|
1 | | -## 1. 堆排序算法思想 |
| 1 | +## 1. 堆结构 |
2 | 2 |
|
3 | | -> **堆排序(Heap sort)基本思想**: |
4 | | -> |
5 | | -> 借用「堆结构」所设计的排序算法。将数组转化为大顶堆,重复从大顶堆中取出数值最大的节点,并让剩余的堆结构继续维持大顶堆性质。 |
| 3 | +「堆排序(Heap sort)」是一种基于「堆结构」实现的高效排序算法。在介绍「堆排序」之前,我们先来了解一下什么是「堆结构」。 |
6 | 4 |
|
7 | 5 | ### 1.1 堆的定义 |
8 | 6 |
|
9 | | -**堆(Heap)**:符合以下两个条件之一的完全二叉树: |
| 7 | +> **堆(Heap)**:一种满足以下两个条件之一的完全二叉树: |
| 8 | +> |
| 9 | +> - **大顶堆(Max Heap)**:任意节点值 ≥ 其子节点值。 |
| 10 | +> - **小顶堆(Min Heap)**:任意节点值 ≤ 其子节点值。 |
10 | 11 | |
11 | | -- **大顶堆**:根节点值 ≥ 子节点值。 |
12 | | -- **小顶堆**:根节点值 ≤ 子节点值。 |
| 12 | +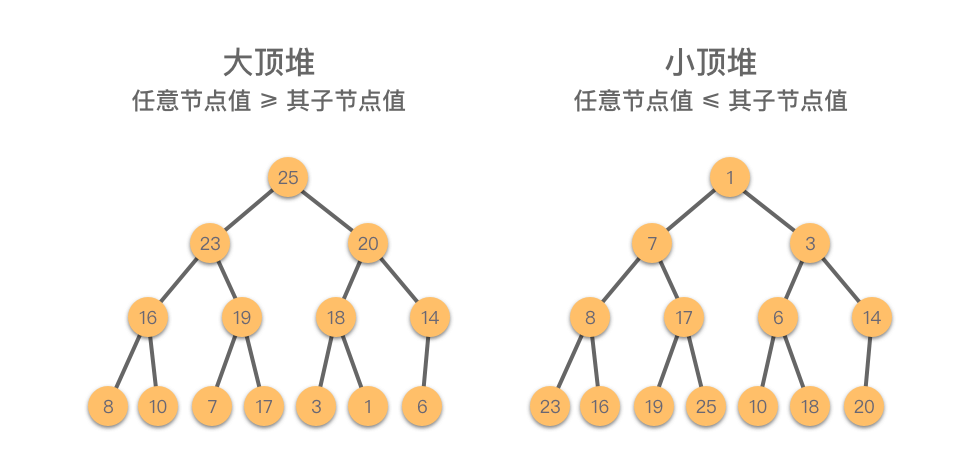 |
13 | 13 |
|
14 | | -### 1.2 堆排序算法步骤 |
| 14 | +### 1.2 堆的存储结构 |
15 | 15 |
|
16 | | -1. **建立初始堆**:将无序序列构造成第 `1` 个大顶堆(初始堆),使得 `n` 个元素的最大值处于序列的第 `1` 个位置。 |
17 | | -2. **调整堆**:交换序列的第 `1` 个元素(最大值元素)与第 `n` 个元素的位置。将序列前 `n - 1` 个元素组成的子序列调整成一个新的大顶堆,使得 `n - 1` 个元素的最大值处于序列第 `1` 个位置,从而得到第 `2` 个最大值元素。 |
18 | | -3. **调整堆**:交换子序列的第 `1` 个元素(最大值元素)与第 `n - 1` 个元素的位置。将序列前 `n - 2` 个元素组成的子序列调整成一个新的大顶堆,使得 `n - 2` 个元素的最大值处于序列第 `1` 个位置,从而得到第 `3` 个最大值元素。 |
19 | | -4. 依次类推,不断交换子序列的第 `1` 个元素(最大值元素)与当前子序列最后一个元素位置,并将其调整成新的大顶堆。直到子序列剩下一个元素时,排序结束。此时整个序列就变成了一个有序序列。 |
| 16 | +堆的逻辑结构就是一颗完全二叉树。而我们在「07.树 - 01.二叉树 - 01.树与二叉树的基础知识」章节中学过,对于完全二叉树(尤其是满二叉树)来说,采用顺序存储结构(数组)的形式来表示完全二叉树,能够充分利用存储空间。 |
20 | 17 |
|
21 | | -从堆排序算法步骤中可以看出:堆排序算法主要涉及「调整堆」和「建立初始堆」两个步骤。 |
| 18 | +当我们使用顺序存储结构(即数组)来表示堆时,堆中元素的节点编号与数组的索引关系为: |
22 | 19 |
|
23 | | -## 2. 调整堆方法 |
| 20 | +- 如果某二叉树节点(非叶子节点)的下标为 $i,ドル那么其左孩子节点下标为 2ドル \times i + 1,ドル右孩子节点下标为 2ドル \times i + 2$。 |
| 21 | +- 如果某二叉树节点(非根结点)的下标为 $i,ドル那么其根节点下标为 $\lfloor \frac{i - 1}{2} \rfloor$(向下取整)。 |
24 | 22 |
|
25 | | -### 2.1 调整堆方法介绍 |
| 23 | +```python |
| 24 | +class MaxHeap: |
| 25 | + def __init__(self): |
