| | 按位或运算符 | 只要对应的两个二进位有一个为 1ドル$ 时,结果位就为 1ドル$。 |
-| `&` | 按位与运算符 | 只有对应的两个二进位都为 1ドル$ 时,结果位才为 1ドル$。 |
-| `<<` | 左移运算符 | 将二进制数的各个二进位全部左移若干位。`<<` 右侧数字指定了移动位数,高位丢弃,低位补 0ドル$。 | -| `>>` | 右移运算符 | 对二进制数的各个二进位全部右移若干位。`>>` 右侧数字指定了移动位数,低位丢弃,高位补 0ドル$。 |
-| `^` | 按位异或运算符 | 对应的两个二进位相异时,结果位为 1ドル,ドル二进位相同时则结果位为 0ドル$。 |
-| `~` | 取反运算符 | 对二进制数的每个二进位取反,使数字 1ドル$ 变为 0ドル,ドル0ドル$ 变为 1ドル$。 |
+| 运算符 | 描述 | 规则说明 |
+| --------- | ------------ | --------------------------------------------------------------------------------------------- |
+| | | 按位或 | 只要对应的两个二进位中有一个为 1ドル,ドル结果位即为 1ドル,ドル否则为 0ドル$。 |
+| `&` | 按位与 | 仅当对应的两个二进位都为 1ドル$ 时,结果位才为 1ドル,ドル否则为 0ドル$。 |
+| `^` | 按位异或 | 对应的两个二进位不同则结果位为 1ドル,ドル相同则为 0ドル$。 |
+| `~` | 按位取反 | 对操作数的每一位取反,1ドル$ 变为 0ドル,ドル0ドル$ 变为 1ドル$。 |
+| `<<` | 左移 | 所有二进位整体向左移动指定的位数,高位溢出丢弃,低位补 0ドル$。 | +| `>>` | 右移 | 所有二进位整体向右移动指定的位数,低位溢出丢弃,高位补 0ドル$(无符号右移时)。 |
### 2.1 按位与运算
-> **按位与运算(AND)**:按位与运算符为 `&`。其功能是对两个二进制数的每一个二进位进行与运算。
-
-- **按位与运算规则**:只有对应的两个二进位都为 1ドル$ 时,结果位才为 1ドル$。
+> **按位与运算(AND)**:使用运算符 `&`,对两个二进制数的每一位进行比较,只有当对应位都为 1ドル$ 时,结果位才为 1ドル,ドル否则为 0ドル$。
+- **按位与运算规则**:
- `1 & 1 = 1`
-
- `1 & 0 = 0`
-
- `0 & 1 = 0`
-
- `0 & 0 = 0`
-
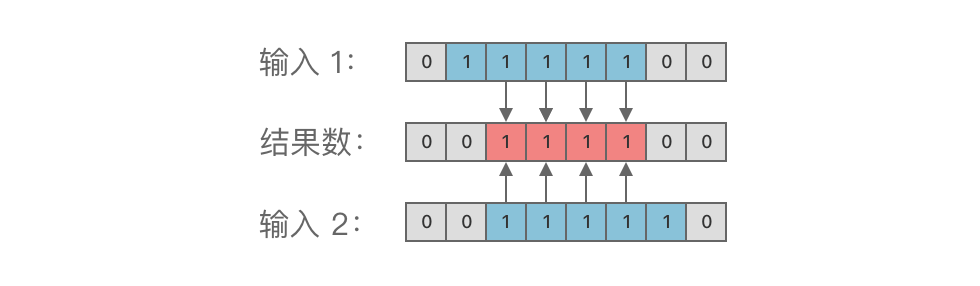
-举个例子,对二进制数 01111100ドル_{(2)}$ 与 00111110ドル_{(2)}$ 进行按位与运算,结果为 00111100ドル_{(2)},ドル如图所示:
+例如,将 01111100ドル_{(2)}$ 与 00111110ドル_{(2)}$ 进行按位与运算,结果为 00111100ドル_{(2)},ドル如下图所示:
### 2.2 按位或运算
-> **按位或运算(OR)**:按位或运算符为 `|`。其功能对两个二进制数的每一个二进位进行或运算。
+> **按位或运算(OR)**:使用运算符 `|`,对两个二进制数的每一位进行「或」操作。只要对应的两个二进位中有一个为 1ドル,ドル结果位就是 1ドル,ドル只有两个都是 0ドル$ 时结果才为 0ドル$。
-- **按位或运算规则**:只要对应的两个二进位有一个为 1ドル$ 时,结果位就为 1ドル$。
