"parent":"27b517127004","children":[],"id":"fbf01411fe0d","title":"可以快速释放掉不必要的内存占用 , 但是CPU压力很大
"}],"id":"27b517127004","title":"定时删除"},{"parent":"550cc736d1a3","children":[{"parent":"5ad26b89a5fb","children":[],"id":"1954cef851e8","title":"在客户端访问key的时候,进行过期检查,如果过期了立即删除"}],"id":"5ad26b89a5fb","title":"惰性策略(惰性删除)"},{"parent":"550cc736d1a3","children":[{"parent":"1494d4d816a6","children":[],"id":"80ed3dbfa838","title":"Redis会将设置了过期时间的key放入一个独立的字典中,定期遍历(默认每秒进行10次扫描)来删除到底的key"},{"parent":"1494d4d816a6","children":[{"parent":"3c1730cc5539","children":[],"id":"418e5db9ebc8","title":"定期遍历不会遍历所有的key,而是采取贪心策略"},{"parent":"3c1730cc5539","children":[],"id":"c03a6231598c","title":"从过期字典中随机选出20个key"},{"parent":"3c1730cc5539","children":[],"id":"d50e70020d97","title":"删除这20个key中已经过期的key"},{"parent":"3c1730cc5539","children":[],"id":"2de36c1ef778","title":"如果过期的key的比例超过1/4,则重复步骤"},{"parent":"3c1730cc5539","children":[],"id":"c646a5a92ec1","title":"为保证不会循环过度,扫描时间上线默认不会超过25ms"}],"id":"3c1730cc5539","title":"贪心策略"}],"id":"1494d4d816a6","title":"定时扫描(定时删除)"},{"parent":"550cc736d1a3","children":[{"parent":"15e0714a86f6","children":[],"id":"0d3ad6052dae","title":"从节点不会进行过期扫描,对过期的处理时被动的,主节点在key到期时,会在AOF里增加一条del指令,同步到从节点,从节点通过指令删除key"}],"id":"15e0714a86f6","title":"从节点过期策略"}],"id":"550cc736d1a3","title":"过期策略"},{"parent":"68e2d53f78c0","children":[{"parent":"1c19ee20a68c","children":[{"parent":"35311e5d526f","children":[],"id":"6ff15aa765c3","title":"采用key/value+链表实现,当字典元素被访问时移动到表头,当空间满的时候踢掉链表尾部的元素"},{"parent":"35311e5d526f","children":[{"parent":"9b7510be7f91","children":[],"id":"dbcf0b911044","title":"Redis的LRU采用一种近似LRU的算法,为每个key增加一个额外字段长度为24bit,为最后一次访问的时间戳"},{"parent":"9b7510be7f91","children":[],"id":"3f37f69602f0","title":"采取懒惰方式处理,当执行写入操作时如果超出最大内存就执行一次LRU淘汰算法,随机采样5(数量可设置)个key,淘汰掉最旧的key,如果淘汰后依旧超出最大内存则继续淘汰"}],"id":"9b7510be7f91","title":"Redis的LRU"}],"id":"35311e5d526f","title":"LRU"}],"id":"1c19ee20a68c","title":"淘汰机制"},{"parent":"68e2d53f78c0","children":[{"parent":"ef4cb7bfd92a","children":[],"id":"77a7955156bf","title":"在调用套接字方法的时候默认是阻塞的,比如,read方法需要读取规定字节后返回,如果没有线程就会卡在那里,直到新数据来或者链接关闭
"},{"parent":"ef4cb7bfd92a","children":[],"id":"f329207efe37","title":"write方法一般不会阻塞,除非内核为套接字分配的写缓冲区已经满了"},{"parent":"ef4cb7bfd92a","children":[],"id":"9bf3cb96e12d","title":"非阻塞的IO提供了一个选项Non_Blocking,打开时读写都不会阻塞 读多少写多少取决于内核的套接字字节分配"},{"parent":"ef4cb7bfd92a","children":[],"id":"9235ef78e11c","title":"非阻塞IO也有问题线程要读数据读了一点就返回了线程什么时候知道继续读?写一样"},{"parent":"ef4cb7bfd92a","children":[],"id":"eb7e9d548e40","title":"一般都是select解决但是性能低现在都是epoll"}],"id":"ef4cb7bfd92a","title":"多路IO复用"}],"collapsed":true,"id":"68e2d53f78c0","title":"Redis"},{"parent":"root","lineStyle":{"randomLineColor":"#13A3ED"},"children":[{"parent":"27d73b325f5b","children":[{"parent":"c126505c846f","children":[{"parent":"3e6fdbd260dc","children":[{"parent":"e3bbe630c77b","children":[],"id":"a52aafb21566","title":"所有节点拥有数据的最新版本"}],"id":"e3bbe630c77b","title":"数据一致性(consistency)"},{"parent":"3e6fdbd260dc","children":[{"parent":"16f0be57497c","children":[],"id":"13e807d7a20d","title":"数据具备高可用性"}],"id":"16f0be57497c","title":"可用性(availability)"},{"parent":"3e6fdbd260dc","children":[{"parent":"7394b794bc3c","children":[],"id":"6f3f4c1e3e1f","title":"容忍网络出现分区,分区之间网络不可达"}],"id":"7394b794bc3c","title":"分区容错性(partition-tolerance)"}],"id":"3e6fdbd260dc","title":"概念"},{"parent":"c126505c846f","children":[{"parent":"ea8b927aa992","children":[],"id":"ea6785f04b60","title":"在容忍网络分区的条件下,"强一致性"和"极致可用性"无法同时达到"}],"id":"ea8b927aa992","title":"定义"}],"id":"c126505c846f","title":"CAP理论"},{"parent":"27d73b325f5b","children":[{"parent":"d63e14aab5d1","children":[{"parent":"94404e1c447b","children":[],"id":"dd9e2dc4af2a","title":"用来维护各个服务的注册信息 , 各个服务通过注册清单的服务名获取服务具体位置(IP地址会变,服务名一般不会变)
"}],"id":"94404e1c447b","title":"服务治理:Eureka"},{"parent":"d63e14aab5d1","children":[{"parent":"885fa0bda765","children":[],"id":"f1bd36f604b7","title":"客户端可以从Eureka Server中得到一份服务清单,在发送请求时通过负载均衡算法,在多个服务器之间选择一个进行访问"}],"id":"885fa0bda765","title":"客户端负载均衡:Ribbon"},{"parent":"d63e14aab5d1","children":[{"parent":"84ec94898586","children":[],"id":"320c4c3f6ad0","title":"在远程服务出现延迟, 宕机情况时提供断路器、线程隔离等功能"}],"id":"84ec94898586","title":"服务容错保护:Hystrix"},{"parent":"d63e14aab5d1","children":[{"parent":"3f725be6c509","children":[],"id":"5d6df34cab52","title":"整合了Ribbon与Hystrix"}],"id":"3f725be6c509","title":"声明式服务调用:Feign"},{"parent":"d63e14aab5d1","children":[{"parent":"b19ae03b802a","children":[],"id":"1cee4018ba68","title":"解决路由规则与服务实例的维护间题, 签名校验、 登录校验冗余问题
"}],"id":"b19ae03b802a","title":"API网关服务:Zuul"},{"parent":"d63e14aab5d1","children":[{"parent":"261553fe2960","children":[{"parent":"510230e16d5b","children":[],"id":"605eb3a4eb2a","title":"通过接口获取数据、并依据此数据初始化自己的应用"}],"id":"510230e16d5b","title":"Client
"},{"parent":"261553fe2960","children":[{"parent":"f97a17502384","children":[],"id":"f0fc3067f1d7","title":"提供配置文件的存储、以接口的形式将配置文件的内容提供出去"}],"id":"f97a17502384","title":"Server"}],"id":"261553fe2960","title":"分布式配置中心:Config"}],"id":"d63e14aab5d1","title":"基础功能"}],"collapsed":true,"id":"27d73b325f5b","title":"Spring Cloud"},{"parent":"root","lineStyle":{"randomLineColor":"#A04AFB"},"children":[],"id":"bc354f9b6903","title":"Zookeeper"},{"parent":"root","lineStyle":{"randomLineColor":"#74C11F"},"children":[],"id":"96167bd3313f","title":"Dubbo"},{"parent":"root","lineStyle":{"randomLineColor":"#F4325C"},"children":[{"parent":"2967bbb0ce6c","children":[{"parent":"12f64511f568","children":[{"parent":"75e771d94bbf","children":[{"parent":"53caf8da86e2","children":[],"id":"696233005cce","title":"NameServer是几乎无状态的, 可以横向扩展, 节点之间相互无通信, 可以通过部署多态机器来标记自己是一个伪集群"},{"parent":"53caf8da86e2","children":[],"id":"20cf4d49dd61","title":"NameServer的压力不会太大, 主要开销在维持心跳和提供Topic-Broker的关系数据"},{"parent":"53caf8da86e2","children":[],"id":"c96708a3cb62","title":"Broker向NameServer发送心跳时, 会携带上当前自己所负责的所有Topic信息(万级别), 若Topic个数很多会导致一次心跳中,就Topic的数据就几十M, 网络情况差的情况下, 网络传输失败, 心跳失败, 导致NameServer误认为Broker心跳失败"}],"id":"53caf8da86e2","title":"主要负责对于源数据的管理,包括了对于Topic和路由信息的管理"}],"id":"75e771d94bbf","title":"NameServer"},{"parent":"12f64511f568","children":[{"parent":"daad2e0ee47a","children":[{"parent":"a3a4b2fa4290","children":[],"id":"a876bb50d0bb","title":"Broker是具体提供业务的服务器, 单个Broker节点与所有NameServer节点保持长连接及心跳, 并会定时将Topic信息注册到NameServer"},{"parent":"a3a4b2fa4290","children":[],"id":"888065bfed04","title":"底层通信和连接基于Netty实现"},{"parent":"a3a4b2fa4290","children":[],"id":"6ff21d8f55f8","title":"Broker负责消息存储, 以Topic为维度支持轻量级队列, 单机可以支撑上万队列规模, 支持消息推拉模型"}],"id":"a3a4b2fa4290","title":"消息中转角色,负责存储消息,转发消息"}],"id":"daad2e0ee47a","title":"Broker"},{"parent":"12f64511f568","children":[{"parent":"5c20008f41b6","children":[{"parent":"cfa99e651913","children":[],"id":"ecf9bb3145fc","title":"同步发送: 发送者向MQ执行发送消息API,同步等待,直到消息服务器返回发送结果。一般用于重要通知消息,例如重要通知邮件、营销短信
"},{"parent":"cfa99e651913","children":[],"id":"8f1cefc4cec3","title":"异步发送: 发送这向MQ执行发送消息API,指定消息发送成功后的回调函数,然后调用消息发送API后,立即返回.消息发送者线程不阻塞,直到运行结束,消息发送成功或失败的回调任务在一个新线程执行,一般用于可能链路耗时较长而对响应时间敏感的业务场景,例如用户视频上传后通知启动转码服务"},{"parent":"cfa99e651913","children":[],"id":"93201d04d89e","title":"单向发送: 发送者MQ执行发送消息API时,直接返回,不等待消息服务器的结果,也不注册回调函数,简单的说就是只管发送,不在乎消息是否成功存储在消息服务器上,适用于某些耗时非常短但对可靠性要求并不高的场景,例如日志收集"}],"id":"cfa99e651913","title":"消息生产者,负责产生消息,一般由业务系统负责产生消息"}],"id":"5c20008f41b6","title":"Producer"},{"parent":"12f64511f568","children":[{"parent":"d7f396e0831a","children":[{"parent":"2167651c5963","children":[],"id":"eac97c7046ef","title":"Pull: 拉取型消费,主动从消息服务器拉去信息, 只要批量拉取到消息, 用户应用就会启动消费过程, 所以Pull成为主动消费型"},{"parent":"2167651c5963","children":[],"id":"e1d302c81ee1","title":"Push: 推送型消费者,封装了消息的拉去,消费进度和其他的内部维护工作, 将消息到达时执行回调接口留给用户程序来实现. 所以Push成为被动消费型, 但从实现上看还是从消息服务器中拉取消息, 不同于Pull的时Push首先要注册消费监听器, 当监听器触发后才开始消费消息"}],"id":"2167651c5963","title":"消息消费者,负责消费消息,一般是后台系统负责异步消费"}],"id":"d7f396e0831a","title":"Consumer"}],"id":"12f64511f568","title":"基础组成"},{"parent":"2967bbb0ce6c","children":[{"parent":"604a2b077915","children":[{"parent":"5f5dd32d8097","children":[{"parent":"ee7415aca487","children":[{"parent":"e8d48c3eb98c","children":[],"id":"c36cc866bf9a","title":"配置简单,单个Master宕机或重启维护对应用无影响,在磁盘配置为RAID10时,即使机器宕机不可恢复情况下,由于RAID10磁盘非常可靠,消息也不会丢失(异步刷盘丢失少量消息,同步刷盘一条不丢)。性能最高"}],"id":"e8d48c3eb98c","title":"优点"},{"parent":"ee7415aca487","children":[{"parent":"043f2943a836","children":[],"id":"df0bc145fab6","title":"单台机器宕机期间,这台机器上未被消费的消息在机器恢复之前不可订阅,消息实时性会受到影响"}],"id":"043f2943a836","title":"缺点"}],"id":"ee7415aca487","title":"一个集群无Slave,全是Master"}],"id":"5f5dd32d8097","title":"多Master"},{"parent":"604a2b077915","children":[{"parent":"1257c8b9aac5","children":[{"parent":"ea64577686e3","children":[{"parent":"90097b5c030f","children":[],"id":"e53091b80fab","title":"即使磁盘损坏,消息丢失的非常少,且消息实时性不会受影响,因为Master 宕机后,消费者仍然可以从Slave消费,此过程对应用透明。不需要人工干预。