| | 按位或运算符 | 只要对应的两个二进位有一个为 1ドル$ 时,结果位就为 1ドル$。 |
+| `^` | 按位异或运算符 | 对应的两个二进位相异时,结果位为 1ドル,ドル二进位相同时则结果位为 0ドル$。 |
+| `~` | 取反运算符 | 对二进制数的每个二进位取反,使数字 1ドル$ 变为 0ドル,ドル0ドル$ 变为 1ドル$。 |
+| `<<` | 左移运算符 | 将二进制数的各个二进位全部左移若干位。`<<` 右侧数字指定了移动位数,高位丢弃,低位补 0ドル$。 | +| `>>` | 右移运算符 | 对二进制数的各个二进位全部右移若干位。`>>` 右侧数字指定了移动位数,低位丢弃,高位补 0ドル$。 |
### 2.1 按位与运算
@@ -265,23 +265,23 @@ class Solution:
那么我们就可以用一个长度为 $n$ 的二进制数来表示集合 $S$ 或者表示 $S$ 的子集。其中二进制的每一个二进位都对应了集合中某一个元素的选取状态。对于集合中第 $i$ 个元素来说,二进制对应位置上的 1ドル$ 代表该元素被选取,0ドル$ 代表该元素未被选取。
-举个例子,比如长度为 5ドル$ 的集合 $S = \left \{ 5, 4, 3, 2, 1 \right \},ドル我们可以用一个长度为 5ドル$ 的二进制数来表示该集合。
+举个例子,比如长度为 5ドル$ 的集合 $S = \lbrace 5, 4, 3, 2, 1 \rbrace,ドル我们可以用一个长度为 5ドル$ 的二进制数来表示该集合。
-比如二进制数 11111ドル_{(2)}$ 就表示选取集合的第 1ドル$ 位、第 2ドル$ 位、第 3ドル$ 位、第 4ドル$ 位、第 5ドル$ 位元素,也就是集合 $\left \{ 5, 4, 3, 2, 1 \right \},ドル即集合 $S$ 本身。如下表所示:
+比如二进制数 11111ドル_{(2)}$ 就表示选取集合的第 1ドル$ 位、第 2ドル$ 位、第 3ドル$ 位、第 4ドル$ 位、第 5ドル$ 位元素,也就是集合 $\lbrace 5, 4, 3, 2, 1 \rbrace,ドル即集合 $S$ 本身。如下表所示:
| 集合 S 中元素位置 | 5 | 4 | 3 | 2 | 1 |
| :---------------- | :--: | :--: | :--: | :--: | :--: |
| 二进位对应值 | 1 | 1 | 1 | 1 | 1 |
| 对应选取状态 | 选取 | 选取 | 选取 | 选取 | 选取 |
-再比如二进制数 10101ドル_{(2)}$ 就表示选取集合的第 1ドル$ 位、第 3ドル$ 位、第 5ドル$ 位元素,也就是集合 $\left \{5, 3, 1 \right \}$。如下表所示:
+再比如二进制数 10101ドル_{(2)}$ 就表示选取集合的第 1ドル$ 位、第 3ドル$ 位、第 5ドル$ 位元素,也就是集合 $\lbrace 5, 3, 1 \rbrace$。如下表所示:
| 集合 S 中元素位置 | 5 | 4 | 3 | 2 | 1 |
| :---------------- | :--: | :----: | :--: | :----: | :--: |
| 二进位对应值 | 1 | 0 | 1 | 0 | 1 |
| 对应选取状态 | 选取 | 未选取 | 选取 | 未选取 | 选取 |
-再比如二进制数 01001ドル_{(2)}$ 就表示选取集合的第 1ドル$ 位、第 4ドル$ 位元素,也就是集合 $\left \{4, 1 \right \}$。如下标所示:
+再比如二进制数 01001ドル_{(2)}$ 就表示选取集合的第 1ドル$ 位、第 4ドル$ 位元素,也就是集合 $\lbrace 4, 1 \rbrace$。如下标所示:
| 集合 S 中元素位置 | 5 | 4 | 3 | 2 | 1 |
| :---------------- | :----: | :--: | :----: | :----: | :--: |
diff --git a/Contents/10.Dynamic-Programming/01.Dynamic-Programming-Basic/01.Dynamic-Programming-Basic.md b/Contents/10.Dynamic-Programming/01.Dynamic-Programming-Basic/01.Dynamic-Programming-Basic.md
index c85bf0a0..9d06b290 100644
--- a/Contents/10.Dynamic-Programming/01.Dynamic-Programming-Basic/01.Dynamic-Programming-Basic.md
+++ b/Contents/10.Dynamic-Programming/01.Dynamic-Programming-Basic/01.Dynamic-Programming-Basic.md
@@ -2,26 +2,80 @@
### 1.1 动态规划的定义
-> **动态规划(Dynamic Programming)**:简称 **DP**,是一种通过把原问题分解为相对简单的子问题的方式而求解复杂问题的方法。
