();
-
- while(true){
- byte[] arr = new byte[1024 * 10];//10kb
- list.add(arr);
-// try {
-// Thread.sleep(5);
-// } catch (InterruptedException e) {
-// e.printStackTrace();
-// }
- }
- }
-}
-```
-
-### 老年代使用CMS GC
-
-**GC设置方法**:参数中使用-XX:+UseConcMarkSweepGC,说明老年代使用CMS GC,同时年轻代也会触发对ParNew的使用,因此添加该参数之后,新生代使用ParNew GC,而老年代使用CMS GC,整体是并发垃圾收集,主打低延迟
-
-
-
-打印出来的GC细节:
-
-
-
-
-
-### 新生代使用Serial GC
-
- **GC设置方法**:参数中使用-XX:+UseSerialGC,说明新生代使用Serial GC,同时老年代也会触发对Serial Old GC的使用,因此添加该参数之后,新生代使用Serial GC,而老年代使用Serial Old GC,整体是串行垃圾收集
-
-
-
- 打印出来的GC细节:
-
-
-
-DefNew代表新生代使用Serial GC,然后Tenured代表老年代使用Serial Old GC
-
-## GC 日志分类
-
-### MinorGC
-
-MinorGC(或 young GC 或 YGC)日志:
-
-```java
-[GC (Allocation Failure) [PSYoungGen: 31744K->2192K (36864K) ] 31744K->2200K (121856K), 0.0139308 secs] [Times: user=0.05 sys=0.01, real=0.01 secs]
-```
-
-
-
-
-
-### FullGC
-
-```java
-[Full GC (Metadata GC Threshold) [PSYoungGen: 5104K->0K (132096K) ] [Par01dGen: 416K->5453K (50176K) ]5520K->5453K (182272K), [Metaspace: 20637K->20637K (1067008K) ], 0.0245883 secs] [Times: user=0.06 sys=0.00, real=0.02 secs]
-```
-
-
-
-
-
-## GC 日志结构剖析
-
-### 透过日志看垃圾收集器
-
-- Serial 收集器:新生代显示 "[DefNew",即 Default New Generation
-
-- ParNew 收集器:新生代显示 "[ParNew",即 Parallel New Generation
-
-- Parallel Scavenge 收集器:新生代显示"[PSYoungGen",JDK1.7 使用的即 PSYoungGen
-
-- Parallel Old 收集器:老年代显示"[ParoldGen"
-
-- G1 收集器:显示"garbage-first heap"
-
-### 透过日志看 GC 原因
-
-- Allocation Failure:表明本次引起 GC 的原因是因为新生代中没有足够的区域存放需要分配的数据
-- Metadata GCThreshold:Metaspace 区不够用了
-- FErgonomics:JVM 自适应调整导致的 GC
-- System:调用了 System.gc()方法
-
-### 透过日志看 GC 前后情况
-
-通过图示,我们可以发现 GC 日志格式的规律一般都是:GC 前内存占用-> GC 后内存占用(该区域内存总大小)
-
-```java
-[PSYoungGen: 5986K->696K (8704K) ] 5986K->704K (9216K)
-```
-
-- 中括号内:GC 回收前年轻代堆大小,回收后大小,(年轻代堆总大小)
-
-- 括号外:GC 回收前年轻代和老年代大小,回收后大小,(年轻代和老年代总大小)
-
-注意:Minor GC 堆内存总容量 = 9/10 年轻代 + 老年代。原因是 Survivor 区只计算 from 部分,而 JVM 默认年轻代中 Eden 区和 Survivor 区的比例关系,Eden:S0:S1=8:1:1。
-
-### 透过日志看 GC 时间
-
-GC 日志中有三个时间:user,sys 和 real
-
-- user:进程执行用户态代码(核心之外)所使用的时间。这是执行此进程所使用的实际 CPU 时间,其他进程和此进程阻塞的时间并不包括在内。在垃圾收集的情况下,表示 GC 线程执行所使用的 CPU 总时间。
-- sys:进程在内核态消耗的 CPU 时间,即在内核执行系统调用或等待系统事件所使用的 CPU 时间
-- real:程序从开始到结束所用的时钟时间。这个时间包括其他进程使用的时间片和进程阻塞的时间(比如等待 I/O 完成)。对于并行 gc,这个数字应该接近(用户时间+系统时间)除以垃圾收集器使用的线程数。
-
-由于多核的原因,一般的 GC 事件中,real time 是小于 sys time + user time 的,因为一般是多个线程并发的去做 GC,所以 real time 是要小于 sys + user time 的。如果 real > sys + user 的话,则你的应用可能存在下列问题:IO 负载非常重或 CPU 不够用。
-
-## Minor GC 日志解析
-
-### 日志格式
-
-```Java
-2021年09月06日T08:44:49.453+0800: 4.396: [GC (Allocation Failure) [PSYoungGen: 76800K->8433K(89600K)] 76800K->8449K(294400K), 0.0060231 secs] [Times: user=0.02 sys=0.01, real=0.01 secs]
-```
-
-### 日志解析
-
-#### 2021年09月06日T08:44:49.453+0800
-
-日志打印时间 日期格式 如 2013年05月04日T21:53:59.234+0800
-
-添加-XX:+PrintGCDateStamps参数
-
-#### 4.396
-
-gc 发生时,Java 虚拟机启动以来经过的秒数
-
-添加-XX:+PrintGCTimeStamps该参数
-
-#### [GC (Allocation Failure)
-
-发生了一次垃圾回收,这是一次 Minor GC。它不区分新生代 GC 还是老年代 GC,括号里的内容是 gc 发生的原因,这里 Allocation Failure 的原因是新生代中没有足够区域能够存放需要分配的数据而失败。
-
-#### [PSYoungGen: 76800K->8433K(89600K)]
-
-**PSYoungGen**:表示GC发生的区域,区域名称与使用的GC收集器是密切相关的
-
-- **Serial收集器**:Default New Generation 显示Defnew
-- **ParNew收集器**:ParNew
-- **Parallel Scanvenge收集器**:PSYoung
-- 老年代和新生代同理,也是和收集器名称相关
-
-**76800K->8433K(89600K)**:GC前该内存区域已使用容量->GC后盖区域容量(该区域总容量)
-
-- 如果是新生代,总容量则会显示整个新生代内存的9/10,即eden+from/to区
-- 如果是老年代,总容量则是全身内存大小,无变化
-
-#### 76800K->8449K(294400K)
-
-虽然本次是Minor GC,只会进行新生代的垃圾收集,但是也肯定会打印堆中总容量相关信息
-
-在显示完区域容量GC的情况之后,会接着显示整个堆内存区域的GC情况:GC前堆内存已使用容量->GC后堆内存容量(堆内存总容量),并且堆内存总容量 = 9/10 新生代 + 老年代,然后堆内存总容量肯定小于初始化的内存大小
-
-#### ,0.0088371
-
-整个GC所花费的时间,单位是秒
-
-#### [Times:user=0.02 sys=0.01,real=0.01 secs]
-
-- **user**:指CPU工作在用户态所花费的时间
-- **sys**:指CPU工作在内核态所花费的时间
-- **real**:指在此次事件中所花费的总时间
-
-## Full GC 日志解析
-
-### 日志格式
-
-```Java
-2021年09月06日T08:44:49.453+0800: 4.396: [Full GC (Metadata GC Threshold) [PSYoungGen: 10082K->0K(89600K)] [ParOldGen: 32K->9638K(204800K)] 10114K->9638K(294400K), [Metaspace: 20158K->20156K(1067008K)], 0.0149928 secs] [Times: user=0.06 sys=0.02, real=0.02 secs]
-```
-
-### 日志解析
-
-#### 2020年11月20日T17:19:43.794-0800
-
-日志打印时间 日期格式 如 2013年05月04日T21:53:59.234+0800
-
-添加-XX:+PrintGCDateStamps参数
-
-#### 1.351
-
-gc 发生时,Java 虚拟机启动以来经过的秒数
-
-添加-XX:+PrintGCTimeStamps该参数
-
-#### Full GC(Metadata GCThreshold)
-
-括号中是gc发生的原因,原因:Metaspace区不够用了。
-除此之外,还有另外两种情况会引起Full GC,如下:
-
-1. Full GC(FErgonomics)
- 原因:JVM自适应调整导致的GC
-2. Full GC(System)
- 原因:调用了System.gc()方法
-
-#### [PSYoungGen: 100082K->0K(89600K)]
-
-**PSYoungGen**:表示GC发生的区域,区域名称与使用的GC收集器是密切相关的
-
-- **Serial收集器**:Default New Generation 显示DefNew
-- **ParNew收集器**:ParNew
-- **Parallel Scanvenge收集器**:PSYoungGen
-- 老年代和新生代同理,也是和收集器名称相关
-
-**10082K->0K(89600K)**:GC前该内存区域已使用容量->GC该区域容量(该区域总容量)
-
-- 如果是新生代,总容量会显示整个新生代内存的9/10,即eden+from/to区
-
-- 如果是老年代,总容量则是全部内存大小,无变化
-
-#### ParOldGen:32K->9638K(204800K)
-
-老年代区域没有发生GC,因此本次GC是metaspace引起的
-
-#### 10114K->9638K(294400K),
-
-在显示完区域容量GC的情况之后,会接着显示整个堆内存区域的GC情况:GC前堆内存已使用容量->GC后堆内存容量(堆内存总容量),并且堆内存总容量 = 9/10 新生代 + 老年代,然后堆内存总容量肯定小于初始化的内存大小
-
-#### [Meatspace:20158K->20156K(1067008K)],
-
-metaspace GC 回收2K空间
-
-
-
-## 论证FullGC是否会回收元空间/永久代垃圾
-
-```Java
-/**
- * jdk6/7中:
- * -XX:PermSize=10m -XX:MaxPermSize=10m
- *
- * jdk8中:
- * -XX:MetaspaceSize=10m -XX:MaxMetaspaceSize=10m
- *
- * @author IceBlue
- * @create 2020 22:24
- */
-public class OOMTest extends ClassLoader {
- public static void main(String[] args) {
- int j = 0;
- try {
- for (int i = 0; i < 100000; i++) { - OOMTest test = new OOMTest(); - //创建ClassWriter对象,用于生成类的二进制字节码 - ClassWriter classWriter = new ClassWriter(0); - //指明版本号,修饰符,类名,包名,父类,接口 - classWriter.visit(Opcodes.V1_8, Opcodes.ACC_PUBLIC, "Class" + i, null, "java/lang/Object", null); - //返回byte[] - byte[] code = classWriter.toByteArray(); - //类的加载 - test.defineClass("Class" + i, code, 0, code.length);//Class对象 - test = null; - j++; - } - } finally { - System.out.println(j); - } - } -} -``` - -输出结果: - -``` -[GC (Metadata GC Threshold) [PSYoungGen: 10485K->1544K(152576K)] 10485K->1552K(500736K), 0.0011517 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
-[Full GC (Metadata GC Threshold) [PSYoungGen: 1544K->0K(152576K)] [ParOldGen: 8K->658K(236544K)] 1552K->658K(389120K), [Metaspace: 3923K->3320K(1056768K)], 0.0051012 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]
-[GC (Metadata GC Threshold) [PSYoungGen: 5243K->832K(152576K)] 5902K->1490K(389120K), 0.0009536 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
-
--------省略N行-------
-
-[Full GC (Last ditch collection) [PSYoungGen: 0K->0K(2427904K)] [ParOldGen: 824K->824K(5568000K)] 824K->824K(7995904K), [Metaspace: 3655K->3655K(1056768K)], 0.0041177 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
-Heap
- PSYoungGen total 2427904K, used 0K [0x0000000755f80000, 0x00000007ef080000, 0x00000007ffe00000)
- eden space 2426880K, 0% used [0x0000000755f80000,0x0000000755f80000,0x00000007ea180000)
- from space 1024K, 0% used [0x00000007ea180000,0x00000007ea180000,0x00000007ea280000)
- to space 1536K, 0% used [0x00000007eef00000,0x00000007eef00000,0x00000007ef080000)
- ParOldGen total 5568000K, used 824K [0x0000000602200000, 0x0000000755f80000, 0x0000000755f80000)
- object space 5568000K, 0% used [0x0000000602200000,0x00000006022ce328,0x0000000755f80000)
- Metaspace used 3655K, capacity 4508K, committed 9728K, reserved 1056768K
- class space used 394K, capacity 396K, committed 2048K, reserved 1048576K
-
-进程已结束,退出代码0
-
-```
-
-通过不断地动态生成类对象,输出GC日志
-
-根据GC日志我们可以看出当元空间容量耗尽时,会触发FullGC,而每次FullGC之前,至会进行一次MinorGC,而MinorGC只会回收新生代空间;
-
-只有在FullGC时,才会对新生代,老年代,永久代/元空间全部进行垃圾收集
\ No newline at end of file
diff --git "a/JDK/345円271円266円345円217円221円347円274円226円347円250円213円/Java344円277円241円345円217円267円351円207円217円346円250円241円345円236円213円Semaphore.md" "b/JDK/345円271円266円345円217円221円347円274円226円347円250円213円/Java344円277円241円345円217円267円351円207円217円346円250円241円345円236円213円Semaphore.md"
index 68b507ec2d..0c8437de80 100644
--- "a/JDK/345円271円266円345円217円221円347円274円226円347円250円213円/Java344円277円241円345円217円267円351円207円217円346円250円241円345円236円213円Semaphore.md"
+++ "b/JDK/345円271円266円345円217円221円347円274円226円347円250円213円/Java344円277円241円345円217円267円351円207円217円346円250円241円345円236円213円Semaphore.md"
@@ -1,55 +1,53 @@
-
-> 面试官一声冷笑:用过semaphore吧,说说信号量模型?
-
-信号量模型可简单概括为:一个计数器,一个等待队列,三个方法。在信号量模型里,计数器和等待队列对外是透明的,所以只能通过信号量模型提供的三个方法来访问它们,这三个方法分别是:init()、down()和up()。你可以结合下图来形象化地理解。
-
-- 信号量模型
+# 1 信号量模型
+## 1.1 模型示意图

-
-> 详细解释下里面提到的这些方法?
-
-- init()
+信号量模型可简单概括为:一个计数器,一个等待队列,三个方法。
+计数器和等待队列对外透明,所以只能通过信号量模型提供的三个方法来访问它们:
+## 1.2 三个方法
+### 1.2.1 init()
设置计数器初始值。
-- down()
+### 1.2.2 down()
计数器-1;若此时计数器<0,则当前线程被阻塞,否则当前线程可继续执行
-- up()
-计数器+1;若此时计数器≤0,则唤醒等待队列中的一个线程,并将其从等待队列中移除。有的人可能认为这里的判断条件应该≥0,估计你是理解生产者-消费者模式中的生产者。可这样思考,`>0` 意味着没有阻塞的线程,所以只有 ≤0 时才需要唤醒一个等待的线程。
+### 1.2.3 up()
+计数器+1;若此时计数器≤0,则唤醒等待队列中的一个线程,并将其从等待队列中移除。
+有的人可能认为这里的判断条件应该≥0,估计你是理解生产者-消费者模式中的生产者。可这样思考,`>0` 意味着无阻塞的线程,所以只有 ≤0 时才需唤醒一个等待的线程。
-down()和up()应该成对出现,并且先调用down()获取锁,处理完成后再调用up()释放锁。若信号量init值为1,应该不会出现>0情况,除非故意调先用up(),这也失去了信号量本身的意义了。
+down()和up()应成对出现 && 先调用down()获取锁,处理完成后再调用up()释放锁。若信号量init值为1,应该不会出现>0情况,除非故意调先用up(),这也失去了信号量本身的意义了。
这些方法都是原子性的,并且这个原子性是由信号量模型的实现方保证的。JDK里的信号量模型是由java.util.concurrent.Semaphore实现,Semaphore这个类能够保证这三个方法都是原子操作。
-
-> talk is cheap,show me code?
-
-- 代码
+## 1.3 代码实现

信号量模型中,down()、up()最早被称为P操作和V操作,信号量模型也称PV原语。还有的人会用semWait()和semSignal()表达它们,叫法不同,语义都相同。JUC的acquire()和release()就对应down()和up()。
-> 如何使用信号量?
-
+# 2 如何使用信号量?
+## 2.1 实例
就像红绿信号灯,车必须先检查是否为绿灯,绿灯才能通过。
比如累加器,count+=1操作是个临界区,只允许一个线程执行,也就是说要保证互斥。

-分析如下:假设线程t1、t2同时访问add(),当同时调用`acquire()`时,由于`acquire()`是一个原子操作,只可能有一个线程(假设t1)把信号量里的计数器减为0,t2则是将计数器减为-1:
+## 2.2 分析
+假设线程t1、t2同时访问add(),当同时调用`acquire()`时,由于`acquire()`是个原子操作,只可能有一个线程(假设t1)把信号量里的计数器减为0,t2则是将计数器减为-1:
- 对t1,信号量里面的计数器的值是0,≥0,所以t1继续执行
- 对t2,信号量里面的计数器的值是-1,<0,所以t2被阻塞
所以此时只有t1会进入临界区执行count+=1。
当t1执行release(),信号量里计数器的值是-1,加1之后的值是0,小于等于0,根据up()操作,此时等待队列中的t2会被唤醒。于是t2在t1执行完临界区代码后,才获得进入临界区执行的机会,这就保证了互斥性。
+## 2.3 既有JDK的Lock,为何还造个Semaphore?
+实现互斥锁,仅是 Semaphore的部分功能,还可允许多个线程访问一个临界区。
+最常见的就是各种池化资源:连接池、对象池、线程池等。比如数据库连接池,同一时刻,是允许多个线程同时使用连接池的。每个连接在被释放前,不允许其他线程使用。
-既然有JDK提供了Lock,为啥还要提供一个Semaphore ?实现互斥锁,仅是 Semaphore部分功能,Semaphore还可以允许多个线程访问一个临界区。
+对象池要求一次性创建出N个对象,之后所有线程重复利用这N个对象,当然对象在被释放前,不允许其他线程使用。所以核心就是限流器的设计:不允许多于N个线程同时进入临界区。
-最常见的就是各种池化资源:连接池、对象池、线程池等。比如数据库连接池,同一时刻,一定是允许多个线程同时使用连接池的。每个连接在被释放前,是不允许其他线程使用的。
+那如何快速实现一个这样的限流器呢?
+信号量!
+若把计数器的值设置成对象池里对象的个数N,就能完美解决对象池的限流问题。
-对象池要求一次性创建出N个对象,之后所有的线程重复利用这N个对象,当然对象在被释放前,也是不允许其他线程使用的。所以核心就是限流器的设计,这里限流指不允许多于N个线程同时进入临界区。
-如何快速实现一个这样的限流器呢?那就是信号量。
-如果我们把计数器的值设置成对象池里对象的个数N,就能完美解决对象池的限流问题了。
代码如下:

+
注意这里使用的是 Vector,进入临界区的N个线程不安全。add/remove都是不安全的。比如 ArrayList remove() :
```java
public E remove(int index) {
@@ -68,8 +66,4 @@ public E remove(int index) {
return oldValue;
}
-```
-
-
-
-> 好的,请回家等通知吧!
