+int main(void)
+{
+ int i = 0;
+ // ppid 指当前进程的父进程pid
+ // pid 指当前进程的pid,
+ // fpid 指fork返回给当前进程的值,在这可以表示子进程
+ for(i = 0; i < 2; i++){ + pid_t fpid = fork(); + if(fpid == 0) + printf("%d child %4d %4d %4d/n",i, getppid(), getpid(), fpid); + else + printf("%d parent %4d %4d %4d/n",i, getppid(), getpid(),fpid); + } + return 0; +} +/*输出内容: + i 父id id 子id + 0 parent 2043 3224 3225 + 0 child 3224 3225 0 + 1 parent 2043 3224 3226 + 1 parent 3224 3225 3227 + 1 child 1 3227 0 + 1 child 1 3226 0 +*/ +``` - 下载安装包: +
- ```sh
- wget http://download.redis.io/releases/redis-5.0.0.tar.gz
- ```
+在 p3224 和 p3225 执行完第二个循环后,main 函数退出,进程死亡。所以 p3226,p3227 就没有父进程了,成为孤儿进程,所以 p3226 和 p3227 的父进程就被置为 ID 为 1 的 init 进程(笔记 Tool → Linux → 进程管理详解)
- 解压安装包:
+参考文章:https://blog.csdn.net/love_gaohz/article/details/41727415
- ```sh
- tar –xvf redis-5.0.0.tar.gz
- ```
- 编译(在解压的目录中执行):
- ```sh
- make
- ```
+***
- 安装(在解压的目录中执行):
- ```sh
- make install
- ```
-
+#### 内存
-2. 安装 Redis
+fork() 调用之后父子进程的内存关系
- redis-server,服务器启动命令 客户端启动命令
+早期 Linux 的 fork() 实现时,就是全部复制,这种方法效率太低,而且造成了很大的内存浪费,现在 Linux 实现采用了两种方法:
- redis-cli,redis核心配置文件
+* 父子进程的代码段是相同的,所以代码段是没必要复制的,只需内核将代码段标记为只读,父子进程就共享此代码段。fork() 之后在进程创建代码段时,子进程的进程级页表项都指向和父进程相同的物理页帧
- redis.conf,RDB文件检查工具(快照持久化文件)
+
- redis-check-dump,AOF文件修复工具
+* 对于父进程的数据段,堆段,栈段中的各页,由于父子进程相互独立,采用**写时复制 COW** 的技术,来提高内存以及内核的利用率
- redis-check-aof
+ 在 fork 之后两个进程用的是相同的物理空间(内存区),子进程的代码段、数据段、堆栈都是指向父进程的物理空间,**两者的虚拟空间不同,但其对应的物理空间是同一个**,当父子进程中有更改相应段的行为发生时,再为子进程相应的段分配物理空间。如果两者的代码完全相同,代码段继续共享父进程的物理空间;而如果两者执行的代码不同,子进程的代码段也会分配单独的物理空间。
+ fork 之后内核会将子进程放在队列的前面,让子进程先执行,以免父进程执行导致写时复制,而后子进程再执行,因无意义的复制而造成效率的下降
+
-***
+补充知识:
+vfork(虚拟内存 fork virtual memory fork):调用 vfork() 父进程被挂起,子进程使用父进程的地址空间。不采用写时复制,如果子进程修改父地址空间的任何页面,这些修改过的页面对于恢复的父进程是可见的
-#### Ubuntu
-安装:
+参考文章:https://blog.csdn.net/Shreck66/article/details/47039937
-* Redis 5.0 被包含在默认的 Ubuntu 20.04 软件源中
- ```sh
- sudo apt update
- sudo apt install redis-server