+> **动态规划(Dynamic Programming)**:简称 **DP**,是一种求解多阶段决策过程最优化问题的方法。在动态规划中,通过把原问题分解为相对简单的子问题,先求解子问题,再由子问题的解而得到原问题的解。
-动态规划最早由理查德 · 贝尔曼于 1957 年在其著作「动态规划(Dynamic Programming)」一书中提出。这里的 Programming 并不是编程的意思,而是指一种表格处理方法,即将每一步计算的结果存储在表格中,供随后的计算查询使用。
+动态规划最早由理查德 · 贝尔曼于 1957 年在其著作「动态规划(Dynamic Programming)」一书中提出。这里的 Programming 并不是编程的意思,而是指一种「表格处理方法」,即将每一步计算的结果存储在表格中,供随后的计算查询使用。
-动态规划方法与分治算法类似,却又不同于分治算法。
+### 1.2 动态规划的核心思想
-「动态规划的核心思想」是:
+> **动态规划的核心思想**:
+>
+> 1. 把「原问题」分解为「若干个重叠的子问题」,每个子问题的求解过程都构成一个 **「阶段」**。在完成一个阶段的计算之后,动态规划方法才会执行下一个阶段的计算。
+> 2. 在求解子问题的过程中,按照「自顶向下的记忆化搜索方法」或者「自底向上的递推方法」求解出「子问题的解」,把结果存储在表格中,当需要再次求解此子问题时,直接从表格中查询该子问题的解,从而避免了大量的重复计算。
-1. 把「原问题」分解为「若干个重叠的子问题」,每个子问题的求解过程都构成一个 **「阶段」**。在完成一个阶段的计算之后,动态规划方法才会执行下一个阶段的计算。
-2. 在求解子问题的过程中,按照自底向上的顺序求解出「子问题的解」,把结果存储在表格中,当需要再次求解此子问题时,直接从表格中查询该子问题的解,从而避免了大量的重复计算。
+这看起来很像是分治算法,但动态规划与分治算法的不同点在于:
-「动态规划方法与分治算法的不同点」在于:适用于动态规划求解的问题,在分解之后得到的子问题往往是相互联系的,会出现若干个重叠子问题。使用动态规划方法会将这些重叠子问题的解保存到表格里,供随后的计算查询使用,从而避免大量的重复计算。
+1. 适用于动态规划求解的问题,在分解之后得到的子问题往往是相互联系的,会出现若干个重叠子问题。
+2. 使用动态规划方法会将这些重叠子问题的解保存到表格里,供随后的计算查询使用,从而避免大量的重复计算。
-### 1.2 动态规划的特征
+### 1.3 动态规划的简单例子
-能够使用动态规划方法解决的问题必须满足下面三个特征:「最优子结构性质」、「重叠子问题性质」和「无后效性」。
+下面我们先来通过一个简单的例子来介绍一下什么是动态规划算法,然后再来讲解动态规划中的各种术语。
-#### 1.2.1 最优子结构性质
+> **斐波那契数列**:数列由 $f(0) = 1,f(1) = 2$ 开始,后面的每一项数字都是前面两项数字的和。也就是:
+>
+> $f(n) = \begin{cases} 0 & n = 0 \cr 1 & n = 1 \cr f(n - 2) + f(n - 1) & n> 1 \end{cases}$
-「最优子结构」:指的是一个问题的最优解包含其子问题的最优解。
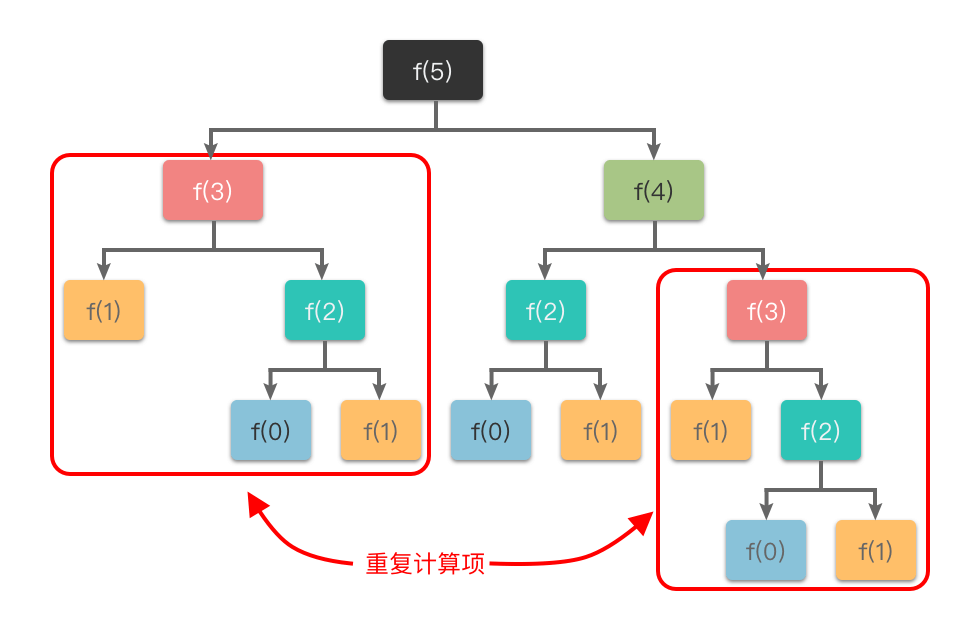
+通过公式 $f(n) = f(n - 2) + f(n - 1),ドル我们可以将原问题 $f(n)$ 递归地划分为 $f(n - 2)$ 和 $f(n - 1)$ 这两个子问题。其对应的递归过程如下图所示:
+
+
+
+从图中可以看出:如果使用传统递归算法计算 $f(5),ドル需要先计算 $f(3)$ 和 $f(4),ドル而在计算 $f(4)$ 时还需要计算 $f(3),ドル这样 $f(3)$ 就进行了多次计算。同理 $f(0)$、$f(1)$、$f(2)$ 都进行了多次计算,从而导致了重复计算问题。
+
+为了避免重复计算,我们可以使用动态规划中的「表格处理方法」来处理。
+
+这里我们使用「自底向上的递推方法」求解出子问题 $f(n - 2)$ 和 $f(n - 1)$ 的解,然后把结果存储在表格中,供随后的计算查询使用。具体过程如下:
+
+1. 定义一个数组 $dp,ドル用于记录斐波那契数列中的值。
+2. 初始化 $dp[0] = 0,dp[1] = 1$。
+3. 根据斐波那契数列的递推公式 $f(n) = f(n - 1) + f(n - 2),ドル从 $dp(2)$ 开始递推计算斐波那契数列的每个数,直到计算出 $dp(n)$。
+4. 最后返回 $dp(n)$ 即可得到第 $n$ 项斐波那契数。
+
+具体代码如下:
+
+```Python
+class Solution:
+ def fib(self, n: int) -> int:
+ if n == 0:
+ return 0
+ if n == 1:
+ return 1
+
+ dp = [0 for _ in range(n + 1)]
+ dp[0] = 0
+ dp[1] = 1
+
+ for i in range(2, n + 1):
+ dp[i] = dp[i - 2] + dp[i - 1]
+
+ return dp[n]
+```
+
+这种使用缓存(哈希表、集合或数组)保存计算结果,从而避免子问题重复计算的方法,就是「动态规划算法」。
+
+## 2. 动态规划的特征
+
+究竟什么样的问题才可以使用动态规划算法解决呢?