\ No newline at end of file
+```
\ No newline at end of file
diff --git "a/JDK/345円271円266円345円217円221円347円274円226円347円250円213円/Java345円271円266円345円217円221円347円274円226円347円250円213円345円256円236円346円210円230円/Java345円271円266円345円217円221円347円274円226円347円250円213円345円256円236円346円210円230円347円263円273円345円210円227円(15)-345円216円237円345円255円220円351円201円215円345円216円206円344円270円216円351円235円236円351円230円273円345円241円236円345円220円214円346円255円245円346円234円272円345円210円266円.md" "b/JDK/345円271円266円345円217円221円347円274円226円347円250円213円/Java345円271円266円345円217円221円347円274円226円347円250円213円345円256円236円346円210円230円/Java345円271円266円345円217円221円347円274円226円347円250円213円345円256円236円346円210円230円347円263円273円345円210円22715円344円271円213円345円216円237円345円255円220円351円201円215円345円216円206円344円270円216円351円235円236円351円230円273円345円241円236円345円220円214円346円255円245円346円234円272円345円210円266円(Atomic-Variables-and-Non-blocking-Synchron.md"
similarity index 68%
rename from "JDK/345円271円266円345円217円221円347円274円226円347円250円213円/Java345円271円266円345円217円221円347円274円226円347円250円213円345円256円236円346円210円230円/Java345円271円266円345円217円221円347円274円226円347円250円213円345円256円236円346円210円230円347円263円273円345円210円227円(15)-345円216円237円345円255円220円351円201円215円345円216円206円344円270円216円351円235円236円351円230円273円345円241円236円345円220円214円346円255円245円346円234円272円345円210円266円.md"
rename to "JDK/345円271円266円345円217円221円347円274円226円347円250円213円/Java345円271円266円345円217円221円347円274円226円347円250円213円345円256円236円346円210円230円/Java345円271円266円345円217円221円347円274円226円347円250円213円345円256円236円346円210円230円347円263円273円345円210円22715円344円271円213円345円216円237円345円255円220円351円201円215円345円216円206円344円270円216円351円235円236円351円230円273円345円241円236円345円220円214円346円255円245円346円234円272円345円210円266円(Atomic-Variables-and-Non-blocking-Synchron.md"
index 5aece1fb28..13eabf7add 100644
--- "a/JDK/345円271円266円345円217円221円347円274円226円347円250円213円/Java345円271円266円345円217円221円347円274円226円347円250円213円345円256円236円346円210円230円/Java345円271円266円345円217円221円347円274円226円347円250円213円345円256円236円346円210円230円347円263円273円345円210円227円(15)-345円216円237円345円255円220円351円201円215円345円216円206円344円270円216円351円235円236円351円230円273円345円241円236円345円220円214円346円255円245円346円234円272円345円210円266円.md"
+++ "b/JDK/345円271円266円345円217円221円347円274円226円347円250円213円/Java345円271円266円345円217円221円347円274円226円347円250円213円345円256円236円346円210円230円/Java345円271円266円345円217円221円347円274円226円347円250円213円345円256円236円346円210円230円347円263円273円345円210円22715円344円271円213円345円216円237円345円255円220円351円201円215円345円216円206円344円270円216円351円235円236円351円230円273円345円241円236円345円220円214円346円255円245円346円234円272円345円210円266円(Atomic-Variables-and-Non-blocking-Synchron.md"
@@ -1,30 +1,32 @@
-非阻塞算法,用底层的原子机器指令代替锁,确保数据在并发访问中的一致性。
-非阻塞算法被广泛应用于OS和JVM中实现线程/进程调度机制和GC及锁,并发数据结构中。
+近年并发算法领域大多数研究都侧重非阻塞算法,这种算法用底层的原子机器指令代替锁来确保数据在并发访问中的一致性,非阻塞算法被广泛应用于OS和JVM中实现线程/进程调度机制和GC以及锁,并发数据结构中。
+
+与锁的方案相比,非阻塞算法都要复杂的多,他们在可伸缩性和活跃性上(避免死锁)都有巨大优势。
-与锁相比,非阻塞算法复杂的多,在可伸缩性和活跃性上(避免死锁)有巨大优势。
非阻塞算法,即多个线程竞争相同的数据时不会发生阻塞,因此能更细粒度的层次上进行协调,而且极大减少调度开销。
# 1 锁的劣势
独占,可见性是锁要保证的。
-许多JVM都对非竞争的锁获取和释放做了很多优化,性能很不错。
-但若一些线程被挂起然后稍后恢复运行,当线程恢复后还得等待其他线程执行完他们的时间片,才能被调度,所以挂起和恢复线程存在很大开销。
-其实很多锁的粒度很小,很简单,若锁上存在激烈竞争,那么 调度开销/工作开销 比值就会非常高,降低业务吞吐量。
+许多JVM都对非竞争的锁获取和释放做了很多优化,性能很不错了。
+
+但是如果一些线程被挂起然后稍后恢复运行,当线程恢复后还得等待其他线程执行完他们的时间片,才能被调度,所以挂起和恢复线程存在很大的开销,其实很多锁的力度很小的,很简单,如果锁上存在着激烈的竞争,那么多调度开销/工作开销比值就会非常高。
+
+与锁相比volatile是一种更轻量的同步机制,因为使用volatile不会发生上下文切换或者线程调度操作,但是volatile的指明问题就是虽然保证了可见性,但是原子性无法保证,比如i++的字节码就是N行。
-而与锁相比,volatile是一种更轻量的同步机制,因为使用volatile不会发生上下文切换或线程调度操作,但volatile的指明问题就是虽然保证了可见性,但是原子性无法保证。
+如果一个线程正在等待锁,它不能做任何事情,如果一个线程在持有锁的情况下呗延迟执行了,例如发生了缺页错误,调度延迟,那么就没法执行。如果被阻塞的线程优先级较高,那么就会出现priority invesion的问题,被永久的阻塞下去。
-- 若一个线程正在等待锁,它不能做任何事情
-- 若一个线程在持有锁情况下被延迟执行了,如发生缺页错误,调度延迟,就没法执行
-- 若被阻塞的线程优先级较高,就会出现priority invesion问题,被永久阻塞
# 2 硬件对并发的支持
-独占锁是悲观锁,对细粒度的操作,更高效的应用是乐观锁,这种方法需要借助**冲突监测机制,来判断更新过程中是否存在来自其他线程的干扰,若存在,则失败重试**。
-几乎所有现代CPU都有某种形式的原子读-改-写指令,如compare-and-swap等,JVM就是使用这些指令来实现无锁并发。
+独占锁是悲观所,对于细粒度的操作,更高效的应用是乐观锁,这种方法需要借助**冲突监测机制来判断更新过程中是否存在来自其他线程的干扰,如果存在则失败重试**。
+
+几乎所有的现代CPU都有某种形式的原子读-改-写指令,例如compare-and-swap等,JVM就是使用这些指令来实现无锁并发。
+
## 2.1 比较并交换
+
CAS(Compare and set)乐观的技术。Java实现的一个compare and set如下,这是一个模拟底层的示例:
+
```java
@ThreadSafe
public class SimulatedCAS {
-
@GuardedBy("this") private int value;
public synchronized int get() {
@@ -45,7 +47,9 @@ public class SimulatedCAS {
== compareAndSwap(expectedValue, newValue));
}
}
+
```
+
## 2.2 非阻塞的计数器
```java
public class CasCounter {
@@ -63,12 +67,14 @@ public class CasCounter {
return v + 1;
}
}
+
```
Java中使用AtomicInteger。
竞争激烈一般时,CAS性能远超基于锁的计数器。看起来他的指令更多,但无需上下文切换和线程挂起,JVM内部的代码路径实际很长,所以反而好些。
-但激烈程度较高时,开销还是较大,但会发生这种激烈程度非常高的情况只是理论,实际生产环境很难遇到。况且JIT很聪明,这种操作往往能非常大的优化。
+但激烈程度较高时,它的开销还是较大,但是你会发生这种激烈程度非常高的情况只是理论,实际生产环境很难遇到。
+况且JIT很聪明,这种操作往往能非常大的优化。
为确保正常更新,可能得将CAS操作放到for循环,从语法结构看,使用**CAS**比使用锁更加复杂,得考虑失败情况(锁会挂起线程,直到恢复)。
但基于**CAS**的原子操作,性能基本超过基于锁的计数器,即使只有很小的竞争或不存在竞争!
@@ -76,19 +82,37 @@ Java中使用AtomicInteger。
在轻度到中度争用情况下,非阻塞算法的性能会超越阻塞算法,因为 CAS 的多数时间都在第一次尝试时就成功,而发生争用时的开销也不涉及**线程挂起**和**上下文切换**,只多了几个循环迭代。
没有争用的 CAS 要比没有争用的锁轻量得多(因为没有争用的锁涉及 CAS 加上额外的处理,加锁至少需要一个CAS,在有竞争的情况下,需要操作队列,线程挂起,上下文切换),而争用的 CAS 比争用的锁获取涉及更短的延迟。
-CAS的缺点是,它使用调用者来处理竞争问题,通过重试、回退、放弃,而锁能自动处理竞争问题,例如阻塞。
+CAS的缺点是它使用调用者来处理竞争问题,通过重试、回退、放弃,而锁能自动处理竞争问题,例如阻塞。
-原子变量可看做更好的volatile类型变量。AtomicInteger在JDK8里面做了改动。
-
+原子变量可以看做更好的volatile类型变量。
+AtomicInteger在JDK8里面做了改动。
+```java
+public final int getAndIncrement() {
+ return unsafe.getAndAddInt(this, valueOffset, 1);
+}
+
+```
JDK7里面的实现如下:
-
-Unsafe是经过特殊处理的,不能理解成常规的Java代码,1.8在调用getAndAddInt时,若系统底层:
-- 支持fetch-and-add,则执行的就是native方法,使用fetch-and-add
-- 不支持,就按照上面getAndAddInt那样,以Java代码方式执行,使用compare-and-swap
+```java
+public final int getAndAdd(int delta) {
+ for(;;) {
+ intcurrent= get();
+ intnext=current+delta;
+ if(compareAndSet(current,next))
+ returncurrent;
+ }
+ }
+
+```
+Unsafe是经过特殊处理的,不能理解成常规的Java代码,区别在于:
+- 1.8在调用getAndAddInt的时候,如果系统底层支持fetch-and-add,那么它执行的就是native方法,使用的是fetch-and-add
+- 如果不支持,就按照上面的所看到的getAndAddInt方法体那样,以java代码的方式去执行,使用的是compare-and-swap
这也正好跟openjdk8中Unsafe::getAndAddInt上方的注释相吻合:
-以下包含在不支持本机指令的平台上使用的基于 CAS 的 Java 实现
-
+```java
+// The following contain CAS-based Java implementations used on
+// platforms not supporting native instructions
+```
# 3 原子变量类
J.U.C的AtomicXXX。
@@ -140,11 +164,18 @@ public class CasNumberRange {
}
}
}
+
```
+
+
# 4 非阻塞算法
+
Lock-free算法,可以实现栈、队列、优先队列或者散列表。
+
## 4.1 非阻塞的栈
-Trebier算法,1986年提出。
+
+Trebier算法,1986年提出的。
+
```java
public class ConcurrentStack {
AtomicReference> top = new AtomicReference>();
@@ -179,9 +210,13 @@ Trebier算法,1986年提出。
}
}
}
+
```
+
## 4.2 非阻塞的链表
-J.U.C的ConcurrentLinkedQueue也是参考这个由Michael and Scott,1996年实现的算法。
+
+有点复杂哦,实际J.U.C的ConcurrentLinkedQueue也是参考了这个由Michael and Scott,1996年实现的算法。
+
```java
public class LinkedQueue {
@@ -222,14 +257,19 @@ public class LinkedQueue {
}
}
}
+
```
+
## 4.3 原子域更新
-AtomicReferenceFieldUpdater,一个基于反射的工具类,能对指定类的指定的volatile引用字段进行原子更新。(该字段不能是private的)
+
+AtomicReferenceFieldUpdater,一个基于反射的工具类,它能对指定类的指定的volatile引用字段进行原子更新。(注意这个字段不能是private的)
通过调用AtomicReferenceFieldUpdater的静态方法newUpdater就能创建它的实例,该方法要接收三个参数:
+
* 包含该字段的对象的类
* 将被更新的对象的类
* 将被更新的字段的名称
+
```java
AtomicReferenceFieldUpdater updater=AtomicReferenceFieldUpdater.newUpdater(Dog.class,String.class,"name");
Dog dog1=new Dog();
@@ -239,4 +279,5 @@ AtomicReferenceFieldUpdater updater=AtomicReferenceFieldUpdater.newUpdater(Dog.c
class Dog {
volatile String name="dog1";
}
+
```
\ No newline at end of file
diff --git "a/JDK/345円271円266円345円217円221円347円274円226円347円250円213円/Java351円253円230円346円200円247円350円203円275円347円274円226円347円250円213円345円256円236円346円210円230円 --- ThreadPoolExecutor-347円272円277円347円250円213円346円261円240円.md" "b/JDK/345円271円266円345円217円221円347円274円226円347円250円213円/Java351円253円230円346円200円247円350円203円275円347円274円226円347円250円213円345円256円236円346円210円230円 --- ThreadPoolExecutor-347円272円277円347円250円213円346円261円240円.md"
deleted file mode 100644
index e0cd2e89b7..0000000000
--- "a/JDK/345円271円266円345円217円221円347円274円226円347円250円213円/Java351円253円230円346円200円247円350円203円275円347円274円226円347円250円213円345円256円236円346円210円230円 --- ThreadPoolExecutor-347円272円277円347円250円213円346円261円240円.md"
+++ /dev/null
@@ -1,1272 +0,0 @@
-# 1 为什么要用线程池
-## 1.1 线程the more, the better?
-1、线程在java中是一个对象,更是操作系统的资源,线程创建、销毁都需要时间。
-如果创建时间+销毁时间>执行任务时间就很不合算。
-2、Java对象占用堆内存,操作系统线程占用系统内存,根据JVM规范,一个线程默认最大栈
-大小1M,这个栈空间是需要从系统内存中分配的。线程过多,会消耗很多的内存。
-3、操作系统需要频繁切换线程上下文(大家都想被运行),影响性能。
-
-线程使应用能够更加充分合理地协调利用CPU、内存、网络、I/O等系统资源.
-线程的创建需要开辟虚拟机栈、本地方法栈、程序计数器等线程私有的内存空间;
-在线程销毁时需要回收这些系统资源.
-频繁地创建和销毁线程会浪费大量的系统资源,增加并发编程风险.
-
-在服务器负载过大的时候,如何让新的线程等待或者友好地拒绝服务?
-
-这些都是线程自身无法解决的;
-所以需要通过线程池协调多个线程,并实现类似主次线程隔离、定时执行、周期执行等任务.
-
-# 2 线程池的作用
-●くろまる 利用线程池管理并复用线程、控制最大并发数等
-
-●くろまる 实现任务线程队列缓存策略和拒绝机制
-
-●くろまる 实现某些与时间相关的功能
-如定时执行、周期执行等
-
-●くろまる 隔离线程环境
-比如,交易服务和搜索服务在同一台服务器上,分别开启两个线程池,交易线程的资源消耗明显要大;
-因此,通过配置独立的线程池,将较慢的交易服务与搜索服务隔离开,避免各服务线程相互影响.
-
-在开发中,合理地使用线程池能够带来3个好处
- - **降低资源消耗** 通过重复利用已创建的线程,降低创建和销毁线程造成的系统资源消耗
- - **提高响应速度** 当任务到达时,任务可以不需要等到线程创建就能立即执行
- - **提高线程的可管理性** 线程是稀缺资源,如果过多地创建,不仅会消耗系统资源,还会降低系统的稳定性,导致使用线程池可以进行统一分配、调优和监控。
-
-# 3 概念
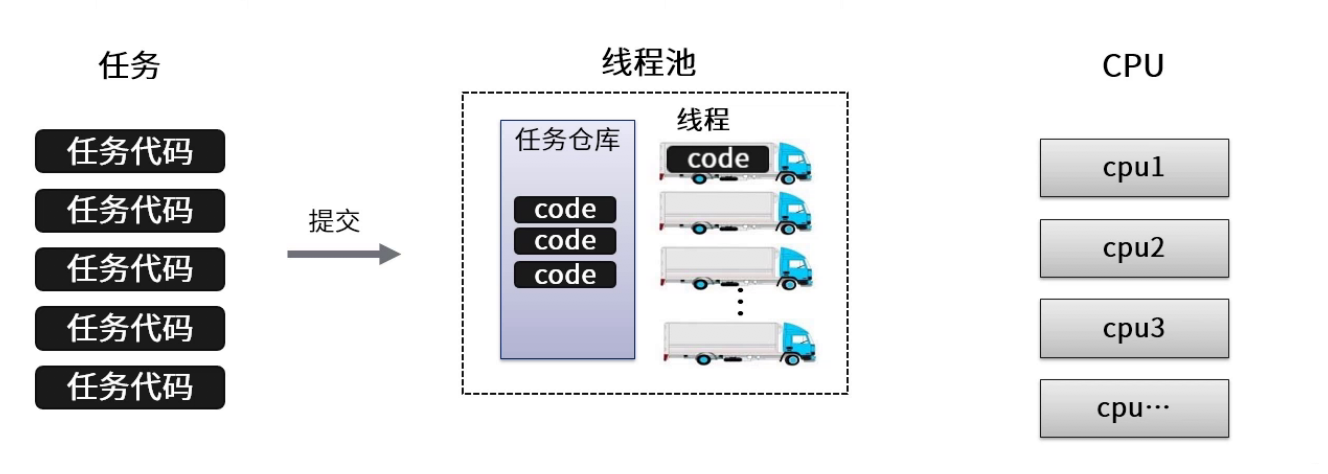
-1、**线程池管理器**
-用于创建并管理线程池,包括创建线程池,销毁线程池,添加新任务;
-2、**工作线程**
-线程池中线程,在没有任务时处于等待状态,可以循环的执行任务;
-3、**任务接口**
-每个任务必须实现的接口,以供工作线程调度任务的执行,它主要规定了任务的入口,任务执行完后的收尾工作,任务的执行状态等;
-4、**任务队列**
-用于存放没有处理的任务。提供缓冲机制。.
-
-- 原理示意图
-
-
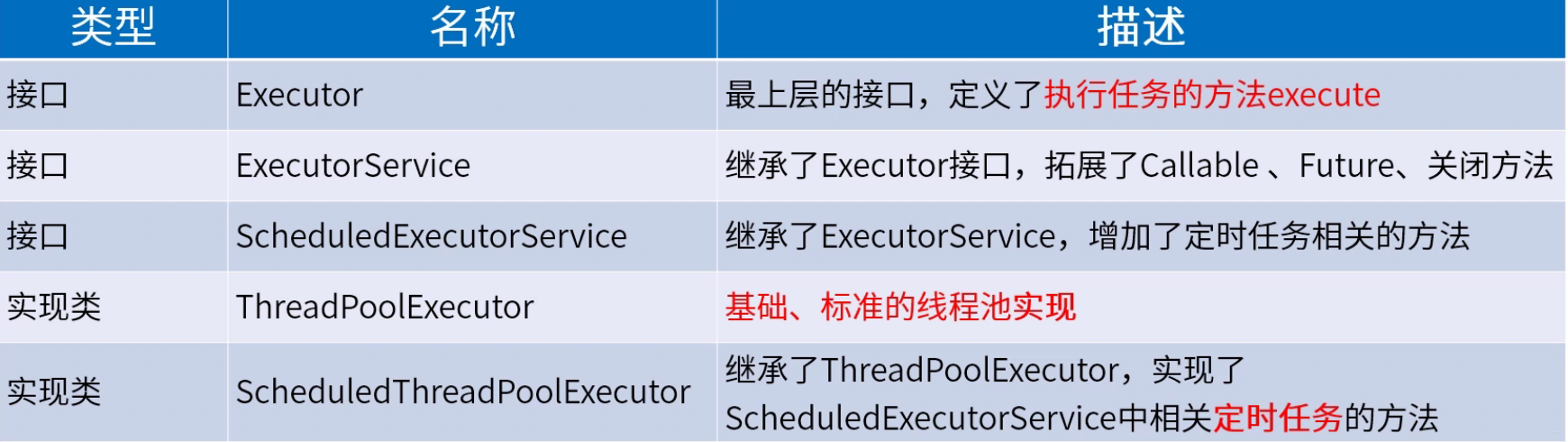
-# 4 线程池API
-## 4.1 接口定义和实现类
-
-### 继承关系图
-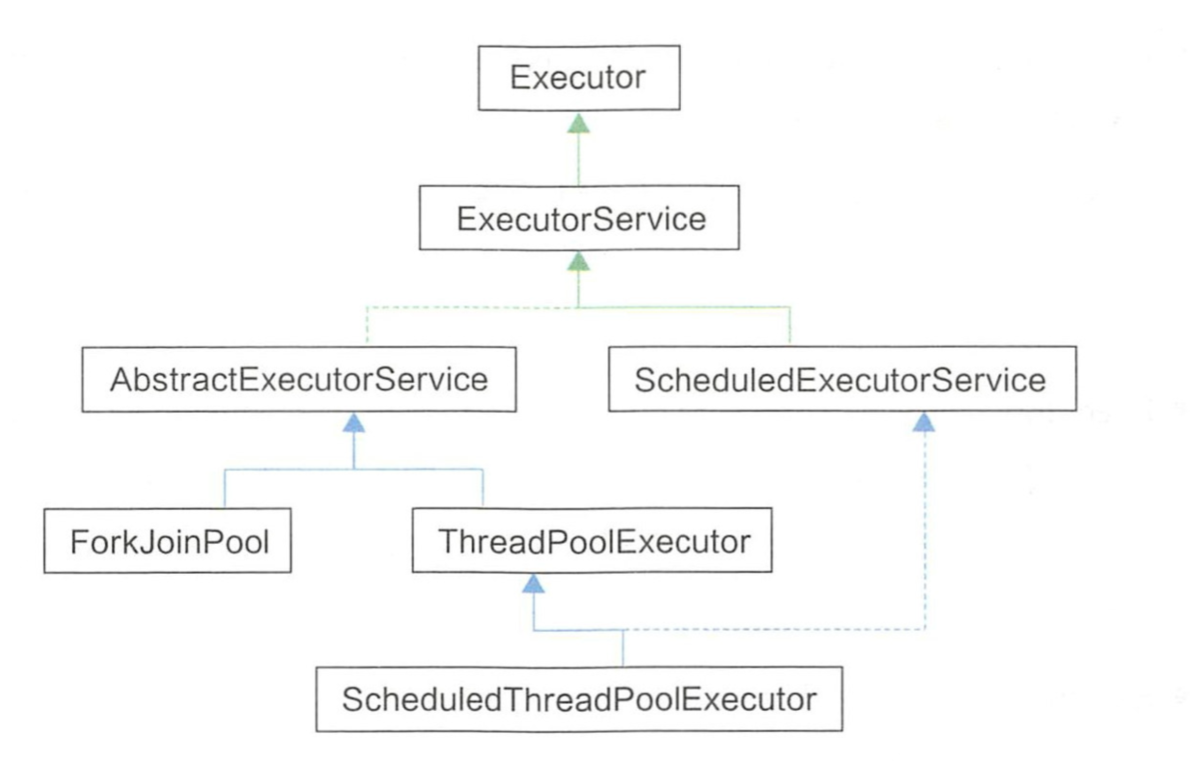
-可以认为ScheduledThreadPoolExecutor是最丰富的实现类!