| 26 | + self.max_heap = [] |
| 27 | +``` |
| 28 | + |
| 29 | +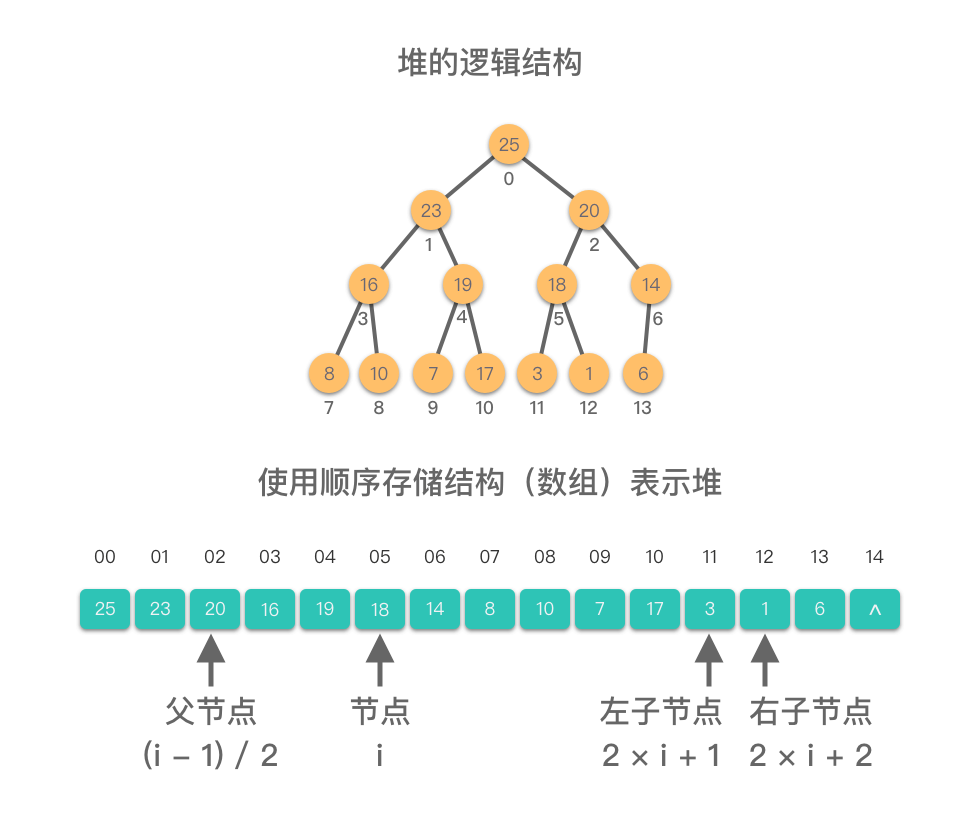 |
26 | 30 |
|
27 | | -**调整堆方法**:把移走了最大值元素以后的剩余元素组成的序列再构造为一个新的堆积。具体步骤如下: |
| 31 | +### 1.3 访问堆顶元素 |
28 | 32 |
|
29 | | -1. 从根节点开始,自上而下地调整节点的位置,使其成为堆积。 |
30 | | - 1. 判断序号为 `i` 的节点与其左子树节点(序号为 `2 * i`)、右子树节点(序号为 `2 * i + 1`)中值关系。 |
31 | | - 2. 如果序号为 `i` 节点大于等于左右子节点值,则排序结束。 |
32 | | - 3. 如果序号为 `i` 节点小于左右子节点值,则将序号为 `i` 节点与左右子节点中值最大的节点交换位置。 |
33 | | -2. 因为交换了位置,使得当前节点的左右子树原有的堆积特性被破坏。于是,从当前节点的左右子树节点开始,自上而下继续进行类似的调整。 |
34 | | -3. 依次类推,直到整棵完全二叉树成为一个大顶堆。 |
| 33 | +> **访问堆顶元素**:指的是从堆结构中获取位于堆顶的元素。 |
35 | 34 | |
36 | | -### 2.2 调整堆方法演示 |
| 35 | +在堆中,堆顶元素位于根节点,当我们使用顺序存储结构(即数组)来表示堆时,堆顶元素就是数组的首个元素。 |
37 | 36 |
|
38 | | -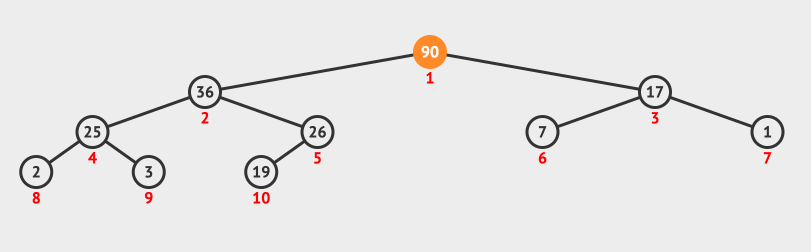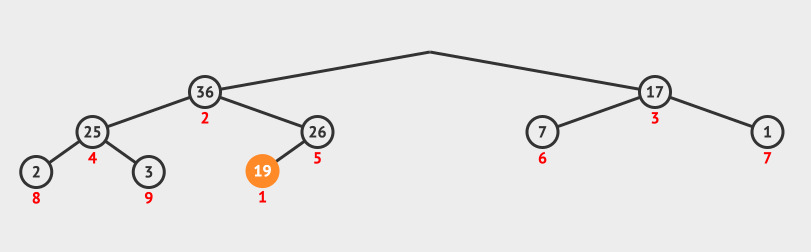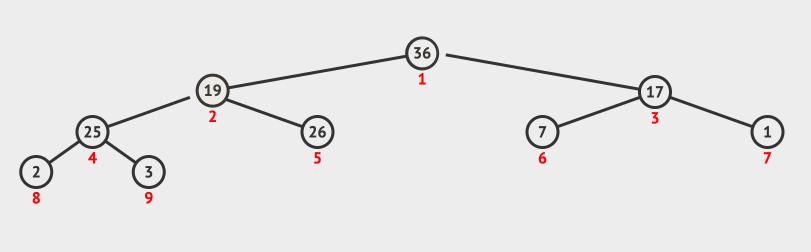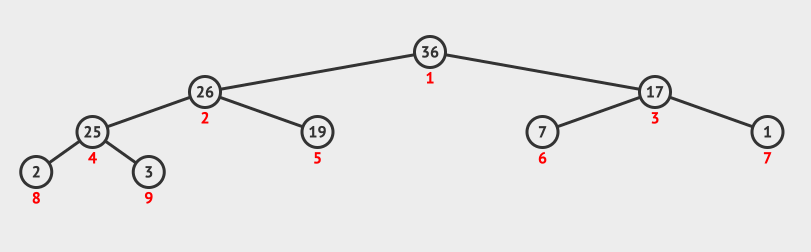 |
| 37 | +```python |
| 38 | +class MaxHeap: |
| 39 | + ...... |
| 40 | + def peek(self) -> int: |
| 41 | + # 大顶堆为空 |
| 42 | + if not self.max_heap: |
| 43 | + return None |
| 44 | + # 返回堆顶元素 |
| 45 | + return self.max_heap[0] |
| 46 | +``` |
39 | 47 |
|
40 | | -1. 交换序列的第 `1` 个元素 `90` 与最后 `1` 个元素 `19` 的位置,此时当前节点为根节点 `19`。 |
41 | | -2. 判断根节点 `19`与其左右子节点值,因为 `17 < 19 < 36`,所以将根节点 `19` 与左子节点 `36` 互换位置,此时当前节点为根节点 `19`。 |
42 | | -3. 判断当前节点 `36` 与其左右子节点值,因为 `19 < 25 < 26`,所以将当前节点 `19` 与右节点 `26` 互换位置。调整堆结束。 |
| 48 | +访问堆顶元素不依赖于数组中元素个数,因此时间复杂度为 $O(1)$。 |
43 | 49 |
|
44 | | -##3. 建立初始堆方法 |
| 50 | +### 1.4 向堆中插入元素 |
45 | 51 |
|
46 | | -### 3.1 建立初始堆方法介绍 |
| 52 | +> **向堆中插入元素**:指的将一个新的元素添加到堆中,调整堆结构,以保持堆的特性不变。 |
47 | 53 | |
48 | | -1. 如果原始序列对应的完全二叉树(不一定是堆)的深度为 `d`,则从 `d - 1` 层最右侧分支节点(序号为 $\lfloor \frac{n}{2} \rfloor$)开始,初始时令 $i = \lfloor \frac{n}{2} \rfloor,ドル调用调整堆算法。 |