性能同多 Master 模式几乎一样"}],"id":"90097b5c030f","title":"优点"},{"parent":"ea64577686e3","children":[{"parent":"4ef440c8e995","children":[],"id":"27e509d14ece","title":"Master宕机,磁盘损坏情况,会丢失少量消息"}],"id":"4ef440c8e995","title":"缺点"}],"id":"ea64577686e3","title":"每个Master配置一个Slave,有多对Master-Slave,HA采用异步复制方式,主备有短暂消息延迟,毫秒级"}],"id":"1257c8b9aac5","title":"多Master, 多Salve, 异步复制"},{"parent":"604a2b077915","children":[{"parent":"4d53b0661b8f","children":[{"parent":"e4a1b95dba5b","children":[{"parent":"9f79418a5eed","children":[],"id":"a5fc7ac37b70","title":"数据与服务都无单点,Master宕机情况下,消息无延迟,服务可用性与数据可用性都非常高"}],"id":"9f79418a5eed","title":"优点"},{"parent":"e4a1b95dba5b","children":[{"parent":"6dd53df1911c","children":[],"id":"57d816d31bf1","title":"性能比异步复制模式略低,大约低10%左右,发送单个消息的RT会略高。目前主宕机后,备机不能自动切换为主机,后续会支持自动切换功能"}],"id":"6dd53df1911c","title":"缺点"}],"id":"e4a1b95dba5b","title":"每个Master配置一个Slave,有多对Master-Slave,HA采用同步双写方式,主备都写成功,向应用才返回成功"}],"id":"4d53b0661b8f","title":"多Master, 多Salve, 双写一致"}],"id":"604a2b077915","title":"支持集群模式"},{"parent":"2967bbb0ce6c","children":[{"parent":"43da161a94fa","children":[],"id":"1a296e9626d0","title":"只有发送成功后返回CONSUME_SUCCESS, 消费才是完成的"},{"parent":"43da161a94fa","children":[{"parent":"8fc82e05be66","children":[{"parent":"d99a334f4878","children":[],"id":"40fed29109ad","title":"当确认批次消息消费失败 (RECONSUME_LATER) 时, RocketMQ会把这批消息重发回Broker (此处非原Topic 而是这个消费者组的 RETRY Topic)
"},{"parent":"d99a334f4878","children":[],"id":"ec26b776e2f4","title":"在延迟的某个时间点(默认是10秒,业务可设置)后,再次投递到这个ConsumerGroup"},{"parent":"d99a334f4878","children":[],"id":"c226bf1b7a9e","title":"如果一直这样重复消费都持续失败到一定次数(默认16次),就会投递到死信队列。人工干预解决"}],"id":"d99a334f4878","title":"顺序消息重试"},{"parent":"8fc82e05be66","children":[],"id":"813946fc3144","title":"无序消息重试"}],"id":"8fc82e05be66","title":"消息重试"},{"parent":"43da161a94fa","children":[{"parent":"a38425631022","children":[],"id":"0964ff7a4b1c","title":"RocketMQ 以 Consumer Group (消费者组)+ Queue (队列) 为单位管理消费进度, 通过 Consumer Offset 标记这个这个消费组在这条Queue上的消费进度"},{"parent":"a38425631022","children":[],"id":"76e7f5c236a6","title":"如果已存在的消费组出现了新消费实例的时候,依靠这个组的消费进度,可以判断第一次是从哪里开始拉取的"},{"parent":"a38425631022","children":[],"id":"65266364b4b8","title":"每次消息成功后,本地的消费进度会被更新,然后由定时器定时同步到broker,以此持久化消费进度"},{"parent":"a38425631022","children":[],"id":"ddcbe167cfd1","title":"但每次记录消费进度时,只会将一批消息中最小的offset值更新为消费进度值"}],"id":"a38425631022","title":"ACK机制"},{"parent":"43da161a94fa","children":[{"parent":"ce692c70d0c6","children":[],"id":"8c1e99f1aebf","title":"由于消费进度只记录了一个下标,就可能出现拉取了100条消息如 100 - 200 的消息,后面99条都消费结束了,只有101消费一直没有结束的情况"},{"parent":"ce692c70d0c6","children":[],"id":"88f2e23d3c86","title":"RocketMQ为了保证消息肯定被消费成功,消费进度只能维持在101,直到101也消费结束,本地消费进度才能标记200消费结束"},{"parent":"ce692c70d0c6","children":[],"id":"df1747541718","title":"在这种情况下,如果RocketMQ机器断电,或者被kill, 此处的消费进度就还是101, 当队列重新分配实例时, 从broker获取的消费进度维持在101, 就会出现重复消费的情况
"},{"parent":"ce692c70d0c6","children":[],"id":"3528a1c8bcec","title":"对于这个场景,RocketMQ暂时无能为力,所以业务必须要保证消息消费的幂等性"}],"id":"ce692c70d0c6","title":"重复消费"},{"parent":"43da161a94fa","children":[{"parent":"b6fc9dbb9580","children":[],"id":"939f53dff9c0","title":"RocketMQ支持按照时间回溯消费,时间维度精确到毫秒,可以向前回溯,也可以向后回溯"}],"id":"b6fc9dbb9580","title":"消息回溯"}],"id":"43da161a94fa","title":"消费保证"},{"parent":"2967bbb0ce6c","children":[{"parent":"403b9cd18917","children":[{"parent":"4439dd28bd16","children":[{"parent":"40d9bda89e49","children":[],"id":"07d61c838390","title":"由于 NameServer 节点是无状态的,且各个节点直接的数据是一致的,故存在多个 NameServer 节点的情况下,部分 NameServer 不可用也可以保证 MQ 服务正常运行"}],"id":"40d9bda89e49","title":"NameServer 集群"},{"parent":"4439dd28bd16","children":[{"parent":"5e1a97f2162e","children":[{"parent":"2abd6a7fd911","children":[],"id":"f4b8c1adb5df","title":"由于Slave只负责读,当 Master 不可用,它对应的 Slave 仍能保证消息被正常消费"},{"parent":"2abd6a7fd911","children":[],"id":"8139525d3db2","title":"由于配置多组 Master-Slave 组,其他的 Master-Slave 组也会保证消息的正常发送和消费"}],"id":"2abd6a7fd911","title":"一个 Master 可以配置多个 Slave,同时也支持配置多个 Master-Slave 组"}],"id":"5e1a97f2162e","title":"Broker 主从, 多主从"},{"parent":"4439dd28bd16","children":[{"parent":"f82965d473fb","children":[],"id":"7e71895d91ef","title":"Consumer 的高可用是依赖于 Master-Slave 配置的,由于 Master 能够支持读写消息,Slave 支持读消息,当 Master 不可用或繁忙时, Consumer 会被自动切换到从 Slave 读取(自动切换,无需配置)"}],"id":"f82965d473fb","title":"Consumer 自动切换"},{"parent":"4439dd28bd16","children":[{"parent":"f3c6854c53d6","children":[],"id":"ad3cb7405f89","title":"在创建Topic时, 将Topic的多个 Message Queue 创建在多个 Broker组 上, 这样当一个Broker组的Master不可用后,其他组的Master仍然可用,Producer仍然可以发送消息
"}],"id":"f3c6854c53d6","title":"Producer 连接多个 Broker"}],"id":"4439dd28bd16","title":"集群"},{"parent":"403b9cd18917","children":[{"parent":"a4cb838b16ea","children":[{"parent":"c2592c074d4c","children":[],"id":"07ef479a1045","title":"在返回写成功状态时,消息已经被写入磁盘中。即消息被写入内存的PAGECACHE 中后,立刻通知刷新线程刷盘,等待刷盘完成,才会唤醒等待的线程并返回成功状态, 超时会返回错误
"}],"id":"c2592c074d4c","title":"同步刷盘"},{"parent":"a4cb838b16ea","children":[{"parent":"3d7e8bfce714","children":[],"id":"4fe92f30b6e8","title":"在返回写成功状态时,消息可能只是被写入内存的 PAGECACHE 中。当内存的消息量积累到一定程度时,触发写操作快速写入, 不返回错误"}],"id":"3d7e8bfce714","title":"异步刷盘"}],"id":"a4cb838b16ea","title":"刷盘机制"},{"parent":"403b9cd18917","children":[{"parent":"55e8e026c976","children":[{"parent":"7e5670f14a09","children":[],"id":"8859c3e13bfe","title":"Master 和 Slave 均写成功后才反馈给客户端写成功状态"}],"id":"7e5670f14a09","title":"同步复制"},{"parent":"55e8e026c976","children":[{"parent":"953b201d922e","children":[],"id":"c97878eed758","title":"只要 Master 写成功,就反馈客户端写成功状态"}],"id":"953b201d922e","title":"异步复制"}],"id":"55e8e026c976","title":"消息的主从复制"}],"id":"403b9cd18917","title":"高可用"},{"parent":"2967bbb0ce6c","children":[{"parent":"e56a055b5068","children":[{"parent":"16961909ae98","children":[],"id":"944ff5256f15","title":"RocketMQ提供了MessageQueueSelector队列选择机制"},{"parent":"16961909ae98","children":[],"id":"68d213356c50","title":"顺序发送 顺序消费由 消费者保证"}],"id":"16961909ae98","title":"Hash取模法"}],"id":"e56a055b5068","title":"顺序消费"},{"parent":"2967bbb0ce6c","children":[{"parent":"7ce52753f364","children":[{"parent":"4fb6ee988efc","children":[],"id":"8c2657879e36","title":"使用业务端逻辑保持幂等性"}],"id":"4fb6ee988efc","title":"原则"},{"parent":"7ce52753f364","children":[{"parent":"1bfaf765406c","children":[],"id":"b0239da60ed7","title":"对于同一操作发起的一次请求或者多次请求的结果是一致的"}],"id":"1bfaf765406c","title":"幂等性"},{"parent":"7ce52753f364","children":[{"parent":"56d747f52657","children":[],"id":"e39d27d3a0ab","title":"保证每条消息都有唯一编号(比如唯一流水号),重复消费时主键冲突不再处理消息"}],"id":"56d747f52657","title":"去重策略"}],"id":"7ce52753f364","title":"消息去重"},{"parent":"2967bbb0ce6c","children":[{"parent":"09e95e6eab93","children":[{"parent":"c8a5405fb7c5","children":[],"id":"3570c5920213","title":"暂不能被Consumer消费的消息, 需要 Producer 对消息的二次确认后,Consumer才能去消费它"}],"id":"c8a5405fb7c5","title":"Half Message (半消息)"},{"parent":"09e95e6eab93","children":[{"parent":"332f741948f5","children":[],"id":"be923878148d","title":"A服务先发送个 Half Message 给 Broker 端,消息中携带 B服务"},{"parent":"332f741948f5","children":[],"id":"55ea8b7092e3","title":"当A服务知道 Half Message 发送成功后, 执行本地事务"},{"parent":"332f741948f5","children":[],"id":"4187239edfc5","title":"如果本地事务成功,那么 Producer 像 Broker 服务器发送 Commit , 这样B服务就可以消费该 Message"},{"parent":"332f741948f5","children":[],"id":"08a1fccc842a","title":"如果本地事务失败,那么 Producer 像 Broker 服务器发送 Rollback , 那么就会直接删除上面这条半消息"},{"parent":"332f741948f5","children":[],"id":"4da11302aa7f","title":"如果因为网络等原因迟迟没有返回失败还是成功,那么会执行RocketMQ的回调接口,来进行事务的回查"}],"id":"332f741948f5","title":"流程"},{"parent":"09e95e6eab93","children":[],"id":"a5095a559452","title":"最终一致性"},{"parent":"09e95e6eab93","children":[],"id":"5c502c270ff1","title":"最大努力通知"}],"id":"09e95e6eab93","title":"事务消息"},{"parent":"2967bbb0ce6c","children":[{"parent":"539927f8e2c1","children":[],"id":"88eabed09a58","title":"Producer 和 NameServer 节点建立一个长连接"},{"parent":"539927f8e2c1","children":[],"id":"fc3d758dc575","title":"定期从 NameServer 获取 Topic 信息