+
+首先,能够使用动态规划方法解决的问题必须满足以下三个特征:
+
+1. **最优子结构性质**
+2. **重叠子问题性质**
+3. **无后效性**
+
+### 2.1 最优子结构性质
+
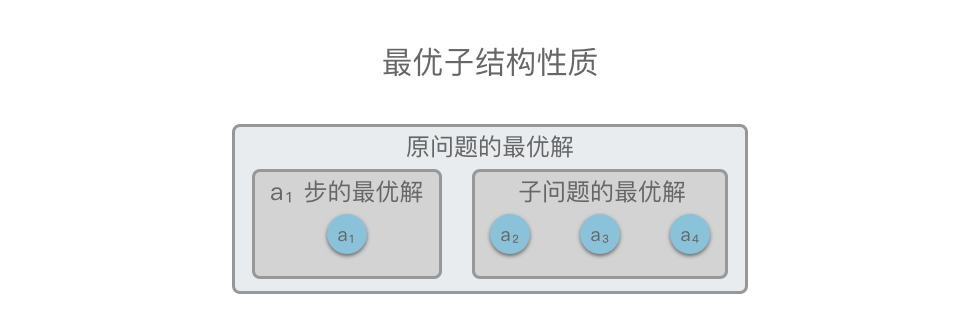
+> **最优子结构**:指的是一个问题的最优解包含其子问题的最优解。
举个例子,如下图所示,原问题 $S = \lbrace a_1, a_2, a_3, a_4 \rbrace,ドル在 $a_1$ 步我们选出一个当前最优解之后,问题就转换为求解子问题 $S_{子问题} = \lbrace a_2, a_3, a_4 \rbrace$。如果原问题 $S$ 的最优解可以由「第 $a_1$ 步得到的局部最优解」和「 $S_{子问题}$ 的最优解」构成,则说明该问题满足最优子结构性质。
@@ -29,33 +83,37 @@
-#### 1.2.2 重叠子问题性质
+### 2.2 重叠子问题性质
+
+> **重叠子问题性质**:指的是在求解子问题的过程中,有大量的子问题是重复的,一个子问题在下一阶段的决策中可能会被多次用到。如果有大量重复的子问题,那么只需要对其求解一次,然后用表格将结果存储下来,以后使用时可以直接查询,不需要再次求解。
+
+
-「重叠子问题性质」:指的是在求解子问题的过程中,有大量的子问题是重复的,一个子问题会在下一阶段的决策中可能会被多次用到。如果有大量重复的子问题,那么只需要对求解一次,然后用表格将结果存储下来,以后使用时可以直接查询,不需要再次求解。
+之前我们提到的「斐波那契数列」例子中,$f(0)$、$f(1)$、$f(2)$、$f(3)$ 都进行了多次重复计算。动态规划算法利用了子问题重叠的性质,在第一次计算 $f(0)$、$f(1)$、$f(2)$、$f(3)$ 时就将其结果存入表格,当再次使用时可以直接查询,无需再次求解,从而提升效率。
-举个例子,比如斐波那契数列的定义是:`f(1) = 1, f(2) = 2, f(n) = f(n - 1) + f(n - 2)`。对应的递推过程如下图所示,其中 `f(1)`、`f(2)`、`f(3)`、`f(4)` 都进行了多次重复计算。而如果我们在第一次计算 `f(1)`、`f(2)`、`f(3)`、`f(4)` 时就将其结果存入表格,则再次使用时可以直接查询,从而避免重复求解相同的子问题,提升效率。
+### 2.3 无后效性
-
+> **无后效性**:指的是子问题的解(状态值)只与之前阶段有关,而与后面阶段无关。当前阶段的若干状态值一旦确定,就不再改变,不会再受到后续阶段决策的影响。
-#### 1.2.3 无后效性
+也就是说,**一旦某一个子问题的求解结果确定以后,就不会再被修改**。
-「无后效性」:指的是子问题的解(状态值)只与之前阶段有关,而与后面阶段无关。当前阶段的若干状态值一旦确定,就不再改变,不会再受到后续阶段决策的影响。换句话说,**一旦某一个子问题的求解结果确定以后,就不会再被修改**。
+举个例子,下图是一个有向无环带权图,我们在求解从 $A$ 点到 $F$ 点的最短路径问题时,假设当前已知从 $A$ 点到 $D$ 点的最短路径(2ドル + 7 = 11$)。那么无论之后的路径如何选择,都不会影响之前从 $A$ 点到 $D$ 点的最短路径长度。这就是「无后效性」。
-其实我们也可以把动态规划方法的求解过程,看做是有向无环图的最长(最短)路的求解过程。每个状态对应有向无环图上的一个节点,决策对应图中的一条有向边。
+而如果一个问题具有「后效性」,则可能需要先将其转化或者逆向求解来消除后效性,然后才可以使用动态规划算法。
-如果一个问题具有「后效性」,则可能需要将其转化或者逆向求解来消除后效性,然后才可以使用动态规划方法。
+
-## 2. 动态规划的基本思路
+## 3. 动态规划的基本思路
如下图所示,我们在使用动态规划方法解决某些最优化问题时,可以将解决问题的过程按照一定顺序(时间顺序、空间顺序或其他顺序)分解为若干个相互联系的「阶段」。然后按照顺序对每一个阶段做出「决策」,这个决策既决定了本阶段的效益,也决定了下一阶段的初始状态。依次做完每个阶段的决策之后,就得到了一个整个问题的决策序列。
-这样就将一个原问题分解为了一系列的子问题,然后通过逐步求解从而获得最终结果。
+这样就将一个原问题分解为了一系列的子问题,再通过逐步求解从而获得最终结果。
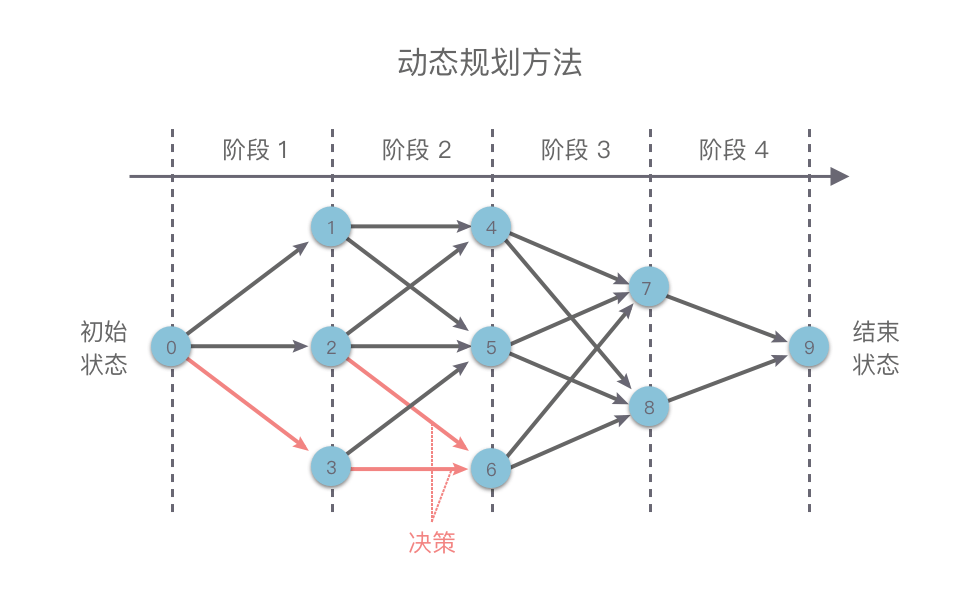
这种前后关联、具有链状结构的多阶段进行决策的问题也叫做「多阶段决策问题」。
-通常我们使用动态规划方法来解决多阶段决策问题,其基本思路如下:
+通常我们使用动态规划方法来解决问题的基本思路如下:
1. **划分阶段**:将原问题按顺序(时间顺序、空间顺序或其他顺序)分解为若干个相互联系的「阶段」。划分后的阶段一定是有序或可排序的,否则问题无法求解。
- 这里的「阶段」指的是子问题的求解过程。每个子问题的求解过程都构成一个「阶段」,在完成前一阶段的求解后才会进行后一阶段的求解。
@@ -65,7 +123,7 @@