- ```
-* 检查Redis状态
- ```sh
- sudo systemctl status redis-server
- ```
-启动:
+****
-* 启动服务器——参数启动
- ```sh
- redis-server [--port port]
- #redis-server --port 6379
- ```
-* 启动服务器——配置文件启动
- ```sh
- redis-server config_file_name
- #redis-server /etc/redis/conf/redis-6397.conf
- ```
-* 启动客户端:
+## 事务机制
+
+### 事务特征
+
+Redis 事务就是将多个命令请求打包,然后**一次性、按顺序**地执行多个命令的机制,并且在事务执行期间,服务器不会中断事务去执行其他的命令请求,会将事务中的所有命令都执行完毕,然后才去处理其他客户端的命令请求,Redis 事务的特性:
+
+* Redis 事务**没有隔离级别**的概念,队列中的命令在事务没有提交之前都不会实际被执行
+* Redis 单条命令式保存原子性的,但是事务**不保证原子性**,事务中如果有一条命令执行失败,其后的命令仍然会被执行,没有回滚
- ```sh
- redis-cli [-h host] [-p port]
- #redis-cli -h 192.168.2.185 -p 6397
- ```
- 注意:服务器启动指定端口使用的是--port,客户端启动指定端口使用的是-p
@@ -8413,31 +13016,53 @@ Redis (REmote DIctionary Server) :用 C 语言开发的一个开源的高性
-### 基本配置
+### 工作流程
-#### 系统目录
+事务的执行流程分为三个阶段:
-1. 创建文件结构
+* 事务开始:MULTI 命令的执行标志着事务的开始,通过在客户端状态的 flags 属性中打开 REDIS_MULTI 标识,将执行该命令的客户端从非事务状态切换至事务状态
- 创建配置文件存储目录
+ ```sh
+ MULTI # 设定事务的开启位置,此指令执行后,后续的所有指令均加入到事务中
+ ```
- ```sh
- mkdir conf
- ```
+* 命令入队:事务队列以先进先出(FIFO)的方式保存入队的命令,每个 Redis 客户端都有事务状态,包含着事务队列:
- 创建服务器文件存储目录(包含日志、数据、临时配置文件等)
+ ```c
+ typedef struct redisClient {
+ // 事务状态
+ multiState mstate; /* MULTI/EXEC state */
+ }
+
+ typedef struct multiState {
+ // 事务队列,FIFO顺序
+ multiCmd *commands;
+
+ // 已入队命令计数
+ int count;
+ }
+ ```
- ```sh
- mkdir data
- ```
+ * 如果命令为 EXEC、DISCARD、WATCH、MULTI 四个命中的一个,那么服务器立即执行这个命令
+ * 其他命令服务器不执行,而是将命令放入一个事务队列里面,然后向客户端返回 QUEUED 回复
+
+* 事务执行:EXEC 提交事务给服务器执行,服务器会遍历这个客户端的事务队列,执行队列中的命令并将执行结果返回
+
+ ```sh
+ EXEC # Commit 提交,执行事务,与multi成对出现,成对使用
+ ```
+
+事务取消的方法:
+
+* 取消事务:
+
+ ```sh
+ DISCARD # 终止当前事务的定义,发生在multi之后,exec之前
+ ```
+
+ 一般用于事务执行过程中输入了错误的指令,直接取消这次事务,类似于回滚
-2. 创建配置文件副本放入 conf 目录,Ubuntu系统配置文件 redis.conf 在目录 `/etc/redis` 中
- ```sh
- cat redis.conf | grep -v "#" | grep -v "^$" -> /conf/redis-6379.conf
- ```
-
- 去除配置文件的注释和空格,输出到新的文件,命令方式采用 redis-port.conf
@@ -8445,138 +13070,116 @@ Redis (REmote DIctionary Server) :用 C 语言开发的一个开源的高性