"},{"parent":"539927f8e2c1","children":[],"id":"e2e50215339f","title":"并且向 Broker Master 建立链接 发送心跳"},{"parent":"539927f8e2c1","children":[],"id":"2063f1f65200","title":"发送消息给 Broker Master"},{"parent":"539927f8e2c1","children":[],"id":"0d92c5a8e5e8","title":"Consumer 从 Mater 和 Slave 一起订阅消息"}],"id":"539927f8e2c1","title":"一次完整的通信流程"},{"parent":"2967bbb0ce6c","children":[{"parent":"9081c42a0f2a","children":[],"id":"1219a6e079fa","title":"不再被正常消费 "},{"parent":"9081c42a0f2a","children":[],"id":"5e70a2a44651","title":"保存3天"},{"parent":"9081c42a0f2a","children":[],"id":"50aa84db0020","title":"面向消费者组 "},{"parent":"9081c42a0f2a","children":[],"id":"d4a503883c07","title":"控制台 重发 重写消费者 单独消费"}],"id":"9081c42a0f2a","title":"死信队列"},{"parent":"2967bbb0ce6c","children":[{"parent":"cc10915c102e","children":[{"parent":"712c8d74cc5a","children":[],"id":"e8d44e34f882","title":"生产者将消息发送给Rocket MQ的时候,如果出现了网络抖动或者通信异常等问题,消息就有可能会丢失"},{"parent":"712c8d74cc5a","children":[{"parent":"e4ba8bf00b71","children":[],"id":"4d4c85447a76","title":"如果消息还没有完成异步刷盘,RocketMQ中的Broker宕机的话,就会导致消息丢失"},{"parent":"e4ba8bf00b71","children":[],"id":"a16ee1c4706e","title":"如果消息已经被刷入了磁盘中,但是数据没有做任何备份,一旦磁盘损坏,那么消息也会丢失"}],"id":"e4ba8bf00b71","title":"消息需要持久化到磁盘中,这时会有两种情况导致消息丢失"},{"parent":"712c8d74cc5a","children":[],"id":"f521198db453","title":"消费者成功从RocketMQ中获取到了消息,还没有将消息完全消费完的时候,就通知RocketMQ我已经将消息消费了,然后消费者宕机,但是RocketMQ认为消费者已经成功消费了数据,所以数据依旧丢失了"}],"id":"712c8d74cc5a","title":"常见场景"},{"parent":"cc10915c102e","children":[{"parent":"6e0281cde36d","children":[],"id":"d1b9b4c61dab","title":"事务消息"},{"parent":"6e0281cde36d","children":[],"id":"d5c1c1f6fd31","title":"同步刷盘"},{"parent":"6e0281cde36d","children":[],"id":"dd9b94bf2957","title":"主从机构的话,需要Leader将数据同步给Followe"},{"parent":"6e0281cde36d","children":[],"id":"29c1212c50c6","title":"消费时无法异步消费,只能等待消费完成再通知RocketMQ消费完成"}],"id":"6e0281cde36d","title":"确保消息零丢失"},{"parent":"cc10915c102e","children":[],"id":"f6dabcb64d3a","title":"上述方案会使性能和吞吐量大幅下降, 需按场景谨慎使用"}],"id":"cc10915c102e","title":"消息丢失"},{"parent":"2967bbb0ce6c","children":[{"parent":"ce3c57e6ab49","children":[{"parent":"12b15ec01705","children":[{"parent":"c74aa299e8ad","children":[],"id":"24987ee3c4db","title":"在业务允许的情况下, 根据一定的丢弃策略来丢弃消息"},{"parent":"c74aa299e8ad","children":[],"id":"036abd6de052","title":"修复Consumer不消费问题,使其恢复正常消费,根据业务需要看是否要暂停"},{"parent":"c74aa299e8ad","children":[],"id":"81368743808e","title":"停止消费 加机器 加Topic, 编写临时处理分发程序消费
"}],"id":"c74aa299e8ad","title":"丢弃, 扩容"}],"id":"12b15ec01705","title":"解决思想"}],"id":"ce3c57e6ab49","title":"消息堆积"},{"parent":"2967bbb0ce6c","children":[{"parent":"8a5fb1ce1bf4","children":[],"id":"05af140b142a","title":"RocketMQ支持定时消息,但是不支持任意时间精度,支持特定的level,例如定时5s,10s,1m等"}],"id":"8a5fb1ce1bf4","title":"定时消息"},{"parent":"2967bbb0ce6c","children":[{"parent":"4aa9ff9ad75c","children":[{"parent":"954e7ff26b10","children":[],"id":"e4f3f3d220ec","title":"单机吞吐量:十万级"},{"parent":"954e7ff26b10","children":[],"id":"c4af3edfc858","title":"可用性:非常高,分布式架构"},{"parent":"954e7ff26b10","children":[],"id":"6a45885fa4c5","title":"消息可靠性:经过参数优化配置,消息可以做到零丢失"},{"parent":"954e7ff26b10","children":[],"id":"77955f421cf0","title":"功能支持:MQ功能较为完善,还是分布式的,扩展性好"},{"parent":"954e7ff26b10","children":[],"id":"2159848b2077","title":"支持10亿级别的消息堆积,不会因为堆积导致性能下降"},{"parent":"954e7ff26b10","children":[],"id":"8d732d9ac0d4","title":"源码是java,我们可以自己阅读源码,定制自己公司的MQ,可以掌控"},{"parent":"954e7ff26b10","children":[],"id":"079ef0e7e12f","title":"天生为金融互联网领域而生,对于可靠性要求很高的场景,尤其是电商里面的订单扣款,以及业务削峰,在大量交易涌入时,后端可能无法及时处理的情况"},{"parent":"954e7ff26b10","children":[],"id":"24933c880163","title":"RoketMQ在稳定性上可能更值得信赖,这些业务场景在阿里双11已经经历了多次考验,如果你的业务有上述并发场景,建议可以选择RocketMQ"}],"id":"954e7ff26b10","title":"优点"},{"parent":"4aa9ff9ad75c","children":[{"parent":"6e817ad0d7e2","children":[],"id":"5bc9518a9f6f","title":"支持的客户端语言不多,目前是java及c++,其中c++不成熟"},{"parent":"6e817ad0d7e2","children":[],"id":"bee9d1ce399f","title":"社区活跃度不是特别活跃那种"},{"parent":"6e817ad0d7e2","children":[],"id":"9e4046411e3c","title":"没有在 mq 核心中去实现JMS等接口,有些系统要迁移需要修改大量代码"}],"id":"6e817ad0d7e2","title":"缺点"}],"id":"4aa9ff9ad75c","title":"优缺点总结"}],"collapsed":true,"id":"2967bbb0ce6c","title":"RocketMQ"},{"parent":"root","lineStyle":{"randomLineColor":"#7754F6"},"children":[],"id":"6b402feebcdf","title":"分布式锁"},{"parent":"root","lineStyle":{"randomLineColor":"#FFCA01"},"children":[{"parent":"426e047d8f9d","children":[{"parent":"4b90dd9864c9","children":[{"parent":"057add18a139","children":[{"parent":"3097acf2ab15","children":[],"id":"df6d551163bc","title":"假如在第一阶段所有参与者都返回准备成功,那么协调者则向所有参与者发送提交事务命令,等待所有事务都提交成功之后,返回事务执行成功"},{"parent":"3097acf2ab15","children":[],"id":"d16589167a2c","title":"假如在第一阶段有一个参与者返回失败,那么协调者就会向所有参与者发送回滚事务的请求,即分布式事务执行失败"}],"id":"3097acf2ab15","title":"准备阶段: 协调者(事务管理器)给每个参与者发送Prepare消息,参与者要么直接返回失败,
要么在本地执行事务,写本地的redo和undo日志,但不做提交"},{"parent":"057add18a139","children":[{"parent":"8c5177c0c885","children":[],"id":"ab3d2da5a1c6","title":"如果第二阶段提交失败, 执行的是回滚事务操作, 那么会不断重试, 直到所有参与者全部回滚, 不然在第一阶段准备成功的参与者会一直阻塞"},{"parent":"8c5177c0c885","children":[],"id":"acc12723768c","title":"如果第二阶段提交失败, 执行的是提交事务, 也会不断重试, 因为有可能一些参与者已经提交成功, 所以只能不断重试, 甚至人工介入处理
"}],"id":"8c5177c0c885","title":"提交阶段: 协调者收到参与者的失败消息或者超时,直接给每个参与者发送回滚消息;
否则,发送提交消息. 参与者根据协调者的指令执行提交或回滚操作,释放锁资源"}],"id":"057add18a139","title":"流程"},{"parent":"4b90dd9864c9","children":[],"id":"fb30798578aa","title":"同步阻塞协议"},{"parent":"4b90dd9864c9","children":[{"parent":"7a977c8d1831","children":[],"id":"1cce93f1a7a6","title":"同步阻塞导致长久资源锁定, 效率低"},{"parent":"7a977c8d1831","children":[],"id":"ffb01d2f2712","title":"协调者是一个单点, 存在单点故障问题, 参与者将一直处于锁定状态"},{"parent":"7a977c8d1831","children":[],"id":"143f109fefcf","title":"脑裂问题, 在提交阶段,如果只有部分参与者接收并执行了提交请求,会导致节点数据不一致
"}],"id":"7a977c8d1831","title":"缺点"},{"parent":"4b90dd9864c9","children":[],"id":"75a98189b051","title":"是数据库层面解决方案"}],"id":"4b90dd9864c9","title":"2PC(两段式提交)"},{"parent":"426e047d8f9d","children":[{"parent":"e8856f8bce0a","children":[{"parent":"1eee8b12a46d","children":[],"id":"623a1ea6da3e","title":"CanCommit阶段: 协调者向参与者发送commit请求,参与者如果可以提交就返回Yes响应,否则返回No响应
"},{"parent":"1eee8b12a46d","children":[{"parent":"1a7358388525","children":[],"id":"21e1c7f27605","title":"假如协调者从所有的参与者获得的反馈都是Yes响应,那么就会执行事务的预执行"},{"parent":"1a7358388525","children":[],"id":"3e2483073c0d","title":"假如有任何一个参与者向协调者发送了No响应,或者等待超时之后,协调者都没有接到参与者的响应,那么就执行事务的中断"}],"id":"1a7358388525","title":"PreCommit阶段: 协调者根据参与者的反应情况来决定是否可以记性事务的PreCommit操作"},{"parent":"1eee8b12a46d","children":[{"parent":"24711faa09db","children":[{"parent":"28223e1f26b4","children":[],"id":"7ccba5096def","title":"发送提交请求 协调接收到参与者发送的ACK响应,那么他将从预提交状态进入到提交状态。并向所有参与者发送doCommit请求"},{"parent":"28223e1f26b4","children":[],"id":"2dd11bddf0c0","title":"事务提交 参与者接收到doCommit请求之后,执行正式的事务提交。并在完成事务提交之后释放所有事务资源"},{"parent":"28223e1f26b4","children":[],"id":"b7a3a303e9f7","title":"响应反馈 事务提交完之后,向协调者发送Ack响应"},{"parent":"28223e1f26b4","children":[],"id":"211c7b4aa22e","title":"完成事务 协调者接收到所有参与者的ack响应之后,完成事务"}],"id":"28223e1f26b4","title":"执行提交"},{"parent":"24711faa09db","children":[{"parent":"8abf9b8b22a0","children":[],"id":"f7664385e997","title":"发送中断请求 协调者向所有参与者发送abort请求"},{"parent":"8abf9b8b22a0","children":[],"id":"8f46d4cf1026","title":"事务回滚 参与者接收到abort请求之后,利用其在阶段二记录的undo信息来执行事务的回滚操作,并在完成回滚之后释放所有的事务资源"},{"parent":"8abf9b8b22a0","children":[],"id":"18777ca3eaf1","title":"反馈结果 参与者完成事务回滚之后,向协调者发送ACK消息"},{"parent":"8abf9b8b22a0","children":[],"id":"d27ccae9a9b6","title":"中断事务 协调者接收到参与者反馈的ACK消息之后,执行事务的中断"}],"id":"8abf9b8b22a0","title":"中断事务: 协调者没有接收到参与者发送的ACK响应, 或响应超时
"}],"id":"24711faa09db","title":"doCommit阶段: 该阶段进行真正的事务提交"}],"id":"1eee8b12a46d","title":"流程"},{"parent":"e8856f8bce0a","children":[{"parent":"bef994d87c61","children":[],"id":"cce362d1b257","title":"降低了阻塞范围,在等待超时后协调者或参与者会中断事务"},{"parent":"bef994d87c61","children":[],"id":"c30827441ec6","title":"避免了协调者单点问题,doCommit阶段中协调者出现问题时,参与者会继续提交事务"}],"id":"bef994d87c61","title":"优点"},{"parent":"e8856f8bce0a","children":[{"parent":"0c7767c1b90d","children":[],"id":"5942b8825222","title":"脑裂问题依然存在,即在参与者收到PreCommit请求后等待最终指令,如果此时协调者无法与参与者正常通信,会导致参与者继续提交事务,造成数据不一致"}],"id":"0c7767c1b90d","title":"缺点"},{"parent":"e8856f8bce0a","children":[],"id":"5bb33349d790","title":"是数据库层面解决方案"}],"id":"e8856f8bce0a","title":"3PC(三段式提交)"},{"parent":"426e047d8f9d","children":[{"parent":"b0b8679322ca","children":[{"parent":"006e94b9f913","children":[],"id":"59b9eb0f94d6","title":"Try阶段: 完成所有业务检查, 预留必须业务资源"},{"parent":"006e94b9f913","children":[],"id":"c5313a0fb055","title":"Confirm阶段: 真正执行业务, 不作任何业务检查, 只使用Try阶段预留的业务资源, Confirm操作必须保证幂等性
"},{"parent":"006e94b9f913","children":[],"id":"471ecf6d09dc","title":"Cancel阶段: 释放Try阶段预留的业务资源, Cancel操作必须保证幂等性
"}],"id":"006e94b9f913","title":"流程"},{"parent":"b0b8679322ca","children":[{"parent":"23870fd0159e","children":[],"id":"752def670283","title":"因为Try阶段检查并预留了资源,所以confirm阶段一般都可以执行成功"},{"parent":"23870fd0159e","children":[],"id":"a233a7cbf2e3","title":"资源锁定都是在业务代码中完成,不会block住DB,可以做到对db性能无影响"},{"parent":"23870fd0159e","children":[],"id":"7d19b1ea9c94","title":"TCC的实时性较高,所有的DB写操作都集中在confirm中,写操作的结果实时返回(失败时因为定时程序执行时间的关系,略有延迟)"}],"id":"23870fd0159e","title":"优点"},{"parent":"b0b8679322ca","children":[{"parent":"2ab2502c2344","children":[],"id":"c8b2dc57628d","title":"因为事务状态管理,将产生多次DB操作,这将损耗一定的性能,并使得整个TCC事务时间拉长"},{"parent":"2ab2502c2344","children":[],"id":"4d1e258645f4","title":"事务涉及方越多,Try、Confirm、Cancel中的代码就越复杂,可复用性就越底"},{"parent":"2ab2502c2344","children":[],"id":"56449003ad04","title":"涉及方越多,这几个阶段的处理时间越长,失败的可能性也越高"}],"id":"2ab2502c2344","title":"缺点"},{"parent":"b0b8679322ca","children":[],"id":"4c6d4fa72f28","title":"是业务层面解决方案"}],"id":"b0b8679322ca","title":"TCC(Try、Confirm、Cancel)"},{"parent":"426e047d8f9d","children":[],"id":"121687a469fc","title":"XA"},{"parent":"426e047d8f9d","children":[],"id":"48c137315bda","title":"最大努力通知"},{"parent":"426e047d8f9d","children":[],"id":"c6b7184c14c3","title":"本地消息表(ebay研发出的)"},{"parent":"426e047d8f9d","children":[{"parent":"3b31deded74d","children":[],"id":"84f89c2ef8a1","title":"事务消息"}],"id":"3b31deded74d","title":"半消息/最终一致性(RocketMQ)"}],"collapsed":true,"id":"426e047d8f9d","title":"分布式事务"}],"root":true,"theme":"dark_caihong","id":"root","title":"Java","structure":"mind_right"}},"meta":{"exportTime":"2022-02-16 17:35:03","member":"60b8501a63768975c7bcc153","diagramInfo":{"creator":"60b8501a63768975c7bcc153","created":"2021-06-23 17:55:24","modified":"2022-02-16 17:28:13","title":"Java知识点","category":"mind_free"},"id":"60d3050c1e08532a43b7f737","type":"ProcessOn Schema File","version":"1.0"}}