4. **初始条件和边界条件**:根据问题描述、状态定义和状态转移方程,确定初始条件和边界条件。
5. **最终结果**:确定问题的求解目标,然后按照一定顺序求解每一个阶段的问题。最后根据状态转移方程的递推结果,确定最终结果。
-## 3. 动态规划的应用
+## 4. 动态规划的应用
动态规划相关的问题往往灵活多变,思维难度大,没有特别明显的套路,并且经常会在各类算法竞赛和面试中出现。
@@ -73,56 +131,66 @@
下面来介绍几道关于动态规划的基础题目。
-### 3.1 斐波那契数
+### 4.1 斐波那契数
-#### 3.1.1 题目链接
+#### 4.1.1 题目链接
- [509. 斐波那契数 - 力扣](https://leetcode.cn/problems/fibonacci-number/)
-#### 3.1.2 题目大意
+#### 4.1.2 题目大意
-**描述**:给定一个整数 `n`。
+**描述**:给定一个整数 $n$。
-**要求**:计算第 `n` 个斐波那契数。
+**要求**:计算第 $n$ 个斐波那契数。
**说明**:
- 斐波那契数列的定义如下:
- - `f(0) = 0, f(1) = 1`。
- - `f(n) = f(n - 1) + f(n - 2)`,其中 `n> 1`。
-
+ - $f(0) = 0, f(1) = 1$。
+ - $f(n) = f(n - 1) + f(n - 2),ドル其中 $n> 1$。
+- 0ドル \le n \le 30$。
**示例**:
+- 示例 1:
+
+```Python
+输入:n = 2
+输出:1
+解释:F(2) = F(1) + F(0) = 1 + 0 = 1
+```
+
+- 示例 2:
+
```Python
-输入 n = 2
-输出 1
-解释 F(2) = F(1) + F(0) = 1 + 0 = 1
+输入:n = 3
+输出:2
+解释:F(3) = F(2) + F(1) = 1 + 1 = 2
```
-#### 3.1.3 解题思路
+#### 4.1.3 解题思路
###### 1. 划分阶段
-我们可以按照整数顺序进行阶段划分,将其划分为整数 `0` ~ `n`。
+我们可以按照整数顺序进行阶段划分,将其划分为整数 0ドル \sim n$。
###### 2. 定义状态
-定义状态 `dp[i]` 为:第 `i` 个斐波那契数。
+定义状态 $dp[i]$ 为:第 $i$ 个斐波那契数。
###### 3. 状态转移方程
-根据题目中所给的斐波那契数列的定义 `f(n) = f(n - 1) + f(n - 2)`,则直接得出状态转移方程为 `dp[i] = dp[i - 1] + dp[i - 2]`。
+根据题目中所给的斐波那契数列的定义 $f(n) = f(n - 1) + f(n - 2),ドル则直接得出状态转移方程为 $dp[i] = dp[i - 1] + dp[i - 2]$。
###### 4. 初始条件
-根据题目中所给的初始条件 `f(0) = 0, f(1) = 1` 确定动态规划的初始条件,即 `dp[0] = 0, dp[1] = 1`。
+根据题目中所给的初始条件 $f(0) = 0, f(1) = 1$ 确定动态规划的初始条件,即 $dp[0] = 0, dp[1] = 1$。
###### 5. 最终结果
-根据状态定义,最终结果为 `dp[n]`,即第 `n` 个斐波那契数为 `dp[n]`。
+根据状态定义,最终结果为 $dp[n],ドル即第 $n$ 个斐波那契数为 $dp[n]$。
-#### 3.1.4 代码
+#### 4.1.4 代码
```Python
class Solution:
@@ -139,20 +207,20 @@ class Solution:
return dp[n]
```
-#### 3.1.5 复杂度分析
+#### 4.1.5 复杂度分析
- **时间复杂度**:$O(n)$。一重循环遍历的时间复杂度为 $O(n)$。
-- **空间复杂度**:$O(n)$。用到了一维数组保存状态,所以总体空间复杂度为 $O(n)$。因为 `dp[i]` 的状态只依赖于 `dp[i - 1]` 和 `dp[i - 2]`,所以可以使用 `3` 个变量来分别表示 `dp[i]`、`dp[i - 1]`、`dp[i - 2]`,从而将空间复杂度优化到 $O(1)$。
+- **空间复杂度**:$O(n)$。用到了一维数组保存状态,所以总体空间复杂度为 $O(n)$。
-### 3.2 爬楼梯
+### 4.2 爬楼梯
-#### 3.2.1 题目链接
+#### 4.2.1 题目链接
- [70. 爬楼梯 - 力扣](https://leetcode.cn/problems/climbing-stairs/)
-#### 3.2.2 题目大意
+#### 4.2.2 题目大意
-**描述**:假设你正在爬楼梯。需要 `n` 阶你才能到达楼顶。每次你可以爬 `1` 或 `2` 个台阶。现在给定一个整数 `n`。