+- **按位或运算规则**:
- `1 | 1 = 1`
- `1 | 0 = 1`
- `0 | 1 = 1`
- `0 | 0 = 0`
-
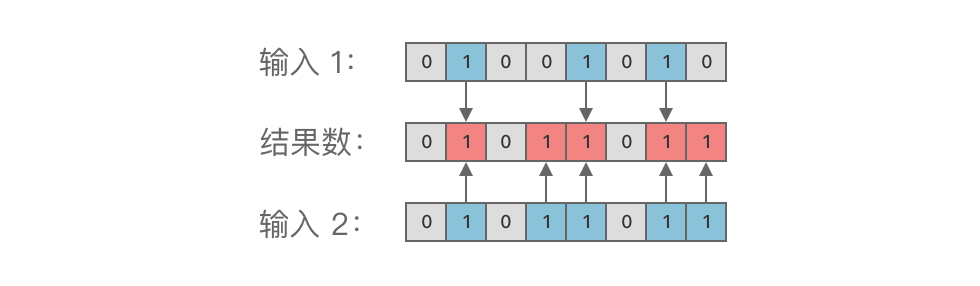
-举个例子,对二进制数 01001010ドル_{(2)}$ 与 01011011ドル_{(2)}$ 进行按位或运算,结果为 01011011ドル_{(2)},ドル如图所示:
+例如,将 01001010ドル_{(2)}$ 与 01011011ドル_{(2)}$ 进行按位或运算,结果为 01011011ドル_{(2)},ドル如下图所示:
### 2.3 按位异或运算
-> **按位异或运算(XOR)**:按位异或运算符为 `^`。其功能是对两个二进制数的每一个二进位进行异或运算。
+> **按位异或运算(XOR)**:使用运算符 `^`,对两个二进制数的每一位进行比较。只有当对应的两位不同(即一位为 1ドル,ドル一位为 0ドル$)时,结果位才为 1ドル,ドル否则为 0ドル$。
-- **按位异或运算规则**:对应的两个二进位相异时,结果位为 1ドル,ドル二进位相同时则结果位为 0ドル$。
-- `0 ^ 0 = 0`
-
-- `1 ^ 0 = 1`
-
-- `0 ^ 1 = 1`
-
-- `1 ^ 1 = 0`
+- **按位异或运算运算规则**:
+ - `0 ^ 0 = 0`
+ - `1 ^ 0 = 1`
+ - `0 ^ 1 = 1`
+ - `1 ^ 1 = 0`
+简而言之,异或运算的本质是「相同为 0ドル,ドル不同为 1ドル$」。
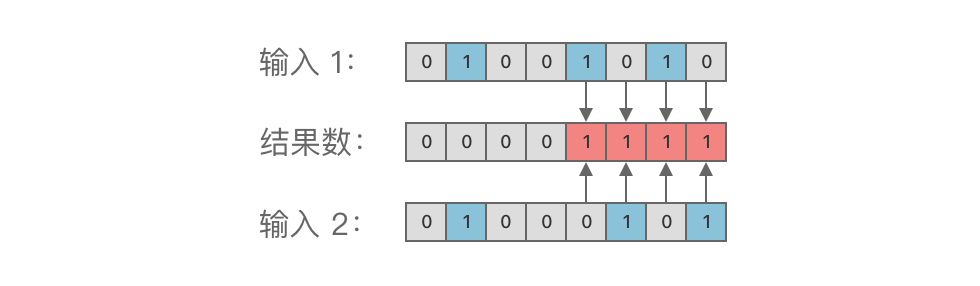
-举个例子,对二进制数 01001010ドル_{(2)}$ 与 01000101ドル_{(2)}$ 进行按位异或运算,结果为 00001111ドル_{(2)},ドル如图所示:
+例如,将 01001010ドル_{(2)}$ 与 01000101ドル_{(2)}$ 进行按位异或运算,结果为 00001111ドル_{(2)},ドル如下图所示:
### 2.4 取反运算
->**取反运算(NOT)**:取反运算符为 `~`。其功能是对一个二进制数的每一个二进位进行取反运算。
+> **取反运算(NOT)**:取反运算符为 `~`,用于将一个二进制数的每一位进行翻转,即 1ドル$ 变为 0ドル,ドル0ドル$ 变为 1ドル$。
-- **取反运算规则**:使数字 1ドル$ 变为 0ドル,ドル0ドル$ 变为 1ドル$。
+- **取反运算规则**:
- `~0 = 1`
- `~1 = 0`
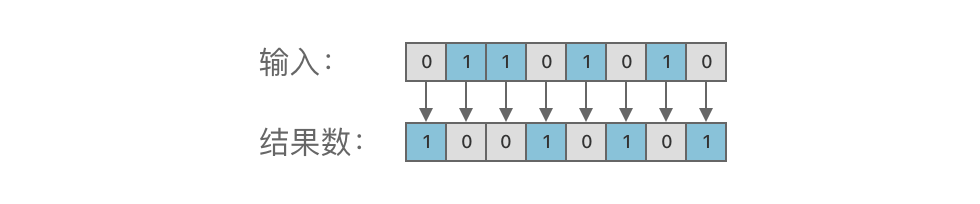
-举个例子,对二进制数 01101010ドル_{(2)}$ 进行取反运算,结果如图所示:
+例如,对二进制数 01101010ドル_{(2)}$ 进行取反,结果如下图所示:
-### 2.5 左移运算和右移运算
+### 2.5 左移运算与右移运算
-> **左移运算(SHL)**: 左移运算符为 `<<`。其功能是对一个二进制数的各个二进位全部左移若干位(高位丢弃,低位补 0ドル$)。 +> **左移运算(SHL)**:使用运算符 `<<`,将一个二进制数的所有位整体向左移动指定的位数。左移时,高位超出部分被舍弃,低位空缺部分补 0ドル$。 -举个例子,对二进制数 01101010ドル_{(2)}$ 进行左移 1ドル$ 位运算,结果为 11010100ドル_{(2)},ドル如图所示: +例如,将二进制数 01101010ドル_{(2)}$ 左移 1ドル$ 位,得到 11010100ドル_{(2)},ドル如下图所示: 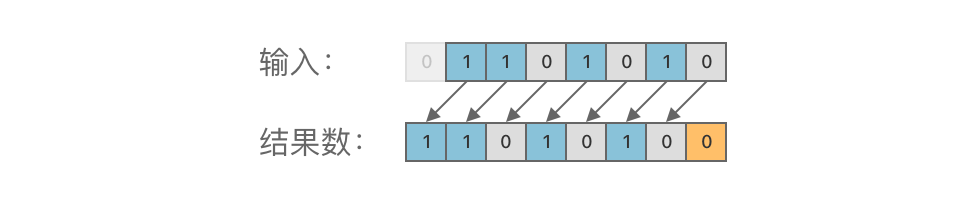 -> **右移运算(SHR)**: 右移运算符为 `>>`。其功能是对一个二进制数的各个二进位全部右移若干位(低位丢弃,高位补 0ドル$)。