\ No newline at end of file
diff --git a/TODO/uml/ReplicaManager#appendRecordstxt b/TODO/uml/ReplicaManager#appendRecordstxt
deleted file mode 100644
index cf9eb42aa7..0000000000
--- a/TODO/uml/ReplicaManager#appendRecordstxt
+++ /dev/null
@@ -1,20 +0,0 @@
-@startuml
-title: ReplicaManager#appendRecords
-
-actor ReplicaManager as ReplicaManager
-
-alt requiredAcks值合法
-ReplicaManager -> ReplicaManager : 写入消息集到本地日志
-ReplicaManager -> ReplicaManager : 构建写入结果状态
-alt 等待其他副本完成写入
-ReplicaManager -> ReplicaManager : 创建延时请求对象
-ReplicaManager -> ReplicaManager : 交由 Puratory 管理
-else
-ReplicaManager -> ReplicaManager : 调用回调逻辑
-end
-else requiredAcks值非法
-ReplicaManager -> ReplicaManager : 构造特定异常对象
-ReplicaManager -> ReplicaManager : 封装进回调函数执行
-end
-
-@enduml
\ No newline at end of file
diff --git a/TODO/uml/mysql.xmind b/TODO/uml/mysql.xmind
deleted file mode 100644
index 2c439b7a2e..0000000000
Binary files a/TODO/uml/mysql.xmind and /dev/null differ
diff --git "a/TODO/uml/redis344円274円230円345円214円226円.xmind" "b/TODO/uml/redis344円274円230円345円214円226円.xmind"
deleted file mode 100644
index f4dfaa071a..0000000000
Binary files "a/TODO/uml/redis344円274円230円345円214円226円.xmind" and /dev/null differ
diff --git a/TODO/uml/spring.xmind b/TODO/uml/spring.xmind
deleted file mode 100644
index f9fd71b68e..0000000000
Binary files a/TODO/uml/spring.xmind and /dev/null differ
diff --git a/out/TODO/uml/ReplicaManager#appendRecordstxt/ReplicaManager#appendRecordstxt.png b/out/TODO/uml/ReplicaManager#appendRecordstxt/ReplicaManager#appendRecordstxt.png
deleted file mode 100644
index f0f9ca8bf5..0000000000
Binary files a/out/TODO/uml/ReplicaManager#appendRecordstxt/ReplicaManager#appendRecordstxt.png and /dev/null differ
diff --git a/out/TODO/uml/ReplicaManager#fetchMessages/ReplicaManager#fetchMessages.png b/out/TODO/uml/ReplicaManager#fetchMessages/ReplicaManager#fetchMessages.png
deleted file mode 100644
index 0e78971422..0000000000
Binary files a/out/TODO/uml/ReplicaManager#fetchMessages/ReplicaManager#fetchMessages.png and /dev/null differ
diff --git a/out/TODO/uml/appendRecords/appendRecords.png b/out/TODO/uml/appendRecords/appendRecords.png
deleted file mode 100644
index 4834cb85f7..0000000000
Binary files a/out/TODO/uml/appendRecords/appendRecords.png and /dev/null differ
diff --git a/out/TODO/uml/processFetchRequest/processFetchRequest.png b/out/TODO/uml/processFetchRequest/processFetchRequest.png
deleted file mode 100644
index 546e4be796..0000000000
Binary files a/out/TODO/uml/processFetchRequest/processFetchRequest.png and /dev/null differ
diff --git "a/345円244円247円346円225円260円346円215円256円/345円244円247円346円225円260円346円215円256円345円205円245円351円227円250円(344円272円224円)-345円210円206円345円270円203円345円274円217円350円256円241円347円256円227円346円241円206円346円236円266円MapReduce.md" "b/345円244円247円346円225円260円346円215円256円/345円244円247円346円225円260円346円215円256円345円205円245円351円227円250円(344円272円224円)-345円210円206円345円270円203円345円274円217円350円256円241円347円256円227円346円241円206円346円236円266円MapReduce.md"
index 0282e5cbcc..45ec7c21b8 100644
--- "a/345円244円247円346円225円260円346円215円256円/345円244円247円346円225円260円346円215円256円345円205円245円351円227円250円(344円272円224円)-345円210円206円345円270円203円345円274円217円350円256円241円347円256円227円346円241円206円346円236円266円MapReduce.md"
+++ "b/345円244円247円346円225円260円346円215円256円/345円244円247円346円225円260円346円215円256円345円205円245円351円227円250円(344円272円224円)-345円210円206円345円270円203円345円274円217円350円256円241円347円256円227円346円241円206円346円236円266円MapReduce.md"
@@ -2,32 +2,39 @@
源自于Google的MapReduce论文,发表于2004年12月。
Hadoop MapReduce是Google MapReduce的克隆版
-## 优点
-海量数量离线处理
-易开发
-易运行
-## 缺点
+
+- 优点
+海量数量离线处理&易开发&易运行
+
+- 缺点
实时流式计算
-# 2 MapReduce编程模型
-## wordcount词频统计
-
+# 2 MapReduce编程模型之通过wordcount词频统计分析案例入门
+
# MapReduce执行流程
- 将作业拆分成Map阶段和Reduce阶段
+
- Map阶段: Map Tasks
+
- Reduce阶段、: Reduce Tasks
+
## MapReduce编程模型执行步骤
-- 准备map处理的输入数据
-- Mapper处理
-- Shuffle
-- Reduce处理
-- 结果输出
-
+◆だいやまーく准备map处理的输入数据
+
+◆だいやまーくMapper处理
+
+◆だいやまーくShuffle
+
+◆だいやまーくReduce处理
+
+◆だいやまーく结果输出
+
+
- InputFormat
-
-
-
-
+
+
+
+
#### OutputFormat
OutputFormt接口决定了在哪里以及怎样持久化作业结果。Hadoop为不同类型的格式提供了一系列的类和接口,实现自定义操作只要继承其中的某个类或接口即可。你可能已经熟悉了默认的OutputFormat,也就是TextOutputFormat,它是一种以行分隔,包含制表符界定的键值对的文本文件格式。尽管如此,对多数类型的数据而言,如再常见不过的数字,文本序列化会浪费一些空间,由此带来的结果是运行时间更长且资源消耗更多。为了避免文本文件的弊端,Hadoop提供了SequenceFileOutputformat,它将对象表示成二进制形式而不再是文本文件,并将结果进行压缩。
@@ -35,32 +42,33 @@ OutputFormt接口决定了在哪里以及怎样持久化作业结果。Hadoop为
Split
InputFormat
OutputFormat
-Combiner
+C ombiner
Partitioner
-
+
## 3.1 Split
-
+
## 3.2 InputFormat
# 4 MapReduce 1.x 架构
-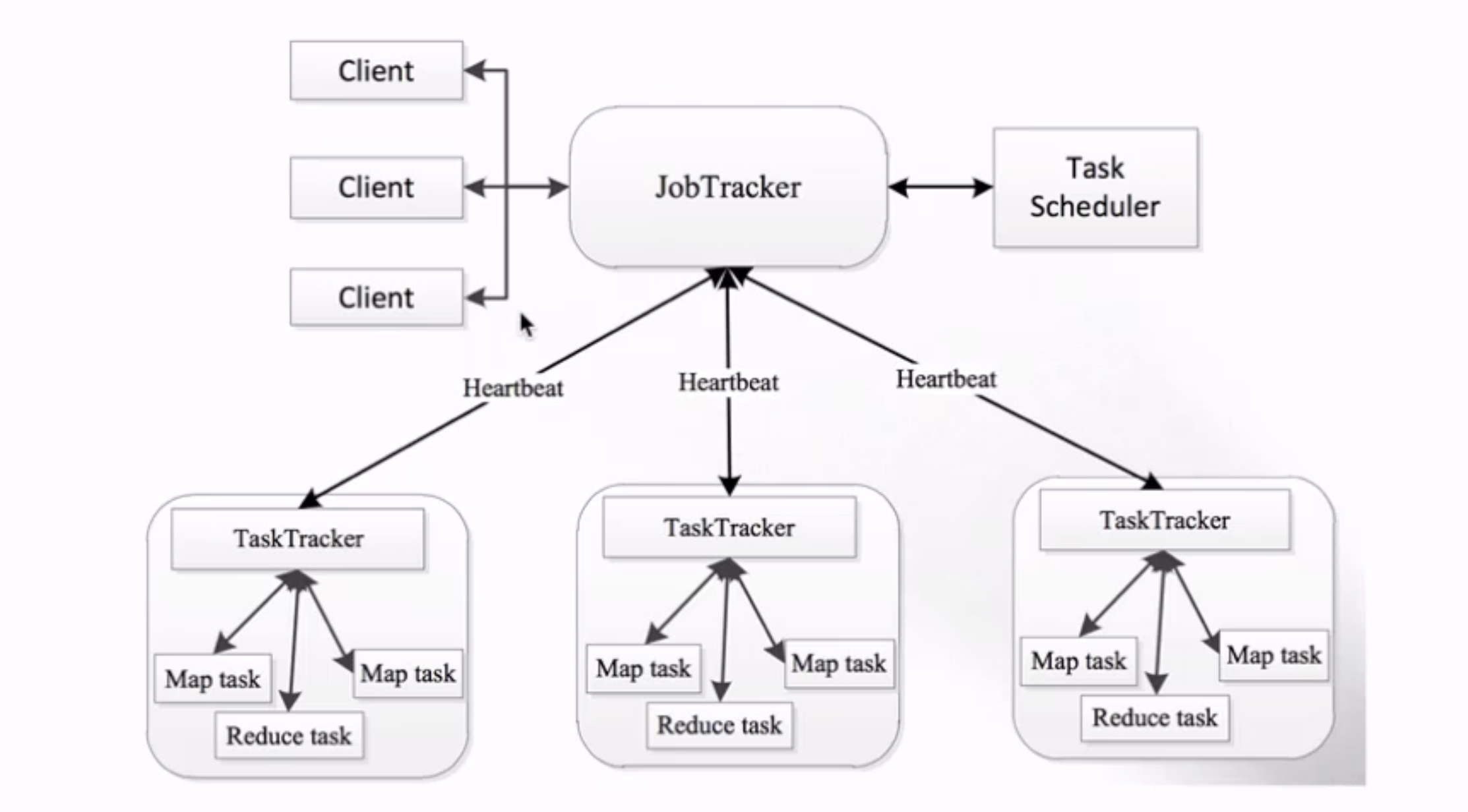
+
-
-
-
-
+
+
+
+
# 5 MapReduce 2.x 架构
-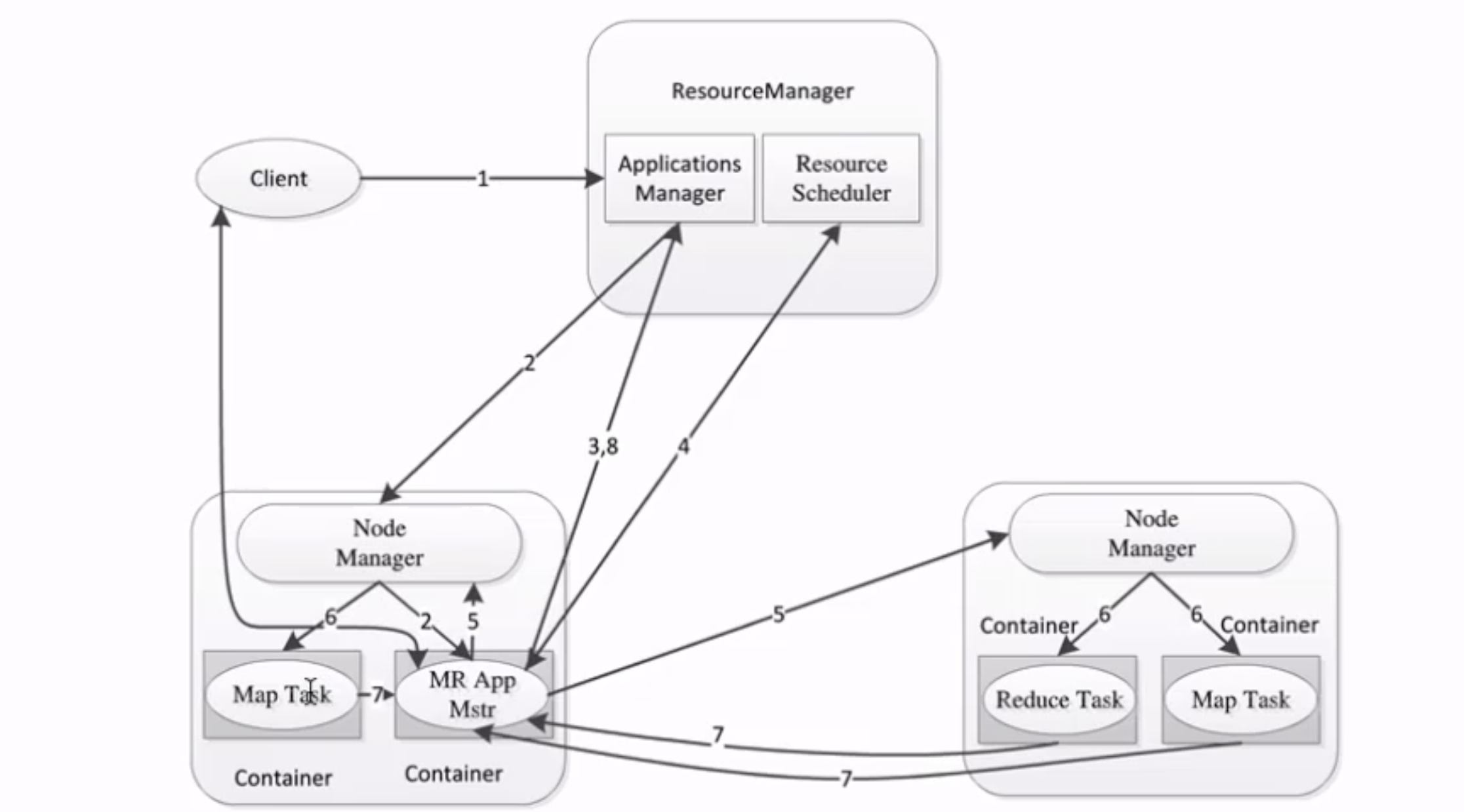
+
# 6 Java 实现 wordCount
-
-
-
-
-
+
+
+
+
+
# 7 重构
-
+
# 8 Combiner编程
-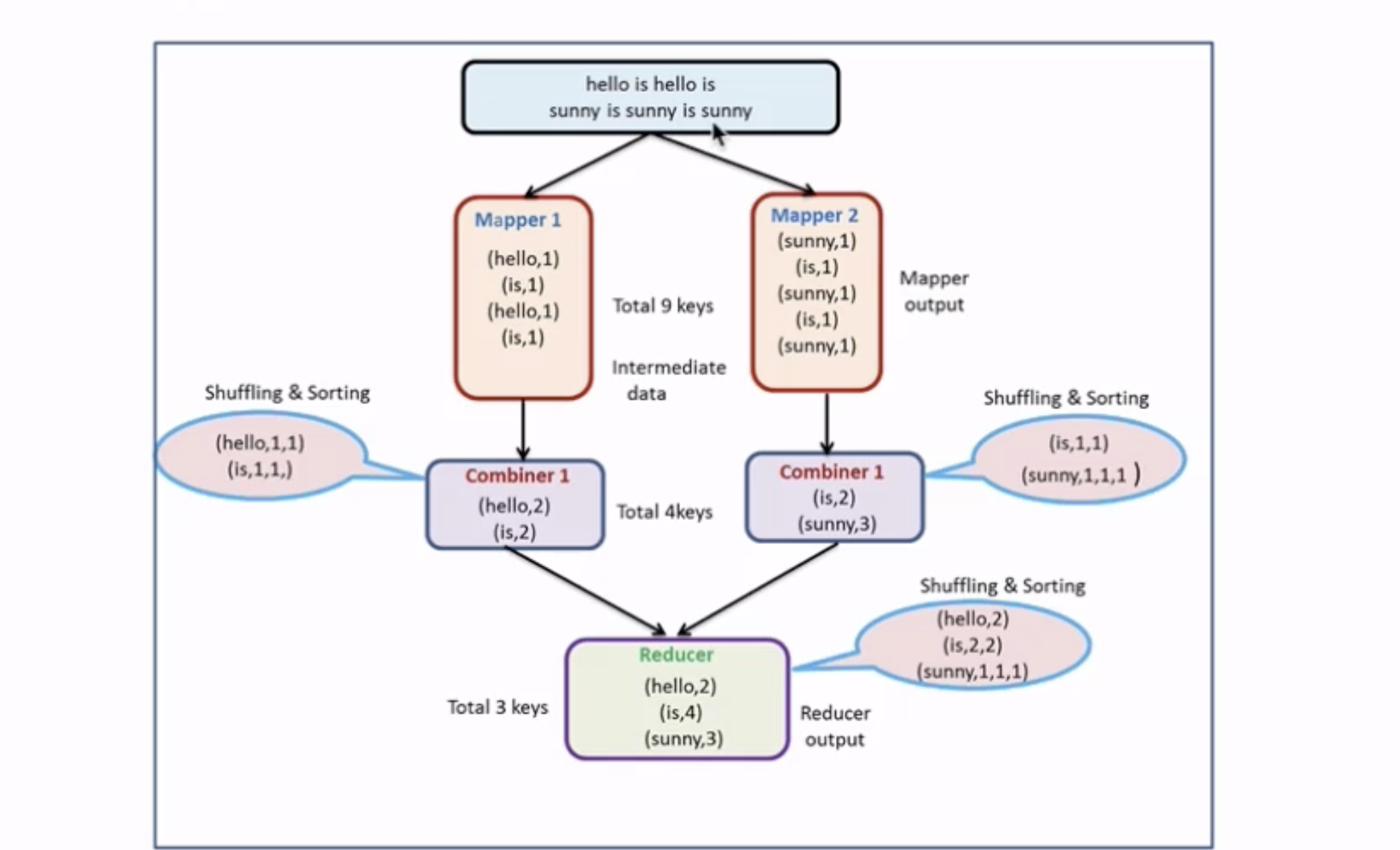
+
# 9 Partitoner
-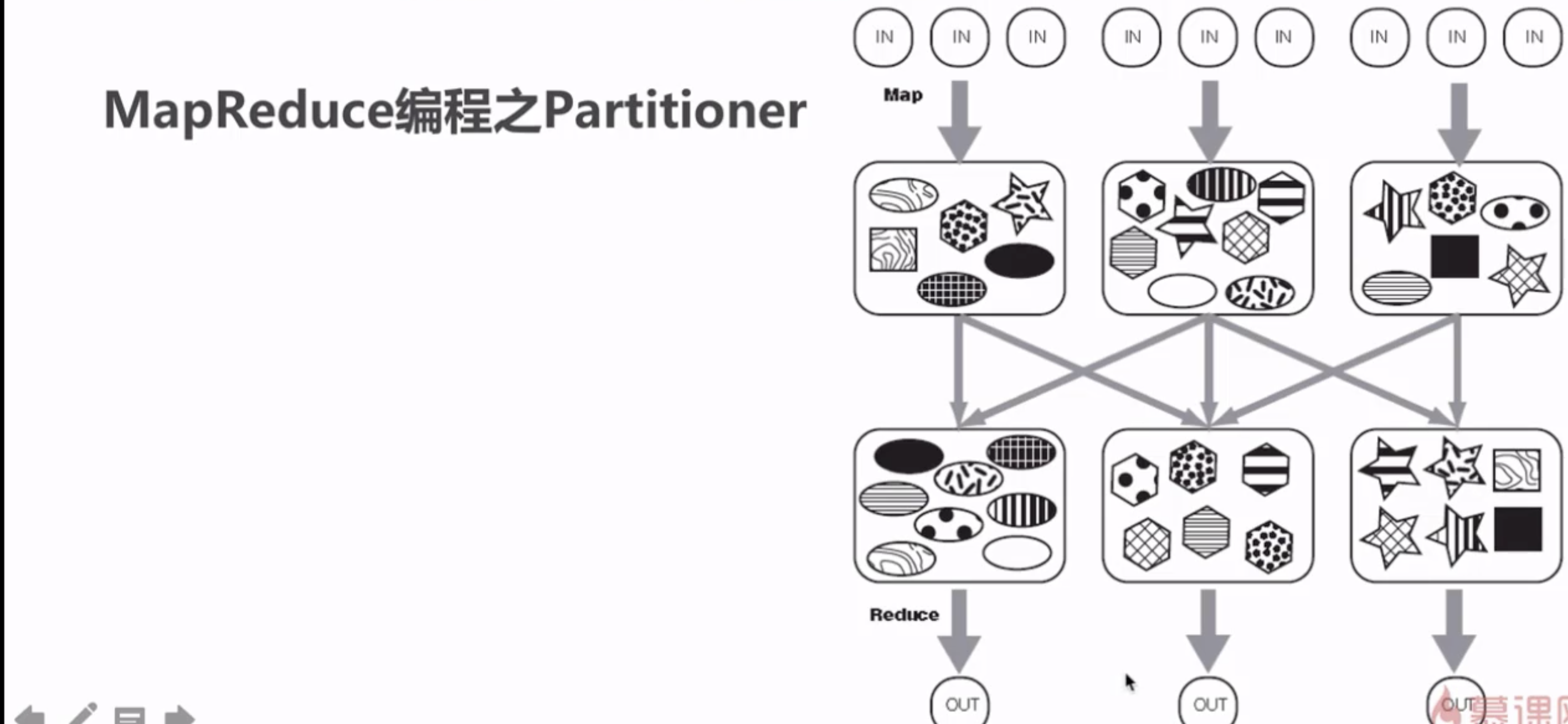
-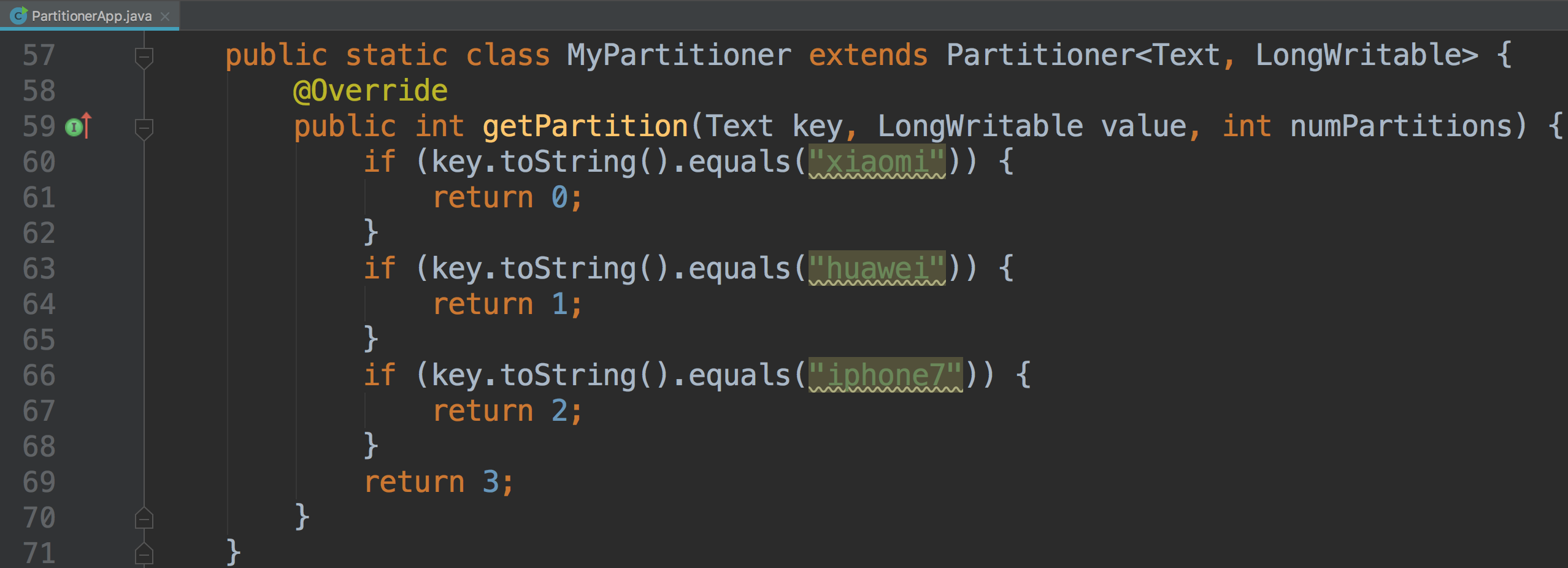
\ No newline at end of file
+
+
+
diff --git "a/346円223円215円344円275円234円347円263円273円347円273円237円/350円256円241円347円256円227円346円234円272円347円273円204円346円210円220円345円216円237円347円220円206円/346円214円207円344円273円244円345円222円214円350円277円220円347円256円227円346円230円257円345円246円202円344円275円225円345円215円217円344円275円234円346円236円204円346円210円220円CPU347円232円204円357円274円237円.md" "b/346円223円215円344円275円234円347円263円273円347円273円237円/350円256円241円347円256円227円346円234円272円347円273円204円346円210円220円345円216円237円347円220円206円/346円214円207円344円273円244円345円222円214円350円277円220円347円256円227円346円230円257円345円246円202円344円275円225円345円215円217円344円275円234円346円236円204円346円210円220円CPU347円232円204円357円274円237円.md"
deleted file mode 100644
index 5b4462873b..0000000000
--- "a/346円223円215円344円275円234円347円263円273円347円273円237円/350円256円241円347円256円227円346円234円272円347円273円204円346円210円220円345円216円237円347円220円206円/346円214円207円344円273円244円345円222円214円350円277円220円347円256円227円346円230円257円345円246円202円344円275円225円345円215円217円344円275円234円346円236円204円346円210円220円CPU347円232円204円357円274円237円.md"
+++ /dev/null
@@ -1,85 +0,0 @@
-连通"指令"和"计算"这两大功能,才能构建完整的CPU。
-# 1 指令周期(Instruction Cycle)
-计算机每执行一条指令的过程,可分解为如下步骤:
-1. Fetch(取指令)
-指令放在存储器,通过PC寄存器和指令寄存器取出指令的过程,由控制器(Control Unit)操作。
-从PC寄存器找到对应指令地址,据指令地址从内存把具体指令加载到指令寄存器,然后PC寄存器自增
-2. Decode(指令译码)
-据指令寄存器里面的指令,解析成要进行何操作,是R、I、J中的哪一种指令,具体要操作哪些寄存器、数据或内存地址。该阶段也是由控制器执行。
-3. Execute(执行指令)
-实际运行对应的R、I、J这些特定的指令,进行算术逻辑操作、数据传输或者直接的地址跳转。无论是算术操作、逻辑操作的R型指令,还是数据传输、条件分支的I型指令,都由算术逻辑单元(ALU)操作,即由运算器处理。
-如果是一个简单的无条件地址跳转,那可直接在控制器里完成,无需运算器。
-4. 重复1〜3
-
-这就是个永动机般的"FDE"循环,即指令周期。
-
-CPU还有两个Cycle:
-## Machine Cycle,机器周期或者CPU周期
-CPU内部操作速度很快,但访问内存速度却慢很多。
-每条指令都需要从内存里面加载而来,所以一般把从内存里面读取一条指令的最短时间,称为CPU周期。
-## Clock Cycle,时钟周期及机器主频
-一个CPU周期,通常由几个时钟周期累积。一个CPU周期时间,就是这几个Clock Cycle总和。
-
-对于一个指令周期,取出一条指令,然后执行它,至少需两个CPU周期:
-- 取出指令,至少得一个CPU周期
-- 执行指令,至少也得一个CPU周期
-因为执行完的结果,还要写回内存
-## 三个周期(Cycle)之间的关系
-
-一个指令周期,包含多个CPU周期,而一个CPU周期包含多个时钟周期。
-# 2 建立数据通路
-名字是什么其实并不重要,一般可以认为,数据通路就是我们的处理器单元,通常由两类原件组成:
-- 操作元件,也叫组合逻辑元件(Combinational Element),就是ALU
-在特定的输入下,根据下面的组合电路的逻辑,生成特定的输出。
-- 存储元件,也叫状态元件(State Element)
-如在计算过程中要用到的寄存器,无论是通用寄存器还是状态寄存器,都是存储元件。
-
-通过数据总线把它们连接起来,就可完成数据存储、处理和传输,即建立了数据通路。
-## 控制器
-可以把它看成只是机械地重复"Fetch - Decode - Execute"循环中的前两个步骤,然后把最后一个步骤,通过控制器产生的控制信号,交给ALU去处理。
-### 控制器将CPU指令解析成不同输出信号
-目前Intel CPU支持2000个以上指令。说明控制器输出的控制信号,至少有2000种不同组合。
-
-运算器里的ALU和各种组合逻辑电路,可认为是一个**固定功能的电路**。
-控制器"翻译"出来的,就是不同控制信号,告诉ALU去做不同计算。正是控制器,才让我们能"编程"实现功能,才铸就了"存储程序型计算机"。
-- 指令译码器将输入的机器码,解析成不同操作码、操作数,然后传输给ALU计算
-
-# 3 CPU对硬件电路的要求
-搭建CPU,还得在数字电路层面,实现如下功能。
-## ALU
-就是个无状态,根据输入计算输出结果的第一个电路。
-## 支持状态读写的电路元件 - 寄存器
-要有电路能存储上次计算结果。
-
-该计算结果不一定要立刻给下游电路使用,但可在需要时直接用。常见支持状态读写的电路:
-- 锁存器(Latch)
-- D触发器(Data/Delay Flip-flop)电路
-## 自动"电路,按固定周期实现PC寄存器自增
-自动执行Fetch - Decode - Execute。
-
-我们的程序执行,并非靠人工拨动开关执行指令。得有个"自动"电路,无休止执行一条条指令。
-
-看似复杂的各种函数调用、条件跳转,只是修改了PC寄存器保存的地址。PC寄存器里面的地址一修改,计算机即可加载一条指令新指令,往下运行。
-PC寄存器还叫程序计数器,随时间变化,不断计数。数字变大了,就去执行一条新指令。所以,我们需要的就是个自动计数的电路。
-## 译码电路
-无论是decode指令,还是对于拿到的内存地址去获取对应的数据或者指令,都要通过一个电路找到对应数据,就是"译码器"电路。
-
-把这四类电路,通过各种方式组合在一起就能组成CPU。要实现这四种电路中的中间两种,我们还需要时钟电路的配合。下一节,我们一起来看一看,这些基础的电路功能是怎么实现的,以及怎么把这些电路组合起来变成一个CPU。
-# 总结
-至此,CPU运转所需的数据通路和控制器介绍完了,也找出完成这些功能,需要的4种基本电路:
-- ALU这样的组合逻辑电路
-- 存储数据的锁存器和D触发器电路
-- 实现PC寄存器的计数器电路
-- 解码和寻址的译码器电路
-
-> CPU 好像一个永不停歇的机器,一直在不停地读取下一条指令去运行。那为什么 CPU 还会有满载运行和 Idle 闲置的状态呢?