-
-## 4.2 方法定义
-### 4.2.1 ExecutorService
-
-
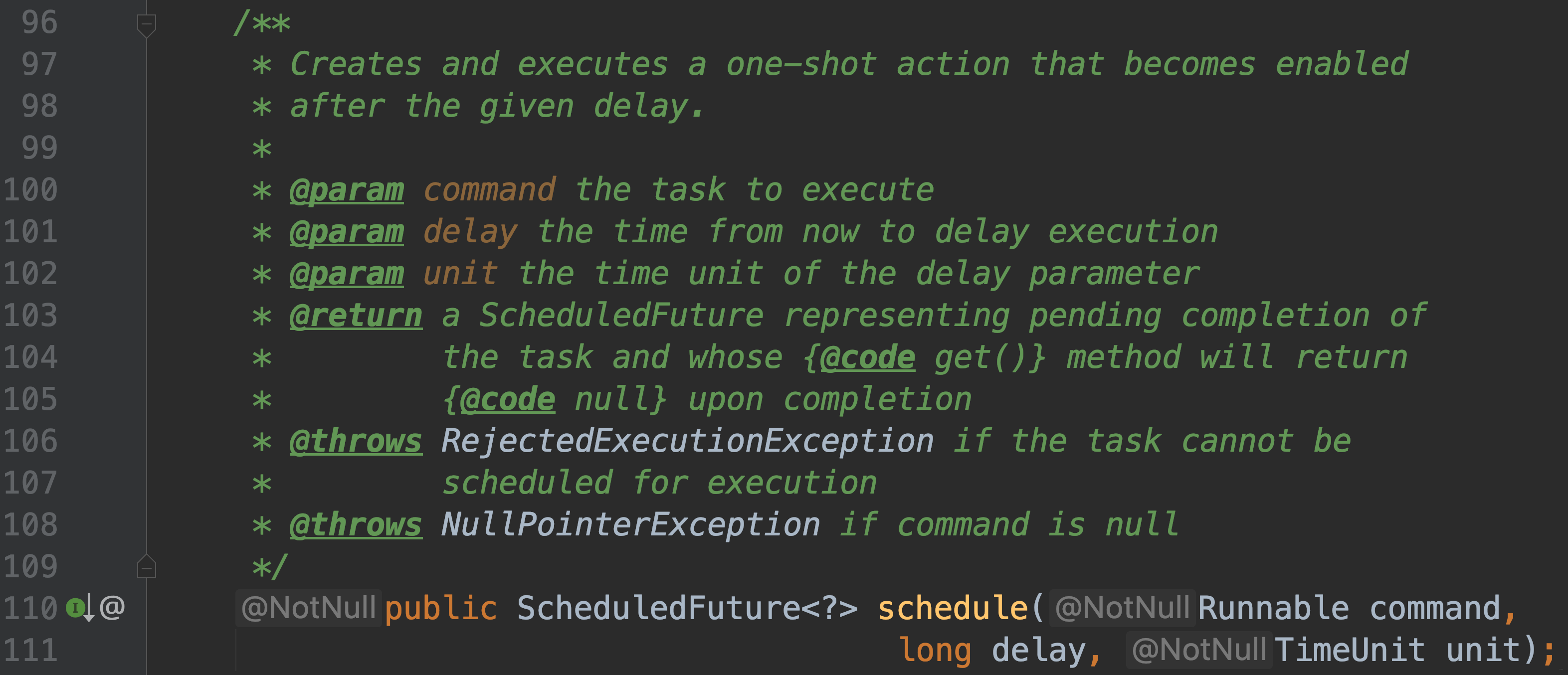
-### 4.2.2 ScheduledExecutorService
-#### public ScheduledFuture schedule(Runnable command, long delay, TimeUnit unit);
-
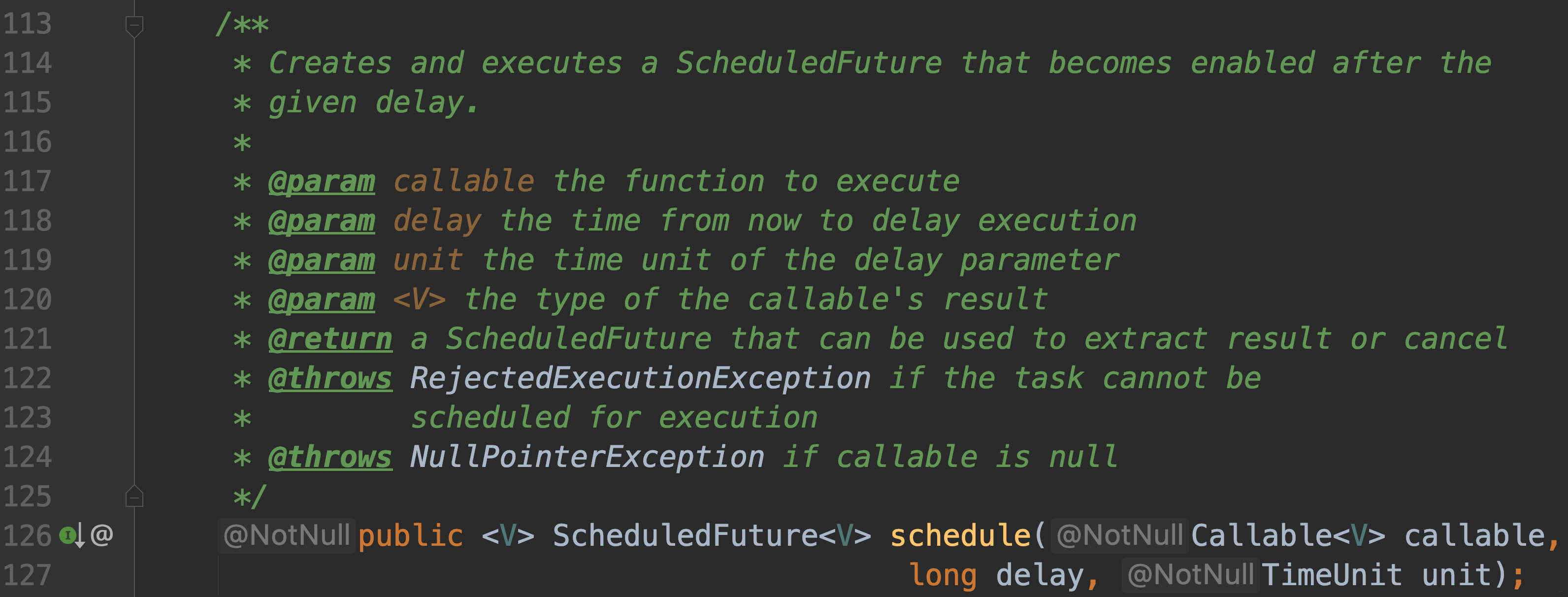
-#### public ScheduledFuture schedule(Callable callable, long delay, TimeUnit unit);
-
-
-#### 以上两种都是创建并执行一个一次性任务, 过了延迟时间就会被执行
-#### public ScheduledFuture scheduleAtFixedRate(Runnable command, long initialDelay, long period, TimeUnit unit);
-
-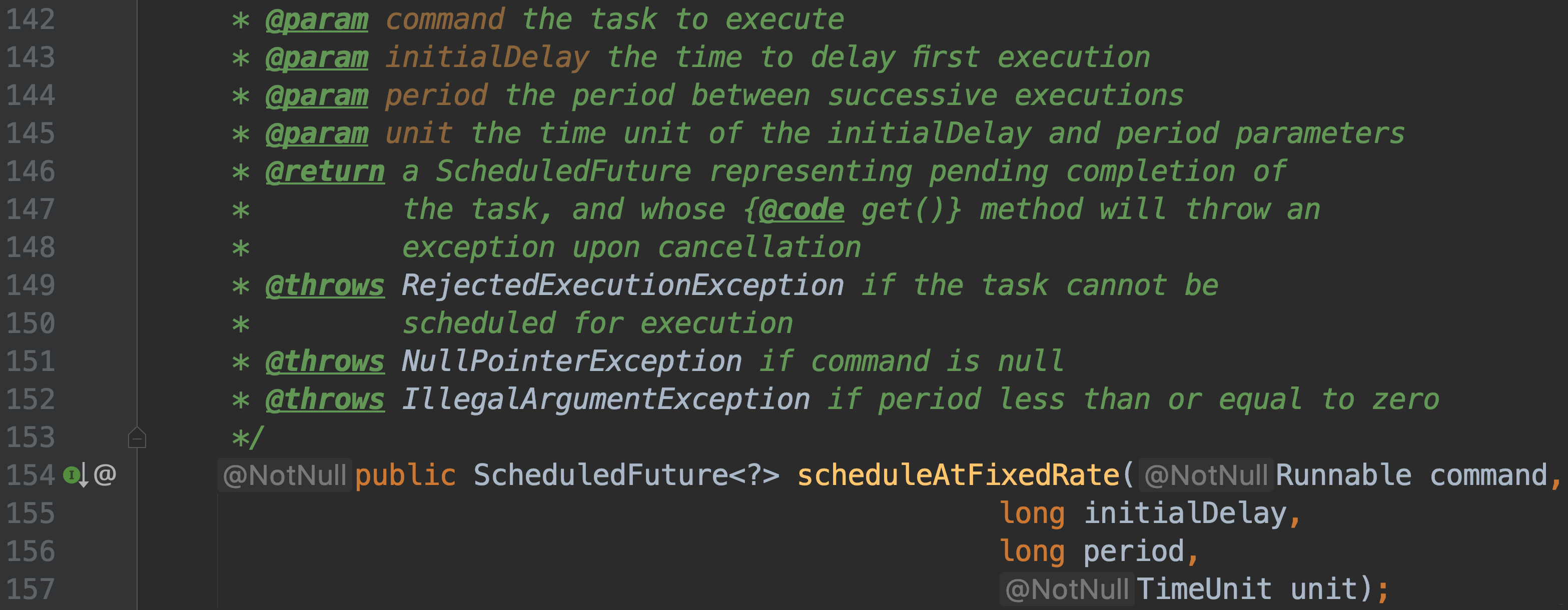
-创建并执行一个周期性任务
-过了给定的初始延迟时间,会第一次被执行
-执行过程中发生了异常,那么任务就停止
-
-一次任务 执行时长超过了周期时间,下一次任务会等到该次任务执行结束后,立刻执行,这也是它和`scheduleWithFixedDelay`的重要区别
-
-#### public ScheduledFuture scheduleWithFixedDelay(Runnable command, long initialDelay, long delay, TimeUnit unit);
-创建并执行一个周期性任务
-过了初始延迟时间,第一次被执行,后续以给定的周期时间执行
-执行过程中发生了异常,那么任务就停止
-
-一次任务执行时长超过了周期时间,下一 次任务 会在该次任务执
-行结束的时间基础上,计算执行延时。
-对于超过周期的长时间处理任务的不同处理方式,这是它和`scheduleAtFixedRate`的重要区别。
-
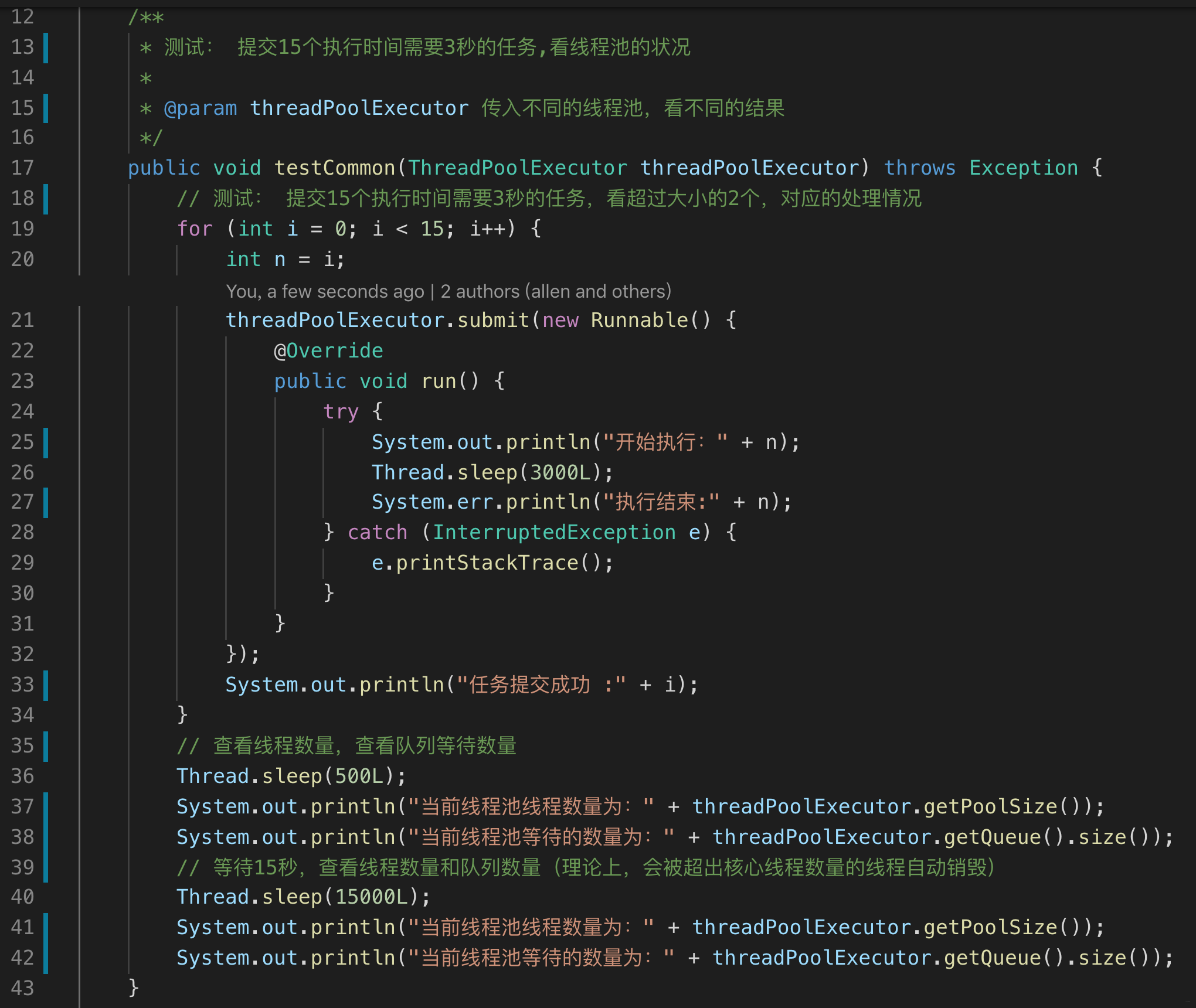
-### 实例
-- 测试例子
-
-- 测试实现
-
-- 运行结果
-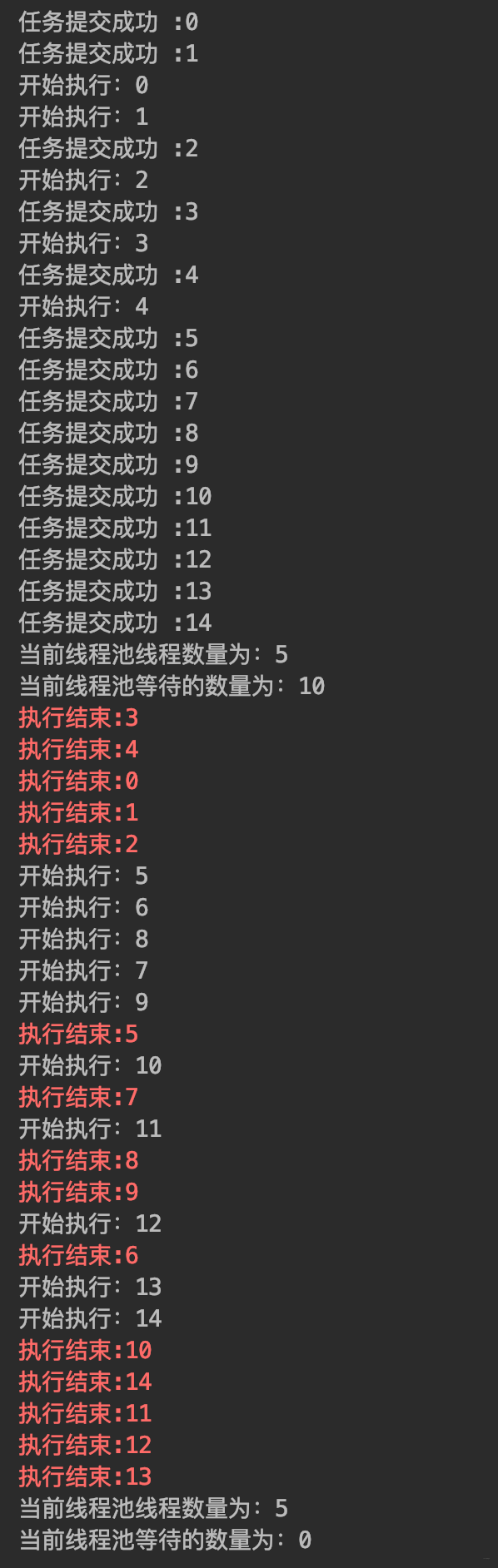
-可以看出超过core的线程都在等待,线程池线程数量为何达不到最大线程数呢?那这个参数还有什么意义, 让我们继续往下阅读吧!
-
-
-### 4.2.2 Executors工具类
-你可以自己实例化线程池,也可以用`Executors`创建线程池的工厂类,常用方法如下:
-
-`ExecutorService` 的抽象类`AbstractExecutorService `提供了`submit`、`invokeAll` 等方法的实现;
-但是核心方法`Executor.execute()`并没有在这里实现.
-因为所有的任务都在该方法执行,不同实现会带来不同的执行策略.
-
-通过`Executors`的静态工厂方法可以创建三个线程池的包装对象
-- ForkJoinPool、
-- ThreadPoolExecutor
-- ScheduledThreadPoolExecutor
-
-●くろまる Executors.newWorkStealingPool
-JDK8 引入,创建持有足够线程的线程池支持给定的并行度;
-并通过使用多个队列减少竞争;
-构造方法中把CPU数量设置为默认的并行度.
-返回`ForkJoinPool` ( JDK7引入)对象,它也是`AbstractExecutorService` 的子类
-
-
-
-●くろまる Executors.newCachedThreadPool
-创建的是一个无界的缓冲线程池。它的任务队列是一个同步队列。
-任务加入到池中
-- 如果池中有空闲线程,则用空闲线程执行
-- 如无, 则创建新线程执行。
-
-池中的线程空闲超过60秒,将被销毁。线程数随任务的多少变化。
-`适用于执行耗时较小的异步任务`。池的核心线程数=0 ,最大线程数= Integer.MAX_ _VALUE
-`maximumPoolSize` 最大可以至`Integer.MAX_VALUE`,是高度可伸缩的线程池.
-若达到该上限,相信没有服务器能够继续工作,直接OOM.
-`keepAliveTime` 默认为60秒;
-工作线程处于空闲状态,则回收工作线程;
-如果任务数增加,再次创建出新线程处理任务.
-
-●くろまる Executors.newScheduledThreadPool
-能定时执行任务的线程池。该池的核心线程数由参数指定,线程数最大至`Integer.MAX_ VALUE`,与上述相同,存在OOM风险.
-`ScheduledExecutorService`接口的实现类,支持**定时及周期性任务执行**;
-相比`Timer`,` ScheduledExecutorService` 更安全,功能更强大.
-与`newCachedThreadPool`的区别是**不回收工作线程**.
-
-●くろまる Executors.newSingleThreadExecutor
-创建一个单线程的线程池,相当于单线程串行执行所有任务,保证按任务的提交顺序依次执行.
-只有-个线程来执行无界任务队列的单-线程池。该线程池确保任务按加入的顺序一个一
-个依次执行。当唯一的线程因任务 异常中止时,将创建一个新的线程来继续执行 后续的任务。
-与newFixedThreadPool(1)的区别在于,单线程池的池大小在`newSingleThreadExecutor`方法中硬编码,不能再改变的。
-
-
-●くろまる Executors.newFixedThreadPool
-创建一个固定大小任务队列容量无界的线程池
-输入的参数即是固定线程数;
-既是核心线程数也是最大线程数;
-不存在空闲线程,所以`keepAliveTime`等于0.
-
-其中使用了 LinkedBlockingQueue, 但是没有设置上限!!!,堆积过多任务!!!