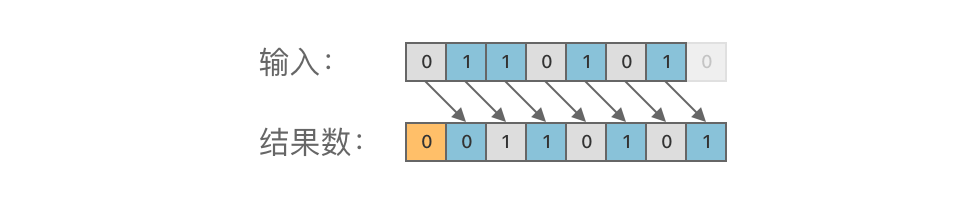
+> **右移运算(SHR)**:使用运算符 `>>`,将一个二进制数的所有位整体向右移动指定的位数。右移时,低位超出部分被舍弃,高位空缺部分补 0ドル$。
-举个例子,对二进制数 01101010ドル_{(2)}$ 进行右移 1ドル$ 位运算,结果为 00110101ドル_{(2)},ドル如图所示:
+例如,将二进制数 01101010ドル_{(2)}$ 右移 1ドル$ 位,得到 00110101ドル_{(2)},ドル如下图所示:
## 3. 位运算的应用
-### 3.1 位运算的常用操作
-
-#### 3.1.1 判断整数奇偶
+### 3.1 判断整数奇偶
-一个整数,只要是偶数,其对应二进制数的末尾一定为 0ドル$;只要是奇数,其对应二进制数的末尾一定为 1ドル$。所以,我们通过与 1ドル$ 进行按位与运算,即可判断某个数是奇数还是偶数。
+判断一个整数的奇偶性,可以利用其二进制表示的最低位。偶数的二进制最低位为 0ドル,ドル奇数的最低位为 1ドル$。因此,通过将该数与 1ドル$ 进行按位与运算即可快速判断:
-1. `(x & 1) == 0` 为偶数。
-2. `(x & 1) == 1` 为奇数。
+- 如果 `(x & 1) == 0`,则 $x$ 为偶数;
+- 如果 `(x & 1) == 1`,则 $x$ 为奇数。
-#### 3.1.2 二进制数选取指定位
+### 3.2 二进制数选取指定位
-如果我们想要从一个二进制数 $X$ 中取出某几位,使取出位置上的二进位保留原值,其余位置为 0ドル,ドル则可以使用另一个二进制数 $Y,ドル使该二进制数上对应取出位置为 1ドル,ドル其余位置为 0ドル$。然后令两个数进行按位与运算(`X & Y`),即可得到想要的数。
+若需从二进制数 $X$ 中提取指定的若干位(即保留这些位的原值,其余位置为 0ドル$),可以先构造一个掩码 $Y,ドル使得需要保留的位置为 1ドル,ドル其余为 0ドル$。随后通过按位与运算(`X & Y`)即可实现目标。
-举个例子,比如我们要取二进制数 $X = 01101010_{(2)}$ 的末尾 4ドル$ 位,则只需将 $X = 01101010_{(2)}$ 与 $Y = 00001111_{(2)}$ (末尾 4ドル$ 位为 1ドル,ドル其余位为 0ドル$) 进行按位与运算,即 `01101010 & 00001111 == 00001010`。其结果 00001010ドル$ 就是我们想要的数(即二进制数 01101010ドル_{(2)}$ 的末尾 4ドル$ 位)。
+例如,如果要获取 $X = 01101010_{(2)}$ 的最低 4ドル$ 位,只需将其与 $Y = 00001111_{(2)}$(最低 4ドル$ 位为 1ドル,ドル其余为 0ドル$)进行按位与运算:`01101010 & 00001111 = 00001010`。结果 00001010ドル$ 即为 $X$ 的末尾 4ドル$ 位。
-#### 3.1.3 将指定位设置为 1ドル$
+### 3.3 将指定位设置为 1ドル$