+**描述**:假设你正在爬楼梯。需要 $n$ 阶你才能到达楼顶。每次你可以爬 1ドル$ 或 2ドル$ 个台阶。现在给定一个整数 $n$。
**要求**:计算出有多少种不同的方法可以爬到楼顶。
@@ -162,42 +230,54 @@ class Solution:
**示例**:
+- 示例 1:
+
+```Python
+输入:n = 2
+输出:2
+解释:有两种方法可以爬到楼顶。
+1. 1 阶 + 1 阶
+2. 2 阶
+```
+
+- 示例 2:
+
```Python
-输入 n = 3
-输出 3
-解释 有三种方法可以爬到楼顶。
+输入:n = 3
+输出:3
+解释:有三种方法可以爬到楼顶。
1. 1 阶 + 1 阶 + 1 阶
2. 1 阶 + 2 阶
3. 2 阶 + 1 阶
```
-#### 3.2.3 解题思路
+#### 4.2.3 解题思路
###### 1. 划分阶段
-我们按照台阶的阶层划分阶段,将其划分为 `0` ~ `n` 阶。
+我们按照台阶的阶层划分阶段,将其划分为 0ドル \sim n$ 阶。
###### 2. 定义状态
-定义状态 `dp[i]` 为:爬到第 `i` 阶台阶的方案数。
+定义状态 $dp[i]$ 为:爬到第 $i$ 阶台阶的方案数。
###### 3. 状态转移方程
-根据题目大意,每次只能爬 `1` 或 `2` 个台阶。则第 `i` 阶楼梯只能从第 `i - 1` 阶向上爬 `1`阶上来,或者从第 `i - 2` 阶向上爬 `2` 阶上来。所以可以推出状态转移方程为 `dp[i] = dp[i - 1] + dp[i - 2]`。
+根据题目大意,每次只能爬 1ドル$ 或 2ドル$ 个台阶。则第 $i$ 阶楼梯只能从第 $i - 1$ 阶向上爬 1ドル$ 阶上来,或者从第 $i - 2$ 阶向上爬 2ドル$ 阶上来。所以可以推出状态转移方程为 $dp[i] = dp[i - 1] + dp[i - 2]$。
###### 4. 初始条件
-- 第 `0` 层台阶方案数:可以看做 `1` 种方法(从 `0` 阶向上爬 `0` 阶),即 `dp[1] = 1`。
-- 第 `1` 层台阶方案数:`1` 种方法(从 `0` 阶向上爬 `1` 阶),即 `dp[1] = 1`。
-- 第 `2` 层台阶方案数:`2` 中方法(从 `0` 阶向上爬 `2` 阶,或者从 `1` 阶向上爬 `1` 阶)。
+- 第 0ドル$ 层台阶方案数:可以看做 1ドル$ 种方法(从 0ドル$ 阶向上爬 0ドル$ 阶),即 $dp[1] = 1$。
+- 第 1ドル$ 层台阶方案数:1ドル$ 种方法(从 0ドル$ 阶向上爬 1ドル$ 阶),即 $dp[1] = 1$。
+- 第 2ドル$ 层台阶方案数:2ドル$ 中方法(从 0ドル$ 阶向上爬 2ドル$ 阶,或者从 1ドル$ 阶向上爬 1ドル$ 阶)。
###### 5. 最终结果
-根据状态定义,最终结果为 `dp[n]`,即爬到第 `n` 阶台阶(即楼顶)的方案数为 `dp[n]`。
+根据状态定义,最终结果为 $dp[n],ドル即爬到第 $n$ 阶台阶(即楼顶)的方案数为 $dp[n]$。
-虽然这道题跟上一道题的状态转移方程都是 `dp[i] = dp[i - 1] + dp[i - 2]`,但是两道题的考察方式并不相同,一定程度上也可以看出来动态规划相关题目的灵活多变。
+虽然这道题跟上一道题的状态转移方程都是 $dp[i] = dp[i - 1] + dp[i - 2],ドル但是两道题的考察方式并不相同,一定程度上也可以看出来动态规划相关题目的灵活多变。
-#### 3.2.4 代码
+#### 4.2.4 代码
```Python
class Solution:
@@ -211,20 +291,20 @@ class Solution:
return dp[n]
```
-#### 3.2.5 复杂度分析
+#### 4.2.5 复杂度分析
- **时间复杂度**:$O(n)$。一重循环遍历的时间复杂度为 $O(n)$。
-- **空间复杂度**:$O(n)$。用到了一维数组保存状态,所以总体空间复杂度为 $O(n)$。因为 `dp[i]` 的状态只依赖于 `dp[i - 1]` 和 `dp[i - 2]`,所以可以使用 `3` 个变量来分别表示 `dp[i]`、`dp[i - 1]`、`dp[i - 2]`,从而将空间复杂度优化到 $O(1)$。
+- **空间复杂度**:$O(n)$。用到了一维数组保存状态,所以总体空间复杂度为 $O(n)$。因为 $dp[i]$ 的状态只依赖于 $dp[i - 1]$ 和 $dp[i - 2],ドル所以可以使用 3ドル$ 个变量来分别表示 $dp[i]$、$dp[i - 1]$、$dp[i - 2],ドル从而将空间复杂度优化到 $O(1)$。
-### 3.3 不同路径
+### 4.3 不同路径
-#### 3.3.1 题目链接
+#### 4.3.1 题目链接
- [62. 不同路径 - 力扣](https://leetcode.cn/problems/unique-paths/)
