You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
This script locates and downloads images from several subreddits (r/deepfriedmemes, r/surrealmemes, r/nukedmemes, r/bigbangedmemes, r/wackytictacs, r/bonehurtingjuice) into your local system.
4
+
5
+
For the sake of simplicity (and so that your system doesn't get stuffed full of images), the **download is limited to 25 (total) images per run**.
6
+
However, you are **welcome to modify that limit** to whatever amount you'd like or **remove it** altogether, but then make sure you **update `sg.ProgressBar()`** so it properly represents the download progress.
7
+
8
+
## Usage
9
+
10
+
Make sure you have installed the **necessary packages** listed in **`requirements.txt`**, then simply run **`script.py`**.
11
+
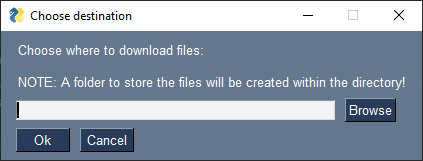
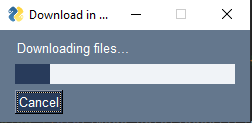
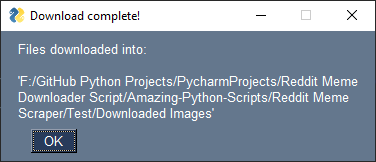
You'll be greeted by a popup window asking where to download the images, after which the download will commence.
12
+
13
+
## Screenshots
14
+
15
+
Some screenshots showing how the script works:
16
+
17
+
18
+
19
+
20
+
21
+
{kind=link}
{kind=link}
{kind=link}
{kind=link}
0 commit comments