-
-下面介绍`LinkedBlockingQueue`的构造方法
-
-使用这样的无界队列,如果瞬间请求非常大,会有OOM的风险;
-除`newWorkStealingPool` 外,其他四个创建方式都存在资源耗尽的风险.
-
-不推荐使用其中的任何创建线程池的方法,因为都没有任何限制,存在安全隐患.
-
- `Executors`中默认的线程工厂和拒绝策略过于简单,通常对用户不够友好.
-线程工厂需要做创建前的准备工作,对线程池创建的线程必须明确标识,就像药品的生产批号一样,为线程本身指定有意义的名称和相应的序列号.
-拒绝策略应该考虑到业务场景,返回相应的提示或者友好地跳转.
-以下为简单的ThreadFactory 示例
-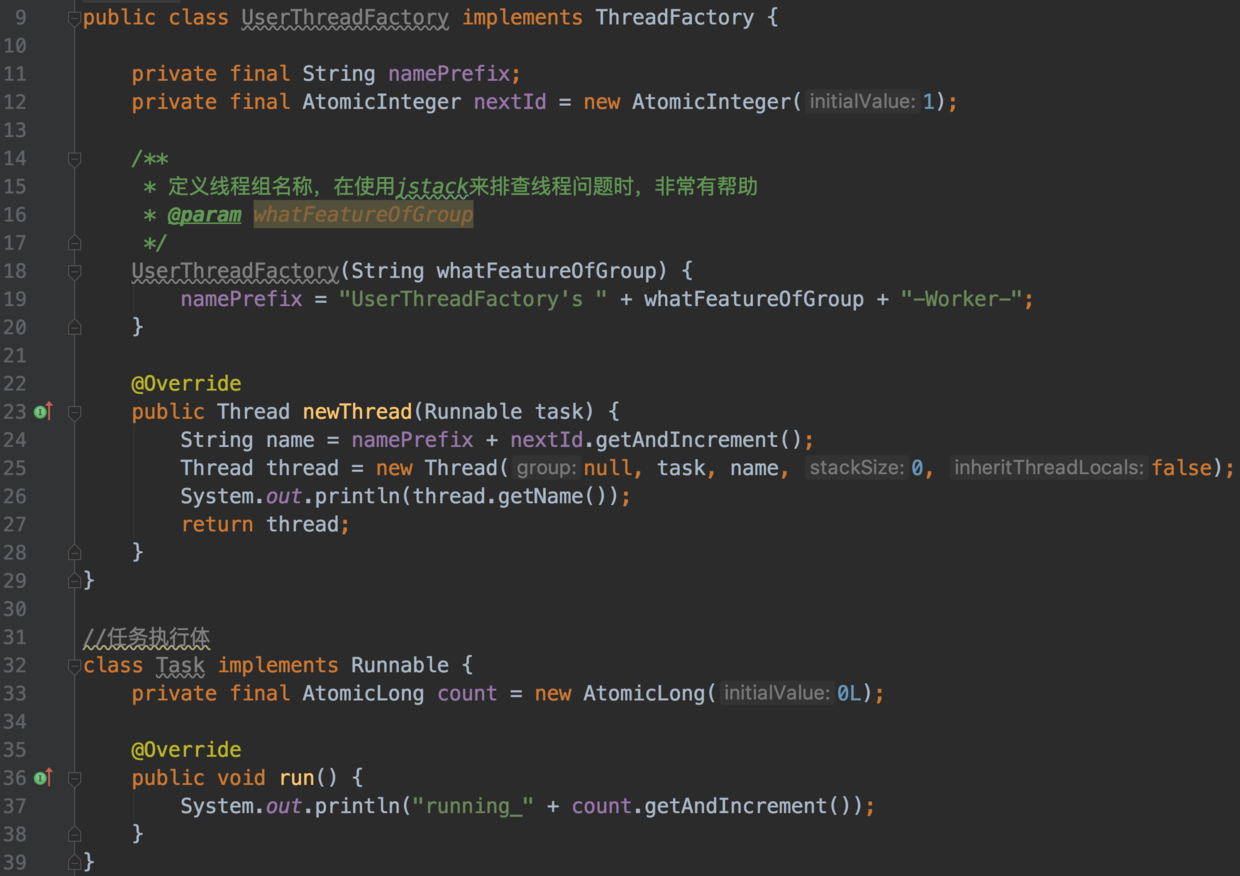
-
-上述示例包括线程工厂和任务执行体的定义;
-通过newThread方法快速、统一地创建线程任务,强调线程一定要有特定意义的名称,方便出错时回溯.
-
-- 单线程池:newSingleThreadExecutor()方法创建,五个参数分别是ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue())。含义是池中保持一个线程,最多也只有一个线程,也就是说这个线程池是顺序执行任务的,多余的任务就在队列中排队。
-- 固定线程池:newFixedThreadPool(nThreads)方法创建
-[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NZEi0e3y-1570557031347)(https://uploadfiles.nowcoder.com/images/20190625/5088755_1561474494512_5D0DD7BCB7171E9002EAD3AEF42149E6 "图片标题")]
-
-池中保持nThreads个线程,最多也只有nThreads个线程,多余的任务也在队列中排队。
-[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SId8FBO1-1570557031347)(https://uploadfiles.nowcoder.com/images/20190625/5088755_1561476084467_4A47A0DB6E60853DEDFCFDF08A5CA249 "图片标题")]
-
-[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6uzv6UAk-1570557031348)(https://uploadfiles.nowcoder.com/images/20190625/5088755_1561476102425_FB5C81ED3A220004B71069645F112867 "图片标题")]
-线程数固定且线程不超时
-- 缓存线程池:newCachedThreadPool()创建,五个参数分别是ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue())。
-含义是池中不保持固定数量的线程,随需创建,最多可以创建Integer.MAX_VALUE个线程(说一句,这个数量已经大大超过目前任何操作系统允许的线程数了),空闲的线程最多保持60秒,多余的任务在SynchronousQueue(所有阻塞、并发队列在后续文章中具体介绍)中等待。
-
-为什么单线程池和固定线程池使用的任务阻塞队列是LinkedBlockingQueue(),而缓存线程池使用的是SynchronousQueue()呢?
-因为单线程池和固定线程池中,线程数量是有限的,因此提交的任务需要在LinkedBlockingQueue队列中等待空余的线程;而缓存线程池中,线程数量几乎无限(上限为Integer.MAX_VALUE),因此提交的任务只需要在SynchronousQueue队列中同步移交给空余线程即可。
-
-- 单线程调度线程池:newSingleThreadScheduledExecutor()创建,五个参数分别是 (1, Integer.MAX_VALUE, 0, NANOSECONDS, new DelayedWorkQueue())。含义是池中保持1个线程,多余的任务在DelayedWorkQueue中等待。
-- 固定调度线程池:newScheduledThreadPool(n)创建,五个参数分别是 (n, Integer.MAX_VALUE, 0, NANOSECONDS, new DelayedWorkQueue())。含义是池中保持n个线程,多余的任务在DelayedWorkQueue中等待。
-
-有一项技术可以缓解执行时间较长任务造成的影响,即限定任务等待资源的时间,而不要无限的等待
-
-先看第一个例子,测试单线程池、固定线程池和缓存线程池(注意增加和取消注释):
-
-```
-public class ThreadPoolExam {
- public static void main(String[] args) {
- //first test for singleThreadPool
- ExecutorService pool = Executors.newSingleThreadExecutor();
- //second test for fixedThreadPool
-// ExecutorService pool = Executors.newFixedThreadPool(2);
- //third test for cachedThreadPool
-// ExecutorService pool = Executors.newCachedThreadPool();
- for (int i = 0; i < 5; i++) { - pool.execute(new TaskInPool(i)); - } - pool.shutdown(); - } -} - -class TaskInPool implements Runnable { - private final int id; - - TaskInPool(int id) { - this.id = id; - } - - @Override - public void run() { - try { - for (int i = 0; i < 5; i++) { - System.out.println("TaskInPool-["+id+"] is running phase-"+i); - TimeUnit.SECONDS.sleep(1); - } - System.out.println("TaskInPool-["+id+"] is over"); - } catch (InterruptedException e) { - e.printStackTrace(); - } - } -} -``` - -如图为排查底层公共缓存调用出错时的截图 - -绿色框采用自定义的线程工厂,明显比蓝色框默认的线程工厂创建的线程名称拥有更多的额外信息:如调用来源、线程的业务含义,有助于快速定位到死锁、StackOverflowError 等问题. - -# 5 创建线程池 -首先从`ThreadPoolExecutor`构造方法讲起,学习如何自定义`ThreadFactory`和`RejectedExecutionHandler`; -并编写一个最简单的线程池示例. -然后,通过分析`ThreadPoolExecutor`的`execute`和`addWorker`两个核心方法; -学习如何把任务线程加入到线程池中运行. - -- ThreadPoolExecutor 的构造方法如下 - - -- 第1个参数: corePoolSize 表示常驻核心线程数 -如果等于0,则任务执行完之后,没有任何请求进入时销毁线程池的线程; -如果大于0,即使本地任务执行完毕,核心线程也不会被销毁. -这个值的设置非常关键; -设置过大会浪费资源; -设置过小会导致线程频繁地创建或销毁. - -- 第2个参数: maximumPoolSize 表示线程池能够容纳同时执行的最大线程数 -从第1处来看,必须>=1.
-如果待执行的线程数大于此值,需要借助第5个参数的帮助,缓存在队列中.
-如果`maximumPoolSize = corePoolSize`,即是固定大小线程池.
-
-- 第3个参数: keepAliveTime 表示线程池中的线程空闲时间
-当空闲时间达到`keepAliveTime`时,线程会被销毁,直到只剩下`corePoolSize`个线程;
-避免浪费内存和句柄资源.
-在默认情况下,当线程池的线程数大于`corePoolSize`时,`keepAliveTime`才起作用.
-但是当`ThreadPoolExecutor`的`allowCoreThreadTimeOut = true`时,核心线程超时后也会被回收.
-
-- 第4个参数: TimeUnit表示时间单位
-keepAliveTime的时间单位通常是TimeUnit.SECONDS.
-
-- 第5个参数: workQueue 表示缓存队列
-当请求的线程数大于`maximumPoolSize`时,线程进入`BlockingQueue`.
-后续示例代码中使用的LinkedBlockingQueue是单向链表,使用锁来控制入队和出队的原子性;
-两个锁分别控制元素的添加和获取,是一个生产消费模型队列.
-
-- 第6个参数: threadFactory 表示线程工厂
-它用来生产一组相同任务的线程;
-线程池的命名是通过给这个factory增加组名前缀来实现的.
-在虚拟机栈分析时,就可以知道线程任务是由哪个线程工厂产生的.
-
-- 第7个参数: handler 表示执行拒绝策略的对象
-当超过第5个参数`workQueue`的任务缓存区上限的时候,就可以通过该策略处理请求,这是一种简单的限流保护.
-友好的拒绝策略可以是如下三种:
-(1 ) 保存到数据库进行削峰填谷;在空闲时再提取出来执行
-(2)转向某个提示页面
-(3)打印日志
-
-### 2.1.1 corePoolSize(核心线程数量)
-线程池中应该保持的主要线程的数量.即使线程处于空闲状态,除非设置了`allowCoreThreadTimeOut`这个参数,当提交一个任务到线程池时,若线程数量Integer 有32位;
-最右边29位表工作线程数;
-最左边3位表示线程池状态,可表示从0至7的8个不同数值
-线程池的状态用高3位表示,其中包括了符号位.
-五种状态的十进制值按从小到大依次排序为
-RUNNING < SHUTDOWN < STOP < TIDYING =核心线程数 或线程创建失败,则将当前任务放到工作队列中
- // 只有线程池处于 RUNNING 态,才执行后半句 : 置入队列
- if (isRunning(c) && workQueue.offer(command)) {
- int recheck = ctl.get();
-
- // 只有线程池处于 RUNNING 态,才执行后半句 : 置入队列
- if (! isRunning(recheck) && remove(command))
- reject(command);
- // 若之前的线程已被消费完,新建一个线程
- else if (workerCountOf(recheck) == 0)
- addWorker(null, false);
- // 核心线程和队列都已满,尝试创建一个新线程
- }
- else if (!addWorker(command, false))
- // 抛出RejectedExecutionException异常
- // 若 addWorker 返回是 false,即创建失败,则唤醒拒绝策略.
- reject(command);
- }
-```
-发生拒绝的理由有两个
-( 1 )线程池状态为非RUNNING状态
-(2)等待队列已满。
-
-下面继续分析`addWorker`
-
-## addWorker 源码解析
-
-根据当前线程池状态,检查是否可以添加新的任务线程,若可以则创建并启动任务;
-若一切正常则返回true;
-返回false的可能性如下
-1. 线程池没有处于`RUNNING`态
-2. 线程工厂创建新的任务线程失败
-### 参数
-- firstTask
-外部启动线程池时需要构造的第一个线程,它是线程的母体
-- core
-新增工作线程时的判断指标
- - true
-需要判断当前`RUNNING`态的线程是否少于`corePoolsize`
- - false
-需要判断当前`RUNNING`态的线程是否少于`maximumPoolsize`
-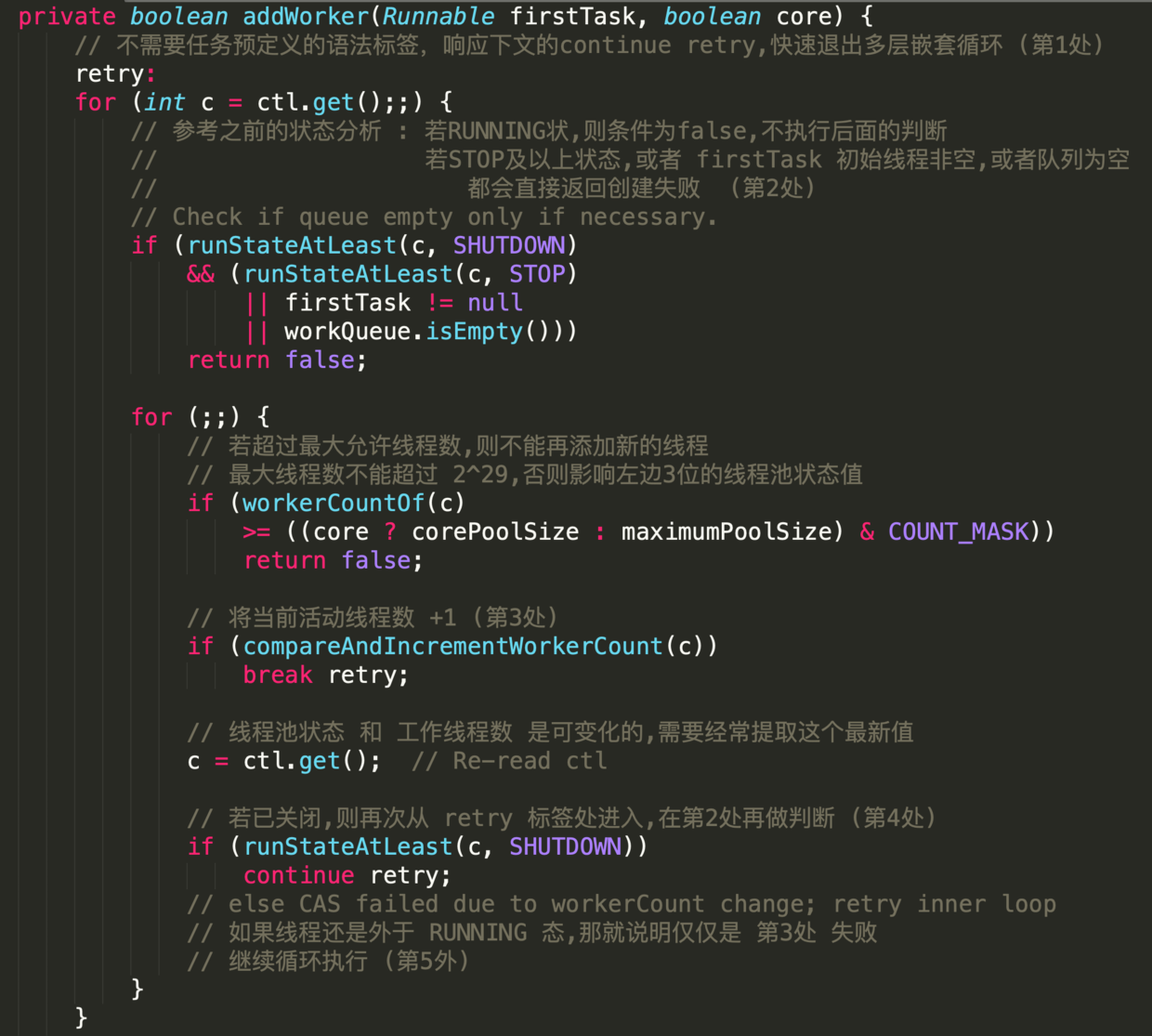
-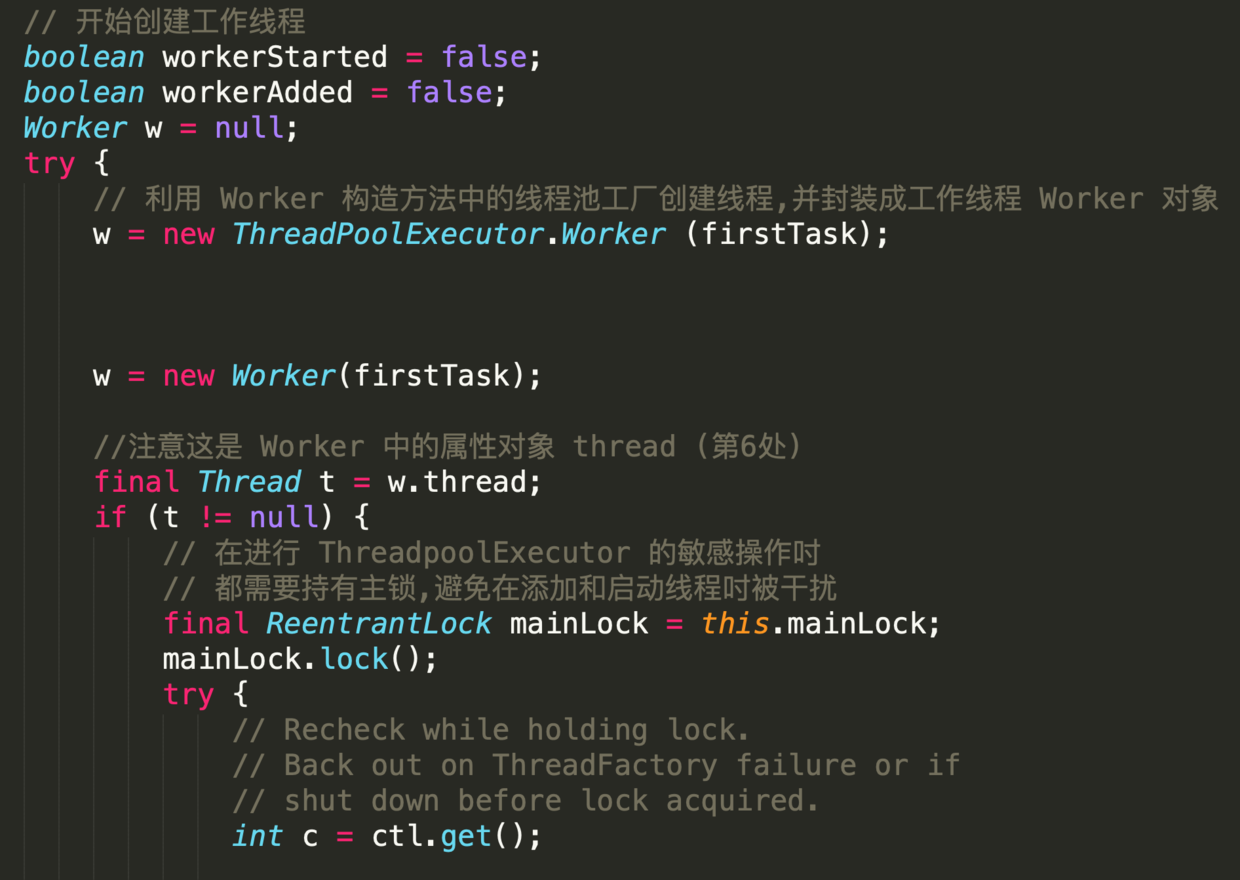
-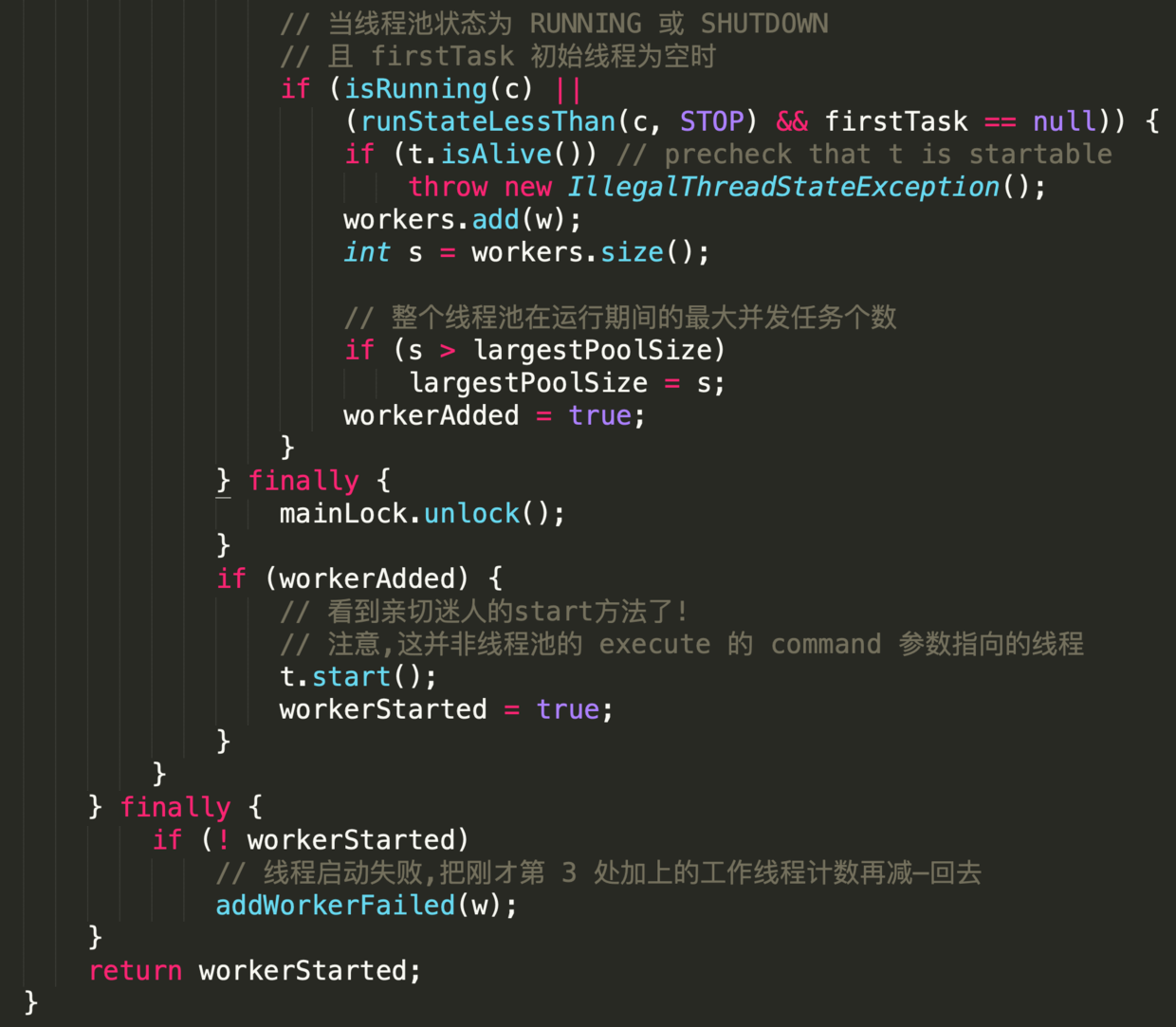
-
-这段代码晦涩难懂,部分地方甚至违反代码规约,但其中蕴含丰富的编码知识点
-
-- 第1处,配合循环语句出现的label,类似于goto 作用
-label 定义时,必须把标签和冒号的组合语句紧紧相邻定义在循环体之前,否则会编译出错.