-如果我们想要把一个二进制数 $X$ 中的某几位设置为 1ドル,ドル其余位置保留原值,则可以使用另一个二进制数 $Y,ドル使得该二进制上对应选取位置为 1ドル,ドル其余位置为 0ドル$。然后令两个数进行按位或运算(`X | Y`),即可得到想要的数。
+若需将二进制数 $X$ 的某几位强制设置为 1ドル$(其余位保持原值),可构造一个掩码 $Y,ドル使得需要设置为 1ドル$ 的位为 1ドル,ドル其余为 0ドル$。然后通过按位或运算(`X | Y`)即可实现。
-举个例子,比如我们想要将二进制数 $X = 01101010_{(2)}$ 的末尾 4ドル$ 位设置为 1ドル,ドル其余位置保留原值,则只需将 $X = 01101010_{(2)}$ 与 $Y = 00001111_{(2)}$(末尾 4ドル$ 位为 1ドル,ドル其余位为 0ドル$)进行按位或运算,即 `01101010 | 00001111 = 01101111`。其结果 01101111ドル$ 就是我们想要的数(即将二进制数 01101010ドル_{(2)}$ 的末尾 4ドル$ 位设置为 1ドル,ドル其余位置保留原值)。
+例如,若要将 $X = 01101010_{(2)}$ 的最低 4ドル$ 位设置为 1ドル,ドル其余位不变,只需与 $Y = 00001111_{(2)}$(最低 4ドル$ 位为 1ドル,ドル其余为 0ドル$)进行按位或运算:`01101010 | 00001111 = 01101111`。结果 01101111ドル$ 即为所需的新数。
-#### 3.1.4 反转指定位
+### 3.4 反转指定位
-如果我们想要把一个二进制数 $X$ 的某几位进行反转,则可以使用另一个二进制数 $Y,ドル使得该二进制上对应选取位置为 1ドル,ドル其余位置为 0ドル$。然后令两个数进行按位异或运算(`X ^ Y`),即可得到想要的数。
+若需反转二进制数 $X$ 的某几位,可构造一个掩码 $Y,ドル使得需要反转的位置为 1ドル,ドル其余为 0ドル$。然后对 $X$ 和 $Y$ 进行按位异或运算(`X ^ Y`),即可实现指定位的反转。
-举个例子,比如想要将二进制数 $X = 01101010_{(2)}$ 的末尾 4ドル$ 位进行反转,则只需将 $X = 01101010_{(2)}$ 与 $Y = 00001111_{(2)}$(末尾 4ドル$ 位为 1ドル,ドル其余位为 0ドル$)进行按位异或运算,即 `01101010 ^ 00001111 = 01100101`。其结果 01100101ドル$ 就是我们想要的数(即将二进制数 $X = 01101010_{(2)}$ 的末尾 4ドル$ 位进行反转)。
+例如,若要反转 $X = 01101010_{(2)}$ 的最低 4ドル$ 位,只需将其与 $Y = 00001111_{(2)}$(最低 4ドル$ 位为 1ドル,ドル其余为 0ドル$)进行异或:`01101010 ^ 00001111 = 01100101`。结果 01100101ドル$ 即为 $X$ 的最低 4ドル$ 位被反转后的新值。
-#### 3.1.5 交换两个数
+### 3.5 交换两个数
-通过按位异或运算可以实现交换两个数的目的(只能用于交换两个整数)。
+通过按位异或运算,可以无需临时变量实现两个整数的交换(仅适用于整数类型)。示例代码如下:
```python
a, b = 10, 20
@@ -184,17 +184,17 @@ a ^= b
print(a, b)
```
-#### 3.1.6 将二进制最右侧为 1ドル$ 的二进位改为 0ドル$
+### 3.6 将二进制最右侧为 1ドル$ 的二进位改为 0ドル$
-如果我们想要将一个二进制数 $X$ 最右侧为 1ドル$ 的二进制位改为 0ドル,ドル则只需通过 `X & (X - 1)` 的操作即可完成。
+要将二进制数 $X$ 最右侧的 1ドル$ 置为 0ドル,ドル只需执行 `X & (X - 1)` 操作即可。
-比如 $X = 01101100_{(2)},ドル$X - 1 = 01101011_{(2)},ドル则 `X & (X - 1) == 01101100 & 01101011 =わ=わ 01101000`,结果为 01101000ドル_{(2)}$(即将 $X$ 最右侧为 1ドル$ 的二进制为改为 0ドル$)。
+例如,$X = 01101100_{(2)},ドル$X - 1 = 01101011_{(2)},ドル则 `X & (X - 1) = 01101100 & 01101011 =わ 01101000`,结果为 01101000ドル_{(2)},ドル即成功将 $X$ 最右侧的 1ドル$ 变为 0ドル$。
-#### 3.1.7 计算二进制中二进位为 1ドル$ 的个数
+### 3.7 计算二进制中二进位为 1ドル$ 的个数
-从 3.1.6 中得知,通过 `X & (X - 1)` 我们可以将二进制 $X$ 最右侧为 1ドル$ 的二进制位改为 0ドル,ドル那么如果我们不断通过 `X & (X - 1)` 操作,最终将二进制 $X$ 变为 0ドル,ドル并统计执行次数,则可以得到二进制中二进位为 1ドル$ 的个数。
+根据 3.6 节的内容,利用 `X & (X - 1)` 操作可以将二进制数 $X$ 的最右侧一个 1ドル$ 变为 0ドル$。因此,如果我们不断对 $X$ 执行该操作,直到 $X$ 变为 0ドル,ドル并统计操作次数,就能得到 $X$ 的二进制表示中 1ドル$ 的个数。
-具体代码如下:
+实现代码如下:
```python
class Solution:
@@ -206,110 +206,113 @@ class Solution:
return cnt
```
-#### 3.1.8 判断某数是否为 2ドル$ 的幂次方
+### 3.8 判断某数是否为 2ドル$ 的幂次方
-通过判断 `X & (X - 1) == 0` 是否成立,即可判断 $X$ 是否为 2ドル$ 的幂次方。
+判断一个数 $X$ 是否为 2ドル$ 的幂,可以利用位运算:只需判断 `X & (X - 1) == 0` 是否成立。
-这是因为:
+原理如下:
-1. 凡是 2ドル$ 的幂次方,其二进制数的某一高位为 1ドル,ドル并且仅此高位为 1ドル,ドル其余位都为 0ドル$。比如:4ドル_{(10)} = 00000100_{(2)}$、8ドル_{(10)} = 00001000_{(2)}$。
-2. 不是 2ドル$ 的幂次方,其二进制数存在多个值为 1ドル$ 的位。比如:5ドル_{10} = 00000101_{(2)}$、6ドル_{10} = 00000110_{(2)}$。
+- 如果 $X$ 是 2ドル$ 的幂,则其二进制表示只有一位为 1ドル,ドル其余全为 0ドル,ドル如 4ドル_{(10)} = 00000100_{(2)},ドル8ドル_{(10)} = 00001000_{(2)}$。
+- 如果 $X$ 不是 2ドル$ 的幂,则其二进制表示中有多位为 1ドル,ドル如 5ドル_{(10)} = 00000101_{(2)},ドル6ドル_{(10)} = 00000110_{(2)}$。
-接下来我们使用 `X & (X - 1)` 操作,将原数对应二进制数最右侧为 1ドル$ 的二进位改为 0ドル$ 之后,得到新值:
+当 $X> 0$ 时,`X & (X - 1)` 的作用是将 $X$ 最右侧的 1ドル$ 变为 0ドル,ドル其余位保持不变:
-1. 如果原数是 2ドル$ 的幂次方,则通过 `X & (X - 1)` 操作之后,新值所有位都为 0ドル,ドル值为 0ドル$。
-2. 如果该数不是 2ドル$ 的幂次方,则通过 `X & (X - 1)` 操作之后,新值仍存在不为 0ドル$ 的位,值肯定不为 0ドル$。
+- 如果 $X$ 是 2ドル$ 的幂,执行 `X & (X - 1)` 后结果为 0ドル$。
+- 如果 $X$ 不是 2ドル$ 的幂,执行后结果不为 0ドル$。
-所以我们可以通过是否为 0ドル$ 即可判断该数是否为 2ドル$ 的幂次方。
+因此,只需判断 `X> 0` 且 `X & (X - 1) == 0`,即可确定 $X$ 是否为 2ドル$ 的幂。
-### 3.2 位运算的常用操作总结
+### 3.9 位运算的常用操作总结
-| 功 能 | 位运算 | 示例 |
-| ----------------------------------------- | ------------------------------------------------------- | ------------------------- |
-| **从右边开始,把最后一个 1ドル$ 改写成 0ドル$** | x & (x - 1) | `100101000 -> 100100000` |
-| **去掉右边起第一个 1ドル$ 的左边** | x & (x ^ (x - 1)) 或 x & (-x) | `100101000 -> 1000` |
-| **去掉最后一位** | x >> 1 | `101101 -> 10110` |
-| **取右数第 $k$ 位** | x >> (k - 1) & 1 | `1101101 -> 1, k = 4` |
-| **取末尾 3ドル$ 位** | x & 7 | `1101101 -> 101` |
-| **取末尾 $k$ 位** | x & 15 | `1101101 -> 1101, k = 4` |
-| **只保留右边连续的 1ドル$** | (x ^ (x + 1)) >> 1 | `100101111 -> 1111` |
-| **右数第 $k$ 位取反** | x ^ (1 << (k - 1)) | `101001 -> 101101, k = 3` |
-| **在最后加一个 0ドル$** | x << 1 | `101101 -> 1011010` |
-| **在最后加一个 1ドル$** | (x << 1) + 1 | `101101 -> 1011011` |
-| **把右数第 $k$ 位变成 0ドル$** | x & ~(1 << (k - 1)) | `101101 -> 101001, k = 3` |
-| **把右数第 $k$ 位变成 1ドル$** | x | (1 << (k - 1)) | `101001 -> 101101, k = 3` |
-| **把右边起第一个 0ドル$ 变成 1ドル$** | x | (x + 1) | `100101111 -> 100111111` |
-| **把右边连续的 0ドル$ 变成 1ドル$** | x | (x - 1) | `11011000 -> 11011111` |
-| **把右边连续的 1ドル$ 变成 0ドル$** | x & (x + 1) | `100101111 -> 100100000` |
-| **把最后一位变成 0ドル$** | x | 1 - 1 | `101101 -> 101100` |
-| **把最后一位变成 1ドル$** | x | 1 | `101100 -> 101101` |
-| **把末尾 $k$ 位变成 1ドル$** | x | (1 << k - 1) | `101001 -> 101111, k = 4` |
-| **最后一位取反** | x ^ 1 | `101101 -> 101100` |
-| **末尾 $k$ 位取反** | x ^ (1 << k - 1) | `101001 -> 100110, k = 4` |
+| 序号 | 操作描述 | 位运算表达式 | 示例 |
+| :--: | :--------------------------------------- | :------------------------------------- | :-------------------------- |
+| 1 | 从右边开始,把最后一个 1ドル$ 改写成 0ドル$ | x & (x - 1) | `100101000 -> 100100000` |
+| 2 | 保留最右侧的 1ドル,ドル其余清零 | x & -x 或 x & (x ^ (x - 1)) | `100101000 -> 1000` |
+| 3 | 去掉最后一位 | x>> 1 | `101101 -> 10110` |
+| 4 | 取右数第 $k$ 位 | (x>> (k - 1)) & 1 | `1101101 -> 1, k = 4` |
+| 5 | 取末尾 $k$ 位 | x & ((1 << k) - 1) | `1101101 -> 101, k = 3`;(x ^ (x + 1))>> 1 | `100101111 -> 1111` |
+| 7 | 右数第 $k$ 位取反 | x ^ (1 << (k - 1)) | `101001 -> 101101, k = 3` |
+| 8 | 在最后加一个 0ドル$ | x << 1 | `101101 -> 1011010` |
+| 9 | 在最后加一个 1ドル$ | (x << 1) + 1 | `101101 -> 1011011` |
+| 10 | 把右数第 $k$ 位变成 0ドル$ | x & ~(1 << (k - 1)) | `101101 -> 101001, k = 3` |
+| 11 | 把右数第 $k$ 位变成 1ドル$ | x | (1 << (k - 1)) | `101001 -> 101101, k = 3` |
+| 12 | 把右边起第一个 0ドル$ 变成 1ドル$ | x | (x + 1) | `100101111 -> 100111111` |
+| 13 | 把右边连续的 0ドル$ 变成 1ドル$ | x | (x - 1) | `11011000 -> 11011111` |
+| 14 | 把右边连续的 1ドル$ 变成 0ドル$ | x & (x + 1) | `100101111 -> 100100000` |
+| 15 | 把最后一位变成 0ドル$ | x & ~1 | `101101 -> 101100` |
+| 16 | 把最后一位变成 1ドル$ | x | 1 | `101100 -> 101101` |
+| 17 | 把末尾 $k$ 位变成 1ドル$ | x | ((1 << k) - 1) | `101001 -> 101111, k = 4` |
+| 18 | 末尾 $k$ 位取反 | x ^ ((1 << k) - 1) | `101101 -> 101100, k = 1`;