49 | | -2. 每调用一次调整堆算法,执行一次 `i = i - 1`,直到 `i == 1` 时,再调用一次,就把原始序列调整为了一个初始堆。 |
| 54 | +向堆中插入元素的步骤如下: |
50 | 55 |
|
51 | | -### 3.2 建立初始堆方法演示 |
| 56 | +1. 将新元素添加到堆的末尾,保持完全二叉树的结构。 |
| 57 | +2. 从新插入的元素节点开始,将该节点与其父节点进行比较。 |
| 58 | + 1. 如果新节点的值大于其父节点的值,则交换它们,以保持最大堆的特性。 |
| 59 | + 2. 如果新节点的值小于等于其父节点的值,说明已满足最大堆的特性,此时结束。 |
| 60 | +3. 重复上述比较和交换步骤,直到新节点不再大于其父节点,或者达到了堆的根节点。 |
52 | 61 |
|
53 | | -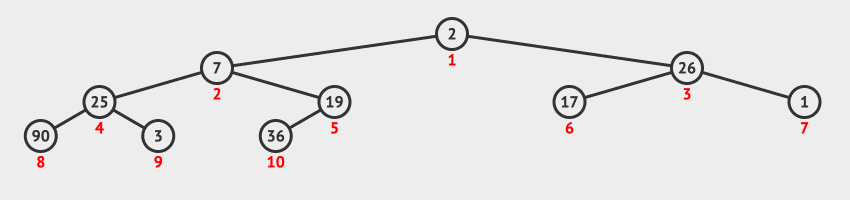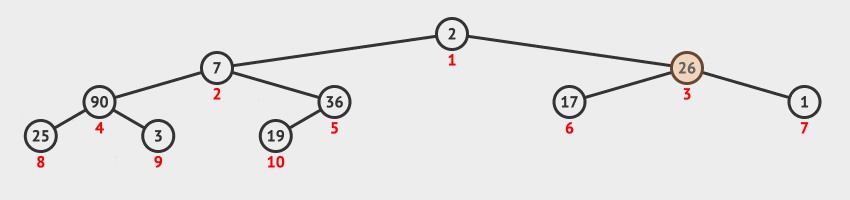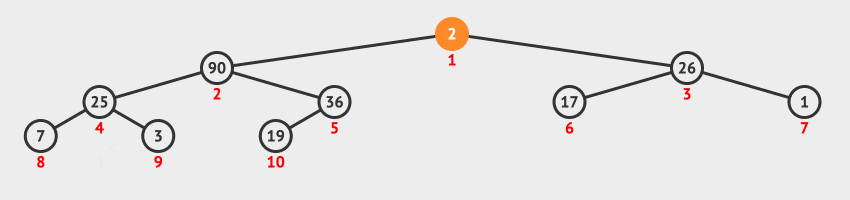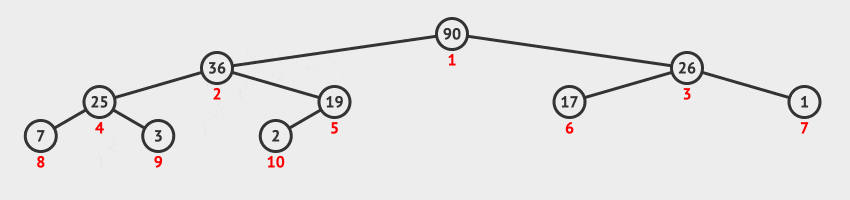 |
| 62 | +这个过程称为「上移调整(Shift Up)」。因为新插入的元素会逐步向堆的上方移动,直到找到了合适的位置,保持堆的有序性。 |
54 | 63 |
|
55 | | -1. 原始序列为 `[2, 7, 26, 25, 19, 17, 1, 90, 3, 36]`,对应完全二叉树的深度为 `3`。 |
56 | | -2. 从第 `2` 层最右侧的分支节点,也就序号为 `5` 的节点开始,调用堆调整算法,使其与子树形成大顶堆。 |
57 | | -3. 节点序号减 `1`,对序号为 `4` 的节点,调用堆调整算法,使其与子树形成大顶堆。 |
58 | | -4. 节点序号减 `1`,对序号为 `3` 的节点,调用堆调整算法,使其与子树形成大顶堆。 |
59 | | -5. 节点序号减 `1`,对序号为 `2` 的节点,调用堆调整算法,使其与子树形成大顶堆。 |
60 | | -6. 节点序号减 `1`,对序号为 `1` 的节点,调用堆调整算法,使其与子树形成大顶堆。 |
61 | | -7. 此时整个原始序列对应的完全二叉树就成了一个大顶堆,建立初始堆完毕。 |
| 64 | +```python |
| 65 | +class MaxHeap: |
| 66 | + ...... |
| 67 | + def push(self, val: int): |
| 68 | + # 将新元素添加到堆的末尾 |
| 69 | + self.max_heap.append(val) |
| 70 | + |
| 71 | + size = len(self.max_heap) |
| 72 | + # 从新插入的元素节点开始,进行上移调整 |
| 73 | + self.__shift_up(size - 1) |
| 74 | + |
| 75 | + def __shift_up(self, i: int): |
| 76 | + while (i - 1) // 2 >= 0 and self.max_heap[i] > self.max_heap[(i - 1) // 2]: |
| 77 | + self.max_heap[i], self.max_heap[(i - 1) // 2] = self.max_heap[(i - 1) // 2], self.max_heap[i] |
| 78 | + i = (i - 1) // 2 |
| 79 | +``` |
62 | 80 |
|
63 | | -## 4. 堆排序方法完整演示 |