-#### 3.3.2 题目大意
+#### 4.3.2 题目大意
-**描述**:给定两个整数 `m` 和 `n`,代表大小为 `m * n` 的棋盘, 一个机器人位于棋盘左上角的位置,机器人每次只能向右、或者向下移动一步。
+**描述**:给定两个整数 $m$ 和 $n,ドル代表大小为 $m \times n$ 的棋盘, 一个机器人位于棋盘左上角的位置,机器人每次只能向右、或者向下移动一步。
**要求**:计算出机器人从棋盘左上角到达棋盘右下角一共有多少条不同的路径。
@@ -235,14 +315,28 @@ class Solution:
**示例**:
+- 示例 1:
+
+```Python
+输入:m = 3, n = 7
+输出:28
+```
+
+- 示例 2:
+
```Python
-输入 m = 3, n = 7
-输出 28
+输入:m = 3, n = 2
+输出:3
+解释:
+从左上角开始,总共有 3 条路径可以到达右下角。
+1. 向右 -> 向下 -> 向下
+2. 向下 -> 向下 -> 向右
+3. 向下 -> 向右 -> 向下
```
-#### 3.3.3 解题思路
+#### 4.3.3 解题思路
###### 1. 划分阶段
@@ -250,23 +344,23 @@ class Solution:
###### 2. 定义状态
-定义状态 `dp[i][j]` 为:从左上角到达 `(i, j)` 位置的路径数量。
+定义状态 $dp[i][j]$ 为:从左上角到达 $(i, j)$ 位置的路径数量。
###### 3. 状态转移方程
-因为我们每次只能向右、或者向下移动一步,因此想要走到 `(i, j)`,只能从 `(i - 1, j)` 向下走一步走过来;或者从 `(i, j - 1)` 向右走一步走过来。所以可以写出状态转移方程为:`dp[i][j] = dp[i - 1][j] + dp[i][j - 1]`,此时 `i> 0,j> 0`。
+因为我们每次只能向右、或者向下移动一步,因此想要走到 $(i, j),ドル只能从 $(i - 1, j)$ 向下走一步走过来;或者从 $(i, j - 1)$ 向右走一步走过来。所以可以写出状态转移方程为:$dp[i][j] = dp[i - 1][j] + dp[i][j - 1],ドル此时 $i> 0,j> 0$。
###### 4. 初始条件
-- 从左上角走到 `(0, 0)` 只有一种方法,即 `dp[0][0] = 1`。
-- 第一行元素只有一条路径(即只能通过前一个元素向右走得到),所以 `dp[0][j] = 1`。
-- 同理,第一列元素只有一条路径(即只能通过前一个元素向下走得到),所以 `dp[i][0] = 1`。
+- 从左上角走到 $(0, 0)$ 只有一种方法,即 $dp[0][0] = 1$。
+- 第一行元素只有一条路径(即只能通过前一个元素向右走得到),所以 $dp[0][j] = 1$。
+- 同理,第一列元素只有一条路径(即只能通过前一个元素向下走得到),所以 $dp[i][0] = 1$。
###### 5. 最终结果
-根据状态定义,最终结果为 `dp[m - 1][n - 1]`,即从左上角到达右下角 `(m - 1, n - 1)` 位置的路径数量为 `dp[m - 1][n - 1]`。
+根据状态定义,最终结果为 $dp[m - 1][n - 1],ドル即从左上角到达右下角 $(m - 1, n - 1)$ 位置的路径数量为 $dp[m - 1][n - 1]$。
-#### 3.3.4 代码
+#### 4.3.4 代码
```Python
class Solution:
@@ -285,10 +379,10 @@ class Solution:
return dp[m - 1][n - 1]
```
-#### 3.3.5 复杂度分析
+#### 4.3.5 复杂度分析
- **时间复杂度**:$O(m * n)$。初始条件赋值的时间复杂度为 $O(m + n),ドル两重循环遍历的时间复杂度为 $O(m * n),ドル所以总体时间复杂度为 $O(m * n)$。
-- **空间复杂度**:$O(m * n)$。用到了二维数组保存状态,所以总体空间复杂度为 $O(m * n)$。因为 `dp[i][j]` 的状态只依赖于上方值 `dp[i - 1][j]` 和左侧值 `dp[i][j - 1]`,而我们在进行遍历时的顺序刚好是从上至下、从左到右。所以我们可以使用长度为 `m` 的一维数组来保存状态,从而将空间复杂度优化到 $O(m)$。
+- **空间复杂度**:$O(m * n)$。用到了二维数组保存状态,所以总体空间复杂度为 $O(m * n)$。因为 $dp[i][j]$ 的状态只依赖于上方值 $dp[i - 1][j]$ 和左侧值 $dp[i][j - 1],ドル而我们在进行遍历时的顺序刚好是从上至下、从左到右。所以我们可以使用长度为 $m$ 的一维数组来保存状态,从而将空间复杂度优化到 $O(m)$。