-
-操作系统内核有 idle 进程,优先级最低,仅当其他进程都阻塞时被调度器选中。idle 进程循环执行 HLT 指令,关闭 CPU 大部分功能以降低功耗,收到中断信号时 CPU 恢复正常状态。 CPU在空闲状态就会停止执行,即切断时钟信号,CPU主频会瞬间降低为0,功耗也会瞬间降为0。由于这个空闲状态是十分短暂的,所以你在任务管理器也只会看到CPU频率下降,不会看到降为0。 当CPU从空闲状态中恢复时,就会接通时钟信号,CPU频率就会上升。所以你会在任务管理器里面看到CPU的频率起伏变化。
-
-uptime 命令查看平均负载
-
-满载运行就是平均负载为1.0(一个一核心CPU),定义为特定时间间隔内运行队列中的平均线程数。
-load average 表示机器一段时间内的平均load,越低越好。过高可能导致机器无法处理其他请求及操作,甚至死机。
-
-当CUP执行完当前系统分配的任务,为省电,系统将执行空闲任务(idle task),该任务循环执行HLT指令,CPU就会停止指令的执行,且让CPU处于HALT状态,CPU虽停止指令执行,且CPU部分功能模块将会被关闭(以低功耗),但CPU的LAPIC(Local Advanced Programmable Interrupt Controller)并不会停止工作,即CPU将会继续接收外部中断、异常等外部事件(事实上,CPU HALT状态的退出将由外部事件触发)。"Idle 闲置"是一种低功耗的状态,cpu在执行最低功耗的循环指令。实际上并非啥都没干,而是一直在干最最轻松的事儿。
-当CPU接收到这些外部事件,将会从HALT状态恢复,执行中断服务函数,且当中断服务函数执行完毕后,指令寄存器(CS:EIP)将会指向HLT指令的下一条指令,即CPU继续执行HLT指令之后的程序。
\ No newline at end of file
diff --git "a/346円223円215円344円275円234円347円263円273円347円273円237円/351円233円266円346円213円267円350円264円235円357円274円210円Zero Copy357円274円211円346円212円200円346円234円257円345円210円260円345円272円225円346円230円257円344円273円200円344円271円210円357円274円237円.md" "b/346円223円215円344円275円234円347円263円273円347円273円237円/351円233円266円346円213円267円350円264円235円357円274円210円Zero Copy357円274円211円346円212円200円346円234円257円345円210円260円345円272円225円346円230円257円344円273円200円344円271円210円357円274円237円.md"
deleted file mode 100644
index ba67fb6257..0000000000
--- "a/346円223円215円344円275円234円347円263円273円347円273円237円/351円233円266円346円213円267円350円264円235円357円274円210円Zero Copy357円274円211円346円212円200円346円234円257円345円210円260円345円272円225円346円230円257円344円273円200円344円271円210円357円274円237円.md"
+++ /dev/null
@@ -1,25 +0,0 @@
-rabbitmq 这么高吞吐量都是因为零拷贝技术,本文以 kafka 为例讲解。
-
-消息从发送到落地保存,broker 维护的消息日志本身就是文件目录,每个文件都是二进制保存,生产者和消费者使用相同格式来处理。
-
-Con获取消息时,服务器先从硬盘读取数据到内存,然后将内存中数据通过 socket 发给Con。
-
-Linux的零拷贝技术:当数据在磁盘和网络之间传输时,避免昂贵的内核态数据拷贝,从而实现快速数据传输。
-Linux平台实现了这样的零拷贝机制,但Windows必须要到Java 8的60更新版本才能"享受"到。
-
-- os将数据从磁盘读入到内核空间的页缓存
-- 应用程序将数据从内核空间读入到用户空间缓存
-- 应用程序将数据写回到内核空间到 socket 缓存
-- os将数据从 socket 缓冲区复制到网卡缓冲区,以便将数据经网络发出
-
-该过程涉及:
-- 4 次上下文切换
-- 4 次数据复制
-有两次复制操作是 CPU 完成的。但该过程中,数据完全无变化,仅是从磁盘复制到网卡缓冲区。
-
-而通过"零拷贝"技术,能去掉这些没必要的数据复制操作, 也减少了上下文切换次数。
-现代的 unix 操作系统提供一个优化的代码路径,将数据从页缓存传输到 socket;
-在 Linux 中,是通过 sendfile 系统调用完成的。Java 提供了访问这个系统调用的方法:**FileChannel.transferTo** API
-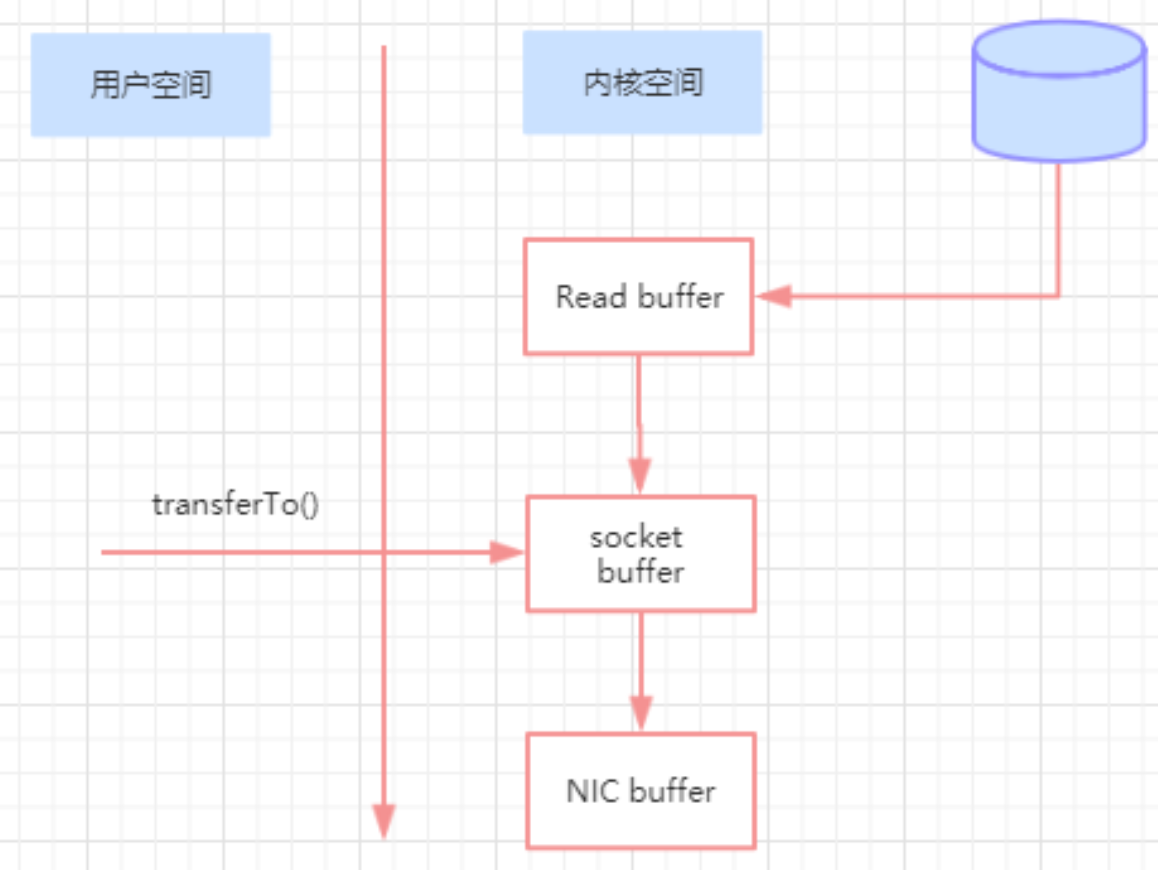
-使用 sendfile,只需一次拷贝,允许os将数据直接从页缓存发送到网络。
-所以在这个优化的路径中, 只有最后一步:将数据拷贝到网卡缓存中是必须的。
\ No newline at end of file
diff --git "a/346円225円260円346円215円256円345円255円230円345円202円250円/Kafka/Kafka345円256円236円346円210円230円/Kafka345円256円236円346円210円230円(7)-344円274円230円351円233円205円345円234円260円351円203円250円347円275円262円 Kafka 351円233円206円347円276円244円.md" "b/346円225円260円346円215円256円345円255円230円345円202円250円/Kafka/Kafka345円256円236円346円210円230円/Kafka345円256円236円346円210円230円(7)-344円274円230円351円233円205円345円234円260円351円203円250円347円275円262円 Kafka 351円233円206円347円276円244円.md"
deleted file mode 100644
index e1f5682e02..0000000000
--- "a/346円225円260円346円215円256円345円255円230円345円202円250円/Kafka/Kafka345円256円236円346円210円230円/Kafka345円256円236円346円210円230円(7)-344円274円230円351円233円205円345円234円260円351円203円250円347円275円262円 Kafka 351円233円206円347円276円244円.md"
+++ /dev/null
@@ -1,109 +0,0 @@
-生产环境需考量各种因素,结合自身业务需求而制定。看一些考虑因素(以下顺序,可是分了顺序的哦)
-# 1 OS
-- Kafka不是JVM上的中间件吗?Java又是跨平台语言,把Kafka安装到不同的os有啥区别吗?
-区别相当大!
-
-Kafka的确由Scala/Java编写,编译后源码就是".class"文件。部署到啥OS应该一样,但毋庸置疑,部署在Linux上的生产环境是最多的,具体原因你能谈笑风生吗?
-## 1.1 I/O模型
-I/O模型其实就是os执行I/O指令的方法,主流的I/O模型通常有5种类型:
-1. 阻塞式I/O
-e.g. Java中Socket的阻塞模式
-2. 非阻塞式I/O
-e.g. Java中Socket的非阻塞模式
-3. I/O多路复用
-e.g. Linux中的系统调用`select`函数
-4. 信号驱动I/O
-e.g. epoll系统调用则介于第三种和第四种模型之间
-5. 异步I/O
-e.g. 很少有Linux支持,反而Windows系统提供了一个叫IOCP线程模型属于该类
-
-I/O模型与Kafka的关系几何?Kafka Client 底层使用了Java的selector,而selector
-- 在Linux上的实现机制是epoll
-- 在Windows平台上的实现机制是select
-
-因为这点,Kafka部署在Linux上更有优势,能获得更高效的I/O性能。
-## 1.2 数据网络传输效率
-- Kafka生产和消费的消息都是通过网络传输,但消息保存在哪呢?
-肯定是磁盘!
-
-故Kafka需在磁盘和网络间进行大量数据传输。在Linux部署Kafka能够享受到零拷贝技术带来的快速数据传输特性。
-## 1.3 社区生态
-社区对Windows平台上发现的Kafka Bug不做任何承诺。
-# 2 磁盘
-## 2.1 机械硬盘 or SSD
-- 前者便宜且容量大,但易坏!
-- 后者性能优势大,但是贵!
-
-建议是使用普通机械硬盘即可。
-- Kafka虽然大量使用磁盘,可多是顺序读写操作,一定程度规避了机械磁盘最大的劣势,即随机读写慢。从这一点上来说,使用SSD并没有太大性能优势,机械磁盘物美价廉
-- 而它因易损坏而造成的可靠性差等缺陷,又由Kafka在软件层面提供机制来保证
-## 2.2 是否应该使用磁盘阵列(RAID)
-使用RAID的主要优势:
-- 提供冗余的磁盘存储空间
-- 提供负载均衡
-
-对于Kafka
-- Kafka自己实现了冗余机制,提供高可靠性
-- 通过分区设计,也能在软件层面自行实现负载均衡
-
-RAID优势也就没有那么明显了。虽然实际上依然有很多大厂确实是把Kafka底层的存储交由RAID,只是目前Kafka在存储这方面提供了越来越便捷的高可靠性方案,因此在线上环境使用RAID似乎变得不是那么重要了。
-
-综上,追求性价比的公司可不搭建RAID,使用普通磁盘组成存储空间即可。使用机械磁盘完全能够胜任Kafka线上环境。
-## 2.3 磁盘容量
-集群到底需要多大?
-Kafka需要将消息保存在磁盘上,这些消息默认会被保存一段时间然后自动被删除。
-虽然这段时间是可以配置的,但你应该如何结合自身业务场景和存储需求来规划Kafka集群的存储容量呢?
-
-假设有个业务
-- 每天需要向Kafka集群发送1亿条消息
-- 每条消息保存两份以防止数据丢失
-- 消息默认保存两周时间
-
-现在假设消息的平均大小是1KB,那么你能说出你的Kafka集群需要为这个业务预留多少磁盘空间吗?
-
-计算:
-- 每天1亿条1KB的消息,存两份
-`1亿 * 1KB * 2 / 1000 / 1000 = 200GB`
-
-- 一般Kafka集群除消息数据还存其他类型数据,比如索引数据
-再为其预留10%磁盘空间,因此总的存储容量就是220GB
-
-- 要存两周,那么整体容量即为
-220GB * 14,大约3TB
-- Kafka支持数据的压缩,假设压缩比是0.75
-那么最后规划的存储空间就是0.75 * 3 = 2.25TB
-
-总之在规划磁盘容量时你需要考虑下面这几个元素:
-- 新增消息数
-- 消息留存时间
-- 平均消息大小
-- 备份数
-- 是否启用压缩
-# 3 带宽
-对于Kafka这种通过网络进行大数据传输的框架,带宽易成为瓶颈。
-
-普通以太网络,带宽主要有两种:
-- 1Gbps的千兆网络
-- 10Gbps的万兆网络
-
-以千兆网络为例,说明带宽资源规划。真正要规划的是所需的Kafka服务器的数量。假设机房环境是千兆网络,即1Gbps,现在有业务,其目标或SLA是在1小时内处理1TB的业务数据。
-
-到底需要多少台Kafka服务器来完成这个业务呢?