| 81 | +在最坏情况下,向堆中插入元素的时间复杂度为 $O(\log n),ドル其中 $n$ 是堆中元素的数量,这是因为堆的高度是 $\log n$。 |
64 | 82 |
|
65 | | -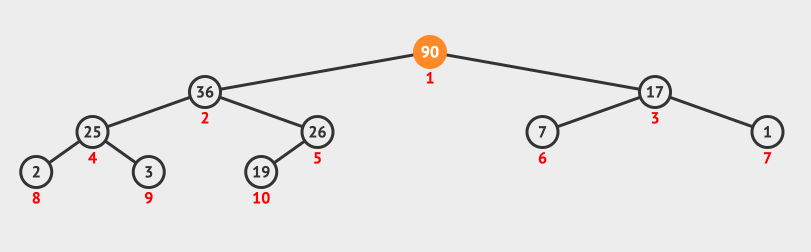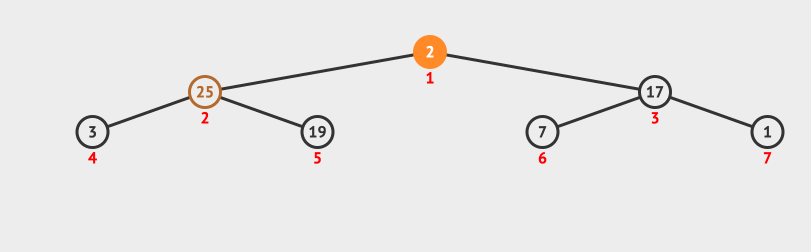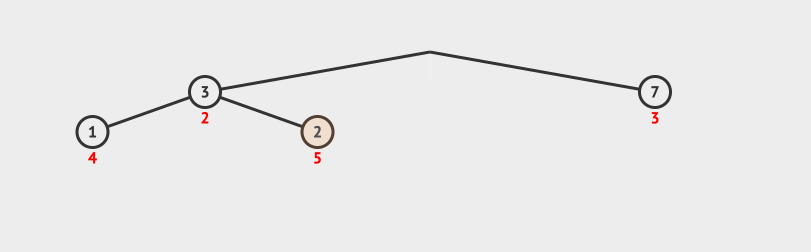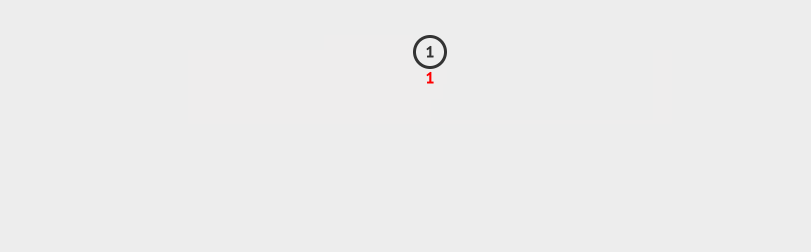 |
| 83 | +### 1.5 删除堆顶元素 |
66 | 84 |
|
67 | | -1. 原始序列为 `[2, 7, 26, 25, 19, 17, 1, 90, 3, 36]`,先根据原始序列建立一个初始堆。 |
68 | | -2. 交换序列中第 `1` 个元素(`90`)与第 `10` 个元素(`2`)的位置。将序列前 `9` 个元素组成的子序列调整成一个大顶堆,此时堆顶变为 `36`。 |
69 | | -3. 交换序列中第 `1` 个元素(`36`)与第 `9` 个元素(`3`)的位置。将序列前 `8` 个元素组成的子序列调整成一个大顶堆,此时堆顶变为 `26`。 |
70 | | -4. 交换序列中第 `1` 个元素(`26`)与第 `8` 个元素(`2`)的位置。将序列前 `7` 个元素组成的子序列调整成一个大顶堆,此时堆顶变为 `25`。 |
71 | | -5. 以此类推,不断交换子序列的第 `1` 个元素(最大值元素)与当前子序列最后一个元素位置,并将其调整成新的大顶堆。直到子序列只剩下最后一个元素 `1` 时,排序结束。此时整个序列变成了一个有序序列,即 `[1, 2, 3, 7, 17, 19, 25, 26, 36, 90]`。 |
| 85 | +> **删除堆顶元素**:指的是从堆中移除位于堆顶的元素,并重新调整对结果,以保持堆的特性不变。 |
72 | 86 | |
73 | | -## 5. 堆排序算法分析 |
| 87 | +删除堆顶元素的步骤如下: |
74 | 88 |
|
75 | | -- **时间复杂度**:$O(n \times \log_2 n)$。 |
76 | | - - 堆积排序的时间主要花费在两个方面:「建立初始堆」和「调整堆」。 |
77 | | - - 设原始序列所对应的完全二叉树深度为 $d,ドル算法由两个独立的循环组成: |
78 | | - 1. 在第 1ドル$ 个循环构造初始堆积时,从 $i = d - 1$ 层开始,到 $i = 1$ 层为止,对每个分支节点都要调用一次调整堆算法,而一次调整堆算法,对于第 $i$ 层一个节点到第 $d$ 层上建立的子堆积,所有节点可能移动的最大距离为该子堆积根节点移动到最后一层(第 $d$ 层) 的距离,即 $d - i$。而第 $i$ 层上节点最多有 2ドル^{i-1}$ 个,所以每一次调用调整堆算法的最大移动距离为 2ドル^{i-1} * (d-i)$。因此,堆积排序算法的第 1ドル$ 个循环所需时间应该是各层上的节点数与该层上节点可移动的最大距离之积的总和,即:$\sum_{i = d - 1}^1 2^{i-1} (d-i) = \sum_{j = 1}^{d-1} 2^{d-j-1} \times j = \sum_{j = 1}^{d-1} 2^{d-1} \times {j \over 2^j} \le n \sum_{j = 1}^{d-1} {j \over 2^j} < 2n$。这一部分的时间花费为 $O(n)$。 |
79 | | - 2. 在第 2ドル$ 个循环中,每次调用调整堆算法一次,节点移动的最大距离为这棵完全二叉树的深度 $d = \lfloor \log_2(n) \rfloor + 1,ドル一共调用了 $n - 1$ 次调整堆算法,所以,第 2ドル$ 个循环的时间花费为 $(n-1)(\lfloor \log_2 (n)\rfloor + 1) = O(n \times \log_2 n)$。 |
80 | | - - 因此,堆积排序的时间复杂度为 $O(n \times \log_2 n)$。 |
81 | | -- **空间复杂度**:$O(1)$。由于在堆积排序中只需要一个记录大小的辅助空间,因此,堆积排序的空间复杂度为:$O(1)$。 |
82 | | -- **排序稳定性**:堆排序是一种 **不稳定排序算法**。 |
| 89 | +1. 将堆顶元素(即根节点)与堆的末尾元素交换。 |
| 90 | +2. 移除堆末尾的元素(之前的堆顶),即将其从堆中剔除。 |
| 91 | +3. 从新的堆顶元素开始,将其与其较大的子节点进行比较。 |
| 92 | + 1. 如果当前节点的值小于其较大的子节点,则将它们交换。这一步是为了将新的堆顶元素「下沉」到适当的位置,以保持最大堆的特性。 |
| 93 | + 2. 如果当前节点的值大于等于其较大的子节点,说明已满足最大堆的特性,此时结束。 |
| 94 | +4. 重复上述比较和交换步骤,直到新的堆顶元素不再小于其子节点,或者达到了堆的底部。 |
83 | 95 |
|
84 | | -## 6. 堆排序代码实现 |
| 96 | +这个过程称为「下移调整(Shift Down)」。因为新的堆顶元素会逐步向堆的下方移动,直到找到了合适的位置,保持堆的有序性。 |
85 | 97 |
|
86 | 98 | ```python |
87 | | -class Solution: |
88 | | - # 调整为大顶堆 |
89 | | - def heapify(self, arr: [int], index: int, end: int): |
90 | | - # 根节点为 index,左节点为 2 * index + 1, 右节点为 2 * index + 2 |
91 | | - left = index * 2 + 1 |
92 | | - right = left + 1 |
93 | | - while left <= end: |
94 | | - # 当前节点为非叶子结点 |
95 | | - max_index = index |
96 | | - if arr[left] > arr[max_index]: |
97 | | - max_index = left |
98 | | - if right <= end and arr[right] > arr[max_index]: |
99 | | - max_index = right |
100 | | - if index == max_index: |
101 | | - # 如果不用交换,则说明已经交换结束 |
| 99 | +class MaxHeap: |
| 100 | + ...... |
| 101 | + def pop(self) -> int: |
| 102 | + # 堆为空 |
| 103 | + if not self.max_heap: |
| 104 | + raise IndexError("堆为空") |
| 105 | + |
| 106 | + size = len(self.max_heap) |
| 107 | + self.max_heap[0], self.max_heap[size - 1] = self.max_heap[size - 1], self.max_heap[0] |
| 108 | + # 删除堆顶元素 |
| 109 | + val = self.max_heap.pop() |
| 110 | + # 节点数减 1 |
| 111 | + size -= 1 |
| 112 | + |
| 113 | + # 下移调整 |
| 114 | + self.__shift_down(0, size) |
| 115 | + |
