correctness
It's unclear what the specification
reverse a string
really means in this context.
To reverse US ASCII like "hello world" is straightforward,
and properly handled by the OP code.
But the internet is global,
and an input like "«déjà vu»" would fare poorly.
Is it "a string"?
Or would a sensible specification keep calling
out that this or that field is "a multibyte string"?
For a text processing solution that can handle "internet text", prefer to call mb_str_split().
special case
if (!strlen($str)) {
return '';
}
It's hard to see why that's even part of the solution.
Surely running the for loop through zero iterations should suffice,
producing the same result.
linear complexity
You used the .= catenation operator -- good!
It results in \$O(n)\$ linear performance.
In order to use it,
it was necessary to traverse the source string in reverse order.
Definitely do not traverse characters in forward order to build a result using this:
$reversed = "{$character}{$reversed}";
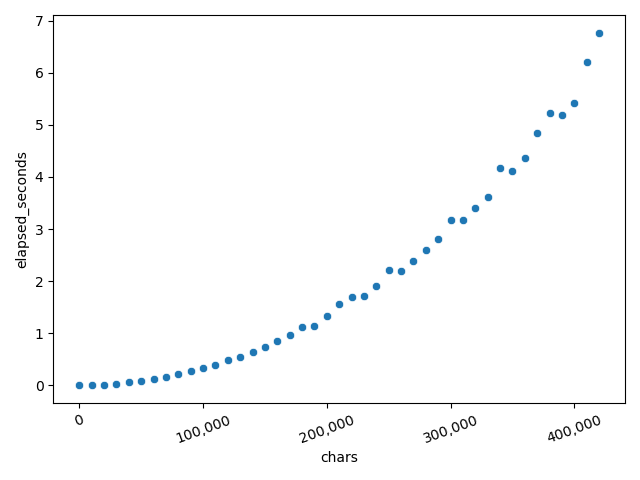
It is observed to suffer from \$O(n^2)\$ quadratic performance,
taking several seconds for a task that should complete
within 20 msec.
The trouble is we keep copying "the string so far"
into a new result string.
In contrast .= requests a "big enough" buffer
and then keeps extending the result string,
without re-reading and re-re-reading partial results.
(Even if it's amortized \$O(n \log n)\$ complexityAnd even with reallocation copying,
that'samortized
cost using a constant growth factor will still mostly indistinguishable fromremain linear.)
time to reverse a string
{kind=link}
correctness
It's unclear what the specification
reverse a string
really means in this context.
To reverse US ASCII like "hello world" is straightforward,
and properly handled by the OP code.
But the internet is global,
and an input like "«déjà vu»" would fare poorly.
Is it "a string"?
Or would a sensible specification keep calling
out that this or that field is "a multibyte string"?
For a text processing solution that can handle "internet text", prefer to call mb_str_split().
special case
if (!strlen($str)) {
return '';
}
It's hard to see why that's even part of the solution.
Surely running the for loop through zero iterations should suffice,
producing the same result.
linear complexity
You used the .= catenation operator -- good!
It results in \$O(n)\$ linear performance.
In order to use it,
it was necessary to traverse the source string in reverse order.
Definitely do not traverse characters in forward order to build a result using this:
$reversed = "{$character}{$reversed}";
It is observed to suffer from \$O(n^2)\$ quadratic performance,
taking several seconds for a task that should complete
within 20 msec.
The trouble is we keep copying "the string so far"
into a new result string.
In contrast .= requests a "big enough" buffer
and then keeps extending the result string,
without re-reading and re-re-reading partial results.
(Even if it's amortized \$O(n \log n)\$ complexity,
that's still mostly indistinguishable from linear.)
time to reverse a string
correctness
It's unclear what the specification
reverse a string
really means in this context.
To reverse US ASCII like "hello world" is straightforward,
and properly handled by the OP code.
But the internet is global,
and an input like "«déjà vu»" would fare poorly.
Is it "a string"?
Or would a sensible specification keep calling
out that this or that field is "a multibyte string"?
For a text processing solution that can handle "internet text", prefer to call mb_str_split().
special case
if (!strlen($str)) {
return '';
}
It's hard to see why that's even part of the solution.