-目的是 在实现多重循环时能够快速退出到任何一层;
-出发点似乎非常贴心,但在大型软件项目中,滥用标签行跳转的后果将是灾难性的.
-示例代码中在`retry`下方有两个无限循环;
-在`workerCount`加1成功后,直接退出两层循环.
-
-- 第2处,这样的表达式不利于阅读,应如是
-
-
-- 第3处,与第1处的标签呼应,`AtomicInteger`对象的加1操作是原子性的;
-`break retry`表 直接跳出与`retry` 相邻的这个循环体
-
-- 第4处,此`continue`跳转至标签处,继续执行循环.
-如果条件为false,则说明线程池还处于运行状态,即继续在`for(;)`循环内执行.
-
-- 第5处,`compareAndIncrementWorkerCount `方法执行失败的概率非常低.
-即使失败,再次执行时成功的概率也是极高的,类似于自旋原理.
-这里是先加1,创建失败再减1,这是轻量处理并发创建线程的方式;
-如果先创建线程,成功再加1,当发现超出限制后再销毁线程,那么这样的处理方式明显比前者代价要大.
-
-- 第6处,`Worker `对象是工作线程的核心类实现,部分源码如下
-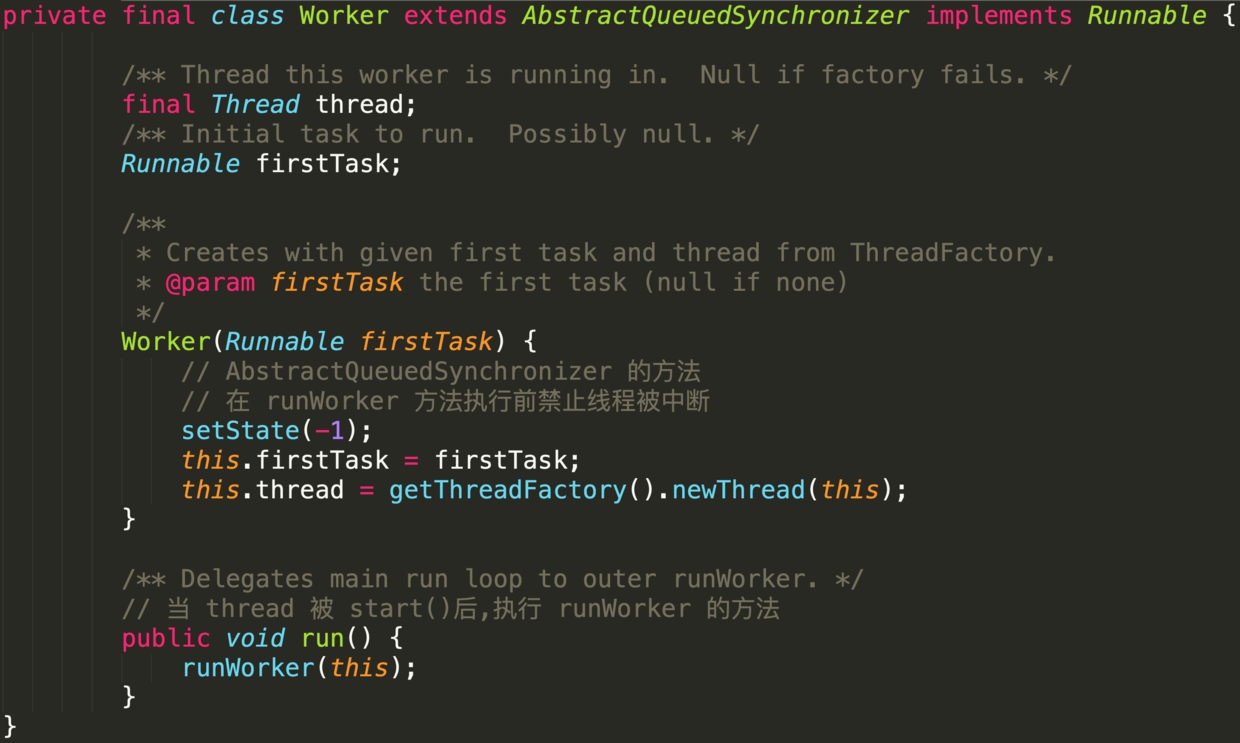
-它实现了`Runnable`接口,并把本对象作为参数输入给`run()`中的`runWorker (this)`;
-所以内部属性线程`thread`在`start`的时候,即会调用`runWorker`.
-
-# 总结
-线程池的相关源码比较精炼,还包括线程池的销毁、任务提取和消费等,与线程状态图一样,线程池也有自己独立的状态转化流程,本节不再展开。
-总结一下,使用线程池要注意如下几点:
-(1)合理设置各类参数,应根据实际业务场景来设置合理的工作线程数。
-(2)线程资源必须通过线程池提供,不允许在应用中自行显式创建线程。
-(3)创建线程或线程池时请指定有意义的线程名称,方便出错时回溯。
-
-线程池不允许使用Executors,而是通过ThreadPoolExecutor的方式创建,这样的处理方式能更加明确线程池的运行规则,规避资源耗尽的风险。
-
-
-
-
-
-进一步查看源码发现,这些方法最终都调用了ThreadPoolExecutor和ScheduledThreadPoolExecutor的构造函数
-而ScheduledThreadPoolExecutor继承自ThreadPoolExecutor
-
-## 0.2 ThreadPoolExecutor 自定义线程池
-[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5A6eRvc8-1570557031390)(https://uploadfiles.nowcoder.com/images/20190625/5088755_1561476436402_10FB15C77258A991B0028080A64FB42D "图片标题")]
-它们都是某种线程池,可以控制线程创建,释放,并通过某种策略尝试复用线程去执行任务的一个管理框架
-
-,因此最终所有线程池的构造函数都调用了Java5后推出的ThreadPoolExecutor的如下构造函数
-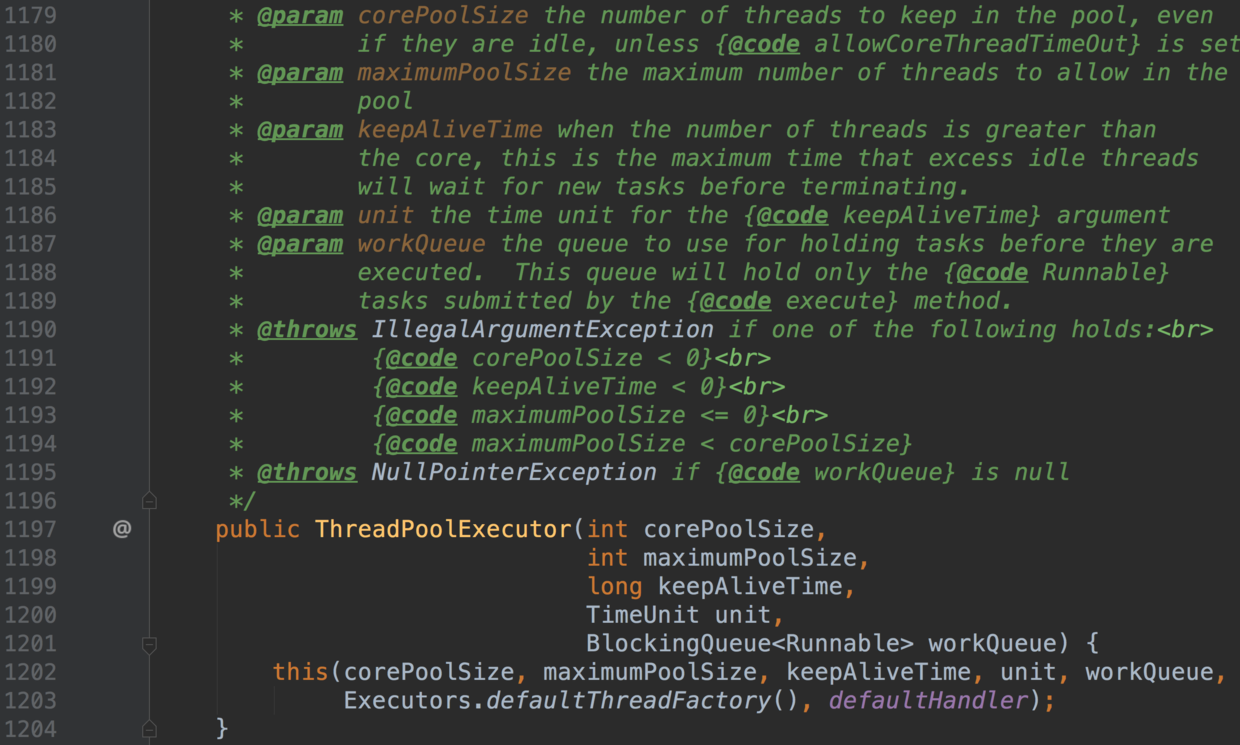
-
-## Java默认提供的线程池
-Java中的线程池是运用场景最多的并发框架,几乎所有需要异步或并发执行任务的程序都可以使用线程池
-
-
-
-我们只需要将待执行的方法放入 run 方法中,将 Runnable 接口的实现类交给线程池的
-execute 方法,作为他的一个参数,比如:
-```java
-Executor e=Executors.newSingleThreadExecutor();
-e.execute(new Runnable(){ //匿名内部类 public void run(){
-//需要执行的任务
-}
-});
-
-```
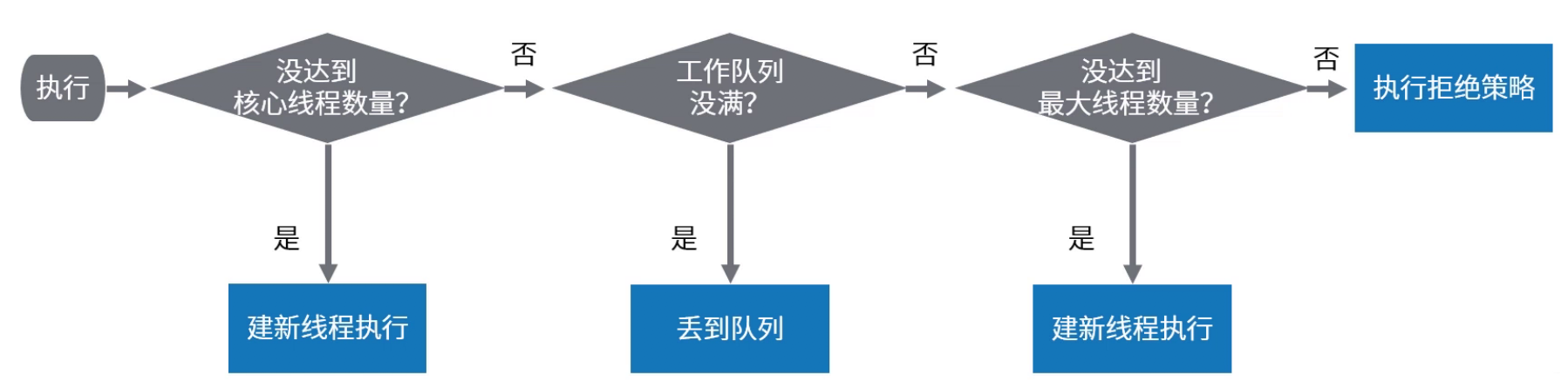
-# 线程池原理 - 任务execute过程
- - 流程图
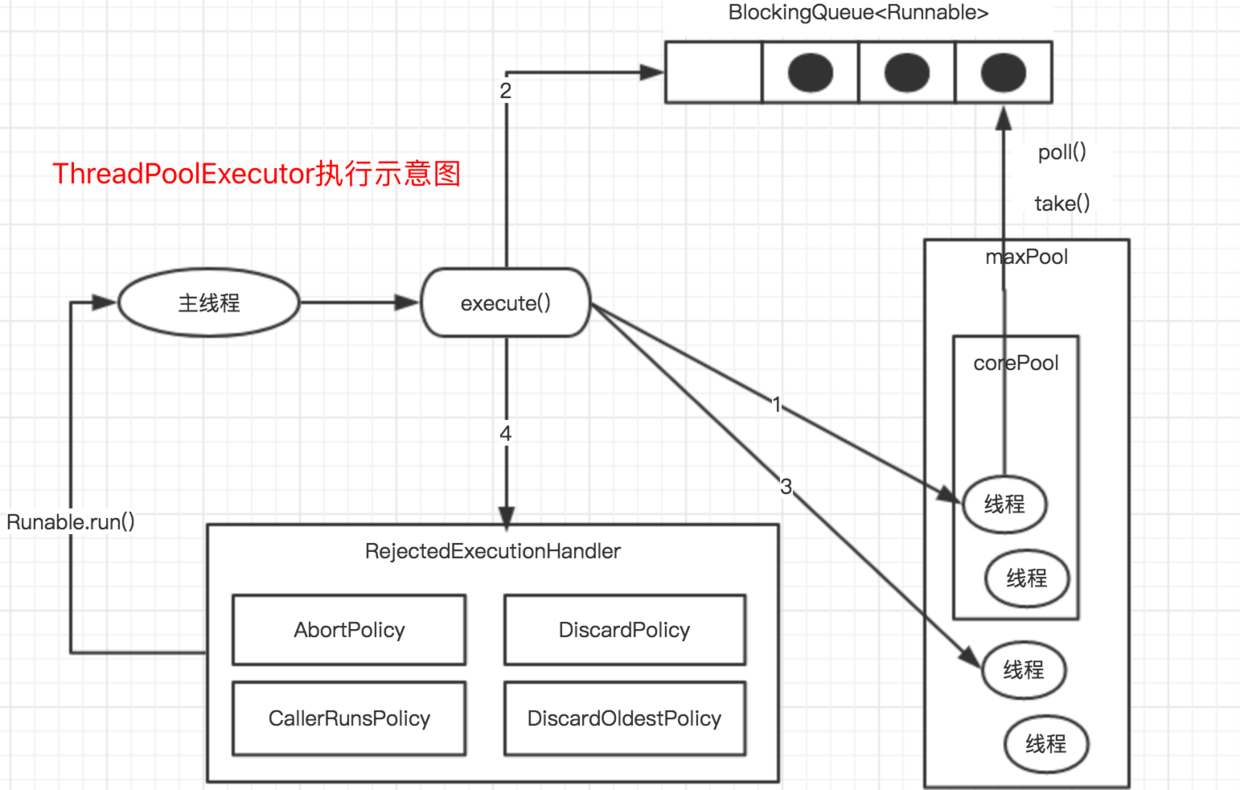
-
-- 示意图
-
-
-ThreadPoolExecutor执行execute()分4种情况
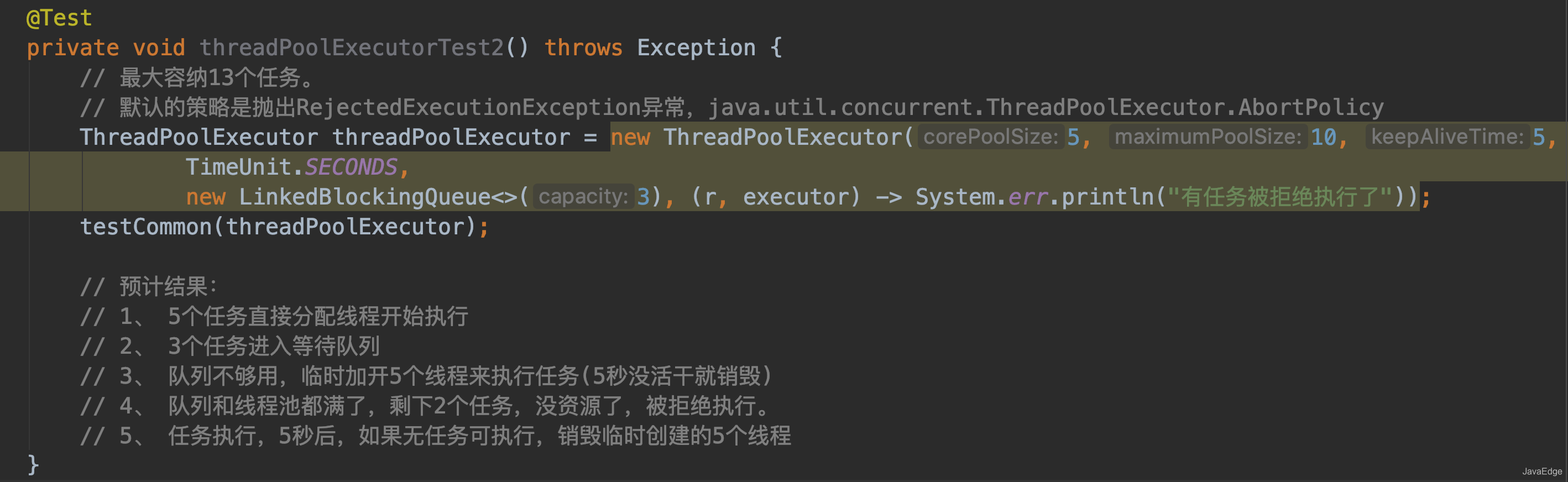
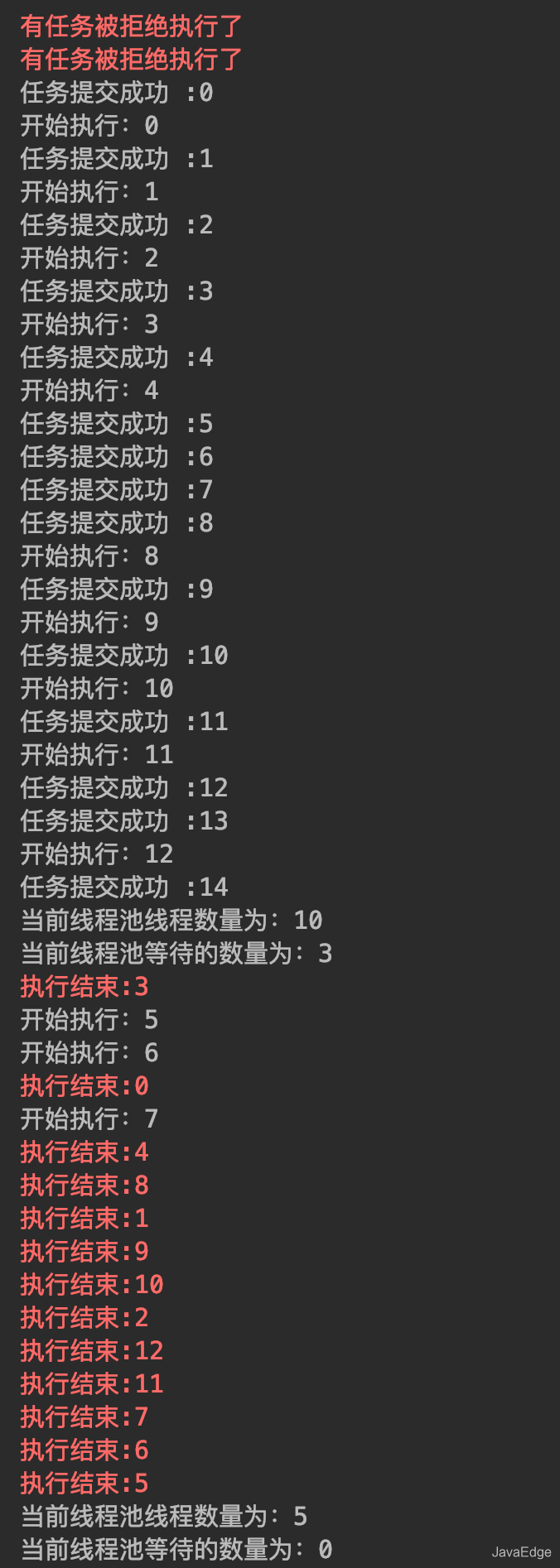
- - 若当前运行的线程少于`corePoolSize`,则创建新线程来执行任务(该步需要获取全局锁)
- - 若运行的线程多于或等于`corePoolSize`,且工作队列没满,则将新提交的任务存储在工作队列里。即, 将任务加入`BlockingQueue`
- - 若无法将任务加入`BlockingQueue`,且没达到线程池最大数量, 则创建新的线程来处理任务(该步需要获取全局锁)
- - 若创建新线程将使当前运行的线程超出`maximumPoolSize`,任务将被拒绝,并调用`RejectedExecutionHandler.rejectedExecution()`
-
-采取上述思路,是为了在执行`execute()`时,尽可能避免获取全局锁
-在ThreadPoolExecutor完成预热之后(当前运行的线程数大于等于corePoolSize),几乎所有的execute()方法调用都是执行步骤2,而步骤2不需要获取全局锁
-
-## 实例
-
-- 结果
-
-
-# **源码分析**
-```
- /**
- * 检查是否可以根据当前池状态和给定的边界(核心或最大)
- * 添加新工作线程。如果是这样,工作线程数量会相应调整,如果可能的话,一个新的工作线程创建并启动
- * 将firstTask作为其运行的第一项任务。
- * 如果池已停止此方法返回false
- * 如果线程工厂在被访问时未能创建线程,也返回false
- * 如果线程创建失败,或者是由于线程工厂返回null,或者由于异常(通常是在调用Thread.start()后的OOM)),我们干净地回滚。
- *
- * @param core if true use corePoolSize as bound, else
- * maximumPoolSize. (A boolean indicator is used here rather than a
- * value to ensure reads of fresh values after checking other pool
- * state).