-#### 服务器
+### WATCH
+
+#### 监视机制
+
+WATCH 命令是一个乐观锁(optimistic locking),可以在 EXEC 命令执行之前,监视任意数量的数据库键,并在 EXEC 命令执行时,检查被监视的键是否至少有一个已经被修改过了,如果是服务器将拒绝执行事务,并向客户端返回代表事务执行失败的空回复
-* 设置服务器以守护进程的方式运行,关闭后服务器控制台中将打印服务器运行信息(同日志内容相同):
+* 添加监控锁
```sh
- daemonize yes|no
+ WATCH key1 [key2......] #可以监控一个或者多个key
```
-* 绑定主机地址,绑定本地IP地址,否则SSH无法访问:
+* 取消对所有 key 的监视
```sh
- bind ip
+ UNWATCH
```
-* 设置服务器端口:
- ```sh
- port port
- ```
-* 设置服务器文件保存地址:
+***
- ```sh
- dir path
- ```
-* 设置数据库的数量:
- ```sh
- databases 16
- ```
+#### 实现原理
-* 多服务器快捷配置:
+每个 Redis 数据库都保存着一个 watched_keys 字典,键是某个被 WATCH 监视的数据库键,值则是一个链表,记录了所有监视相应数据库键的客户端:
- 导入并加载指定配置文件信息,用于快速创建 redis 公共配置较多的 redis 实例配置文件,便于维护
+```c
+typedef struct redisDb {
+ // 正在被 WATCH 命令监视的键
+ dict *watched_keys;
+}
+```
- ```sh
- include /path/conf_name.conf
- ```
+所有对数据库进行修改的命令,在执行后都会调用 `multi.c/touchWatchKey` 函数对 watched_keys 字典进行检查,是否有客户端正在监视刚被命令修改过的数据库键,如果有的话函数会将监视被修改键的客户端的 REDIS_DIRTY_CAS 标识打开,表示该客户端的事务安全性已经被破坏
-
+服务器接收到个客户端 EXEC 命令时,会根据这个客户端是否打开了 REDIS_DIRTY_CAS 标识,如果打开了说明客户端提交事务不安全,服务器会拒绝执行
-***
-#### 客户端
-* 服务器允许客户端连接最大数量,默认0,表示无限制,当客户端连接到达上限后,Redis会拒绝新的连接:
+****
- ```sh
- maxclients count
- ```
-* 客户端闲置等待最大时长,达到最大值后关闭对应连接,如需关闭该功能,设置为 0:
- ```sh
- timeout seconds
- ```
+### ACID
+#### 原子性
+事务具有原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)
-***
+原子性指事务队列中的命令要么就全部都执行,要么一个都不执行,但是在命令执行出错时,不会保证原子性(下一节详解)
+Redis 不支持事务回滚机制(rollback),即使事务队列中的某个命令在执行期间出现了错误,整个事务也会继续执行下去,直到将事务队列中的所有命令都执行完毕为止
+回滚需要程序员在代码中实现,应该尽可能避免:
-#### 日志配置
+* 事务操作之前记录数据的状态
-* 设置服务器以指定日志记录级别:
+ * 单数据:string
- ```sh
- loglevel debug|verbose|notice|warning
- ```
+ * 多数据:hash、list、set、zset
-* 日志记录文件名
- ```sh
- logfile filename
- ```
+* 设置指令恢复所有的被修改的项
-注意:日志级别开发期设置为 verbose 即可,生产环境中配置为 notice,简化日志输出量,降低写日志IO的频度
+ * 单数据:直接 set(注意周边属性,例如时效)
+ * 多数据:修改对应值或整体克隆复制
-**配置文件:**
-```sh
-bind 192.168.2.185
-port 6379
-#timeout 0
-daemonize no
-logfile /etc/redis/data/redis-6379.log