Surely running the for loop through zero iterations should suffice,
producing the same result.
linear complexity
You used the .= catenation operator -- good!
It results in \$O(n)\$ linear performance.
In order to use it,
it was necessary to traverse the source string in reverse order.
Definitely do not traverse characters in forward order to build a result using this:
$reversed = "{$character}{$reversed}";
It is observed to suffer from \$O(n^2)\$ quadratic performance,
taking several seconds for a task that should complete
within 20 msec.
The trouble is we keep copying "the string so far"
into a new result string.
In contrast .= requests a "big enough" buffer
and then keeps extending the result string,
without re-reading and re-re-reading partial results.
And even with reallocation copying,
amortized
cost using a constant growth factor will still remain linear.
time to reverse a string
correctness
It's unclear what the specification
reverse a string
really means in this context.
To reverse US ASCII like "hello world" is straightforward,
and properly handled by the OP code.
But the internet is global,
and an input like "«déjà vu»" would fare poorly.
Is it "a string"?
Or would a sensible specification keep calling
out that this or that field is "a multibyte string"?
For a text processing solution that can handle "internet text", prefer to call mb_str_split().
special case
if (!strlen($str)) {
return '';
}
It's hard to see why that's even part of the solution.
Surely running the for loop through zero iterations should suffice,
producing the same result.
quadraticlinear complexity
You used the .= catenation operator -- good!
It results in \$O(n)\$ linear performance.
In order to use it,
it was necessary to traverse the source string in reverse order.
Definitely do not traverse characters in forward order to build a result using this:
$reversed = "{$character}{$reversed}";
It is observed to suffer from \$O(n^2)\$ quadratic performance,
taking several seconds for a task that should complete
within 20 msec.
The trouble is we keep copying the "string"the string so far"
into a new result string.
In contrast .= requests a "big enough" buffer
and then keeps extending the result string,
without re-reading and re-re-reading partial results.
(Even if it's amortized \$O(n \log n)\$ complexity,
that's still mostly indistinguishable from linear.)
time to reverse a string
correctness
It's unclear what the specification
reverse a string
really means in this context.
To reverse US ASCII like "hello world" is straightforward,
and properly handled by the OP code.
But the internet is global,
and an input like "«déjà vu»" would fare poorly.
Is it "a string"?
Or would a sensible specification keep calling
out that this or that field is "a multibyte string"?
For a text processing solution that can handle "internet text", prefer to call mb_str_split().
special case
if (!strlen($str)) {
return '';
}
It's hard to see why that's even part of the solution.
Surely running the for loop through zero iterations should suffice,
producing the same result.
quadratic complexity
You used the .= catenation operator -- good!
It results in \$O(n)\$ linear performance.
In order to use it,
it was necessary to traverse the source string in reverse order.
Definitely do not traverse characters in forward order to build a result using this:
$reversed = "{$character}{$reversed}";
It is observed to suffer from \$O(n^2)\$ quadratic performance,
taking several seconds for a task that should complete
within 20 msec.
The trouble is we keep copying the "string so far"
into a new result string.
In contrast .= requests a "big enough" buffer
and then keeps extending the result string,
without re-reading and re-re-reading partial results.
(Even if it's amortized \$O(n \log n)\$ complexity,
that's still mostly indistinguishable from linear.)
time to reverse a string
correctness
It's unclear what the specification
reverse a string
really means in this context.
To reverse US ASCII like "hello world" is straightforward,
and properly handled by the OP code.
But the internet is global,
and an input like "«déjà vu»" would fare poorly.
Is it "a string"?
Or would a sensible specification keep calling
out that this or that field is "a multibyte string"?
For a text processing solution that can handle "internet text", prefer to call mb_str_split().
special case
if (!strlen($str)) {
return '';
}
It's hard to see why that's even part of the solution.
Surely running the for loop through zero iterations should suffice,
producing the same result.
linear complexity
You used the .= catenation operator -- good!
It results in \$O(n)\$ linear performance.
In order to use it,
it was necessary to traverse the source string in reverse order.
Definitely do not traverse characters in forward order to build a result using this:
$reversed = "{$character}{$reversed}";
It is observed to suffer from \$O(n^2)\$ quadratic performance,
taking several seconds for a task that should complete
within 20 msec.