- * @return true if successful
- */
- private boolean addWorker(Runnable firstTask, boolean core) {
- retry:
- for (;;) {
- int c = ctl.get();
- int rs = runStateOf(c);
-
-
- /**
- * Check if queue empty only if necessary.
- *
- * 如果线程池已关闭,并满足以下条件之一,那么不创建新的 worker:
- * 1. 线程池状态大于 SHUTDOWN,也就是 STOP, TIDYING, 或 TERMINATED
- * 2. firstTask != null
- * 3. workQueue.isEmpty()
- * 简单分析下:
- * 状态控制的问题,当线程池处于 SHUTDOWN ,不允许提交任务,但是已有任务继续执行
- * 当状态大于 SHUTDOWN ,不允许提交任务,且中断正在执行任务
- * 多说一句:若线程池处于 SHUTDOWN,但 firstTask 为 null,且 workQueue 非空,是允许创建 worker 的
- *
- */
- if (rs>= SHUTDOWN &&
- ! (rs == SHUTDOWN &&
- firstTask == null &&
- ! workQueue.isEmpty()))
- return false;
-
- for (;;) {
- int wc = workerCountOf(c);
- if (wc>= CAPACITY ||
- wc>= (core ? corePoolSize : maximumPoolSize))
- return false;
- // 如果成功,那么就是所有创建线程前的条件校验都满足了,准备创建线程执行任务
- // 这里失败的话,说明有其他线程也在尝试往线程池中创建线程
- if (compareAndIncrementWorkerCount(c))
- break retry;
- // 由于有并发,重新再读取一下 ctl
- c = ctl.get(); // Re-read ctl
- // 正常如果是 CAS 失败的话,进到下一个里层的for循环就可以了
- // 可如果是因为其他线程的操作,导致线程池的状态发生了变更,如有其他线程关闭了这个线程池
- // 那么需要回到外层的for循环
- if (runStateOf(c) != rs)
- continue retry;
- // else CAS failed due to workerCount change; retry inner loop
- }
- }
-
- /* *
- * 到这里,我们认为在当前这个时刻,可以开始创建线程来执行任务
- */
-
- // worker 是否已经启动
- boolean workerStarted = false;
- // 是否已将这个 worker 添加到 workers 这个 HashSet 中
- boolean workerAdded = false;
- Worker w = null;
- try {
- // 把 firstTask 传给 worker 的构造方法
- w = new Worker(firstTask);
- // 取 worker 中的线程对象,Worker的构造方法会调用 ThreadFactory 来创建一个新的线程
- final Thread t = w.thread;
- if (t != null) {
- //先加锁
- final ReentrantLock mainLock = this.mainLock;
- // 这个是整个类的全局锁,持有这个锁才能让下面的操作"顺理成章",
- // 因为关闭一个线程池需要这个锁,至少我持有锁的期间,线程池不会被关闭
- mainLock.lock();
- try {
- // Recheck while holding lock.
- // Back out on ThreadFactory failure or if
- // shut down before lock acquired.
- int rs = runStateOf(ctl.get());
-
- // 小于 SHUTTDOWN 即 RUNNING
- // 如果等于 SHUTDOWN,不接受新的任务,但是会继续执行等待队列中的任务
- if (rs < SHUTDOWN || - (rs == SHUTDOWN && firstTask == null)) { - // worker 里面的 thread 不能是已启动的 - if (t.isAlive()) // precheck that t is startable - throw new IllegalThreadStateException(); - // 加到 workers 这个 HashSet 中 - workers.add(w); - int s = workers.size(); - if (s> largestPoolSize)
- largestPoolSize = s;
- workerAdded = true;
- }
- } finally {
- mainLock.unlock();
- }
- // 若添加成功
- if (workerAdded) {
- // 启动线程
- t.start();
- workerStarted = true;
- }
- }
- } finally {
- // 若线程没有启动,做一些清理工作,若前面 workCount 加了 1,将其减掉
- if (! workerStarted)
- addWorkerFailed(w);
- }
- // 返回线程是否启动成功
- return workerStarted;
- }
-```
-看下 `addWorkFailed`
-
-
-
-
-
-
-
-
-`worker` 中的线程 `start` 后,其 `run` 方法会调用 `runWorker `
-
-继续往下看 `runWorker`
-```
-// worker 线程启动后调用,while 循环(即自旋!)不断从等待队列获取任务并执行
-// worker 初始化时,可指定 firstTask,那么第一个任务也就可以不需要从队列中获取
-final void runWorker(Worker w) {
- Thread wt = Thread.currentThread();
- // 该线程的第一个任务(若有)
- Runnable task = w.firstTask;
- w.firstTask = null;
- // 允许中断
- w.unlock();
-
- boolean completedAbruptly = true;
- try {
- // 循环调用 getTask 获取任务
- while (task != null || (task = getTask()) != null) {
- w.lock();
- // 若线程池状态大于等于 STOP,那么意味着该线程也要中断
- /**
- * 若线程池STOP,请确保线程 已被中断
- * 如果没有,请确保线程未被中断
- * 这需要在第二种情况下进行重新检查,以便在关中断时处理shutdownNow竞争
- */
- if ((runStateAtLeast(ctl.get(), STOP) ||
- (Thread.interrupted() &&
- runStateAtLeast(ctl.get(), STOP))) &&
- !wt.isInterrupted())
- wt.interrupt();
- try {
- // 这是一个钩子方法,留给需要的子类实现
- beforeExecute(wt, task);
- Throwable thrown = null;
- try {
- // 到这里终于可以执行任务了
- task.run();
- } catch (RuntimeException x) {
- thrown = x; throw x;
- } catch (Error x) {
- thrown = x; throw x;
- } catch (Throwable x) {
- // 这里不允许抛出 Throwable,所以转换为 Error
- thrown = x; throw new Error(x);
- } finally {
- // 也是一个钩子方法,将 task 和异常作为参数,留给需要的子类实现
- afterExecute(task, thrown);
- }
- } finally {
- // 置空 task,准备 getTask 下一个任务
- task = null;
- // 累加完成的任务数
- w.completedTasks++;
- // 释放掉 worker 的独占锁
- w.unlock();
- }
- }
- completedAbruptly = false;
- } finally {
- // 到这里,需要执行线程关闭
- // 1. 说明 getTask 返回 null,也就是说,这个 worker 的使命结束了,执行关闭
- // 2. 任务执行过程中发生了异常
- // 第一种情况,已经在代码处理了将 workCount 减 1,这个在 getTask 方法分析中说
- // 第二种情况,workCount 没有进行处理,所以需要在 processWorkerExit 中处理
- processWorkerExit(w, completedAbruptly);
- }
-}
-```
-看看 `getTask() `
-
-```
-// 此方法有三种可能
-// 1. 阻塞直到获取到任务返回。默认 corePoolSize 之内的线程是不会被回收的,它们会一直等待任务
-// 2. 超时退出。keepAliveTime 起作用的时候,也就是如果这么多时间内都没有任务,那么应该执行关闭
-// 3. 如果发生了以下条件,须返回 null
-// 池中有大于 maximumPoolSize 个 workers 存在(通过调用 setMaximumPoolSize 进行设置)
-// 线程池处于 SHUTDOWN,而且 workQueue 是空的,前面说了,这种不再接受新的任务
-// 线程池处于 STOP,不仅不接受新的线程,连 workQueue 中的线程也不再执行
-private Runnable getTask() {
- boolean timedOut = false; // Did the last poll() time out?
-
- for (;;) {
- // 允许核心线程数内的线程回收,或当前线程数超过了核心线程数,那么有可能发生超时关闭
-
- // 这里 break,是为了不往下执行后一个 if (compareAndDecrementWorkerCount(c))
- // 两个 if 一起看:如果当前线程数 wc> maximumPoolSize,或者超时,都返回 null
- // 那这里的问题来了,wc> maximumPoolSize 的情况,为什么要返回 null?
- // 换句话说,返回 null 意味着关闭线程。
- // 那是因为有可能开发者调用了 setMaximumPoolSize 将线程池的 maximumPoolSize 调小了
-
- // 如果此 worker 发生了中断,采取的方案是重试
- // 解释下为什么会发生中断,这个读者要去看 setMaximumPoolSize 方法,
- // 如果开发者将 maximumPoolSize 调小了,导致其小于当前的 workers 数量,
- // 那么意味着超出的部分线程要被关闭。重新进入 for 循环,自然会有部分线程会返回 null
- int c = ctl.get();
- int rs = runStateOf(c);
-
- // Check if queue empty only if necessary.
- if (rs>= SHUTDOWN && (rs>= STOP || workQueue.isEmpty())) {
- // CAS 操作,减少工作线程数
- decrementWorkerCount();
- return null;
- }
-
- int wc = workerCountOf(c);
-
- // Are workers subject to culling?
- boolean timed = allowCoreThreadTimeOut || wc> corePoolSize;
-
- if ((wc> maximumPoolSize || (timed && timedOut))
- && (wc> 1 || workQueue.isEmpty())) {
- if (compareAndDecrementWorkerCount(c))
- return null;
- continue;
- }
-
- try {
- Runnable r = timed ?
- workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
- workQueue.take();
- if (r != null)
- return r;
- timedOut = true;
- } catch (InterruptedException retry) {
- // 如果此 worker 发生了中断,采取的方案是重试
- // 解释下为什么会发生中断,这个读者要去看 setMaximumPoolSize 方法,
- // 如果开发者将 maximumPoolSize 调小了,导致其小于当前的 workers 数量,
- // 那么意味着超出的部分线程要被关闭。重新进入 for 循环,自然会有部分线程会返回 null
- timedOut = false;
- }
- }
-}
-```
-到这里,基本上也说完了整个流程,回到 execute(Runnable command) 方法,看看各个分支,我把代码贴过来一下:
-```
-/**
- * Executes the given task sometime in the future. The task
- * may execute in a new thread or in an existing pooled thread.
- *
- * If the task cannot be submitted for execution, either because this
- * executor has been shutdown or because its capacity has been reached,
- * the task is handled by the current {@code RejectedExecutionHandler}.
- *
- * @param command the task to execute
- * @throws RejectedExecutionException at discretion of
- * {@code RejectedExecutionHandler}, if the task
- * cannot be accepted for execution
- * @throws NullPointerException if {@code command} is null
- */
- public void execute(Runnable command) {
- if (command == null)
- throw new NullPointerException();
- /*
- * Proceed in 3 steps:
- *
- * 1. If fewer than corePoolSize threads are running, try to
- * start a new thread with the given command as its first
- * task. The call to addWorker atomically checks runState and
- * workerCount, and so prevents false alarms that would add
- * threads when it shouldn't, by returning false.
- *
- * 2. If a task can be successfully queued, then we still need
- * to double-check whether we should have added a thread
- * (because existing ones died since last checking) or that
- * the pool shut down since entry into this method. So we
- * recheck state and if necessary roll back the enqueuing if
- * stopped, or start a new thread if there are none.
- *
- * 3. If we cannot queue task, then we try to add a new
- * thread. If it fails, we know we are shut down or saturated
- * and so reject the task.
- */
- //表示 "线程池状态" 和 "线程数" 的整数
- int c = ctl.get();
- // 如果当前线程数少于核心线程数,直接添加一个 worker 执行任务,
- // 创建一个新的线程,并把当前任务 command 作为这个线程的第一个任务(firstTask)
- if (workerCountOf(c) < corePoolSize) { - // 添加任务成功,即结束 - // 执行的结果,会包装到 FutureTask - // 返回 false 代表线程池不允许提交任务 - if (addWorker(command, true)) - return; - - c = ctl.get(); - } - - // 到这说明,要么当前线程数大于等于核心线程数,要么刚刚 addWorker 失败 - - // 如果线程池处于 RUNNING ,把这个任务添加到任务队列 workQueue 中 - if (isRunning(c) && workQueue.offer(command)) { - /* 若任务进入 workQueue,我们是否需要开启新的线程 - * 线程数在 [0, corePoolSize) 是无条件开启新线程的 - * 若线程数已经大于等于 corePoolSize,则将任务添加到队列中,然后进到这里 - */ - int recheck = ctl.get(); - // 若线程池不处于 RUNNING ,则移除已经入队的这个任务,并且执行拒绝策略 - if (! isRunning(recheck) && remove(command)) - reject(command); - // 若线程池还是 RUNNING ,且线程数为 0,则开启新的线程 - // 这块代码的真正意图:担心任务提交到队列中了,但是线程都关闭了 - else if (workerCountOf(recheck) == 0) - addWorker(null, false); - } - // 若 workQueue 满,到该分支 - // 以 maximumPoolSize 为界创建新 worker, - // 若失败,说明当前线程数已经达到 maximumPoolSize,执行拒绝策略 - else if (!addWorker(command, false)) - reject(command); - } -``` -**工作线程**:线程池创建线程时,会将线程封装成工作线程Worker,Worker在执行完任务后,还会循环获取工作队列里的任务来执行.我们可以从Worker类的run()方法里看到这点 - -``` - public void run() { - try { - Runnable task = firstTask; - firstTask = null; - while (task != null || (task = getTask()) != null) { - runTask(task); - task = null; - } - } finally { - workerDone(this); - } - } - boolean workerStarted = false; - boolean workerAdded = false; - Worker w = null; - try { - w = new Worker(firstTask); - - final Thread t = w.thread; - if (t != null) { - //先加锁 - final ReentrantLock mainLock = this.mainLock; - mainLock.lock(); - try { - // Recheck while holding lock. - // Back out on ThreadFactory failure or if - // shut down before lock acquired. - int rs = runStateOf(ctl.get()); - - if (rs < SHUTDOWN || - (rs == SHUTDOWN && firstTask == null)) { - if (t.isAlive()) // precheck that t is startable - throw new IllegalThreadStateException(); - workers.add(w); - int s = workers.size(); - if (s> largestPoolSize)
- largestPoolSize = s;
- workerAdded = true;
- }
- } finally {
- mainLock.unlock();
- }
- if (workerAdded) {
- t.start();
- workerStarted = true;
- }
- }
- } finally {
- if (! workerStarted)
- addWorkerFailed(w);
- }
- return workerStarted;
- }
-```
-线程池中的线程执行任务分两种情况
- - 在execute()方法中创建一个线程时,会让这个线程执行当前任务
- - 这个线程执行完上图中 1 的任务后,会反复从BlockingQueue获取任务来执行
-
-# 线程池的使用
-
-## 向线程池提交任务
- 可以使用两个方法向线程池提交任务
-### execute()
-用于提交不需要返回值的任务,所以无法判断任务是否被线程池执行成功.通过以下代码可知execute()方法输入的任务是一个Runnable类的实例.
-```
- threadsPool.execute(new Runnable() {
- @Override
- public void run() {
- // TODO Auto-generated method stub
- }
- });
-```
-从运行结果可以看出,单线程池中的线程是顺序执行的。固定线程池(参数为2)中,永远最多只有两个线程并发执行。缓存线程池中,所有线程都并发执行。
-第二个例子,测试单线程调度线程池和固定调度线程池。
-
-```
-public class ScheduledThreadPoolExam {
- public static void main(String[] args) {
- //first test for singleThreadScheduledPool
- ScheduledExecutorService scheduledPool = Executors.newSingleThreadScheduledExecutor();
- //second test for scheduledThreadPool
-// ScheduledExecutorService scheduledPool = Executors.newScheduledThreadPool(2);
- for (int i = 0; i < 5; i++) { - scheduledPool.schedule(new TaskInScheduledPool(i), 0, TimeUnit.SECONDS); - } - scheduledPool.shutdown(); - } -} - -class TaskInScheduledPool implements Runnable { - private final int id; - - TaskInScheduledPool(int id) { - this.id = id; - } - - @Override - public void run() { - try { - for (int i = 0; i < 5; i++) { - System.out.println("TaskInScheduledPool-["+id+"] is running phase-"+i); - TimeUnit.SECONDS.sleep(1); - } - System.out.println("TaskInScheduledPool-["+id+"] is over"); - } catch (InterruptedException e) { - e.printStackTrace(); - } - } -} -``` -从运行结果可以看出,单线程调度线程池和单线程池类似,而固定调度线程池和固定线程池类似。 -总结: - -- 如果没有特殊要求,使用缓存线程池总是合适的; -- 如果只能运行一个线程,就使用单线程池。 -- 如果要运行调度任务,则按需使用调度线程池或单线程调度线程池 -- 如果有其他特殊要求,则可以直接使用ThreadPoolExecutor类的构造函数来创建线程池,并自己给定那五个参数。 - -### submit() -用于提交需要返回值的任务.线程池会返回一个future类型对象,通过此对象可以判断任务是否执行成功 -并可通过get()获取返回值,get()会阻塞当前线程直到任务完成,而使用get(long timeout,TimeUnit unit)方法则会阻塞当前线程一段时间后立即返回,这时候可能任务没有执行完. - -``` - Future future = executor.submit(harReturnValuetask);
- try {
- Object s = future.get();
- } catch (InterruptedException e) {
- // 处理中断异常
- } catch (ExecutionException e) {
- // 处理无法执行任务异常
- } finally {
- // 关闭线程池
- executor.shutdown();
- }
-```
-## 关闭线程池
-可通过调用线程池的**shutdown**或**shutdownNow**方法来关闭线程池.
-它们的原理是遍历线程池中的工作线程,然后逐个调用线程的**interrupt**方法来中断线程,所以无法响应中断的任务可能永远无法终止.
-但是它们存在一定的区别
-
- - **shutdownNow**首先将线程池的状态设置成STOP,然后尝试停止所有的正在执行或暂停任务的线程,并返回等待执行任务的列表
- - **shutdown**只是将线程池的状态设置成SHUTDOWN状态,然后中断所有没有正在执行任务的线程.