-dir /etc/redis/data
-dbfilename "dump-6379.rdb"
-```
+***
+#### 一致性
+事务具有一致性指的是,数据库在执行事务之前是一致的,那么在事务执行之后,无论事务是否执行成功,数据库也应该仍然是一致的
-***
+一致是数据符合数据库的定义和要求,没有包含非法或者无效的错误数据,Redis 通过错误检测和简单的设计来保证事务的一致性:
+* 入队错误:命令格式输入错误,出现语法错误造成,**整体事务中所有命令均不会执行**,包括那些语法正确的命令
+
-## 体系结构
+* 执行错误:命令执行出现错误,例如对字符串进行 incr 操作,事务中正确的命令会被执行,运行错误的命令不会被执行
-### 存储对象
+
-Redis 使用对象来表示数据库中的键和值,当在 Redis 数据库中新创建一个键值对时至少会创建两个对象,一个对象用作键值对的键(键对象),另一个对象用作键值对的值(值对象)
+* 服务器停机:
-Redis 中对象由一个 redisObject 结构表示,该结构中和保存数据有关的三个属性分别是 type、 encoding、ptr:
+ * 如果服务器运行在无持久化的内存模式下,那么重启之后的数据库将是空白的,因此数据库是一致的
+ * 如果服务器运行在持久化模式下,重启之后将数据库还原到一致的状态
-```c
-typedef struct redisObiect{
- //类型
- unsigned type:4;
- //编码
- unsigned encoding:4;
- //指向底层数据结构的指针
- void *ptr;
-}
-```
-Redis 中主要数据结构有:简单动态字符串(SDS)、双端链表、字典、压缩列表、整数集合、跳跃表
-Redis 并没有直接使用数据结构来实现键值对数据库,而是基于这些数据结构创建了一个对象系统,包含字符串对象、列表对象、哈希对象、集合对象和有序集合对象这五种类型的对象,而每种对象又通过不同的编码映射到不同的底层数据结构
-Redis 自身是一个 Map,其中所有的数据都是采用 key : value 的形式存储,**键对象都是字符串对象**,而值对象有五种基本类型和三种高级类型对象
+***
+
-
+#### 隔离性
+
+Redis 是一个单线程的执行原理,所以对于隔离性,分以下两种情况:
+* 并发操作在 EXEC 命令前执行,隔离性的保证要使用 WATCH 机制来实现,否则隔离性无法保证
+* 并发操作在 EXEC 命令后执行,隔离性可以保证
@@ -8584,52 +13187,58 @@ Redis 自身是一个 Map,其中所有的数据都是采用 key : value 的形
-### 线程模型
+#### 持久性
-Redis 基于 Reactor 模式开发了网络事件处理器,这个处理器被称为文件事件处理器(file event handler),这个文件事件处理器是单线程的,所以 Redis 叫做单线程的模型
+Redis 并没有为事务提供任何额外的持久化功能,事务的持久性由 Redis 所使用的持久化模式决定
-文件事件处理器以单线程方式运行,但是使用 I/O 多路复用程序来监听多个套接字,既实现了高性能的网络通信模型,又很好地与 Redis 服务器中其他同样以单线程方式运行的模块进行对接,保持了 Redis 单线程设计的简单性
+配置选项 `no-appendfsync-on-rewrite` 可以配合 appendfsync 选项在 AOF 持久化模式使用:
-工作原理:
+* 选项打开时在执行 BGSAVE 或者 BGREWRITEAOF 期间,服务器会暂时停止对 AOF 文件进行同步,从而尽可能地减少 I/O 阻塞
+* 选项打开时运行在 always 模式的 AOF 持久化,事务也不具有持久性,所以该选项默认关闭
-* 文件事件处理器使用 I/O 多路复用(multiplexing)程序来同时监听多个套接字,并根据套接字目前执行的任务来为套接字关联不同的事件处理器
+在一个事务的最后加上 SAVE 命令总可以保证事务的耐久性
-* 当被监听的套接字准备好执行连接应答 (accept)、读取 (read)、写入 (write)、关闭 (close) 等操作时,与操作相对应的文件事件就会产生,这时文件事件处理器会将处理请求放入**单线程的执行队列**中,等待调用套接字关联好的事件处理器来处理事件