-### 计算
-带宽1Gbps,即每秒处理1Gb数据
-假设每台Kafka服务器都是安装在专属机器,即每台Kafka机器上没有混入其他服务
-通常情况下你只能假设Kafka会用到70%的带宽资源,因为总要为其他应用或进程留一些资源。超过70%的阈值就有网络丢包可能性,故70%的设定是一个比较合理的值,也就是说单台Kafka服务器最多也就能使用大约700Mb带宽。
-
-这只是它能使用的最大带宽资源,你不能让Kafka服务器常规性使用这么多资源,故通常要再额外预留出2/3的资源,即
-`单台服务器使用带宽700Mb / 3 ≈ 240Mbps`
-这里的2/3其实是相当保守的,可以结合机器使用情况酌情减少该值
-
-有了240Mbps,可以计算1小时内处理1TB数据所需的服务器数量了。
-根据这个目标,每秒需要处理2336Mb的数据,除以240,约等于10台服务器。
-如果消息还需要额外复制两份,那么总的服务器台数还要乘以3,即30台。
-# 总结
-部署Kafka环境,一开始就要思考好实际场景下业务所需的集群环境,不能仅从单个维度上进行评估。
-
-> 参考
-> - Linux内核模型架构
-> - Kafka核心技术与实战
\ No newline at end of file
diff --git "a/346円225円260円346円215円256円345円255円230円345円202円250円/Kafka/Kafka345円256円236円346円210円230円/Kafka345円256円236円346円210円230円(344円270円203円) - 344円274円230円351円233円205円345円234円260円351円203円250円347円275円262円 Kafka 351円233円206円347円276円244円.md" "b/346円225円260円346円215円256円345円255円230円345円202円250円/Kafka/Kafka345円256円236円346円210円230円/Kafka345円256円236円346円210円230円(344円270円203円) - 344円274円230円351円233円205円345円234円260円351円203円250円347円275円262円 Kafka 351円233円206円347円276円244円.md"
new file mode 100644
index 0000000000..7d79f7f122
--- /dev/null
+++ "b/346円225円260円346円215円256円345円255円230円345円202円250円/Kafka/Kafka345円256円236円346円210円230円/Kafka345円256円236円346円210円230円(344円270円203円) - 344円274円230円351円233円205円345円234円260円351円203円250円347円275円262円 Kafka 351円233円206円347円276円244円.md"
@@ -0,0 +1,127 @@
+既然是集群,必然有多个Kafka节点,只有单节点构成的Kafka伪集群只能用于日常测试,不可能满足线上生产需求。
+真正的线上环境需要考量各种因素,结合自身的业务需求而制定。看一些考虑因素(以下顺序,可是分了顺序的哦)
+
+# 1 操作系统 - OS
+可能你会问Kafka不是JVM上的大数据框架吗?Java又是跨平台的语言,把Kafka安装到不同的操作系统上会有什么区别吗?
+区别相当大!
+
+确实,Kafka由Scala/Java编写,编译后源码就是".class"文件。
+本来部署到哪个OS应该一样,但是不同OS的差异还是给Kafka集群带来了相当大的影响。
+毋庸置疑,部署在Linux上的生产环境是最多的。
+
+考虑操作系统与Kafka的适配性,Linux系统显然要比其他两个特别是Windows系统更加适合部署Kafka。可具体原因你能谈笑风生吗?
+## 1.1 I/O模型
+I/O模型可以近似认为I/O模型就是OS执行I/O指令的方法。
+主流的I/O模型通常有5种类型:
+1. 阻塞式I/O
+e.g. Java中Socket的阻塞模式
+2. 非阻塞式I/O
+e.g. Java中Socket的非阻塞模式
+3. I/O多路复用
+e.g. Linux中的系统调用`select`函数
+4. 信号驱动I/O
+e.g. epoll系统调用则介于第三种和第四种模型之间
+5. 异步I/O
+e.g. 很少有Linux支持,反而Windows系统提供了一个叫IOCP线程模型属于该类
+
+我在这里不详细展开每一种模型的实现细节,因为那不是本文重点。
+
+言归正传,I/O模型与Kafka的关系几何?
+Kafka Client 底层使用了Java的selector,而selector
+- 在Linux上的实现机制是epoll
+- 在Windows平台上的实现机制是select
+
+因此在这一点上将Kafka部署在Linux上是有优势的,能够获得更高效的I/O性能。
+## 1.2 数据网络传输效率
+Kafka生产和消费的消息都是通过网络传输的,而消息保存在哪里呢?
+肯定是磁盘!
+故Kafka需要在磁盘和网络间进行大量数据传输。
+Linux有个零拷贝(Zero Copy)技术,就是当数据在磁盘和网络进行传输时避免昂贵内核态数据拷贝从而实现快速数据传输。Linux平台实现了这样的零拷贝机制,但有些令人遗憾的是在Windows平台上必须要等到Java 8的60更新版本才能"享受"到。
+
+一句话,在Linux部署Kafka能够享受到零拷贝技术所带来的快速数据传输特性带来的极致快感。
+
+## 1.3 社区生态
+社区目前对Windows平台上发现的Kafka Bug不做任何承诺。因此,Windows平台上部署Kafka只适合于个人测试或用于功能验证,千万不要应用于生产环境。
+
+# 2 磁盘
+## 2.1 灵魂拷问:机械硬盘 or 固态硬盘
+- 前者便宜且容量大,但易坏!
+- 后者性能优势大,但是贵!
+
+
+建议是使用普通机械硬盘即可。
+- Kafka虽然大量使用磁盘,可多是顺序读写操作,一定程度上规避了机械磁盘最大的劣势,即随机读写慢。从这一点上来说,使用SSD并没有太大性能优势,机械磁盘物美价廉
+- 而它因易损坏而造成的可靠性差等缺陷,又由Kafka在软件层面提供机制来保证
+
+
+## 2.2 是否应该使用磁盘阵列(RAID)
+使用RAID的两个主要优势在于:
+- 提供冗余的磁盘存储空间
+- 提供负载均衡
+
+不过就Kafka而言
+- Kafka自己实现了冗余机制提供高可靠性
+- 通过分区的设计,也能在软件层面自行实现负载均衡
+
+如此说来RAID的优势也就没有那么明显了。虽然实际上依然有很多大厂确实是把Kafka底层的存储交由RAID的,只是目前Kafka在存储这方面提供了越来越便捷的高可靠性方案,因此在线上环境使用RAID似乎变得不是那么重要了。
+综上,追求性价比的公司可以不搭建RAID,使用普通磁盘组成存储空间即可。使用机械磁盘完全能够胜任Kafka线上环境。
+
+## 2.3 磁盘容量
+集群到底需要多大?
+Kafka需要将消息保存在磁盘上,这些消息默认会被保存一段时间然后自动被删除。
+虽然这段时间是可以配置的,但你应该如何结合自身业务场景和存储需求来规划Kafka集群的存储容量呢?
+
+假设有个业务
+- 每天需要向Kafka集群发送1亿条消息
+- 每条消息保存两份以防止数据丢失
+- 消息默认保存两周时间
+
+现在假设消息的平均大小是1KB,那么你能说出你的Kafka集群需要为这个业务预留多少磁盘空间吗?
+
+计算:
+- 每天1亿条1KB的消息,存两份
+`1亿 * 1KB * 2 / 1000 / 1000 = 200GB`
+
+- 一般Kafka集群除消息数据还存其他类型数据,比如索引数据
+再为其预留10%磁盘空间,因此总的存储容量就是220GB
+
+- 要存两周,那么整体容量即为
+220GB * 14,大约3TB
+- Kafka支持数据的压缩,假设压缩比是0.75
+那么最后规划的存储空间就是0.75 * 3 = 2.25TB
+
+总之在规划磁盘容量时你需要考虑下面这几个元素:
+- 新增消息数
+- 消息留存时间
+- 平均消息大小
+- 备份数
+- 是否启用压缩
+
+# 3 带宽
+对于Kafka这种通过网络进行大数据传输的框架,带宽容易成为瓶颈。
+普通的以太网络,带宽主要有两种:1Gbps的千兆网络和10Gbps的万兆网络,特别是千兆网络应该是一般公司网络的标准配置了
+以千兆网络为例,说明带宽资源规划。
+
+真正要规划的是所需的Kafka服务器的数量。
+假设机房环境是千兆网络,即1Gbps,现在有业务,其目标或SLA是在1小时内处理1TB的业务数据。
+那么问题来了,你到底需要多少台Kafka服务器来完成这个业务呢?
+
+### 计算
+带宽1Gbps,即每秒处理1Gb数据
+假设每台Kafka服务器都是安装在专属机器,即每台Kafka机器上没有混入其他服务
+通常情况下你只能假设Kafka会用到70%的带宽资源,因为总要为其他应用或进程留一些资源。超过70%的阈值就有网络丢包可能性,故70%的设定是一个比较合理的值,也就是说单台Kafka服务器最多也就能使用大约700Mb带宽。
+
+这只是它能使用的最大带宽资源,你不能让Kafka服务器常规性使用这么多资源,故通常要再额外预留出2/3的资源,即
+`单台服务器使用带宽700Mb / 3 ≈ 240Mbps`
+这里的2/3其实是相当保守的,可以结合机器使用情况酌情减少该值
+
+有了240Mbps,可以计算1小时内处理1TB数据所需的服务器数量了。
+根据这个目标,每秒需要处理2336Mb的数据,除以240,约等于10台服务器。
+如果消息还需要额外复制两份,那么总的服务器台数还要乘以3,即30台。
+
+# 总结
+与其盲目上马一套Kafka环境然后事后费力调整,不如在一开始就思考好实际场景下业务所需的集群环境。在考量部署方案时需要通盘考虑,不能仅从单个维度上进行评估。
+
+# 参考
+- Linux内核模型架构
+- Kafka核心技术与实战
diff --git "a/346円225円260円346円215円256円345円255円230円345円202円250円/Kafka/Kafka345円256円236円346円210円230円/Kafka345円256円236円346円210円230円(4) -Kafka351円227円250円346円264円276円347円237円245円345円244円232円345円260円221円.md" "b/346円225円260円346円215円256円345円255円230円345円202円250円/Kafka/Kafka345円256円236円346円210円230円/Kafka345円256円236円346円210円230円(345円233円233円) -Kafka351円227円250円346円264円276円347円237円245円345円244円232円345円260円221円.md"
similarity index 100%
rename from "346円225円260円346円215円256円345円255円230円345円202円250円/Kafka/Kafka345円256円236円346円210円230円/Kafka345円256円236円346円210円230円(4) -Kafka351円227円250円346円264円276円347円237円245円345円244円232円345円260円221円.md"
rename to "346円225円260円346円215円256円345円255円230円345円202円250円/Kafka/Kafka345円256円236円346円210円230円/Kafka345円256円236円346円210円230円(345円233円233円) -Kafka351円227円250円346円264円276円347円237円245円345円244円232円345円260円221円.md"
diff --git "a/346円225円260円346円215円256円345円255円230円345円202円250円/Kafka/Kafka351円253円230円346円200円247円350円203円275円345円216円237円347円220円206円345円210円206円346円236円220円.md" "b/346円225円260円346円215円256円345円255円230円345円202円250円/Kafka/Kafka351円253円230円346円200円247円350円203円275円345円216円237円347円220円206円345円210円206円346円236円220円.md"
index 2c90d94a66..65c0b5f134 100644
--- "a/346円225円260円346円215円256円345円255円230円345円202円250円/Kafka/Kafka351円253円230円346円200円247円350円203円275円345円216円237円347円220円206円345円210円206円346円236円220円.md"
+++ "b/346円225円260円346円215円256円345円255円230円345円202円250円/Kafka/Kafka351円253円230円346円200円247円350円203円275円345円216円237円347円220円206円345円210円206円346円236円220円.md"
@@ -214,5 +214,25 @@ Kafka 中存储的一般都是海量的消息数据,为了避免日志文件
## 4.3 消息写入的性能
我们现在大部分企业仍然用的是机械结构的磁盘,如果把消息以随机的方式写入到磁盘,那么磁盘首先要做的就是寻址,也就是定位到数据所在的物理地址,在磁盘上就要找到对应的柱面、磁头以及对应的扇区;这个过程相对内 存来说会消耗大量时间,为了规避随机读写带来的时间消耗,kafka 采用顺序写的方式存储数据。
-即使是这样,但是频繁的 I/O 操作仍然会造成磁盘的性能瓶颈,所以 kafka 还有一个性能策略。
+即使是这样,但是频繁的 I/O 操作仍然会造成磁盘的性能瓶颈,所以 kafka 还有一个性能策略
+
+## 4.4 零拷贝
+消息从发送到落地保存,broker 维护的消息日志本身就是文件目录,每个文件都是二进制保存,生产者和消费者使用相同的格式来处理。在消费者获取消息时,服务器先从硬盘读取数据到内存,然后把内存中的数据原封不动的通 过 socket 发送给消费者。
+
+虽然这个操作描述起来很简单, 但实际上经历了很多步骤
+
+
+▪ 操作系统将数据从磁盘读入到内核空间的页缓存
+▪ 应用程序将数据从内核空间读入到用户空间缓存中
+▪ 应用程序将数据写回到内核空间到 socket 缓存中
+▪ 操作系统将数据从 socket 缓冲区复制到网卡缓冲区,以便将数据经网络发出
+
+这个过程涉及到 4 次上下文切换以及 4 次数据复制,并且有两次复制操作是由 CPU 完成。但是这个过程中,数据完全没有进行变化,仅仅是从磁盘复制到网卡缓冲区。
+
+通过"零拷贝"技术,可以去掉这些没必要的数据复制操作, 同时也会减少上下文切换次数。现代的 unix 操作系统提供 一个优化的代码路径,用于将数据从页缓存传输到 socket;
+在 Linux 中,是通过 sendfile 系统调用来完成的。
+Java 提供了访问这个系统调用的方法:FileChannel.transferTo API
+
+
+使用 sendfile,只需要一次拷贝就行,允许操作系统将数据直接从页缓存发送到网络上。所以在这个优化的路径中, 只有最后一步将数据拷贝到网卡缓存中是需要的。
diff --git "a/346円225円260円346円215円256円347円273円223円346円236円204円344円270円216円347円256円227円346円263円225円/345円233円236円346円272円257円347円256円227円346円263円225円.md" "b/346円225円260円346円215円256円347円273円223円346円236円204円344円270円216円347円256円227円346円263円225円/345円233円236円346円272円257円347円256円227円346円263円225円.md"
deleted file mode 100644
index c001787db6..0000000000
--- "a/346円225円260円346円215円256円347円273円223円346円236円204円344円270円216円347円256円227円346円263円225円/345円233円236円346円272円257円347円256円227円346円263円225円.md"
+++ /dev/null
@@ -1,68 +0,0 @@
-DFS利用的就是是回溯算法思想,但其实回溯还可用在如正则表达式匹配、编译原理中的语法分析等。
-
-数学问题也可,如数独、八皇后、0-1背包、图的着色、旅行商问题、全排列等。
-# 理解"回溯算法"
-> 若人生可重来,如何才能在岔路口做出最正确选择,让自己的人生"最优"?
-
-贪心算法,在每次面对岔路口的时候,都做出看起来最优的选择,期望这一组选择可以使得我们的人生达到"最优"。但不一定能得到的是最优解。
-
-> 如何确保得到最优解?
-
-回溯算法很多时候都应用在"搜索"问题:在一组可能解中,搜索期望解。
-处理思想,类似枚举搜索:枚举所有解,找到满足期望的解。
-
-为规律枚举所有可能解,避免遗漏、重复,将问题求解过程分为多个阶段。
-每个阶段,都要面对一个岔路口,先随意选一条路走,当发现这条路走不通(不符合期望的解),就回退到上一个岔路口,另选一种走法继续走。
-# 八皇后
-8x8的棋盘,往里放8个棋子(皇后),每个棋子所在的行、列、对角线都不能有另一个棋子。
-
-
-把这个问题划分成8个阶段,依次将8个棋子放到第一行、第二行、第三行......第八行。
-放置过程中,不停地检查当前方法,是否满足要求
-- 满足
-跳到下一行继续放置棋子
-- 不满足
-换种方法尝试
-
-适合递归实现:
-
-# 0-1背包
-经典解法是动态规划,但还有简单但没那么高效的回溯解法。
-
-- 有一背包,背包总承载重量Wkg
-- 有n个物品,每个物品重量不等且不可分割
-- 期望选择几件物品,装载到背包中。在不超过背包所能装载重量的前提下,求背包中物品的总重量max?
-
-这个背包问题,物品不可分割,要么装要么不装,所以叫0-1背包,就无法通过贪心解决了。
-
-- 对于每个物品来说,都有两种选择,装 or 不装
-- 对于n个物品,就有 2ドル^n$ 种装法,去掉总重量超过Wkg的,从剩下的装法中选择总重量最接近Wkg的
-- 但如何才能不重复地穷举出这 2ドル^n$ 种装法?