## 参考资料
@@ -300,4 +394,4 @@ class Solution:
- 【书籍】算法训练营 陈小玉 著
- 【书籍】趣学算法 陈小玉 著
- 【书籍】算法竞赛进阶指南 - 李煜东 著
-- 【书籍】ACM-ICPC 程序设计系列 - 算法设计与实现 - 陈宇 吴昊 主编
\ No newline at end of file
+- 【书籍】ACM-ICPC 程序设计系列 - 算法设计与实现 - 陈宇 吴昊 主编
diff --git a/Contents/10.Dynamic-Programming/02.Memoization/01.Memoization.md b/Contents/10.Dynamic-Programming/02.Memoization/01.Memoization.md
index d4ad7f00..d52b55d5 100644
--- a/Contents/10.Dynamic-Programming/02.Memoization/01.Memoization.md
+++ b/Contents/10.Dynamic-Programming/02.Memoization/01.Memoization.md
@@ -4,13 +4,13 @@
记忆化搜索是动态规划的一种实现方式。在记忆化搜索中,当算法需要计算某个子问题的结果时,它首先检查是否已经计算过该问题。如果已经计算过,则直接返回已经存储的结果;否则,计算该问题,并将结果存储下来以备将来使用。
-举个例子,比如「斐波那契数列」的定义是:`f(1) = 1, f(2) = 2, f(n) = f(n - 1) + f(n - 2)`。如果我们使用递归算法求解第 $n$ 个斐波那契数,则对应的递推过程如下:
+举个例子,比如「斐波那契数列」的定义是:$f(0) = 0, f(1) = 1, f(n) = f(n - 1) + f(n - 2)$。如果我们使用递归算法求解第 $n$ 个斐波那契数,则对应的递推过程如下:
-
+
-从图中可以看出:如果使用普通递归算法,想要计算 `f(5)`,需要先计算 `f(4)` 和 `f(3)`,而在计算 `f(4)` 时还需要计算 `f(3)`。这样 `f(3)` 就进行了多次计算。
+从图中可以看出:如果使用普通递归算法,想要计算 $f(5),ドル需要先计算 $f(3)$ 和 $f(4),ドル而在计算 $f(4)$ 时还需要计算 $f(3)$。这样 $f(3)$ 就进行了多次计算,同理 $f(0)$、$f(1)$、$f(2)$ 都进行了多次计算,从而导致了重复计算问题。
-为了避免重复计算,我们可以使用一个缓存(数组或哈希表)来保存已经求解过的 `f(k)` 的结果。如上图所示,当递归调用用到 `f(k)` 时,先查看一下之前是否已经计算过结果,如果已经计算过,则直接从缓存中取值返回,而不用再递推下去,这样就避免了重复计算问题。
+为了避免重复计算,在递归的同时,我们可以使用一个缓存(数组或哈希表)来保存已经求解过的 $f(k)$ 的结果。如上图所示,当递归调用用到 $f(k)$ 时,先查看一下之前是否已经计算过结果,如果已经计算过,则直接从缓存中取值返回,而不用再递推下去,这样就避免了重复计算问题。
使用「记忆化搜索」方法解决斐波那契数列的代码如下:
@@ -81,9 +81,9 @@ class Solution:
#### 4.1.2 题目大意
-**描述**:给定一个整数数组 `nums` 和一个整数 `target`。数组长度不超过 `20`。向数组中每个整数前加 `+` 或 `-`。然后串联起来构造成一个表达式。
+**描述**:给定一个整数数组 $nums$ 和一个整数 $target$。数组长度不超过 20ドル$。向数组中每个整数前加 `+` 或 `-`。然后串联起来构造成一个表达式。
-**要求**:返回通过上述方法构造的、运算结果等于 `target` 的不同表达式数目。
+**要求**:返回通过上述方法构造的、运算结果等于 $target$ 的不同表达式数目。
**说明**:
@@ -120,14 +120,14 @@ class Solution:
使用深度优先搜索对每位数字进行 `+` 或者 `-`,具体步骤如下:
-1. 定义从位置 `0`、和为 `0` 开始,到达数组尾部位置为止,和为 `target` 的方案数为 `dfs(0, 0)`,`size`。
-2. 下面从位置 `0`、和为 `0` 开始,以深度优先搜索遍历每个位置。
-3. 如果当前位置 `i` 到达最后一个位置 `size`:
- 1. 如果和 `cur_sum` 等于目标和 `target`,则返回方案数 `1`。
- 2. 如果和 `cur_sum` 不等于目标和 `target`,则返回方案数 `0`。
-4. 递归搜索 `i + 1` 位置,和为 `cur_sum - nums[i]` 的方案数。
-5. 递归搜索 `i + 1` 位置,和为 `cur_sum + nums[i]` 的方案数。
-6. 将 4 ~ 5 两个方案数加起来就是当前位置 `i`、和为 `cur_sum` 的方案数,返回该方案数。