-
-只要调用了这两个关闭方法中的任意一个,isShutdown方法就会返回true.
-当所有的任务都已关闭后,才表示线程池关闭成功,这时调用isTerminaed方法会返回true.
-至于应该调用哪一种方法,应该由提交到线程池的任务的特性决定,通常调用shutdown方法来关闭线程池,若任务不一定要执行完,则可以调用shutdownNow方法.
-
-## 合理配置
-
-要想合理地配置线程池,就必须首先
-
-### 分析任务特性
-
-可从以下几个角度来分析
- - 任务的性质:CPU密集型任务、IO密集型任务和混合型任务
- - 任务的优先级:高、中和低
- - 任务的执行时间:长、中和短
- - 任务的依赖性:是否依赖其他系统资源,如数据库连接。
-
-### 任务性质
-可用不同规模的线程池分开处理
-
-#### CPU密集型任务(计算型任务)
-应配置尽可能小的线程,配置
- ` N(CPU)+1 `或 `N(CPU) * 2`
-
-#### I/O密集型任务
-相对比计算型任务,需多一些线程,根据具体 I/O 阻塞时长考量
-
-> 如Tomcat中默认最大线程数: 200。
-
-也可考虑根据需要在一个最小数量和最大数量间自动增减线程数。
-
-业务读取较多,线程并不是一直在执行任务,则应配置尽可能多的线程
-`N(CPU)/1 - 阻塞系数(0.8~0.9)`
-
-一般,生产环境下,CPU使用率达到80,说明被充分利用
-
-#### 混合型的任务
-如果可以拆分,将其拆分成一个CPU密集型任务和一个IO密集型任务,只要这两个任务执行的时间相差不是太大,那么分解后执行的吞吐量将高于串行执行的吞吐量.如果这两个任务执行时间相差太大,则没必要进行分解.
-
-可以通过Runtime.getRuntime().availableProcessors()方法获得当前设备的CPU个数.
-
-优先级不同的任务可以使用PriorityBlockingQueue处理.它可以让优先级高
-的任务先执行.
-
-> 注意 如果一直有优先级高的任务提交到队列里,那么优先级低的任务可能永远不能执行
-
-执行时间不同的任务可以交给不同规模的线程池来处理,或者可以使用优先级队列,让执行时间短的任务先执行.
-
-依赖数据库连接池的任务,因为线程提交SQL后需要等待数据库返回结果,等待的时间越长,则CPU空闲时间就越长,那么线程数应该设置得越大,这样才能更好地利用CPU.
-
-**建议使用有界队列** 有界队列能增加系统的稳定性和预警能力,可以根据需要设大一点,比如几千.
-假如系统里后台任务线程池的队列和线程池全满了,不断抛出抛弃任务的异常,通过排查发现是数据库出现了问题,导致执行SQL变得非常缓慢,因为后台任务线程池里的任务全是需要向数据库查询和插入数据的,所以导致线程池里的工作线程全部阻塞,任务积压在线程池里.
-如果我们设置成无界队列,那么线程池的队列就会越来越多,有可能会撑满内存,导致整个系统不可用,而不只是后台任务出现问题.
-## 2.5 线程池的监控
-如果在系统中大量使用线程池,则有必要对线程池进行监控,方便在出现问题时,可以根据线程池的使用状况快速定位问题.可通过线程池提供的参数进行监控,在监控线程池的时候可以使用以下属性:
-
- - taskCount:线程池需要执行的任务数量
- - completedTaskCount:线程池在运行过程中已完成的任务数量,小于或等于taskCount。
- - largestPoolSize:线程池里曾经创建过的最大线程数量.通过这个数据可以知道线程池是否曾经满过.如该数值等于线程池的最大大小,则表示线程池曾经满过.
- - getPoolSize:线程池的线程数量.如果线程池不销毁的话,线程池里的线程不会自动销毁,所以这个大小只增不减.
- - getActiveCount:获取活动的线程数.
-
-通过扩展线程池进行监控.可以通过继承线程池来自定义线程池,重写线程池的
-beforeExecute、afterExecute和terminated方法,也可以在任务执行前、执行后和线程池关闭前执行一些代码来进行监控.例如,监控任务的平均执行时间、最大执行时间和最小执行时间等.
-这几个方法在线程池里是空方法.
-
-```
-protected void beforeExecute(Thread t, Runnable r) { }
-```
-## 2.6 线程池的状态
-1.当线程池创建后,初始为 running 状态
-2.调用 shutdown 方法后,处 shutdown 状态,此时不再接受新的任务,等待已有的任务执行完毕
-3.调用 shutdownnow 方法后,进入 stop 状态,不再接受新的任务,并且会尝试终止正在执行的任务。
-4.当处于 shotdown 或 stop 状态,并且所有工作线程已经销毁,任务缓存队列已清空,线程池被设为 terminated 状态。
-
-# 总结
-## java 线程池有哪些关键属性?
-- corePoolSize 到 maximumPoolSize 之间的线程会被回收,当然 corePoolSize 的线程也可以通过设置而得到回收(allowCoreThreadTimeOut(true))。
-- workQueue 用于存放任务,添加任务的时候,如果当前线程数超过了 corePoolSize,那么往该队列中插入任务,线程池中的线程会负责到队列中拉取任务。
-- keepAliveTime 用于设置空闲时间,如果线程数超出了 corePoolSize,并且有些线程的空闲时间超过了这个值,会执行关闭这些线程的操作
-- rejectedExecutionHandler 用于处理当线程池不能执行此任务时的情况,默认有抛出 RejectedExecutionException 异常、忽略任务、使用提交任务的线程来执行此任务和将队列中等待最久的任务删除,然后提交此任务这四种策略,默认为抛出异常。
-##线程池中的线程创建时机?
-- 如果当前线程数少于 corePoolSize,那么提交任务的时候创建一个新的线程,并由这个线程执行这个任务;
-- 如果当前线程数已经达到 corePoolSize,那么将提交的任务添加到队列中,等待线程池中的线程去队列中取任务;
-- 如果队列已满,那么创建新的线程来执行任务,需要保证池中的线程数不会超过 maximumPoolSize,如果此时线程数超过了 maximumPoolSize,那么执行拒绝策略。
-
-## 任务执行过程中发生异常怎么处理?
-如果某个任务执行出现异常,那么执行任务的线程会被关闭,而不是继续接收其他任务。然后会启动一个新的线程来代替它。
-
-## 什么时候会执行拒绝策略?
-- workers 的数量达到了 corePoolSize,任务入队成功,以此同时线程池被关闭了,而且关闭线程池并没有将这个任务出队,那么执行拒绝策略。这里说的是非常边界的问题,入队和关闭线程池并发执行,读者仔细看看 execute 方法是怎么进到第一个 reject(command) 里面的。
-- workers 的数量大于等于 corePoolSize,准备入队,可是队列满了,任务入队失败,那么准备开启新的线程,可是线程数已经达到 maximumPoolSize,那么执行拒绝策略。
-
-# 参考
-- 《码出高效》
-
-- 《Java并发编程的艺术》
\ No newline at end of file
diff --git "a/Python/347円210円254円350円231円253円/python351円253円230円347円272円247円347円210円254円350円231円253円345円256円236円346円210円230円344円271円213円Headers344円277円241円346円201円257円346円240円241円351円252円214円-Cookie.md" "b/Python/347円210円254円350円231円253円/python351円253円230円347円272円247円347円210円254円350円231円253円345円256円236円346円210円230円344円271円213円Headers344円277円241円346円201円257円346円240円241円351円252円214円-Cookie.md"
deleted file mode 100644
index fccea8ba37..0000000000
--- "a/Python/347円210円254円350円231円253円/python351円253円230円347円272円247円347円210円254円350円231円253円345円256円236円346円210円230円344円271円213円Headers344円277円241円346円201円257円346円240円241円351円252円214円-Cookie.md"
+++ /dev/null
@@ -1,68 +0,0 @@
-### python高级爬虫实战之Headers信息校验-Cookie
-
-#### 一、什么是cookie
-
- 上期我们了解了User-Agent,这期我们来看下如何利用Cookie进行用户模拟登录从而进行网站数据的爬取。
-
-首先让我们来了解下什么是Cookie:
-
- Cookie指某些网站为了辨别用户身份、从而储存在用户本地终端上的数据。当客户端在第一次请求网站指定的首页或登录页进行登录之后,服务器端会返回一个Cookie值给客户端。如果客户端为浏览器,将自动将返回的cookie存储下来。当再次访问改网页的其他页面时,自动将cookie值在Headers里传递过去,服务器接受值后进行验证,如合法处理请求,否则拒绝请求。
-
-### 二、如何利用cookie
-
- 举个例子我们要去微博爬取相关数据,首先我们会遇到登录的问题,当然我们可以利用python其他的功能模块进行模拟登录,这里可能会涉及到验证码等一些反爬手段。
-
-
-
-换个思路,我们登录好了,通过开发者工具"右击" 检查(或者按F12) 获取到对应的cookie,那我们就可以绕个登录的页面,利用cookie继续用户模拟操作从而直接进行操作了。
-
-
-
-利用cookie实现模拟登录的两种方法:
-
-- [ ] 将cookie插入Headers请求头
-
- ```
- Headers={"cookie":"复制的cookie值"}
- ```
-
-
-
-- [ ] 将cookie直接作为requests方法的参数
-
-```
-cookie={"cookie":"复制的cookie值"}
-requests.get(url,cookie=cookie)
-```
-
-#### 三、利用selenium获取cookie,实现用户模拟登录
-
-实现方法:利用selenium模拟浏览器操作,输入用户名,密码 或扫码进行登录,获取到登录的cookie保存成文件,加载文件解析cookie实现用户模拟登录。
-
-```python
-from selenium import webdriver
-from time import sleep
-import json
-#selenium模拟浏览器获取cookie
-def getCookie:
- driver = webdriver.Chrome()
- driver.maximize_window()
- driver.get('https://weibo.co m/login.php')
- sleep(20) # 留时间进行扫码
- Cookies = driver.get_cookies() # 获取list的cookies
- jsCookies = json.dumps(Cookies) # 转换成字符串保存
- with open('cookies.txt', 'w') as f:
- f.write(jsCookies)
-
-def login:
- filename = 'cookies.txt'
- #创建MozillaCookieJar实例对象
- cookie = cookiejar.MozillaCookieJar()
- #从文件中读取cookie内容到变量
- cookie.load(filename, ignore_discard=True, ignore_expires=True)
- response = requests.get('https://weibo.co m/login.php',cookie=cookie)
-```
-
-#### 四、拓展思考
-
- 如果频繁使用一个账号进行登录爬取网站数据有可能导致服务器检查到异常,对当前账号进行封禁,这边我们就需要考虑cookie池的引入了。
\ No newline at end of file
diff --git "a/Python/347円210円254円350円231円253円/python351円253円230円347円272円247円347円210円254円350円231円253円345円256円236円346円210円230円344円271円213円Headers344円277円241円346円201円257円346円240円241円351円252円214円-User-Agent.md" "b/Python/347円210円254円350円231円253円/python351円253円230円347円272円247円347円210円254円350円231円253円345円256円236円346円210円230円344円271円213円Headers344円277円241円346円201円257円346円240円241円351円252円214円-User-Agent.md"
deleted file mode 100644
index 0fa29af29d..0000000000
--- "a/Python/347円210円254円350円231円253円/python351円253円230円347円272円247円347円210円254円350円231円253円345円256円236円346円210円230円344円271円213円Headers344円277円241円346円201円257円346円240円241円351円252円214円-User-Agent.md"
+++ /dev/null
@@ -1,61 +0,0 @@
-### python高级爬虫实战之Headers信息校验-User-Agent
-
- User-agent 是当前网站反爬策略中最基础的一种反爬技术,服务器通过接收请求头中的user-agen的值来判断是否为正常用户访问还是爬虫程序。
-
- 下面举一个简单的例子 爬取我们熟悉的豆瓣网:
-
-```python
-import requests
-url='https://movie.douban.com/'
-resp=requests.get(url)
-print(resp.status_code)
-```
-
-运行结果得到status_code:418
-
-说明我们爬虫程序已经被服务器所拦截,无法正常获取相关网页数据。
-
-我们可以通过返回的状态码来了解服务器的相应情况
-
-- 100–199:信息反馈
-- 200–299:成功反馈
-- 300–399:重定向消息
-- 400–499:客户端错误响应
-- 500–599:服务器错误响应
-
-现在我们利用google chrome浏览器来打开豆瓣网,查看下网页。
-
-正常打开网页后,我们在页面任意地方右击"检查" 打开开发者工具。
-
-image-20240301205014592
-
-
-
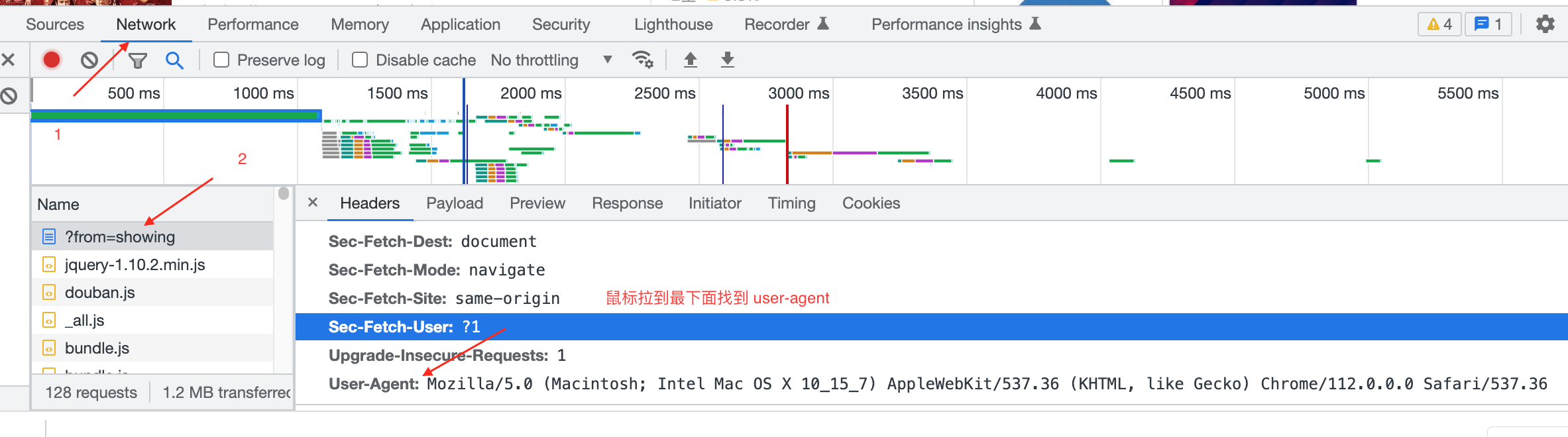
-选择:Network-在Name中随便找一个文件点击后,右边Headers显示内容,鼠标拉到最下面。
-
-
-
-User-Agent:
-
-Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36
-
-我们把这段带到程序中再试下看效果如何。
-
-```python
-import requests
-url='https://movie.douban.com/'
-headers={
-"user-agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36"
-}
-resp=requests.get(url,headers=headers)
-print(resp.status_code)
-```
-
-完美,执行后返回状态码200 ,说明已经成功骗过服务器拿到了想要的数据。
-
- 对于User-agent 我们可以把它当做一个身份证,这个身份证中会包含很多信息,通过这些信息可以识别出访问者。所以当服务器开启了user-agent认证时,就需要像服务器传递相关的信息进行核对。核对成功,服务器才会返回给用户正确的内容,否则就会拒绝服务。
-
-当然,对于Headers的相关信息还有很多,后续我们再一一讲解,下期见。
-
-
-
diff --git "a/Python/347円210円254円350円231円253円/345円210円251円347円224円250円python345円256円236円347円216円260円345円260円217円350円257円264円350円207円252円347円224円261円.md" "b/Python/347円210円254円350円231円253円/345円210円251円347円224円250円python345円256円236円347円216円260円345円260円217円350円257円264円350円207円252円347円224円261円.md"
deleted file mode 100644
index deb2f6262f..0000000000
--- "a/Python/347円210円254円350円231円253円/345円210円251円347円224円250円python345円256円236円347円216円260円345円260円217円350円257円264円350円207円252円347円224円261円.md"
+++ /dev/null
@@ -1,91 +0,0 @@
-### 利用python实现小说自由
-
-#### 一、用到的相关模块
-
-1.reuqests模块
-
-安装reuqest模块,命令行输入:
-
-```
-pip install requests
-```
-
-2.xpath解析
-
- XPath 即为 XML 路径语言,它是一种用来确定 XML (标准通用标记语言子集)文档中某部分位置的语言。XPath 基于 XML 的树状结构,提供在数据结构树中找寻节点的能力。起初 XPath 的提出的初衷是将其作为一个通用的、介于 XPointer 与 XSL 间的语法模型。但是 XPath 很快的被开发者采用来当作小型查询语言。
-
- 简单的来说:Xpath(XML Path Language)是一门在 XML 和 HTML 文档中查找信息的语言,可用来在 XML 和 HTML 文档中对元素和属性进行遍历。
-
- xml 是 一个HTML/XML的解析器,主要的功能是如何解析和提取 HTML/XML 数据。
-
-安装xml:
-
-```
-pip install lxml
-```
-
-
-
-#### 二、实现步骤
-
-1.首先我们打开一个小说的网址:https://www.qu-la.com/booktxt/17437775116/
-
-2.右击"检查" 查看下这个网页的相关代码情况
-
-
-
-我们可以发现所有的内容都被包裹在
-## 4 目录结构
+## 4 目录结构(不断优化中)
| 数据结构与算法 | 操作系统 | 网络 | 面向对象 | 数据存储 | Java | 架构设计 | 框架 | 编程规范 | 职业规划 |
| :--------: | :---------: | :---------: | :---------: | :---------: | :---------:| :---------: | :-------: | :-------:| :------:|
@@ -83,6 +93,15 @@
### :memo: 职业规划
+## QQ 技术交流群
+
+为大家提供一个学习交流平台,在这里你可以自由地讨论技术问题。
+
+
+
+## 微信交流群
+
+
### 本人微信
@@ -95,17 +114,4 @@
### 绘图工具
- [draw.io](https://www.draw.io/)
-- keynote
-
-再分享我整理汇总的一些 Java 面试相关资料(亲自验证,严谨科学!别再看网上误导人的垃圾面试题!!!),助你拿到更多 offer!
-
-
-
-[点击获取更多经典必读电子书!](https://mp.weixin.qq.com/s?__biz=MzUzNTY5MzA3MQ==&mid=2247497273&idx=1&sn=b0f1e2e03cd7de3ce5d93cc8793d6d88&chksm=fa832459cdf4ad4fb046c0beb7e87ecea48f338278846679ef65238af45f0a135720e7061002&token=766333302&lang=zh_CN#rd)
-
-2023年最新Java学习路线一条龙:
-
-[](https://www.nowcoder.com/discuss/353159357007339520?sourceSSR=users)
-
-
-再给大家推荐一个学习 前后端软件开发 和准备Java 面试的公众号[【JavaEdge】](https://mp.weixin.qq.com/s?__biz=MzUzNTY5MzA3MQ==&mid=2247498257&idx=1&sn=b09d88691f9bfd715e000b69ef61227e&chksm=fa832871cdf4a1675d4491727399088ca488fa13e0a3cdf2ece3012265e5a3ef273dff540879&token=766333302&lang=zh_CN#rd)(强烈推荐!)