-**Redis 单线程也能高效的原因**:
-* 纯内存操作
-* 核心是基于非阻塞的 IO 多路复用机制,单线程可以高效处理多个请求
-* 底层使用 C 语言实现,C 语言实现的程序距离操作系统更近,执行速度相对会更快
-* 单线程同时也**避免了多线程的上下文频繁切换问题**,预防了多线程可能产生的竞争问题
+***
-****
+## Lua 脚本
-### 多线程
+### 环境创建
-Redis6.0 引入多线程主要是为了提高网络 IO 读写性能,因为这是 Redis 的一个性能瓶颈(Redis 的瓶颈主要受限于内存和网络),多线程只是用来**处理网络数据的读写和协议解析**, 执行命令仍然是单线程顺序执行,因此不需要担心线程安全问题。
+#### 基本介绍
-Redis6.0 的多线程默认是禁用的,只使用主线程。如需开启需要修改 redis 配置文件 `redis.conf` :
+Redis 对 Lua 脚本支持,通过在服务器中嵌入 Lua 环境,客户端可以使用 Lua 脚本直接在服务器端**原子地执行**多个命令
```sh
-io-threads-do-reads yesCopy to clipboardErrorCopied
+EVAL
@@ -8556,7 +8748,7 @@ v-on:为 HTML 标签绑定事件,有简写方式
new Vue({
el:"#div",
data:{
- name:"黑马程序员"
+ name:"sea程序员"
},
methods:{
change(){
@@ -8586,7 +8778,7 @@ v-on:为 HTML 标签绑定事件,有简写方式
将Model和View关联起来的就是ViewModel,它是桥梁。
ViewModel负责把Model的数据同步到View显示出来,还负责把View修改的数据同步回Model。
- 
+ 
```html
@@ -8758,11 +8950,11 @@ Element:网站快速成型工具,是饿了么公司前端开发团队提供
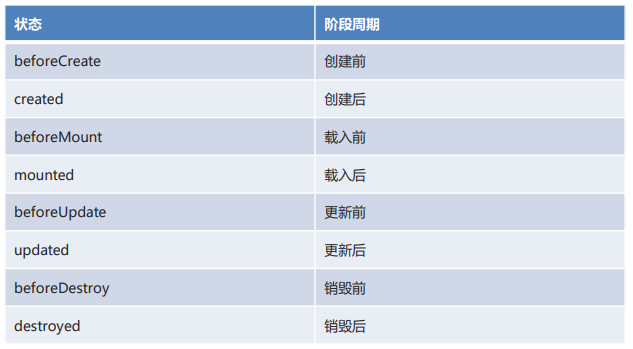
* 生命周期
- 
+ 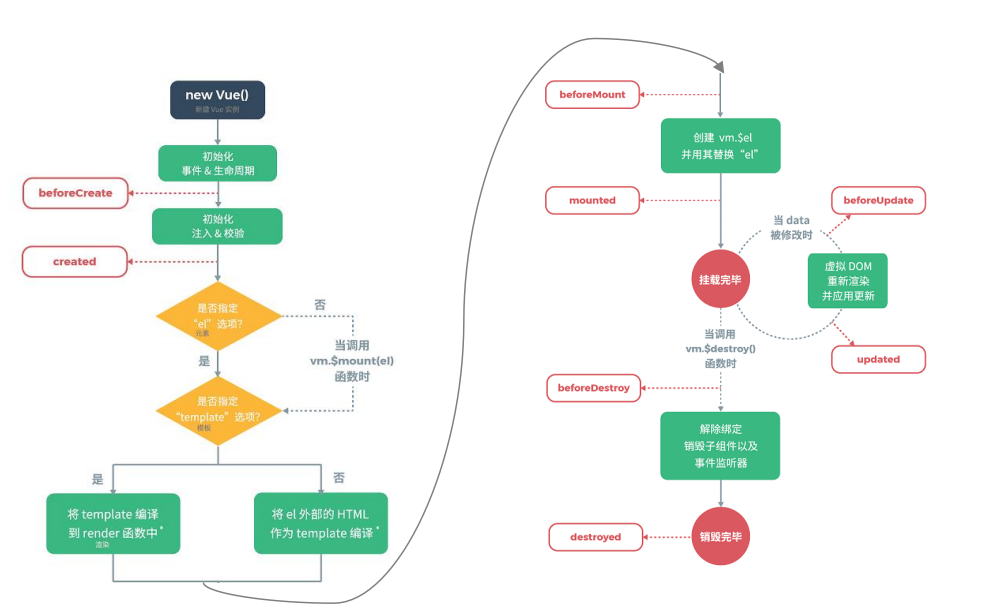
* 生命周期八个阶段
- 
+ 
@@ -8872,9 +9064,9 @@ Element:网站快速成型工具,是饿了么公司前端开发团队提供
## 安装软件
-Nginx(engine x) 是一个高性能的HTTP和[反向代理](https://baike.baidu.com/item/反向代理/7793488)web服务器,同时也提供了IMAP/POP3/SMTP服务。
+Nginx 是一个高性能的 HTTP 和[反向代理 ](https://baike.baidu.com/item/反向代理/7793488)Web 服务器,同时也提供了 IMAP/POP3/SMTP 服务
-Nginx两个最核心的功能:高性能的静态web服务器,反向代理
+Nginx 两个最核心的功能:高性能的静态 Web 服务器,反向代理
* 安装指令:sudo apt-get install nginx
@@ -8882,6 +9074,7 @@ Nginx两个最核心的功能:高性能的静态web服务器,反向代理
* 系统指令:systemctl / service start/restart/stop/status nginx
配置文件安装目录:/etc/nginx
+
日志文件:/var/log/nginx
@@ -8892,20 +9085,20 @@ Nginx两个最核心的功能:高性能的静态web服务器,反向代理
## 配置文件
-nginx.conf 文件时nginx的主配置文件
+nginx.conf 文件时 Nginx 的主配置文件
-
+
-* main部分
-
+* main 部分
+
-* events部分
-
+* events 部分
+
-* server部分
-
+* server 部分
+
- root设置的路径会拼接上location的路径,然后去最终路径寻找对应的文件
+ root 设置的路径会拼接上 location 的路径,然后去最终路径寻找对应的文件
@@ -8915,15 +9108,18 @@ nginx.conf 文件时nginx的主配置文件
## 发布项目
-1. 创建一个toutiao目录
- cd /home
- mkdir toutiao
-
-2. 将项目上传到toutiao目录