+1. 定义从位置 0ドル$、和为 0ドル$ 开始,到达数组尾部位置为止,和为 $target$ 的方案数为 `dfs(0, 0)`。
+2. 下面从位置 0ドル$、和为 0ドル$ 开始,以深度优先搜索遍历每个位置。
+3. 如果当前位置 $i$ 到达最后一个位置 $size$:
+ 1. 如果和 `cur_sum` 等于目标和 $target,ドル则返回方案数 1ドル$。
+ 2. 如果和 `cur_sum` 不等于目标和 $target,ドル则返回方案数 0ドル$。
+4. 递归搜索 $i + 1$ 位置,和为 `cur_sum - nums[i]` 的方案数。
+5. 递归搜索 $i + 1$ 位置,和为 `cur_sum + nums[i]` 的方案数。
+6. 将 4 ~ 5 两个方案数加起来就是当前位置 $i$、和为 `cur_sum` 的方案数,返回该方案数。
7. 最终方案数为 `dfs(0, 0)`,将其作为答案返回即可。
##### 思路 1:代码
@@ -158,18 +158,18 @@ class Solution:
在思路 1 中我们单独使用深度优先搜索对每位数字进行 `+` 或者 `-` 的方法超时了。所以我们考虑使用记忆化搜索的方式,避免进行重复搜索。
-这里我们使用哈希表 `table` 记录遍历过的位置 `i` 及所得到的的当前和`cur_sum` 下的方案数,来避免重复搜索。具体步骤如下:
-
-1. 定义从位置 `0`、和为 `0` 开始,到达数组尾部位置为止,和为 `target` 的方案数为 `dfs(0, 0)`。
-2. 下面从位置 `0`、和为 `0` 开始,以深度优先搜索遍历每个位置。
-3. 如果当前位置 `i` 遍历完所有位置:
- 1. 如果和 `cur_sum` 等于目标和 `target`,则返回方案数 `1`。
- 2. 如果和 `cur_sum` 不等于目标和 `target`,则返回方案数 `0`。
-4. 如果当前位置 `i`、和为 `cur_sum` 之前记录过(即使用 `table` 记录过对应方案数),则返回该方案数。
-5. 如果当前位置 `i`、和为 `cur_sum` 之前没有记录过,则:
- 1. 递归搜索 `i + 1` 位置,和为 `cur_sum - nums[i]` 的方案数。
- 2. 递归搜索 `i + 1` 位置,和为 `cur_sum + nums[i]` 的方案数。
- 3. 将上述两个方案数加起来就是当前位置 `i`、和为 `cur_sum` 的方案数,将其记录到哈希表 `table` 中,并返回该方案数。
+这里我们使用哈希表 $table$ 记录遍历过的位置 $i$ 及所得到的的当前和`cur_sum` 下的方案数,来避免重复搜索。具体步骤如下:
+
+1. 定义从位置 0ドル$、和为 0ドル$ 开始,到达数组尾部位置为止,和为 $target$ 的方案数为 `dfs(0, 0)`。
+2. 下面从位置 0ドル$、和为 0ドル$ 开始,以深度优先搜索遍历每个位置。
+3. 如果当前位置 $i$ 遍历完所有位置:
+ 1. 如果和 `cur_sum` 等于目标和 $target,ドル则返回方案数 1ドル$。
+ 2. 如果和 `cur_sum` 不等于目标和 $target,ドル则返回方案数 0ドル$。
+4. 如果当前位置 $i$、和为 `cur_sum` 之前记录过(即使用 $table$ 记录过对应方案数),则返回该方案数。
+5. 如果当前位置 $i$、和为 `cur_sum` 之前没有记录过,则:
+ 1. 递归搜索 $i + 1$ 位置,和为 `cur_sum - nums[i]` 的方案数。
+ 2. 递归搜索 $i + 1$ 位置,和为 `cur_sum + nums[i]` 的方案数。
+ 3. 将上述两个方案数加起来就是当前位置 $i$、和为 `cur_sum` 的方案数,将其记录到哈希表 $table$ 中,并返回该方案数。
6. 最终方案数为 `dfs(0, 0)`,将其作为答案返回即可。
##### 思路 2:代码
@@ -244,7 +244,7 @@ T_4 =わ 1 +たす 1 +たす 2 =わ 4
##### 思路 1:记忆化搜索
1. 问题的状态定义为:第 $n$ 个泰波那契数。其状态转移方程为:$T_0 = 0, T_1 = 1, T_2 = 1,ドル且在 $n>= 0$ 的条件下,$T_{n + 3} = T_{n} + T_{n+1} + T_{n+2}$。
-2. 定义一个长度为 $n + 1$ 数组 `memo` 用于保存一斤个计算过的泰波那契数。
+2. 定义一个长度为 $n + 1$ 数组 $memo$ 用于保存一斤个计算过的泰波那契数。
3. 定义递归函数 `my_tribonacci(n, memo)`。
1. 当 $n = 0$ 或者 $n = 1,ドル或者 $n = 2$ 时直接返回结果。
2. 当 $n> 2$ 时,首先检查是否计算过 $T(n),ドル即判断 $memo[n]$ 是否等于 0ドル$。