The trouble is we keep copying "the string so far"
into a new result string.
In contrast .= requests a "big enough" buffer
and then keeps extending the result string,
without re-reading and re-re-reading partial results.
(Even if it's amortized \$O(n \log n)\$ complexity,
that's still mostly indistinguishable from linear.)
time to reverse a string
correctness
It's unclear what the specification
reverse a string
really means in this context.
To reverse US ASCII like "hello world" is straightforward,
and properly handled by the OP code.
But the internet is global,
and an input like "«déjà vu»" would fare poorly.
Is it "a string"?
Or would a sensible specification keep calling
out that this or that field is "a multibyte string"?
For a text processing solution that can handle "internet text", prefer to call mb_str_split().
special case
if (!strlen($str)) {
return '';
}
It's hard to see why that's even part of the solution.
Surely running the for loop through zero iterations should suffice,
producing the same result.
quadratic complexity
You used the .= catenation operator -- good!
It results in \$O(n)\$ linear performance.
In order to use it,
it was necessary to traverse the source string in reverse order.
Definitely do not traverse characters in forward order to build a result using this:
$reversed = "{$character}{$reversed}";
It is observed to suffer from \$O(n^2)\$ quadratic performance,
taking several seconds for a task that should complete
within 20 msec.
The trouble is we keep copying the "string so far"
into a new result string.
In contrast .= requests a "big enough" buffer
and then keeps extending the result string,
without re-reading and re-re-reading partial results.
(Even if it's amortized \$O(n \log n)\$ complexity,
that's still mostly indistinguishable from linear.)
time to reverse a string
correctness
It's unclear what the specification
reverse a string
really means in this context.
To reverse US ASCII like "hello world" is straightforward,
and properly handled by the OP code.
But the internet is global,
and an input like "«déjà vu»" would fare poorly.
Is it "a string"?
Or would a sensible specification keep calling
out that this or that field is "a multibyte string"?
For a text processing solution that can handle "internet text", prefer to call mb_str_split().
special case
if (!strlen($str)) {
return '';
}
It's hard to see why that's even part of the solution.
Surely running the for loop through zero iterations should suffice,
producing the same result.
quadratic complexity
You used the .= catenation operator -- good!
It results in \$O(n)\$ linear performance.
In order to use it,
it was necessary to traverse the source string in reverse order.
Definitely do not traverse characters in forward order to build a result using this:
$reversed = "{$character}{$reversed}";
It is observed to suffer from \$O(n^2)\$ quadratic performance.
The trouble is we keep copying the "string so far"
into a new result string.
In contrast .= requests a "big enough" buffer
and then keeps extending the result string,
without re-reading and re-re-reading partial results.
(Even if it's amortized \$O(n \log n)\$ complexity,
that's still mostly indistinguishable from linear.)
time to reverse a string
correctness
It's unclear what the specification
reverse a string
really means in this context.
To reverse US ASCII like "hello world" is straightforward,
and properly handled by the OP code.
But the internet is global,
and an input like "«déjà vu»" would fare poorly.
Is it "a string"?
Or would a sensible specification keep calling
out that this or that field is "a multibyte string"?
For a text processing solution that can handle "internet text", prefer to call mb_str_split().
special case
if (!strlen($str)) {
return '';
}
It's hard to see why that's even part of the solution.
Surely running the for loop through zero iterations should suffice,
producing the same result.
quadratic complexity
You used the .= catenation operator -- good!
It results in \$O(n)\$ linear performance.
In order to use it,
it was necessary to traverse the source string in reverse order.
Definitely do not traverse characters in forward order to build a result using this:
$reversed = "{$character}{$reversed}";
It is observed to suffer from \$O(n^2)\$ quadratic performance,
taking several seconds for a task that should complete
within 20 msec.
The trouble is we keep copying the "string so far"
into a new result string.
In contrast .= requests a "big enough" buffer
and then keeps extending the result string,
without re-reading and re-re-reading partial results.
(Even if it's amortized \$O(n \log n)\$ complexity,
that's still mostly indistinguishable from linear.)
time to reverse a string