I'm trying to find the fastest way to multiply every element in an array by a given number, in this case 2. So far I have written a SIMD instruction that performs at 33 ns multiplying every number in an array of size 1000 by 2.
The techniques used so far are: SIMD instructions, MemoryMarshal method for the loop, Spans, Vector256 Unsafe loading and storing, BitHacks for the multiplication and calculating upper limit of SIMD instructions.
Does anyone know of anything else I can try? You an view each iteration of what I've tried in the following thread. I've learned so much already I am definitely going to attempt another challenge soon.
var testSpace = TestSpaceManager.BigArrayOfInts.Value;
Vector<int> multiplier = new(2);
Span<int> result = stackalloc int[testSpace.Length];
testSpace.CopyTo(result);
var batchSize = Vector<int>.Count;
var remainder = testSpace.Length % batchSize;
var upperLimit = testSpace.Length - remainder;
for (int i = 0; i < upperLimit; i += batchSize)
{
var currentSlice = result.Slice(i, batchSize);
Vector<int> v = new (currentSlice);
(v*multiplier).CopyTo(currentSlice);
}
for (int i = upperLimit; i < testSpace.Length; i++) result[i] *= 2;
The testSpace is a lazy initialised array of size 1000.
I have included a the Benchmarks of the 11 ways of achieving this task where the version above is 'SIMD_no_heap_allocation'. Please see the thread for the code of the other versions and to see how far we have come.
Times in ns:
| Method | Mean | Error | StdDev | Gen0 | Gen1 | Allocated |
|------------------------------------------------------ |-------------:|-----------:|-----------:|-------:|-------:|----------:|
| PLINQ | 22,086.67 ns | 301.232 ns | 235.182 ns | 2.9907 | 0.0305 | 17968 B |
| LINQ | 1,674.13 ns | 3.968 ns | 3.518 ns | 0.6485 | - | 4072 B |
| for_loop | 597.42 ns | 2.075 ns | 1.839 ns | 0.6409 | - | 4024 B |
| memory_marshall_method_bit_hacked | 373.40 ns | 0.442 ns | 0.392 ns | - | - | - |
| SIMD | 208.13 ns | 0.870 ns | 0.727 ns | 0.6413 | - | 4024 B |
| SIMD_no_heap_allocation | 209.12 ns | 0.448 ns | 0.374 ns | - | - | - |
| SIMD_no_heap_allocation_bit_hacked | 129.27 ns | 0.766 ns | 0.679 ns | - | - | - |
| SIMD_memory_marshall_method | 59.86 ns | 0.942 ns | 0.925 ns | - | - | - |
| SIMD_Vector256_Memory_marshal | 58.63 ns | 0.171 ns | 0.160 ns | - | - | - |
| SIMD_Vector256_Memory_Marshal_unrolled | 37.67 ns | 0.114 ns | 0.101 ns | - | - | - |
| SIMD_Vector256_Memory_Marshal_unrolled_quicker_bounds | 33.85 ns | 0.110 ns | 0.103 ns | - | - | - |
-
1\$\begingroup\$ How did you measure the performance of your code? \$\endgroup\$Peter Csala– Peter Csala2023年11月03日 12:21:59 +00:00Commented Nov 3, 2023 at 12:21
-
\$\begingroup\$ @PeterCsala I ran a benchmark. I can post the results of that if you would like. I've compared it against LINQ, a regular for loop and a SIMD instruction with heap allocation \$\endgroup\$Henners2002– Henners20022023年11月03日 12:23:27 +00:00Commented Nov 3, 2023 at 12:23
-
\$\begingroup\$ Anything that extends the review context is more than welcome. \$\endgroup\$Peter Csala– Peter Csala2023年11月03日 12:24:40 +00:00Commented Nov 3, 2023 at 12:24
-
\$\begingroup\$ Note that tasks must have chunks to process that are big enough in order to compensate for the overhead involved in task management. Did you have a loop into Task Parallel Library (TPL)? \$\endgroup\$Olivier Jacot-Descombes– Olivier Jacot-Descombes2023年11月03日 12:31:37 +00:00Commented Nov 3, 2023 at 12:31
-
\$\begingroup\$ @PeterCsala I have included Benchmarks of five relevant methods \$\endgroup\$Henners2002– Henners20022023年11月03日 12:31:50 +00:00Commented Nov 3, 2023 at 12:31
5 Answers 5
I have shaved off about 100ns with the following improvements: used a shift operator to perform the multiplication by 2, since I know that my Vector<int>.Count is 8 which is a power of 2 I was able to replace the expensive modulo operator with a bit hack, removed the unnecessary creation of the result span and worked on testSpace directly. Interestingly it is currently not possible to perform bit shift operators on Vectors in .NET does anyone know why this is?
var testSpace = TestSpaceManager.BigArrayOfInts.Value;
var batchSize = Vector<int>.Count;
Vector<int> multiplier = new(2);
var upperLimit = testSpace.Length & ~(batchSize - 1);
for (int i = 0; i < upperLimit; i += batchSize)
{
Span<int> currentSlice = new(testSpace, i, batchSize);
Vector<int> v = new(currentSlice);
(v * multiplier).CopyTo(currentSlice);
}
for (int i = upperLimit; i < testSpace.Length; i++) testSpace[i] <<= 1;
{kind=link}
-
1\$\begingroup\$ Bit shifts were added to this API but only relatively recently, in .NET 7. In general this API lacks a lot of stuff though. \$\endgroup\$user555045– user5550452023年11月06日 11:02:12 +00:00Commented Nov 6, 2023 at 11:02
Upon a suggestion from @iSR5 I have reimplemented the SIMD instruction using the MemoryMarshall method. This has shaved off a further 60ns. I think SIMD instructions and the memory marshall method go really well together as the both require a fairly large data set to be worthwhile. The code in the below snippet should never be actually implemented if maintainability and readability are concerns at all but it is interesting how much performance you can squeeze out. Comparing LINQ at 1,747 ns to this at 82ns is quite staggering.
var testSpace = TestSpaceManager.BigArrayOfInts.Value;
var batchSize = Vector<int>.Count;
Vector<int> multiplier = new(2);
var upperLimit = testSpace.Length & ~(batchSize - 1);
ref var start = ref MemoryMarshal.GetArrayDataReference(testSpace);
ref var SIMDend = ref Unsafe.Add(ref start, upperLimit);
while (Unsafe.IsAddressLessThan(ref start, ref SIMDend))
{
Span<int> currentSlice = MemoryMarshal.CreateSpan(ref start, batchSize);
Vector<int> v = new(currentSlice);
(v * multiplier).CopyTo(currentSlice);
start = ref Unsafe.Add(ref start, batchSize);
}
for (int i = upperLimit; i < testSpace.Length; i++) testSpace[i] <<= 1;
enter image description here I haven't implemented the memory marshall method for the remainder loop as I think it does iterate over a large enough data set to be worthwhile.
{kind=link}
Does anyone have anymore suggestions?
-
\$\begingroup\$ Seeing as you're using
Unsafealready, you could try usingUnsafe.ReadandUnsafe.Writeto load and store the vector. Also there is a ShiftLeft function as I've noted in an early comment, but it requires.NET 7, can you use it? \$\endgroup\$user555045– user5550452023年11月06日 12:30:08 +00:00Commented Nov 6, 2023 at 12:30 -
\$\begingroup\$ @harold I'm currently on .NET 7 both
v << multiplierandv << 1do not compile for me. I'll try using Unsafe.Read and Unsafe.Write though thank you \$\endgroup\$Henners2002– Henners20022023年11月06日 12:39:15 +00:00Commented Nov 6, 2023 at 12:39 -
\$\begingroup\$ @ wait do you mean
v.ShiftLeft()\$\endgroup\$Henners2002– Henners20022023年11月06日 12:39:51 +00:00Commented Nov 6, 2023 at 12:39 -
\$\begingroup\$ It's a function on
Vector(an extra class that works together withVector<T>to supply a bunch of auxiliary functions) soVector.ShiftLeft(v, shiftcount)\$\endgroup\$user555045– user5550452023年11月06日 12:42:24 +00:00Commented Nov 6, 2023 at 12:42 -
\$\begingroup\$ @harold ok I'll Benchmark that thank you very much. Also with Unsafe.Read() it seems to just accept a void pointer to 1 specific memory location and then return the value there. I suppose I could then iterate through to create the Vector? \$\endgroup\$Henners2002– Henners20022023年11月06日 12:46:53 +00:00Commented Nov 6, 2023 at 12:46
After a suggestion by @harold a further 15ns has been shaved off by using the Vector.ShiftLeft(v, 1) method instead of doing the multiplication and secondly to use LoadUnsafe instead of using the new(Span<int> constructor)
This also allowed for the removal of the multiplier vector.
var testSpace = TestSpaceManager.BigArrayOfInts.Value;
var batchSize = Vector256<int>.Count;
var upperLimit = testSpace.Length & ~(batchSize - 1);
ref var start = ref MemoryMarshal.GetArrayDataReference(testSpace);
ref var SIMDend = ref Unsafe.Add(ref start, upperLimit);
while (Unsafe.IsAddressLessThan(ref start, ref SIMDend))
{
Vector256<int> v = Vector256.ShiftLeft(Vector256.LoadUnsafe(ref start), 1);
v.CopyTo(MemoryMarshal.CreateSpan(ref start, batchSize));
start = ref Unsafe.Add(ref start, batchSize);
}
for (int i = upperLimit; i < testSpace.Length; i++) testSpace[i] <<= 1;
Below are the benchmarks of everything I have tried so far. Any further suggestions would be more than welcome. If anyone can get the performance under 50ns that would be fantastic.
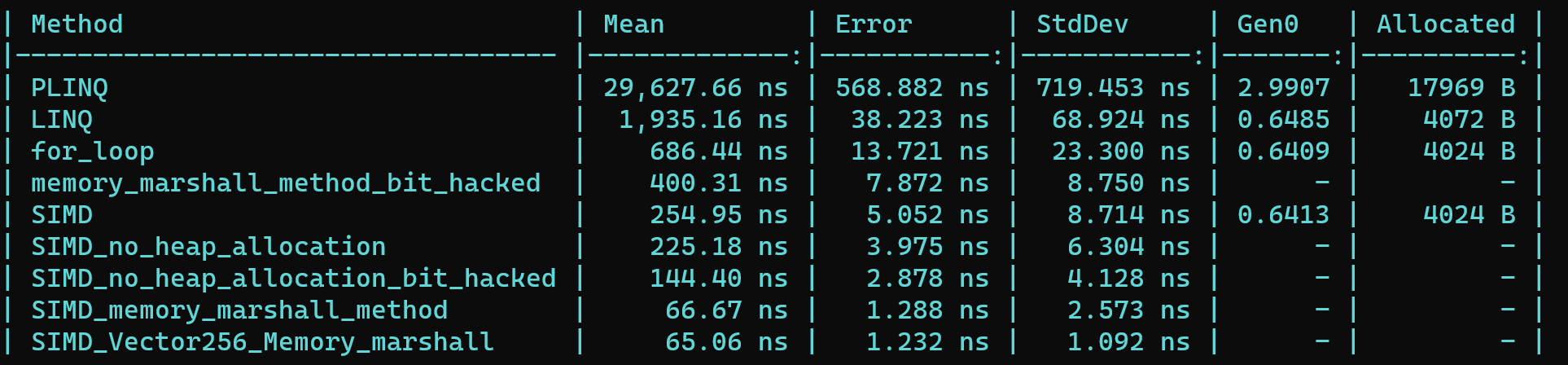{kind=link}
A couple of further things we can do are:
Use
Vector256.StoreUnsafefor the store. It's not a huge deal, but going by the assembly, theCreateSpanandCopyTocombo results in a redundantmov r10, r8in the loop. A mov between registers like that may be eliminated or not, depending on whether the CPU can do that at all and other constraints, but in any case it's better for it to not be there. Mov-elimination is not guaranteed and an eliminated instruction still needs to be decoded and so on, just not executed.Unroll the loop by 2x. I'm suggesting that because according to uica the loop is issue-bottlenecked, which we can improve by reducing the amount of loop overhead compared to the amount of actual work.
var upperLimit = testSpace.Length & ~(batchSize * 2 - 1); // upperLimit must be changed a bit to accommodate unrolling ref var start = ref MemoryMarshal.GetArrayDataReference(testSpace); ref var SIMDend = ref Unsafe.Add(ref start, upperLimit); while (Unsafe.IsAddressLessThan(ref start, ref SIMDend)) { Vector256<int> v = Vector256.ShiftLeft(Vector256.LoadUnsafe(ref start), 1); Vector256<int> v2 = Vector256.ShiftLeft(Vector256.LoadUnsafe(ref Unsafe.Add(ref start, batchSize)), 1); Vector256.StoreUnsafe(v, ref start); Vector256.StoreUnsafe(v2, ref Unsafe.Add(ref start, batchSize)); start = ref Unsafe.Add(ref start, batchSize * 2); }Then with that change, according to uica the loop can make iteration every 2 cycles (on Skylake at least), which is as good as it gets[1] (on Skylake). The unrolling means however that with an array length of 1000, the scalar loop at the end would run (1000 is not divisible by 16), you could reduce the amount of time spent in the scalar loop by adding an optional "non-unrolled" step between the main loop and the scalar loop. I usually don't bother with that sort of thing but it's something you can try.
- In the sense that Skylake can store at most 1 vector to memory per cycle, and the code would already hit that, at least theoretically as predicted by pipeline simulators. If you could avoid putting the result in memory (eg in a context where you can product the result and immediately use it) then it's a different story. Also some newer CPUs can store two vectors per cycle, so the balance shifts.
-
\$\begingroup\$ Thank you so much for this. It knocked off about 20 ns with a few tweaks. I was able to improve the bounds check and the remainder calculation aswell which has brought it down to 33ns. Please see the thread for more details \$\endgroup\$Henners2002– Henners20022023年11月07日 19:24:23 +00:00Commented Nov 7, 2023 at 19:24
Thanks to @harold the goal of getting under 50 ns was achieved with loop unrolling and removing the unnecessary copy instruction. The code below is similar to his but is bithacked and instead of using the for loop for the bounds check on the remaining elements after the SIMD instruction a faster if statement is used. Also a Span is created as this is faster for inputs with higher remainders.
var testSpace = TestSpaceManager.BigArrayOfInts.Value;
var batchSize = Vector256<int>.Count;
var upperLimit = testSpace.Length & ~((batchSize << 1) - 1); // upperLimit must be changed a bit to accommodate unrolling
ref var start = ref MemoryMarshal.GetArrayDataReference(testSpace);
ref var SIMDend = ref Unsafe.Add(ref start, upperLimit);
while (Unsafe.IsAddressLessThan(ref start, ref SIMDend))
{
Vector256<int> v = Vector256.ShiftLeft(Vector256.LoadUnsafe(ref start), 1);
Vector256<int> v2 = Vector256.ShiftLeft(Vector256.LoadUnsafe(ref Unsafe.Add(ref start, batchSize)), 1);
Vector256.StoreUnsafe(v, ref start);
Vector256.StoreUnsafe(v2, ref Unsafe.Add(ref start, batchSize));
start = ref Unsafe.Add(ref start, batchSize << 1);
}
if ((upperLimit & (batchSize - 1)) == 0) return;
Span<int> remainder = new(testSpace, upperLimit, testSpace.Length - upperLimit);
for (int i = upperLimit; i < remainder.Length; i++) remainder[i] <<= 1;
This version is SIMD_Vector256_Memory_Marshal_unrolled_quicker_bounds() on the benchmark. It seems like there should be a way to perform the Unsafe.Add() only once though?
-
\$\begingroup\$ The
Unsafe.Add(ref start, batchSize)that occurs twice, doesn't correspond to any instruction, it just changes the memory operand from[r8]to[r8+0x20]. No big deal. \$\endgroup\$user555045– user5550452023年11月08日 02:47:56 +00:00Commented Nov 8, 2023 at 2:47 -
\$\begingroup\$ To be clear I don't mean that that will happen in general, but it can happen here, and more importantly, it actually happened. \$\endgroup\$user555045– user5550452023年11月08日 06:21:35 +00:00Commented Nov 8, 2023 at 6:21