+1. 创建一个 toutiao 目录
+
+ ```sh
+ cd /home
+ mkdir toutiao
+ ```
+
+2. 将项目上传到 toutiao 目录
3. 解压项目 unzip web.zip
-4. 编辑Nginx配置文件nginx.conf
+4. 编辑 Nginx 配置文件 nginx.conf
```shell
server {
@@ -8936,9 +9132,9 @@ nginx.conf 文件时nginx的主配置文件
}
```
-5. 重启nginx服务:systemctl restart nginx
+5. 重启 Nginx 服务:systemctl restart nginx
-6. 浏览器打开网址 http://127.0.0.1:80
+6. 浏览器打开网址:http://127.0.0.1:80
@@ -8948,32 +9144,32 @@ nginx.conf 文件时nginx的主配置文件
## 反向代理
-> 无法访问Google,可以配置一个代理服务器,发送请求到代理服务器,代理服务器经过转发,再将请求转发给Google,返回结果之后,再次转发给用户。这个叫做正向代理,正向代理对于用户来说,是有感知的
+> 无法访问 Google,可以配置一个代理服务器,发送请求到代理服务器,代理服务器经过转发,再将请求转发给 Google,返回结果之后,再次转发给用户,这个叫做正向代理,正向代理对于用户来说,是有感知的
-**正向代理(forward proxy)**:是一个位于客户端和目标服务器之间的服务器(代理服务器),为了从目标服务器取得内容,客户端向代理服务器发送一个请求并指定目标,然后代理服务器向目标服务器转交请求并将获得的内容返回给客户端,**正向代理,其实是"代理服务器"代理了"客户端",去和"目标服务器"进行交互**
+**正向代理(forward proxy)**:是一个位于客户端和目标服务器之间的代理服务器,为了从目标服务器取得内容,客户端向代理服务器发送一个请求并指定目标,然后代理服务器向目标服务器转交请求并将获得的内容返回给客户端,**正向代理,其实是"代理服务器"代理了当前"客户端",去和"目标服务器"进行交互**
作用:
-* 突破访问限制:通过代理服务器,可以突破自身IP访问限制,访问国外网站,教育网等
+* 突破访问限制:通过代理服务器,可以突破自身 IP 访问限制,访问国外网站,教育网等
* 提高访问速度:代理服务器都设置一个较大的硬盘缓冲区,会将部分请求的响应保存到缓冲区中,当其他用户再访问相同的信息时, 则直接由缓冲区中取出信息,传给用户,以提高访问速度
-* 隐藏客户端真实IP:隐藏自己的IP,免受攻击
+* 隐藏客户端真实 IP:隐藏自己的 IP,免受攻击
-
+
-**反向代理(reverse proxy)**:是指以代理服务器来接受internet上的连接请求,然后将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给internet上请求连接的客户端,此时代理服务器对外就表现为一个反向代理服务器,**反向代理,其实是"代理服务器"代理了"目标服务器",去和"客户端"进行交互**
+**反向代理(reverse proxy)**:是指以代理服务器来接受 Internet 上的连接请求,然后将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给 Internet 上请求连接的客户端,此时代理服务器对外就表现为一个反向代理服务器,**反向代理,其实是"代理服务器"代理了"目标服务器",去和当前"客户端"进行交互**
作用:
-* 隐藏服务器真实IP:使用反向代理,可以对客户端隐藏服务器的IP地址
+* 隐藏服务器真实 IP:使用反向代理,可以对客户端隐藏服务器的 IP 地址
* 负载均衡:根据所有真实服务器的负载情况,将客户端请求分发到不同的真实服务器上
* 提高访问速度:反向代理服务器可以对于静态内容及短时间内有大量访问请求的动态内容提供缓存服务
-* 提供安全保障:反向代理服务器可以作为应用层防火墙,为网站提供对基于Web的攻击行为(例如DoS/DDoS)的防护,更容易排查恶意软件等
+* 提供安全保障:反向代理服务器可以作为应用层防火墙,为网站提供对基于 Web 的攻击行为(例如 DoS/DDoS)的防护,更容易排查恶意软件等
-
+
区别: