|
2 | 2 |
|
3 | 3 | > **快速排序(Quick Sort)基本思想**: |
4 | 4 | > |
5 | | -> 通过一趟排序将无序序列分为独立的两个序列,第一个序列的值均比第二个序列的值小。然后递归地排列两个子序列,以达到整个序列有序。 |
| 5 | +> 采用经典的分治策略,选择数组中某个元素作为基准数,通过一趟排序将数组分为独立的两个子数组,一个子数组中所有元素值都比基准数小,另一个子数组中所有元素值都比基准数大。然后再按照同样的方式递归的对两个子数组分别进行快速排序,以达到整个数组有序。 |
| 6 | +> |
6 | 7 | |
7 | 8 | ## 2. 快速排序算法步骤 |
8 | 9 |
|
9 | | -1. 从序列中找到一个基准数 `pivot`(这里以当前序列第 `1` 个元素作为基准数,即 `pivot = arr[low]`)。 |
10 | | -2. 使用双指针,将序列中比基准数大的元素移动到基准数右侧,比他小的元素移动到基准数左侧: |
11 | | - 1. 使用指针 `i`,指向当前需要处理的元素位置,需要保证位置 `i` 之前的元素都小于基准数。初始时,`i` 指向当前序列的第 `2` 个元素位置。 |
12 | | - 2. 使用指针 `j` 遍历当前序列,如果遇到 `arr[j]` 小于基准数 `pivot`,则将 `arr[j]` 与当前需要处理的元素 `arr[i]` 交换,并将 `i` 向右移动 `1` 位,保证位置 `i` 之前的元素都小于基准数。 |
13 | | - 3. 最后遍历完,此时位置 `i` 之前的元素都小于基准数,第 `i - 1` 位置上的元素是最后一个小于基准数 `pivot` 的元素,此位置为基准数最终的正确位置。将基准数与该位置上的元素进行交换。此时,基准数左侧都是小于基准数的元素,右侧都是大于等于基准数的元素。 |
14 | | - 4. 然后将序列拆分为左右两个子序列。 |
15 | | -3. 对左右两个子序列分别重复第 `2` 步,直到各个子序列只有 `1` 个元素,则排序结束。 |
16 | | - |
17 | | -## 3. 快速排序动画演示 |
18 | | - |
19 | | -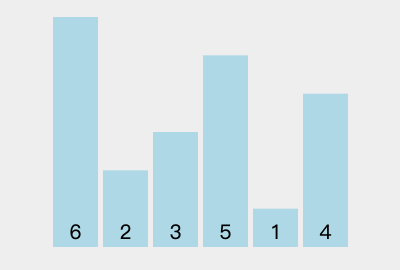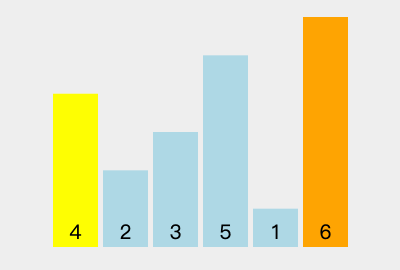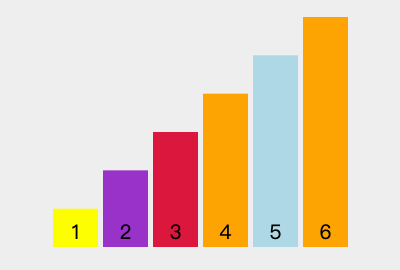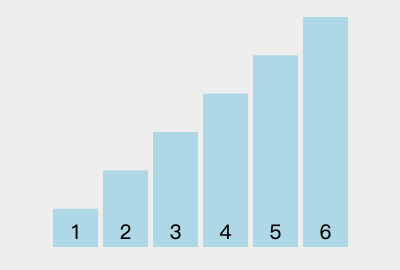 |
20 | | - |
21 | | -1. 初始序列为:`[6, 2, 3, 5, 1, 4]`。 |
22 | | -2. 第 `1` 趟排序: |
23 | | - 1. 选择当前序列第 `1` 个元素 `6` 作为基准数。 |
24 | | - 2. 从左到右遍历序列: |
25 | | - 1. 遇到 `2 < 6`,此时 `i` 与 `j` 相同,指针 `i` 向右移动 `1` 位。 |
26 | | - 2. 遇到 `3 < 6`,此时 `i` 与 `j` 相同,指针 `i` 向右移动 `1` 位。 |
27 | | - 3. 遇到 `5 < 6`,此时 `i` 与 `j` 相同,指针 `i` 向右移动 `1` 位。 |
28 | | - 4. 遇到 `1 < 6`,此时 `i` 与 `j` 相同,指针 `i` 向右移动 `1` 位。 |
29 | | - 5. 遇到 `4 < 6`,此时 `i` 与 `j` 相同,指针 `i` 向右移动 `1` 位,`i` 到达数组末尾。 |
30 | | - 3. 最终将基准值 `6` 与最后 `1` 位交换位置,则序列变为 `[4, 2, 3, 5, 1, 6]`。 |
31 | | - 4. 将序列分为左子序列 `[4, 2, 3, 5, 1]` 和右子序列 `[]`。 |
32 | | -3. 第 `2` 趟排序: |
33 | | - 1. 左子序列 `[4, 2, 3, 5, 1]` 中选择当前序列第 `1` 个元素 `4` 作为基准数。 |
34 | | - 2. 从到右遍历左子序列: |
35 | | - 1. 遇到 `2 < 4`,此时 `i` 与 `j` 相同,指针 `i` 向右移动 `1` 位。 |
36 | | - 2. 遇到 `3 < 4`,此时 `i` 与 `j` 相同,指针 `i` 向右移动 `1` 位。 |
37 | | - 3. 遇到 `5 > 4`,不进行操作; |
38 | | - 4. 遇到 `1 < 4`,此时 `i` 指向 `5`,`j` 指向 `1`。则将 `5` 与 `1` 进行交换,指针 `i` 向右移动 `1` 位,`i` 到达数组末尾。 |
39 | | - 3. 最终将基准值 `4` 与 `1` 交换位置,则序列变为 `[1, 2, 3, 4, 5, 6]`。 |
40 | | -4. 依次类推,重复选定基准数,并将序列中比基准数大的元素移动到基准数右侧,比他小的元素移动到基准数左侧。直到各个子序列只有 `1` 个元素,则排序结束。此时序列变为 `[1, 2, 3, 4, 5, 6]`。 |
| 10 | +快速排序算法的步骤可以简单总结为两步:「递归排序」和「哨兵划分」。 |
41 | 11 |
|
42 | | -## 4. 快速排序算法分析 |
| 12 | +假设数组的元素个数为 $n$ 个,则快速排序的算法步骤如下: |
43 | 13 |
|
44 | | -快速排序算法的时间复杂度主要跟基准数的选择有关。本文中是将当前序列中第 `1` 个元素作为基准值。 |
| 14 | +1. **哨兵划分**:将数组中比基准数大的元素移动到基准数右侧,比他小的元素移动到基准数左侧。 |
| 15 | + 1. 从当前数组中找到一个基准数 $pivot$(这里以当前数组第 1ドル$ 个元素作为基准数,即 $pivot = nums[low]$)。 |
| 16 | + 2. 使用指针 $i$ 指向数组开始位置,指针 $j$ 指向数组末尾位置。 |
| 17 | + 3. 从右向左移动指针 $j,ドル找到第 1ドル$ 个小于基准值的元素。 |
| 18 | + 4. 从左向右移动指针 $i,ドル找到第 1ドル$ 个大于基准数的元素。 |
| 19 | + 5. 交换指针 $i$、指针 $j$ 指向的两个元素。 |
| 20 | + 6. 重复第 3ドル \sim 5$ 步,直到指针 $i$ 和指针 $j$ 相遇时停止,最后将基准数放到两个子数组交界的位置上。 |
| 21 | +2. **递归排序**:按照同样的方式递归的对两个子数组分别进行快速排序。 |
| 22 | + 1. 按照基准数的位置将数组拆分为左右两个子数组。 |
| 23 | + 2. 对每个子数组分别重复「哨兵划分」和「递归排序」,直到各个子数组只有 1ドル$ 个元素,排序结束。 |
45 | 24 |
|
46 | | -在这种选择下,如果参加排序的元素初始时已经有序的情况下,快速排序方法花费的时间最长。也就是会得到最坏时间复杂度。 |
| 25 | +接下来,我们以 $[4, 7, 5, 2, 6, 1, 3]$ 为例,演示一下快速排序的「哨兵划分」和「递归排序」。 |
47 | 26 |
|
48 | | -在这种情况下,第 `1` 趟排序经过 `n - 1` 次比较以后,将第 `1` 个元素仍然确定在原来的位置上,并得到 `1` 个长度为 `n - 1` 的子序列。第 `2` 趟排序进过 `n - 2` 次比较以后,将第 `2` 个元素确定在它原来的位置上,又得到 `1` 个长度为 `n - 2` 的子序列。 |
| 27 | +### 2.1 哨兵划分 |
49 | 28 |
|
50 | | -最终总的比较次数为 $(n − 1) + (n − 2) + ... + 1 = \frac{n(n − 1)}{2}$。因此这种情况下的时间复杂度为 $O(n^2),ドル也是最坏时间复杂度。 |
| 29 | +::: tabs#quickSort |
51 | 30 |
|
52 | | -我们可以改进一下基准数的选择。如果每次我们选中的基准数恰好能将当前序列平分为两份,也就是刚好取到当前序列的中位数。 |
| 31 | +@tab <1> |
53 | 32 |
|
54 | | -在这种选择下,每一次都将序列从 $n$ 个元素变为 $\frac{n}{2}$ 个元素。此时的时间复杂度公式为 $T(n) = 2 \times T(\frac{n}{2}) + \Theta(n)$。根据主定理可以得出 $T(n) = O(n \times \log_2n),ドル也是最佳时间复杂度。 |
| 33 | +@tab <2> |
55 | 34 |
|
56 | | -而在平均情况下,我们可以从当前序列中随机选择一个元素作为基准数。这样,每一次选择的基准数可以看做是等概率随机的。其期望时间复杂度为 $O(n \times \log_2n),ドル也就是平均时间复杂度。 |
| 35 | +@tab <3> |
57 | 36 |
|
58 | | -下面来总结一下: |
| 37 | +::: |
59 | 38 |
|
60 | | -- **最佳时间复杂度**:$O(n \times \log_2n)$。每一次选择的基准数都是当前序列的中位数,此时算法时间复杂度满足的递推式为 $T(n) = 2 \times T(\frac{n}{2}) + \Theta(n),ドル由主定理可得 $T(n) = O(n \times \log_2n)$。 |
61 | | -- **最坏时间复杂度**:$O(n^2)$。每一次选择的基准数都是序列的最终位置上的值,此时算法时间复杂度满足的递推式为 $T(n) = T(n - 1) + \Theta(n),ドル累加可得 $T(n) = O(n^2)$。 |
62 | | -- **平均时间复杂度**:$O(n \times \log_2n)$。在平均情况下,每一次选择的基准数可以看做是等概率随机的。其期望时间复杂度为 $O(n \times \log_2n)$。 |
63 | | -- **空间复杂度**:$O(n)$。无论快速排序算法递归与否,排序过程中都需要用到堆栈或其他结构的辅助空间来存放当前待排序序列的首、尾位置。最坏的情况下,空间复杂度为 $O(n)$。如果对算法进行一些改写,在一趟排序之后比较被划分所得到的两个子序列的长度,并且首先对长度较短的子序列进行快速排序,这时候需要的空间复杂度可以达到 $O(log_2 n)$。 |
64 | | -- **排序稳定性**:快速排序是一种 **不稳定排序算法**。 |
| 39 | +### 2.2 递归排序 |
65 | 40 |
|
66 | | -## 5. 快速排序代码实现 |
| 41 | + |
| 42 | + |
| 43 | +## 3. 快速排序代码实现 |
67 | 44 |
|
68 | 45 | ```python |
69 | 46 | import random |
70 | 47 |
|
71 | 48 | class Solution: |
72 | | - # 从 arr[low: high + 1] 中随机挑选一个基准数,并进行移动排序 |
73 | | - def randomPartition(self, arr: [int], low: int, high: int): |
| 49 | + # 随机哨兵划分:从 nums[low: high + 1] 中随机挑选一个基准数,并进行移位排序 |
| 50 | + def randomPartition(self, nums: [int], low: int, high: int) -> int: |
74 | 51 | # 随机挑选一个基准数 |
75 | 52 | i = random.randint(low, high) |
76 | 53 | # 将基准数与最低位互换 |
77 | | - arr[i], arr[low] = arr[low], arr[i] |
78 | | - # 以最低位为基准数,然后将序列中比基准数大的元素移动到基准数右侧,比他小的元素移动到基准数左侧。最后将基准数放到正确位置上 |
79 | | - return self.partition(arr, low, high) |
| 54 | + nums[i], nums[low] = nums[low], nums[i] |
| 55 | + # 以最低位为基准数,然后将数组中比基准数大的元素移动到基准数右侧,比他小的元素移动到基准数左侧。最后将基准数放到正确位置上 |
| 56 | + return self.partition(nums, low, high) |
80 | 57 |
|
81 | | - # 以最低位为基准数,然后将序列中比基准数大的元素移动到基准数右侧,比他小的元素移动到基准数左侧。最后将基准数放到正确位置上 |
82 | | - def partition(self, arr: [int], low: int, high: int): |
83 | | - pivot = arr[low] # 以第 1 为为基准数 |
84 | | - i = low+1# 从基准数后 1 位开始遍历,保证位置 i 之前的元素都小于基准数 |
| 58 | + # 哨兵划分:以第 1 位元素 nums[low] 为基准数,然后将比基准数小的元素移动到基准数左侧,将比基准数大的元素移动到基准数右侧,最后将基准数放到正确位置上 |
| 59 | + def partition(self, nums: [int], low: int, high: int) -> int: |
| 60 | + # 以第 1 位元素为基准数 |
| 61 | + pivot = nums[low] |
85 | 62 |
|
86 | | - for j in range(i, high + 1): |
87 | | - # 发现一个小于基准数的元素 |
88 | | - if arr[j] < pivot: |
89 | | - # 将小于基准数的元素 arr[j] 与当前 arr[i] 进行换位,保证位置 i 之前的元素都小于基准数 |
90 | | - arr[i], arr[j] = arr[j], arr[i] |
91 | | - # i 之前的元素都小于基准数,所以 i 向右移动一位 |
| 63 | + i, j = low, high |
| 64 | + while i < j: |
| 65 | + # 从右向左找到第 1 个小于基准数的元素 |
| 66 | + while i < j and nums[j] >= pivot: |
| 67 | + j -= 1 |
| 68 | + # 从左向右找到第 1 个大于基准数的元素 |
| 69 | + while i < j and nums[i] <= pivot: |
92 | 70 | i += 1 |
| 71 | + # 交换元素 |
| 72 | + nums[i], nums[j] = nums[j], nums[i] |
| 73 | + |
93 | 74 | # 将基准节点放到正确位置上 |
94 | | - arr[i -1], arr[low] = arr[low], arr[i -1] |
95 | | - # 返回基准数位置 |
96 | | - return i-1 |
| 75 | + nums[i], nums[low] = nums[low], nums[i] |
| 76 | + # 返回基准数的索引 |
| 77 | + return i |
97 | 78 |
|
98 | | - def quickSort(self, arr, low, high): |
| 79 | + def quickSort(self, nums: [int], low: int, high: int) -> [int]: |
99 | 80 | if low < high: |
100 | | - # 按照基准数的位置,将序列划分为左右两个子序列 |
101 | | - pi = self.randomPartition(arr, low, high) |
102 | | - # 对左右两个子序列分别进行递归快速排序 |
103 | | - self.quickSort(arr, low, pi - 1) |
104 | | - self.quickSort(arr, pi + 1, high) |
| 81 | + # 按照基准数的位置,将数组划分为左右两个子数组 |
| 82 | + pivot_i = self.randomPartition(nums, low, high) |
| 83 | + # 对左右两个子数组分别进行递归快速排序 |
| 84 | + self.quickSort(nums, low, pivot_i - 1) |
| 85 | + self.quickSort(nums, pivot_i + 1, high) |
105 | 86 |
|
106 | | - return arr |
| 87 | + return nums |
107 | 88 |
|
108 | | - def sortArray(self, nums: List[int]) -> List[int]: |
| 89 | + def sortArray(self, nums: [int]) -> [int]: |
109 | 90 | return self.quickSort(nums, 0, len(nums) - 1) |
110 | 91 | ``` |
111 | 92 |
|
| 93 | +## 4. 快速排序算法分析 |
| 94 | + |
| 95 | +快速排序算法的时间复杂度主要跟基准数的选择有关。本文中是将当前数组中第 1ドル$ 个元素作为基准值。 |
| 96 | + |
| 97 | +在这种选择下,如果参加排序的元素初始时已经有序的情况下,快速排序方法花费的时间最长。也就是会得到最坏时间复杂度。 |
| 98 | + |
| 99 | +在这种情况下,第 1ドル$ 趟排序经过 $n - 1$ 次比较以后,将第 1ドル$ 个元素仍然确定在原来的位置上,并得到 1ドル$ 个长度为 $n - 1$ 的子数组。第 2ドル$ 趟排序进过 $n - 2$ 次比较以后,将第 2ドル$ 个元素确定在它原来的位置上,又得到 1ドル$ 个长度为 $n - 2$ 的子数组。 |
| 100 | + |
| 101 | +最终总的比较次数为 $(n − 1) + (n − 2) + ... + 1 = \frac{n(n − 1)}{2}$。因此这种情况下的时间复杂度为 $O(n^2),ドル也是最坏时间复杂度。 |
| 102 | + |
| 103 | +我们可以改进一下基准数的选择。如果每次我们选中的基准数恰好能将当前数组平分为两份,也就是刚好取到当前数组的中位数。 |
| 104 | + |
| 105 | +在这种选择下,每一次都将数组从 $n$ 个元素变为 $\frac{n}{2}$ 个元素。此时的时间复杂度公式为 $T(n) = 2 \times T(\frac{n}{2}) + \Theta(n)$。根据主定理可以得出 $T(n) = O(n \times \log n),ドル也是最佳时间复杂度。 |
| 106 | + |
| 107 | +而在平均情况下,我们可以从当前数组中随机选择一个元素作为基准数。这样,每一次选择的基准数可以看做是等概率随机的。其期望时间复杂度为 $O(n \times \log n),ドル也就是平均时间复杂度。 |
| 108 | + |
| 109 | +下面来总结一下: |
| 110 | + |
| 111 | +- **最佳时间复杂度**:$O(n \times \log n)$。每一次选择的基准数都是当前数组的中位数,此时算法时间复杂度满足的递推式为 $T(n) = 2 \times T(\frac{n}{2}) + \Theta(n),ドル由主定理可得 $T(n) = O(n \times \log n)$。 |
| 112 | +- **最坏时间复杂度**:$O(n^2)$。每一次选择的基准数都是数组的最终位置上的值,此时算法时间复杂度满足的递推式为 $T(n) = T(n - 1) + \Theta(n),ドル累加可得 $T(n) = O(n^2)$。 |
| 113 | +- **平均时间复杂度**:$O(n \times \log n)$。在平均情况下,每一次选择的基准数可以看做是等概率随机的。其期望时间复杂度为 $O(n \times \log n)$。 |
| 114 | +- **空间复杂度**:$O(n)$。无论快速排序算法递归与否,排序过程中都需要用到堆栈或其他结构的辅助空间来存放当前待排序数组的首、尾位置。最坏的情况下,空间复杂度为 $O(n)$。如果对算法进行一些改写,在一趟排序之后比较被划分所得到的两个子数组的长度,并且首先对长度较短的子数组进行快速排序,这时候需要的空间复杂度可以达到 $O(log_2 n)$。 |
| 115 | +- **排序稳定性**:快速排序是一种 **不稳定排序算法**。 |
| 116 | + |
112 | 117 | ## 参考资料 |
113 | 118 |
|
114 | 119 | - 【文章】[快速排序 - OI Wiki](https://oi-wiki.org/basic/quick-sort/) |
0 commit comments