| 116 | + # 返回堆顶元素 |
| 117 | + return val |
| 118 | + |
| 119 | + |
| 120 | + def __shift_down(self, i: int, n: int): |
| 121 | + while 2 * i + 1 < n: |
| 122 | + # 左右子节点编号 |
| 123 | + left, right = 2 * i + 1, 2 * i + 2 |
| 124 | + |
| 125 | + # 找出左右子节点中的较大值节点编号 |
| 126 | + if 2 * i + 2 >= n: |
| 127 | + # 右子节点编号超出范围(只有左子节点 |
| 128 | + larger = left |
| 129 | + else: |
| 130 | + # 左子节点、右子节点都存在 |
| 131 | + if self.max_heap[left] >= self.max_heap[right]: |
| 132 | + larger = left |
| 133 | + else: |
| 134 | + larger = right |
| 135 | + |
| 136 | + # 将当前节点值与其较大的子节点进行比较 |
| 137 | + if self.max_heap[i] < self.max_heap[larger]: |
| 138 | + # 如果当前节点值小于其较大的子节点,则将它们交换 |
| 139 | + self.max_heap[i], self.max_heap[larger] = self.max_heap[larger], self.max_heap[i] |
| 140 | + i = larger |
| 141 | + else: |
| 142 | + # 如果当前节点值大于等于于其较大的子节点,此时结束 |
102 | 143 | break |
103 | | - arr[index], arr[max_index] = arr[max_index], arr[index] |
104 | | - # 继续调整子树 |
105 | | - index = max_index |
106 | | - left = index * 2 + 1 |
107 | | - right = left + 1 |
108 | | - |
109 | | - # 初始化大顶堆 |
110 | | - def buildMaxHeap(self, arr: [int]): |
111 | | - size = len(arr) |
112 | | - # (size - 2) // 2 是最后一个非叶节点,叶节点不用调整 |
113 | | - for i in range((size - 2) // 2, -1, -1): |
114 | | - self.heapify(arr, i, size - 1) |
115 | | - return arr |
116 | | - |
117 | | - # 升序堆排序,思路如下: |
118 | | - # 1. 先建立大顶堆 |
119 | | - # 2. 让堆顶最大元素与最后一个交换,然后调整第一个元素到倒数第二个元素,这一步获取最大值 |
120 | | - # 3. 再交换堆顶元素与倒数第二个元素,然后调整第一个元素到倒数第三个元素,这一步获取第二大值 |
121 | | - # 4. 以此类推,直到最后一个元素交换之后完毕。 |
122 | | - def maxHeapSort(self, arr: [int]): |
123 | | - self.buildMaxHeap(arr) |
124 | | - size = len(arr) |
125 | | - for i in range(size): |
126 | | - arr[0], arr[size - i - 1] = arr[size - i - 1], arr[0] |
127 | | - self.heapify(arr, 0, size - i - 2) |
128 | | - return arr |
| 144 | +``` |
| 145 | + |
| 146 | +删除堆顶元素的时间复杂度通常为$O(\log n),ドル其中 $n$ 是堆中元素的数量,因为堆的高度是 $\log n$。 |
| 147 | + |
| 148 | +## 2. 堆排序 |
129 | 149 |
|
130 | | - def sortArray(self, nums: List[int]) -> List[int]: |
| 150 | +### 2.1 堆排序算法思想 |
| 151 | + |
| 152 | +> **堆排序(Heap sort)基本思想**: |
| 153 | +> |
| 154 | +> 借用「堆结构」所设计的排序算法。将数组转化为大顶堆,重复从大顶堆中取出数值最大的节点,并让剩余的堆结构继续维持大顶堆性质。 |
| 155 | + |
| 156 | +### 2.2 堆排序算法步骤 |
| 157 | + |
| 158 | +1. **构建初始大顶堆**: |
| 159 | + 1. 定义一个数组实现的堆结构,将原始数组的元素依次存入堆结构的数组中(初始顺序不变)。 |
| 160 | + 2. 从数组的中间位置开始,从右至左,依次通过「下移调整」将数组转换为一个大顶堆。 |
| 161 | + |
| 162 | +2. **交换元素,调整堆**: |
| 163 | + 1. 交换堆顶元素(第 1ドル$ 个元素)与末尾(最后 1ドル$ 个元素)的位置,交换完成后,堆的长度减 1ドル$。 |
| 164 | + 2. 交换元素之后,由于堆顶元素发生了改变,需要从根节点开始,对当前堆进行「下移调整」,使其保持堆的特性。 |
| 165 | + |
| 166 | +3. **重复交换和调整堆**: |
| 167 | + 1. 重复第 2ドル$ 步,直到堆的大小为 1ドル$ 时,此时大顶堆的数组已经完全有序。 |
| 168 | + |
| 169 | + |
| 170 | +### 2.3 堆排序代码实现 |
| 171 | + |
| 172 | +```python |
| 173 | +class MaxHeap: |
| 174 | + ...... |
| 175 | + def __buildMaxHeap(self, nums: [int]): |
| 176 | + size = len(nums) |
| 177 | + # 先将数组 nums 的元素按顺序添加到 max_heap 中 |
| 178 | + for i in range(size): |
| 179 | + self.max_heap.append(nums[i]) |
| 180 | + |
| 181 | + # 从最后一个非叶子节点开始,进行下移调整 |
| 182 | + for i in range((size - 2) // 2, -1, -1): |
| 183 | + self.__shift_down(i, size) |
| 184 | + |
| 185 | + def maxHeapSort(self, nums: [int]) -> [int]: |
| 186 | + # 根据数组 nums 建立初始堆 |
| 187 | + self.__buildMaxHeap(nums) |
| 188 | + |
| 189 | + size = len(self.max_heap) |
| 190 | + for i in range(size - 1, -1, -1): |
| 191 | + # 交换根节点与当前堆的最后一个节点 |
| 192 | + self.max_heap[0], self.max_heap[i] = self.max_heap[i], self.max_heap[0] |
| 193 | + # 从根节点开始,对当前堆进行下移调整 |
| 194 | + self.__shift_down(0, i) |
| 195 | + |
| 196 | + # 返回排序后的数组 |
| 197 | + return self.max_heap |
| 198 | + |
| 199 | +class Solution: |
| 200 | + def maxHeapSort(self, nums: [int]) -> [int]: |
| 201 | + return MaxHeap().maxHeapSort(nums) |
| 202 | + |
| 203 | + def sortArray(self, nums: [int]) -> [int]: |
131 | 204 | return self.maxHeapSort(nums) |
| 205 | + |
| 206 | +print(Solution().sortArray([10, 25, 6, 8, 7, 1, 20, 23, 16, 19, 17, 3, 18, 14])) |
132 | 207 | ``` |
133 | 208 |
|
| 209 | +### 2.4 堆排序算法分析 |
| 210 | + |
| 211 | +- **时间复杂度**:$O(n \times \log n)$。 |
| 212 | + - 堆积排序的时间主要花费在两个方面:「建立初始堆」和「下移调整」。 |
| 213 | + - 设原始数组所对应的完全二叉树深度为 $d,ドル算法由两个独立的循环组成: |
| 214 | + 1. 在第 1ドル$ 个循环构造初始堆积时,从 $i = d - 1$ 层开始,到 $i = 1$ 层为止,对每个分支节点都要调用一次调整堆算法,而一次调整堆算法,对于第 $i$ 层一个节点到第 $d$ 层上建立的子堆积,所有节点可能移动的最大距离为该子堆积根节点移动到最后一层(第 $d$ 层) 的距离,即 $d - i$。而第 $i$ 层上节点最多有 2ドル^{i-1}$ 个,所以每一次调用调整堆算法的最大移动距离为 2ドル^{i-1} * (d-i)$。因此,堆积排序算法的第 1ドル$ 个循环所需时间应该是各层上的节点数与该层上节点可移动的最大距离之积的总和,即:$\sum_{i = d - 1}^1 2^{i-1} (d-i) = \sum_{j = 1}^{d-1} 2^{d-j-1} \times j = \sum_{j = 1}^{d-1} 2^{d-1} \times {j \over 2^j} \le n \times \sum_{j = 1}^{d-1} {j \over 2^j} < 2 \times n$。这一部分的时间花费为 $O(n)$。 |
| 215 | + 2. 在第 2ドル$ 个循环中,每次调用调整堆算法一次,节点移动的最大距离为这棵完全二叉树的深度 $d = \lfloor \log_2(n) \rfloor + 1,ドル一共调用了 $n - 1$ 次调整堆算法,所以,第 2ドル$ 个循环的时间花费为 $(n-1)(\lfloor \log_2 (n)\rfloor + 1) = O(n \times \log n)$。 |
| 216 | + - 因此,堆积排序的时间复杂度为 $O(n \times \log n)$。 |
| 217 | +- **空间复杂度**:$O(1)$。由于在堆积排序中只需要一个记录大小的辅助空间,因此,堆积排序的空间复杂度为:$O(1)$。 |
| 218 | +- **排序稳定性**:在进行「下移调整」时,相等元素的相对位置可能会发生变化。因此,堆排序是一种 **不稳定排序算法**。 |
0 commit comments