-
-这就能回溯,把物品依次排列,整个问题分解为n个阶段,每个阶段对应一个物品怎么选择;
-- 先对第一个物品进行处理,选择装进去 or 不装进去
-- 再递归处理剩下物品
-
-搜索剪枝的技巧:当发现 已选择物品重量 > Wkg,就停止探测剩下物品。
-
-## 正则表达式
-假设正表达式中只包含`*`、`?`通配符且现在规定:
-- `*` 匹配任意多个(大于等于0个)任意字符
-- `?` 匹配0或1个任意字符
-
-如何用回溯算法,判断某给定文本,是否匹配给定的正则表达式?
-依次考察正则表达式中的每个字符,当是非通配符时,就直接跟文本的字符进行匹配:
-- 相同
-继续往下处理
-- 不同
-回溯
-
-遇到特殊字符时,就有多种处理方式,如`*`有多种匹配方案,可匹配任意个文本串中的字符,先随意选择一种匹配方案,然后继续考察剩下字符:
-- 若中途发现无法继续匹配,就回到岔路口,重新选择一种匹配方案,再继续匹配剩下字符。
-
-# 总结
-回溯算法思想很简单,大部分都是用来解决广义搜索问题:从一组可能解中,选出一个满足要求的解。
-
-回溯非常适合用递归实现,剪枝是提高回溯效率的一种技巧,无需穷举搜索所有情况。
-
-回溯算法可解决很多问题,如我们开头提到的深度优先搜索、八皇后、0-1背包问题、图的着色、旅行商问题、数独、全排列、正则表达式匹配等。
\ No newline at end of file
diff --git "a/346円225円260円346円215円256円347円273円223円346円236円204円344円270円216円347円256円227円346円263円225円/346円225円260円346円215円256円347円273円223円346円236円204円/345円246円202円344円275円225円350円256円276円350円256円241円345円255円230円345円202円250円347円244円276円344円272円244円345円271円263円345円217円260円345円245円275円345円217円213円345円205円263円347円263円273円347円232円204円346円225円260円346円215円256円347円273円223円346円236円204円.md" "b/346円225円260円346円215円256円347円273円223円346円236円204円344円270円216円347円256円227円346円263円225円/346円225円260円346円215円256円347円273円223円346円236円204円/345円246円202円344円275円225円350円256円276円350円256円241円345円255円230円345円202円250円347円244円276円344円272円244円345円271円263円345円217円260円345円245円275円345円217円213円345円205円263円347円263円273円347円232円204円346円225円260円346円215円256円347円273円223円346円236円204円.md"
deleted file mode 100644
index 7546256101..0000000000
--- "a/346円225円260円346円215円256円347円273円223円346円236円204円344円270円216円347円256円227円346円263円225円/346円225円260円346円215円256円347円273円223円346円236円204円/345円246円202円344円275円225円350円256円276円350円256円241円345円255円230円345円202円250円347円244円276円344円272円244円345円271円263円345円217円260円345円245円275円345円217円213円345円205円263円347円263円273円347円232円204円346円225円260円346円215円256円347円273円223円346円236円204円.md"
+++ /dev/null
@@ -1,118 +0,0 @@
-x博中,两个人可以互相关注,互加好友,那如何存储这些社交网络的好友关系呢?
-
-这就要用到:图。
-# 什么是"图"?(Graph)
-和树比起来,这是一种更加复杂的非线性表结构。
-
-树的元素称为节点,图中元素叫作顶点(vertex)。图中的一个顶点可以与任意其他顶点建立连接关系,这种建立的关系叫作边(edge)。
-
-社交网络就是典型的图结构。
-
-把每个用户看作一个顶点。如果两个用户之间互加好友,就在两者之间建立一条边。
-所以,整个微信的好友关系就可用一张图表示。
-每个用户有多少个好友,对应到图中就叫作顶点的度(degree),即跟顶点相连接的边的条数。
-
-不过微博的社交关系跟微信还有点不同,更复杂一点。微博允许单向关注,即用户A关注用户B,但B可不关注A。
-
-> 如何用图表示这种单向社交关系呢?
-
-这就引入边的"方向"。
-
-A关注B,就在图中画一条从A到B的带箭头的边,表示边的方向。A、B互关,就画一条从A指向B的边,再画一条从B指向A的边,这种边有方向的图叫作"有向图"。边没有方向的图也就叫"无向图"。
-
-无向图中有"度":一个顶点有多少条边。
-有向图中,把度分为:
-- 入度(In-degree)
-有多少条边指向这个顶点,即有多少粉丝
-- 出度(Out-degree)
-有多少条边是以这个顶点为起点指向其他顶点。对应到微博的例子,即关注了多少人
-
-QQ社交关系更复杂,不仅记录用户之间的好友关系,还记录了两个用户之间的亲密度,如何在图中记录这种好友关系亲密度呢?
-这就要用到带权图(weighted graph),每条边都有个权重(weight),可以通过这个权重来表示QQ好友间的亲密度。
-
-# 存储
-## 邻接矩阵存储方法
-最直观的一种存储方法,邻接矩阵(Adjacency Matrix)。
-
-依赖一个二维数组:
-- 无向图
-如果顶点i与顶点j之间有边,就将A[i][j]和A[j][i]标记为1
-- 有向图
-如果顶点i到顶点j之间,有一条箭头从顶点i指向顶点j的边,那我们就将A[i][j]标记为1
-如果有一条箭头从顶点j指向顶点i的边,我们就将A[j][i]标记为1
-- 带权图,数组中就存储相应的权重
-
-
-> 简单、直观,但比较浪费存储空间!
-
-无向图,若A[i][j]==1,则A[j][i]==1。实际上,只需存储一个即可。即无向图的二维数组,如果将其用对角线划分为上下两部分,则只需利用上或下面这样一半空间就够了,另外一半其实完全浪费。
-如果存储的是稀疏图(Sparse Matrix),即顶点很多,但每个顶点的边并不多,则更浪费空间。
-如微信有好几亿用户,对应到图就是好几亿顶点。但每个用户好友并不很多,一般也就三五百个而已。如果我们用邻接矩阵来存储,那绝大部分的存储空间都被浪费了。
-
-但这也并不是说,邻接矩阵的存储方法就完全没有优点。首先,邻接矩阵的存储方式简单、直接,因为基于数组,所以在获取两个顶点的关系时,就非常高效。其次,用邻接矩阵存储图的另外一个好处是方便计算。这是因为,用邻接矩阵的方式存储图,可以将很多图的运算转换成矩阵之间的运算。比如求解最短路径问题时会提到一个Floyd-Warshall算法,就是利用矩阵循环相乘若干次得到结果。
-## 邻接表存储方法
-针对上面邻接矩阵比较浪费内存空间,另外一种图存储,邻接表(Adjacency List)。
-
-有点像散列表?每个顶点对应一条链表,链表中存储的是与这个顶点相连接的其他顶点。图中画的是一个有向图的邻接表存储方式,每个顶点对应的链表里面,存储的是指向的顶点。对于无向图来说,也是类似的,不过,每个顶点的链表中存储的,是跟这个顶点有边相连的顶点,你可以自己画下。
-
-
-- 邻接矩阵存储较浪费空间,但更省时
-- 邻接表较节省存储空间,但较耗时
-
-如上图示例,若要确定是否存在一条从顶点2到顶点4的边,就要遍历顶点2的链表,看其中是否存在顶点4,而链表存储对缓存不友好。所以邻接表查询两个顶点之间的关系较为低效。
-
-基于链表法解决冲突的散列表中,若链过长,为提高查找效率,可将链表换成其他更高效数据结构,如平衡二叉查找树。
-邻接表长得很像散列。所以,也可将邻接表同散列表一样进行"优化"。
-
-可将邻接表中的链表改成平衡二叉查找树。实际可选用红黑树。即可更快速查找两个顶点之间是否存在边。
-这里的二叉查找树也可换成其他动态数据结构,如跳表、散列表。
-还可将链表改成有序动态数组,通过二分查找快速定位两个顶点之间是否存在边。
-# 如何存储微博、微信等社交网络中的好友关系?
-虽然微博有向图,微信是无向图,但对该问题,二者思路类似,以微博为例。
-
-数据结构服务于算法,选择哪种存储方法和需支持的操作有关。
-对于微博用户关系,需支持如下操作:
-- 判断用户A是否关注了用户B
-- 判断用户A是否是用户B的粉丝
-- 用户A关注用户B
-- 用户A取消关注用户B
-- 根据用户名称的首字母排序,分页获取用户的粉丝列表
-- 根据用户名称的首字母排序,分页获取用户的关注列表
-
-因为社交网络是一张稀疏图,使用邻接矩阵存储比较浪费存储空间。所以,这里采用邻接表。
-
-但一个邻接表存储这种有向图也是不够的。查找某用户关注了哪些用户很容易,但若想知道某用户都被哪些用户关注了,即粉丝列表就没法了。
-
-因此,还需一个逆邻接表,存储用户的被关注关系:
-- 邻接表,每个顶点的链表中,存储的就是该顶点指向的顶点
-查找某个用户关注了哪些用户
-- 逆邻接表,每个顶点的链表中,存储的是指向该顶点的顶点
-查找某个用户被哪些用户关注
-
-
-基础的邻接表不适合快速判断两个用户是否为关注与被关注关系,所以进行优化,将邻接表的链表改为支持快速查找的动态数据结构。
-
-> 那是红黑树、跳表、有序动态数组还是散列表呢?
-
-因需按照用户名称首字母排序,分页获取用户的粉丝列表或关注列表,跳表最合适:插入、删除、查找都非常高效,时间复杂度$O(logn),ドル空间复杂度稍高,是$O(n)$。
-跳表存储数据先天有序,分页获取粉丝列表或关注列表,非常高效。
-
-对小规模数据,如社交网络中只有几万、几十万个用户,可将整个社交关系存储在内存,该解决方案没问题。
-
-> 但像微博上亿用户,数据量太大,无法全部存储在内存,何解?
-
-可通过哈希算法等数据分片方案,将邻接表存储在不同机器:
-- 机器1存储顶点1,2,3的邻接表
-- 机器2存储顶点4,5的邻接表
-逆邻接表的处理方式同理。
-
-当要查询顶点与顶点关系时,利用同样的哈希算法,先定位顶点所在机器,然后再在相应机器上查找。
-
-
-还能借助外部存储(比如硬盘),因为外部存储的存储空间比内存多很多:
-如用下表存储这样一个图。为高效支持前面定义的操作,可建多个索引,比如第一列、第二列,给这两列都建立索引。
-
-
-> 参考
-> - https://chowdera.com/2021/03/20210326155939001z.html
-> - https://www.zhihu.com/question/20216864
\ No newline at end of file
diff --git "a/346円225円260円346円215円256円347円273円223円346円236円204円344円270円216円347円256円227円346円263円225円/350円216円267円345円217円226円Top 10345円276円256円345円215円232円347円203円255円346円220円234円345円205円263円351円224円256円350円257円215円357円274円237円.md" "b/346円225円260円346円215円256円347円273円223円346円236円204円344円270円216円347円256円227円346円263円225円/350円216円267円345円217円226円Top 10345円276円256円345円215円232円347円203円255円346円220円234円345円205円263円351円224円256円350円257円215円357円274円237円.md"
deleted file mode 100644
index 0c21f06f0a..0000000000
--- "a/346円225円260円346円215円256円347円273円223円346円236円204円344円270円216円347円256円227円346円263円225円/350円216円267円345円217円226円Top 10345円276円256円345円215円232円347円203円255円346円220円234円345円205円263円351円224円256円350円257円215円357円274円237円.md"
+++ /dev/null
@@ -1,178 +0,0 @@
-搜索引擎每天会接收大量的用户搜索请求,它会把这些用户输入的搜索关键词记录下来,然后再离线统计分析,得到最热门TopN搜索关键词。
-
-现在有一包含10亿个搜索关键词的日志文件,如何能快速获取到热门榜Top 10搜索关键词?
-可用堆解决,堆的几个应用:优先级队列、求Top K和求中位数。
-# 优先级队列
-首先应该是一个队列。队列最大的特性FIFO。 但优先级队列中,数据出队顺序是按优先级来,优先级最高的,最先出队。
-
-方法很多,但堆实现最直接、高效。因为堆和优先级队列很相似。一个堆即可看作一个优先级队列。很多时候,它们只是概念上的区分。
-- 往优先级队列中插入一个元素,就相当于往堆中插入一个元素
-- 从优先级队列中取出优先级最高的元素,就相当于取出堆顶元素
-
-优先级队列应用场景非常多:赫夫曼编码、图的最短路径、最小生成树算法等,Java的PriorityQueue。
-## 合并有序小文件
-- 有100个小文件
-- 每个文件100M
-- 每个文件存储有序字符串
-
-将这100个小文件合并成一个有序大文件,就用到优先级队列。
-像归排的合并函数。从这100个文件中,各取第一个字符串,放入数组,然后比较大小,把最小的那个字符串放入合并后的大文件中,并从数组中删除。
-
-假设,这最小字符串来自13.txt这个小文件,就再从该小文件取下一个字符串并放入数组,重新比较大小,并且选择最小的放入合并后的大文件,并且将它从数组中删除。依次类推,直到所有的文件中的数据都放入到大文件为止。
-
-用数组存储从小文件中取出的字符串。每次从数组取最小字符串,都需循环遍历整个数组,不高效,如何更高效呢?
-就要用到优先级队列,即堆:将从小文件中取出的字符串放入小顶堆,则堆顶元素就是优先级队列队首,即最小字符串。
-将这个字符串放入大文件,并将其从堆中删除。
-再从小文件中取出下一个字符串,放入到堆
-循环该 过程,即可将100个小文件中的数据依次放入大文件。
-
-删除堆顶数据、往堆插数据时间复杂度都是$O(logn),ドル该案例$n=100$。
-这不比原来数组存储高效多了?
-# 2 高性能定时器
-有一定时器,维护了很多定时任务,每个任务都设定了一个执行时间点。
-定时器每过一个单位时间(如1s),就扫描一遍任务,看是否有任务到达设定执行时间。若到达,则执行。
-
-显然这样每过1s就扫描一遍任务列表很低效:
-- 任务约定执行时间离当前时间可能还很久,这样很多次扫描其实都无意义
-- 每次都要扫描整个任务列表,若任务列表很大,就很耗时
-
-这时就该优先级队列上场了。按任务设定的执行时间,将这些任务存储在优先级队列,队首(即小顶堆的堆顶)存储最先执行的任务。
-
-这样,定时器就无需每隔1s就扫描一遍任务列表了。
-
-> $队首任务执行时间点 - 当前时间点相减 = 时间间隔T$
-
-T就是,从当前时间开始,需等待多久,才会有第一个任务要被执行。
-定时器就能设定在T秒后,再来执行任务。
-当前时间点 ~ $(T-1)s$ 时间段,定时器无需做任何事情。
-
-当Ts时间过去后,定时器取优先级队列中队首任务执行
-再计算新的队首任务执行时间点与当前时间点差值,将该值作为定时器执行下一个任务需等待时间。
-
-如此设计,定时器既不用间隔1s就轮询一次,也无需遍历整个任务列表,性能大大提高。
-# 利用堆求Top K
-求Top K的问题抽象成两类:
-## 静态数据集合
-数据集合事先确定,不会再变。
-
-可维护一个大小为K的小顶堆,顺序遍历数组,从数组中取数据与堆顶元素比较:
-- >堆顶
-删除堆顶,并将该元素插入堆
-- <堆顶
-do nothing,继续遍历数组
-
-等数组中的数据都遍历完,堆中数据就是Top K。
-
-遍历数组需要$O(n)$时间复杂度
-一次堆化操作需$O(logK)$时间复杂度
-所以最坏情况下,n个元素都入堆一次,所以时间复杂度就是$O(nlogK)$
-## 动态数据集合
-数据集合事先并不确定,有数据动态地加入到集合中,也就是求实时Top K。
-一个数据集合中有两个操作:
-- 添加数据
-- 询问当前TopK数据
-
-若每次询问Top K大数据,都基于当前数据重新计算,则时间复杂度$O(nlogK),ドルn表示当前数据的大小。
-其实可一直都维护一个K大小的小顶堆,当有数据被添加到集合,就拿它与堆顶元素对比:
-- >堆顶
-就把堆顶元素删除,并且将这个元素插入到堆中
-- <堆顶
-do nothing。无论何时需查询当前的前K大数据,都可以里立刻返回给他
-# 利用堆求中位数
-求**动态数据**集合中的中位数:
-- 数据个数奇数
-把数据从小到大排列,第$\frac{n}{2}+1$个数据就是中位数
-- 数据个数是偶数
-处于中间位置的数据有两个,第$\frac{n}{2}$个、第$\frac{n}{2}+1$个数据,可随意取一个作为中位数,比如取两个数中靠前的那个,即第$\frac{n}{2}$个数据
-
-一组静态数据的中位数是固定的,可先排序,第$\frac{n}{2}$个数据就是中位数。
-每次询问中位数,直接返回该固定值。所以,尽管排序的代价比较大,但是边际成本会很小。但是,如果我们面对的是动态数据集合,中位数在不停地变动,如果再用先排序的方法,每次询问中位数的时候,都要先进行排序,那效率就不高了。
-
-借助堆,不用排序,即可高效地实现求中位数操作:
-需维护两个堆:
-- 大顶堆
-存储前半部分数据
-- 小顶堆
-存储后半部分数据 && 小顶堆数据都 > 大顶堆数据
-
-即若有n(偶数)个数据,从小到大排序,则:
-- 前 $\frac{n}{2}$ 个数据存储在大顶堆
-- 后$\frac{n}{2}$个数据存储在小顶堆
-
-大顶堆中的堆顶元素就是我们要找的中位数。
-
-n是奇数也类似:
-- 大顶堆存储$\frac{n}{2}+1$个数据
-- 小顶堆中就存储$\frac{n}{2}$个数据
-
-数据动态变化,当新增一个数据时,如何调整两个堆,让大顶堆堆顶继续是中位数, 若:
-- 新加入的数据 ≤ 大顶堆堆顶,则将该新数据插到大顶堆
-- 新加入的数据大于等于小顶堆的堆顶元素,我们就将这个新数据插入到小顶堆。
-
-这时可能出现,两个堆中的数据个数不符合前面约定的情况,若:
-- n是偶数,两个堆中的数据个数都是 $\frac{n}{2}$
-- n是奇数,大顶堆有 $\frac{n}{2}+1$ 个数据,小顶堆有 $\frac{n}{2}$ 个数据
-
-即可从一个堆不停将堆顶数据移到另一个堆,以使得两个堆中的数据满足上面约定。
-
-插入数据涉及堆化,所以时间复杂度$O(logn),ドル但求中位数只需返回大顶堆堆顶,所以时间复杂度$O(1)$。
-
-利用两个堆还可快速求其他百分位的数据,原理类似。
-"如何快速求接口的99%响应时间?
-
-中位数≥前50%数据,类比中位数,若将一组数据从小到大排列,这个99百分位数就是大于前面99%数据的那个数据。
-
-假设有100个数据:1,2,3,......,100,则99百分位数就是99,因为≤99的数占总个数99%。
-
-> 那99%响应时间是啥呢?
-
-若有100个接口访问请求,每个接口请求的响应时间都不同,如55ms、100ms、23ms等,把这100个接口的响应时间按照从小到大排列,排在第99的那个数据就是99%响应时间,即99百分位响应时间。
-
-即若有n个数据,将数据从小到大排列后,99百分位数大约就是第n*99%个数据。
-维护两个堆,一个大顶堆,一个小顶堆。假设当前总数据的个数是n,大顶堆中保存n*99%个数据,小顶堆中保存n*1%个数据。大顶堆堆顶的数据就是我们要找的99%响应时间。
-
-每插入一个数据时,要判断该数据跟大顶堆、小顶堆堆顶的大小关系,以决定插入哪个堆:
-- 新插入数据 < 大顶堆的堆顶,插入大顶堆
-- 新插入的数据 > 小顶堆的堆顶,插入小顶堆
-
-但为保持大顶堆中的数据占99%,小顶堆中的数据占1%,每次新插入数据后,都要重新计算,这时大顶堆和小顶堆中的数据个数,是否还符合99:1:
-- 不符合,则将一个堆中的数据移动到另一个堆,直到满足比例
-移动的方法类似前面求中位数的方法
-
-如此,每次插入数据,可能涉及几个数据的堆化操作,所以时间复杂度$O(logn)$。
-每次求99%响应时间时,直接返回大顶堆中的堆顶即可,时间复杂度$O(1)$。
-# 含10亿个搜索关键词的日志文件,快速获取Top 10
-很多人肯定说使用MapReduce,但若将场景限定为单机,可使用内存为1GB,你咋办?
-
-用户搜索的关键词很多是重复的,所以首先要统计每个搜索关键词出现的频率。
-可通过散列表、平衡二叉查找树或其他一些支持快速查找、插入的数据结构,记录关键词及其出现次数。
-
-假设散列表。
-顺序扫描这10亿个搜索关键词。当扫描到某关键词,去散列表中查询:
-- 存在,对应次数加一
-- 不存在,插入散列表,并记录次数1
-
-等遍历完这10亿个搜索关键词后,散列表就存储了不重复的搜索关键词及出现次数。
-
-再根据堆求Top K方案,建立一个大小为10小顶堆,遍历散列表,依次取出每个搜索关键词及对应出现次数,然后与堆顶搜索关键词对比:
-- 出现次数 > 堆顶搜索关键词的次数
-删除堆顶关键词,将该出现次数更多的关键词入堆。
-
-以此类推,当遍历完整个散列表中的搜索关键词之后,堆中的搜索关键词就是出现次数最多的Top 10搜索关键词了。
-
-但其实有问题。10亿的关键词还是很多的。
-假设10亿条搜索关键词中不重复的有1亿条,如果每个搜索关键词的平均长度是50个字节,那存储1亿个关键词起码需要5G内存,而散列表因为要避免频繁冲突,不会选择太大的装载因子,所以消耗的内存空间就更多了。
-而机器只有1G可用内存,无法一次性将所有的搜索关键词加入内存。
-
-> 何解?
-
-因为相同数据经哈希算法后的哈希值相同,可将10亿条搜索关键词先通过哈希算法分片到10个文件:
-- 创建10个空文件:00~09
-- 遍历这10亿个关键词,并通过某哈希算法求哈希值
-- 哈希值同10取模,结果就是该搜索关键词应被分到的文件编号
-
-10亿关键词分片后,每个文件都只有1亿关键词,去掉重复的,可能就只剩1000万,每个关键词平均50个字节,总大小500M,1G内存足矣。
-
-针对每个包含1亿条搜索关键词的文件:
-- 利用散列表和堆,分别求Top 10
-- 10个Top 10放一起,取这100个关键词中,出现次数Top 10关键词,即得10亿数据的Top 10热搜关键词
\ No newline at end of file
diff --git "a/346円236円266円346円236円204円/345円210円206円345円270円203円345円274円217円345円276円256円346円234円215円345円212円241円/Dubbo/Dubbo347円232円204円SPI346円234円272円345円210円266円.md" "b/346円236円266円346円236円204円/345円210円206円345円270円203円345円274円217円345円276円256円346円234円215円345円212円241円/Dubbo/Dubbo SPI V.S JDK SPI.md"
similarity index 72%
rename from "346円236円266円346円236円204円/345円210円206円345円270円203円345円274円217円345円276円256円346円234円215円345円212円241円/Dubbo/Dubbo347円232円204円SPI346円234円272円345円210円266円.md"
rename to "346円236円266円346円236円204円/345円210円206円345円270円203円345円274円217円345円276円256円346円234円215円345円212円241円/Dubbo/Dubbo SPI V.S JDK SPI.md"
index 15237562fb..251c042766 100644
--- "a/346円236円266円346円236円204円/345円210円206円345円270円203円345円274円217円345円276円256円346円234円215円345円212円241円/Dubbo/Dubbo347円232円204円SPI346円234円272円345円210円266円.md"
+++ "b/346円236円266円346円236円204円/345円210円206円345円270円203円345円274円217円345円276円256円346円234円215円345円212円241円/Dubbo/Dubbo SPI V.S JDK SPI.md"
@@ -1,3 +1,33 @@
+# 1 简介
+SPI,Service Provider Interface,一种服务发现机制。
+
+比如某接口有3个实现类,那系统运行时,该接口到底选择哪个实现类呢?
+这就需要SPI,**根据指定或默认配置,找到对应实现类,加载进来,然后使用该实现类实例**。
+
+如下系统运行时,加载配置,用实现A2实例化一个对象来提供服务:
+
+
+再如,你要通过jar包给某个接口提供实现,就在自己jar包的`META-INF/services/`目录下放一个接口同名文件,指定接口的实现是自己这个jar包里的某类即可:
+
+别人用这个接口,然后用你的jar包,就会在运行时通过你的jar包指定文件找到这个接口该用哪个实现类。这是JDK内置提供的功能。
+
+假设你有个工程P,有个接口A,A在P无实现类,系统运行时怎么给A选实现类呢?
+可以自己搞个jar包,`META-INF/services/`,放上一个文件,文件名即接口名,接口A的实现类=`com.javaedge.service.实现类A2`。
+让P来依赖你的jar包,等系统运行时,P跑起来了,对于接口A,就会扫描依赖的jar包,看看有没有`META-INF/services`文件夹:
+- 有,再看看有无名为接口A的文件:
+ - 有,在里面查找指定的接口A的实现是你的jar包里的哪个类即可
+# 2 适用场景
+插件扩展。
+比如你开发了一个开源框架,若你想让别人自己写个插件,安排到你的开源框架里中,扩展功能时
+## 2.1 Java SPI
+如JDBC。Java定义了一套JDBC的接口,但并未提供具体实现类。
+
+> 但项目运行时,要使用JDBC接口的哪些实现类呢?
+
+一般要根据自己使用的数据库驱动jar包,比如我们最常用的MySQL,其`mysql-jdbc-connector.jar` 里面就有:
+
+系统运行时碰到你使用JDBC的接口,就会在底层使用你引入的那个jar中提供的实现类。
+## 2.2 Dubbo SPI
Dubbo 没使用 Java SPI,而重新实现了一套功能更强的 SPI。
Dubbo SPI 逻辑封装在 ExtensionLoader 类,通过 ExtensionLoader,可加载指定实现类。Dubbo SPI 所需配置文件需放置在 `META-INF/dubbo` 路径: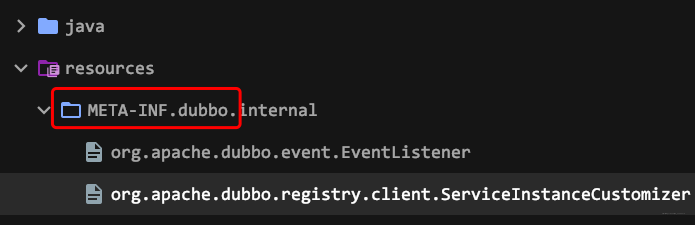
@@ -14,7 +44,7 @@ Dubbo要判断系统运行时,应该选用该Protocol接口的哪个实现类
微内核,可插拔,大量的组件,Protocol负责RPC调用的东西,你可以实现自己的RPC调用组件,实现Protocol接口,给自己的一个实现类即可。
这行代码就是Dubbo里大量使用的,对很多组件都保留一个接口和多个实现,然后在系统运行的时候动态根据配置去找到对应实现类。
若你没配置,那就走默认实现。
-# 实例
+### 2.2.1 实例
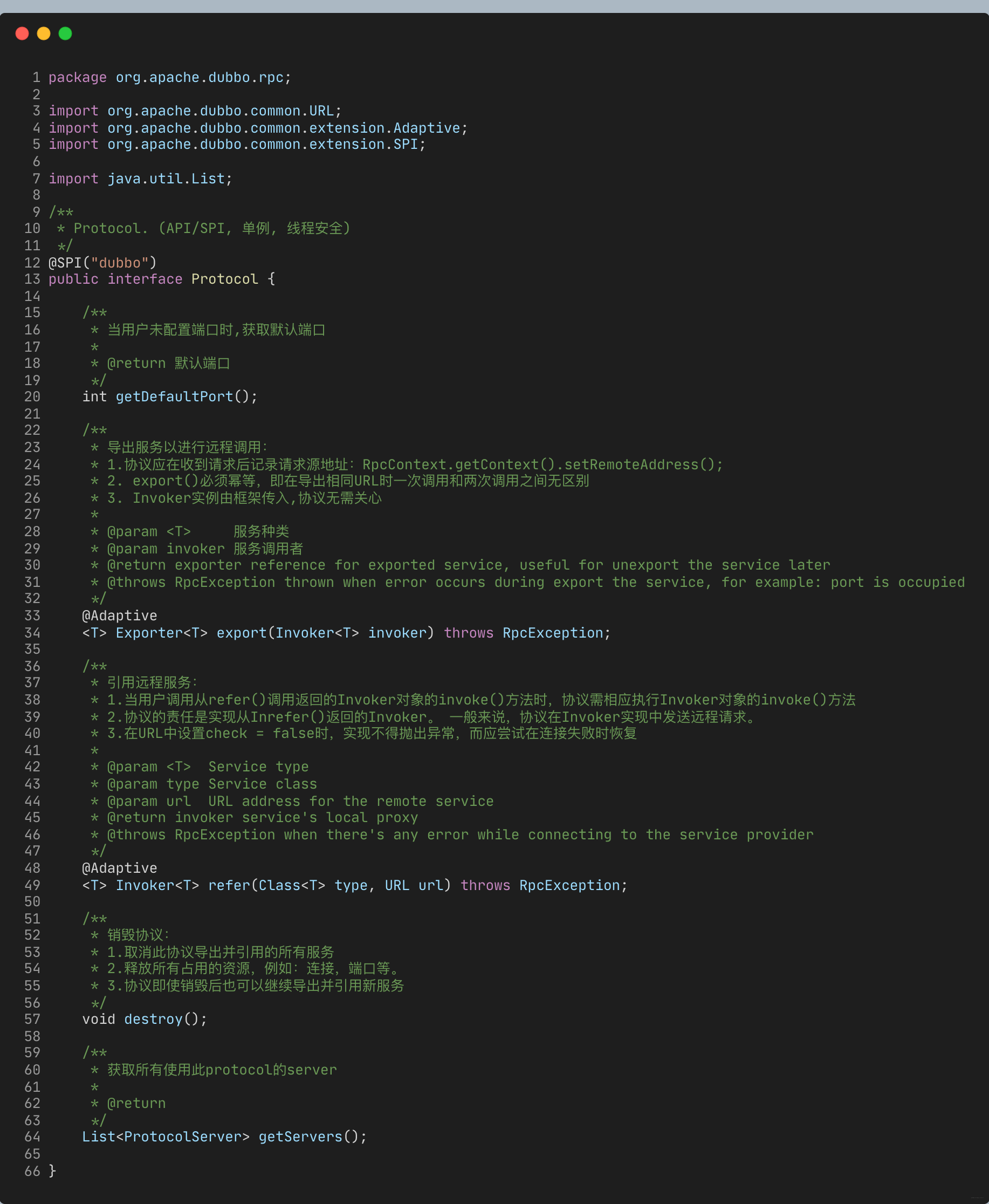
在Dubbo自己的jar里
在`/META_INF/dubbo/internal/com.alibaba.dubbo.rpc.Protocol`文件中:
@@ -27,7 +57,7 @@ Dubbo要判断系统运行时,应该选用该Protocol接口的哪个实现类
> Dubbo的默认网络通信协议,就是dubbo协议,用的DubboProtocol
> 在 Java 的 SPI 配置文件里每一行只有一个实现类的全限定名,在 Dubbo的 SPI配置文件中是 key=value 的形式,我们只需要对应的 key 就能加载对应的实现。
-# 源码
+### 源码
```java
/**
* 返回指定名字的扩展。如果指定名字的扩展不存在,则抛异常 {@link IllegalStateException}.
@@ -91,7 +121,7 @@ private T createExtension(String name) {
比如这个Protocol接口搞了俩`@Adaptive`注解了方法,在运行时会针对Protocol生成代理类,该代理类的那俩方法中会有代理代码,代理代码会在运行时动态根据url中的protocol来获取key(默认是dubbo),也可以自己指定,如果指定了别的key,那么就会获取别的实现类的实例。通过这个url中的参数不同,就可以控制动态使用不同的组件实现类
-# 扩展Dubbo组件
+# 3 扩展Dubbo组件
自己写个工程,可以打成jar包的那种哦
- 里面的`src/main/resources`目录下
- 搞一个`META-INF/services`
@@ -106,5 +136,6 @@ private T createExtension(String name) {
这个时候provider启动的时候,就会加载到我们jar包里的`my=com.javaedge.MyProtocol`这行配置,接着会根据你的配置使用你定义好的MyProtocol了,这个就是简单说明一下,你通过上述方式,可以替换掉大量的dubbo内部的组件,就是扔个你自己的jar包,然后配置一下即可~
- Dubbo的SPI原理图
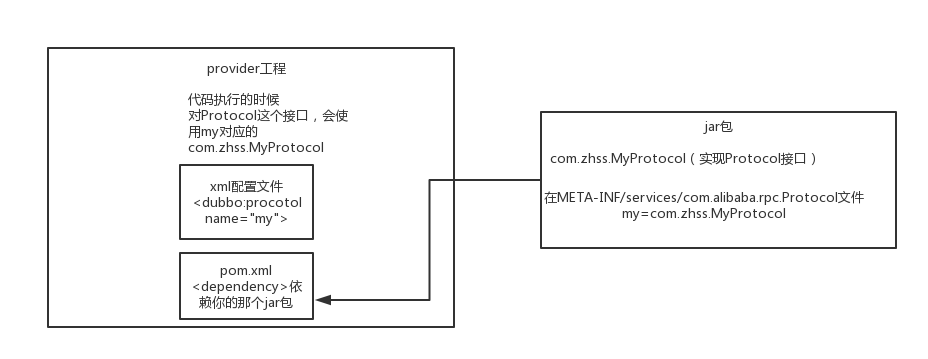
-Dubbo中提供了大量的类似上面的扩展点。
+
+Dubbo中提供了大量的类似上面的扩展点.
你要扩展一个东西,只需自己写个jar,让你的consumer或者是provider工程,依赖它,在你的jar里指定目录下配置好接口名称对应的文件,里面通过`key=实现类`然后对对应的组件,用类似`