+- keynote
\ No newline at end of file
diff --git "a/TODO/uml/redis344円274円230円345円214円226円.xmind" "b/TODO/uml/redis344円274円230円345円214円226円.xmind"
deleted file mode 100644
index f4dfaa071a..0000000000
Binary files "a/TODO/uml/redis344円274円230円345円214円226円.xmind" and /dev/null differ
diff --git a/TODO/uml/spring.xmind b/TODO/uml/spring.xmind
deleted file mode 100644
index f9fd71b68e..0000000000
Binary files a/TODO/uml/spring.xmind and /dev/null differ
diff --git "a/346円236円266円346円236円204円/351円253円230円345円217円257円347円224円250円/351円253円230円345円217円257円347円224円250円347円232円204円345円276円256円346円234円215円345円212円241円346円236円266円346円236円204円350円256円276円350円256円241円-350円265円204円346円272円220円351円232円224円347円246円273円343円200円201円351円231円220円346円265円201円343円200円201円347円206円224円346円226円255円343円200円201円351円231円215円347円272円247円343円200円201円347円233円221円346円216円247円.md" "b/346円236円266円346円236円204円/351円253円230円345円217円257円347円224円250円/351円253円230円345円217円257円347円224円250円347円232円204円345円276円256円346円234円215円345円212円241円346円236円266円346円236円204円350円256円276円350円256円241円-350円265円204円346円272円220円351円232円224円347円246円273円343円200円201円351円231円220円346円265円201円343円200円201円347円206円224円346円226円255円343円200円201円351円231円215円347円272円247円343円200円201円347円233円221円346円216円247円.md"
index a475fdcd3a..877ad0a5c3 100644
--- "a/346円236円266円346円236円204円/351円253円230円345円217円257円347円224円250円/351円253円230円345円217円257円347円224円250円347円232円204円345円276円256円346円234円215円345円212円241円346円236円266円346円236円204円350円256円276円350円256円241円-350円265円204円346円272円220円351円232円224円347円246円273円343円200円201円351円231円220円346円265円201円343円200円201円347円206円224円346円226円255円343円200円201円351円231円215円347円272円247円343円200円201円347円233円221円346円216円247円.md"
+++ "b/346円236円266円346円236円204円/351円253円230円345円217円257円347円224円250円/351円253円230円345円217円257円347円224円250円347円232円204円345円276円256円346円234円215円345円212円241円346円236円266円346円236円204円350円256円276円350円256円241円-350円265円204円346円272円220円351円232円224円347円246円273円343円200円201円351円231円220円346円265円201円343円200円201円347円206円224円346円226円255円343円200円201円351円231円215円347円272円247円343円200円201円347円233円221円346円216円247円.md"
@@ -3,28 +3,22 @@
# 舱壁隔离模式
# 容错理念
-- 凡是依赖都可能会失败
-- 凡是资源都有限制
+- 凡是依赖,都可能失败
+- 凡是资源,都有限制
- CPU/Memory/Threads/Queue
-- 网络并不可靠,延迟是应用稳定性杀手
-
-
-
+- 网络并不可靠,延迟是应用稳定性的杀手
# 1 资源隔离
-让你的系统里,某一块东西,在故障的情况下,不会耗尽系统所有的资源,比如线程资源
+系统里,某块故障时,不会耗尽系统所有资源(如线程资源)。
-项目中的一个case,有一块东西,是要用多线程做一些事情,小伙伴做项目的时候,没有太留神,资源隔离,那块代码,在遇到一些故障的情况下,每个线程在跑的时候,因为那个bug,直接就死循环了,导致那块东西启动了大量的线程,每个线程都死循环
-
-最终导致系统资源耗尽,崩溃,不工作,不可用,废掉了
-
-资源隔离,那一块代码,最多最多就是用掉10个线程,不能再多了,就废掉了,限定好的一些资源
+项目中的一个case,有一块东西,要用多线程做一些事,开发同学不留神,资源隔离那块,在遇到故障时,每个线程跑时,因为那个bug,直接死循环,导致那块东西启动了大量线程,每个线程都死循环。
+最终导致系统资源耗尽,崩溃,不工作,不可用,废了。
+资源隔离,就是确保那块代码,最多只能用掉10个线程,不能再多。
# 2 限流
-高并发的流量涌入进来,比如说突然间一秒钟100万QPS,废掉了,10万QPS进入系统,其他90万QPS被拒绝了
-
+高并发的流量涌入进来,比如突然间100万QPS,系统废了。应该10万QPS进入系统,其他90万QPS被拒绝了。
# 3 熔断
-A服务调用B服务的某个功能,由于网络不稳定问题,或者B服务卡机,导致功能时
-间超长。如果这样的次数太多。我们就可以直接将B断路(A不再请求B接口),凡是
+A服务调用B服务的某个功能,由于网络不稳定或B服务宕机,导致功能时间超长。
+若这样的次数太多。我们就可以直接将B断路(A不再请求B接口),凡是
调用B的直接返回降级数据,不必等待B的超长执行。这样B的故障问题,就不会级联影
响到A。
diff --git "a/351円207円215円346円236円204円/350円256円276円350円256円241円346円250円241円345円274円217円/350円256円276円350円256円241円346円250円241円345円274円217円345円256円236円346円210円230円-347円255円226円347円225円245円346円250円241円345円274円217円(Strategy-Pattern).md" "b/351円207円215円346円236円204円/350円256円276円350円256円241円346円250円241円345円274円217円/350円256円276円350円256円241円346円250円241円345円274円217円345円256円236円346円210円230円-347円255円226円347円225円245円346円250円241円345円274円217円(Strategy-Pattern).md"
index ef6bcb6e23..4e0c46e216 100644
--- "a/351円207円215円346円236円204円/350円256円276円350円256円241円346円250円241円345円274円217円/350円256円276円350円256円241円346円250円241円345円274円217円345円256円236円346円210円230円-347円255円226円347円225円245円346円250円241円345円274円217円(Strategy-Pattern).md"
+++ "b/351円207円215円346円236円204円/350円256円276円350円256円241円346円250円241円345円274円217円/350円256円276円350円256円241円346円250円241円345円274円217円345円256円236円346円210円230円-347円255円226円347円225円245円346円250円241円345円274円217円(Strategy-Pattern).md"
@@ -1,106 +1,101 @@
-[相关源码](https://github.com/Wasabi1234/Java-DesignPatterns-Tuitorial)
-# 1 简介
-## 1.1 定义
+# 0.0 相关源码链接
+https://github.com/Wasabi1234/design-patterns
+
+# 1 定义
+
也叫做政策模式(Policy Pattern)
-- wiki
-对象有某个行为,但是在不同的场景中,该行为有不同的实现算法.。比如每个人都要"交个人所得税",但是"在美国交个人所得税"和"在中国交个人所得税"就有不同的算税方法.
+- 维基百科
+对象有某个行为,但是在不同的场景中,该行为有不同的实现算法.
+比如每个人都要"交个人所得税",但是"在美国交个人所得税"和"在中国交个人所得税"就有不同的算税方法.
- 定义
Define a family of algorithms,encapsulate each one,and make them interchangeable.
-定义一组算法,将每个算法都封装起来,并且使它们之间可以互换。
+定义一组算法,将每个算法都封装起来,并且使它们之间可以互换.
-常见 if/else 结构。
-## 1.2 类型
-行为型。
-在`运行时`(**非编译时**)改变软件的算法行为。
+在`运行时`(非编译时)改变软件的算法行为
+- 主要思想
+定义一个通用的问题,使用不同的算法来实现,然后将这些算法都封装在一个统一接口的背后.
-## 1.3 主要思想
-定义一个通用的问题,使用不同的算法来实现,然后将这些算法都封装在一个统一接口。
+
+策略模式使用的就是面向对象的继承和多态机制
-策略模式使用的就是OOP的继承和多态。
+策略模式的三个角色
+●くろまる Context 封装角色
+也叫做上下文角色,起承上启下封装作用;
+屏蔽高层模块对策略、算法的直接访问,封装可能存在的变化.
-## 1.4 主要角色
-### 通用类图
-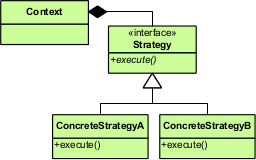
+●くろまる Strategy抽象策略角色
+策略、算法家族的抽象,通常为接口,定义每个策略或算法必须具有的方法和属性
-- Context 封装角色
-即上下文角色,起承上启下的封装作用。屏蔽高层模块对策略&算法的直接访问,封装可能存在的变化。
+●くろまる ConcreteStrategy具体策略角色
+实现抽象策略中的操作,含有具体的算法
-- Strategy 抽象策略角色
-策略&算法家族的抽象,通常为接口,定义每个策略或算法必须具有的方法和属性。
+### 通用源码
+- 抽象策略角色,它是一个非常普通的接口,在我们的项目中就是一个普通得不能再普通的接口了,定义一个或多个具体的算法
-- ConcreteStrategy 具体策略角色
-实现抽象策略中的操作,含有具体的算法。
-### 通用源码
-- 抽象策略角色
-一个非常普通的接口,在项目中就是一个普通接口,定义一或多个具体算法。
# 2 适用场景
-一个对象,其行为有些固定不变,有些又容易变化。对于这些容易变化的行为,我们不希望将其实现绑定在对象中,而希望能够动态地针对不同场景产生不同应对的策略。
-这时就要用到策略模式,就是为了应对对象中复杂多变的行为而产生的:
-- 系统有很多类,而他们的区别仅在于行为不同
+针对一个对象,其行为有些是固定的不变的,有些是容易变化的,针对不同情况有不同的表现形式。那么对于这些容易变化的行为,我们不希望将其实现绑定在对象中,而是希望以动态的形式,针对不同情况产生不同的应对策略。那么这个时候就要用到策略模式了。简言之,策略模式就是为了应对对象中复杂多变的行为而产生的。
+
+- 系统有很多类,而他们的区别仅仅在于他们的行为不同
- 一个系统需要动态地在几种算法中选择一种
+
# 3 优点
- 符合开闭原则
- 避免使用多重条件转移语句
-e.g. 省去大量 if/else、switch,降低代码耦合度
+比如省去大量的 if/else 和 switch 语句,降低代码的耦合
- 提高算法的保密性和安全性
-只需知道策略的业务功能,而不关心内部实现
+只需知道策略的作用,而不关心内部实现
+
# 4 缺点
-- 客户端必须知道所有的策略类,并决定使用哪个策略类
+- 客户端必须知道所有的策略类,并自行决定使用哪一个策略类
- 产生很多策略类
# 5 相关设计模式的差异
-## 5.1 V.S 工厂模式
+## 策略模式和工厂模式
- 行为型
-接收已经创建好的对象,从而实现不同的行为
+接收已经创建好的对象,从而实现不同的行为
- 创造型
-接收指令,创建符合要求的具体对象
-
-## 5.2 V.S 状态模式
-- 若系统中某类的某行为存在多种实现方式,客户端需知道到底使用哪个策略
-- 若系统中某对象存在多种状态,不同状态下的行为又具有差异,状态之间会自动转换,客户端不需要关心具体状态
-## 5.3 V.S 模板模式
-- 策略模式:只有选择权(由用户自己选择已有的固定算法)
-- 模板模式,侧重点不是选择,你没得选择,你必须这么做。你可以参与某一部分内容自定义
+接收指令,创建出符合要求的具体对象
+
+## 策略模式和状态模式
+- 若系统中某个类的某个行为存在多种实现方式,客户端需要知道到底使用哪个策略
+- 若系统中某个对象存在多种状态,不同状态下的行为又具有差异性,状态之间会自动转换,客户端不需要关心具体状态
+
# 6 实战
-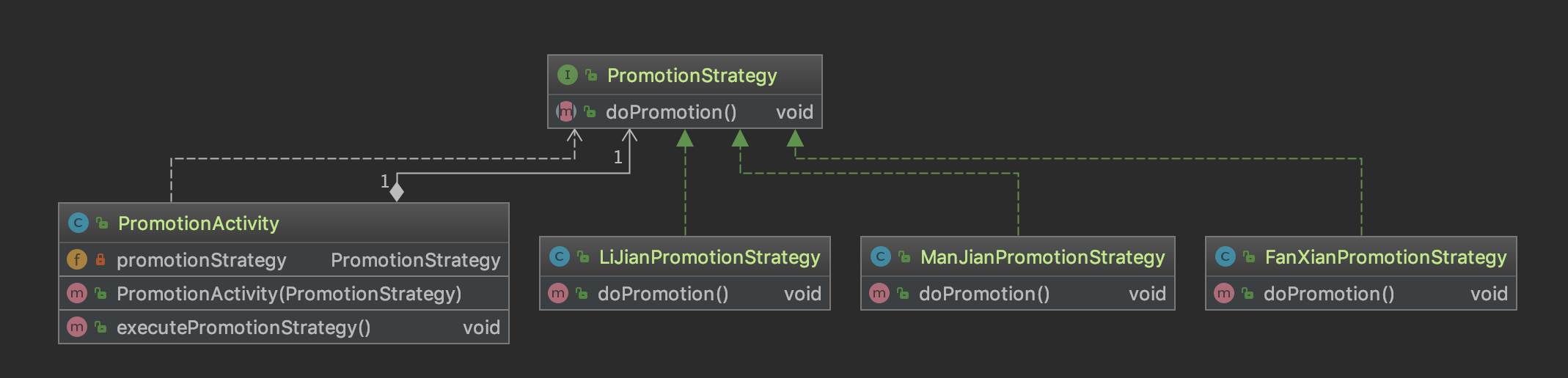
-- 促销策略接口
-
-- 返现策略
-
-- 立减策略
-
-- 满减策略
-
-- 测试类
-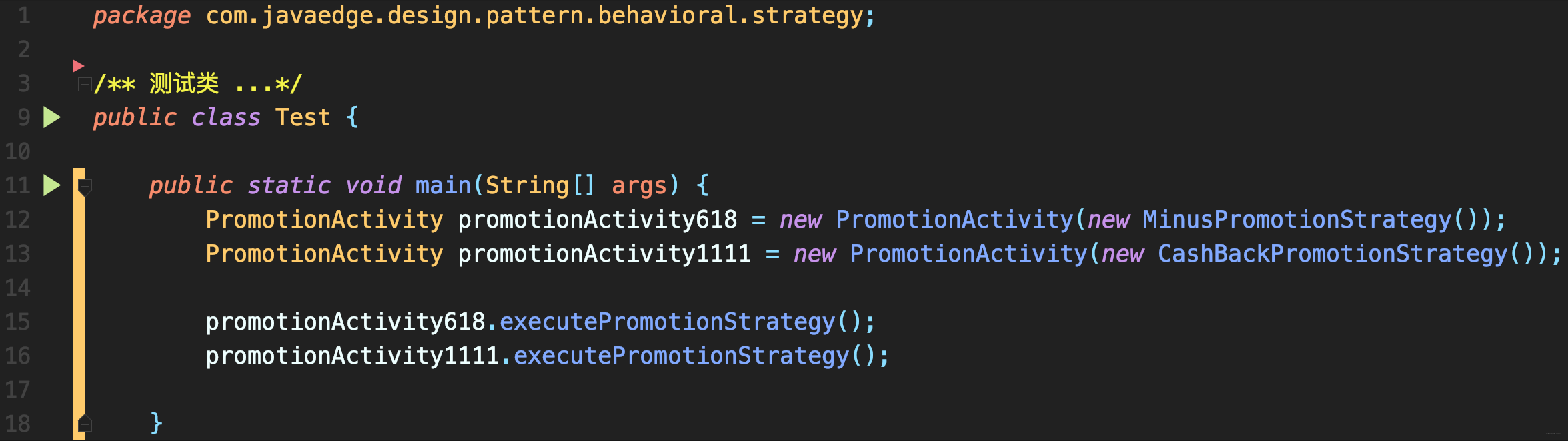
-
+
+
+
+
+
+
+
+
改造后的测试类
-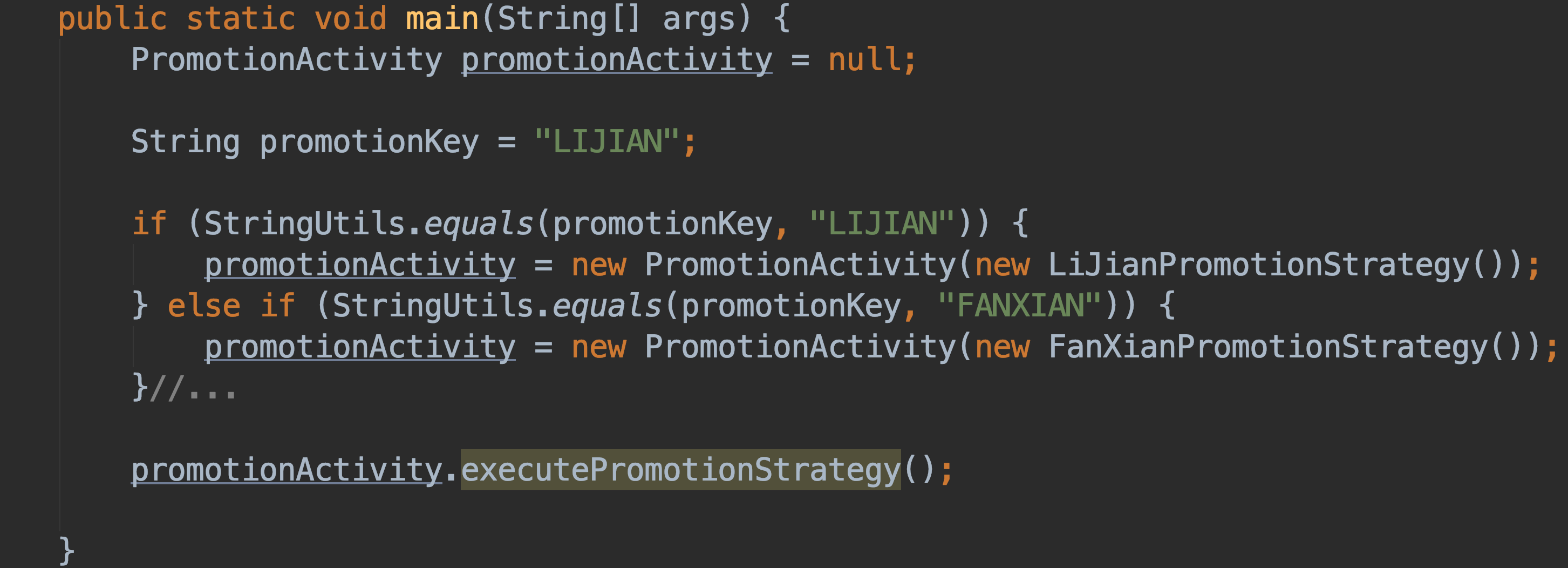
+
可见 if/else 语句过多,采取策略+工厂模式结合
- 策略工厂
-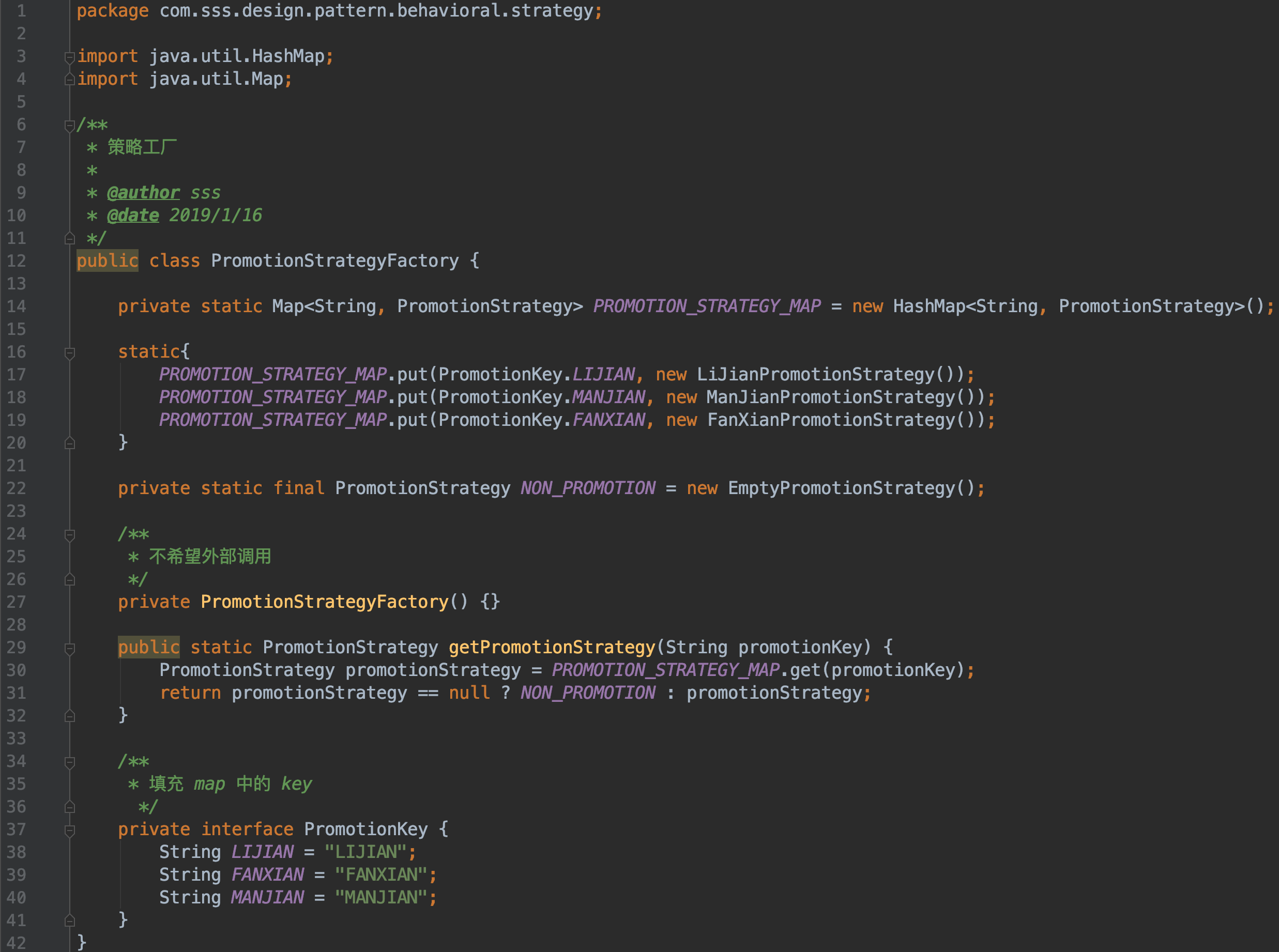
+
- 最新测试类
-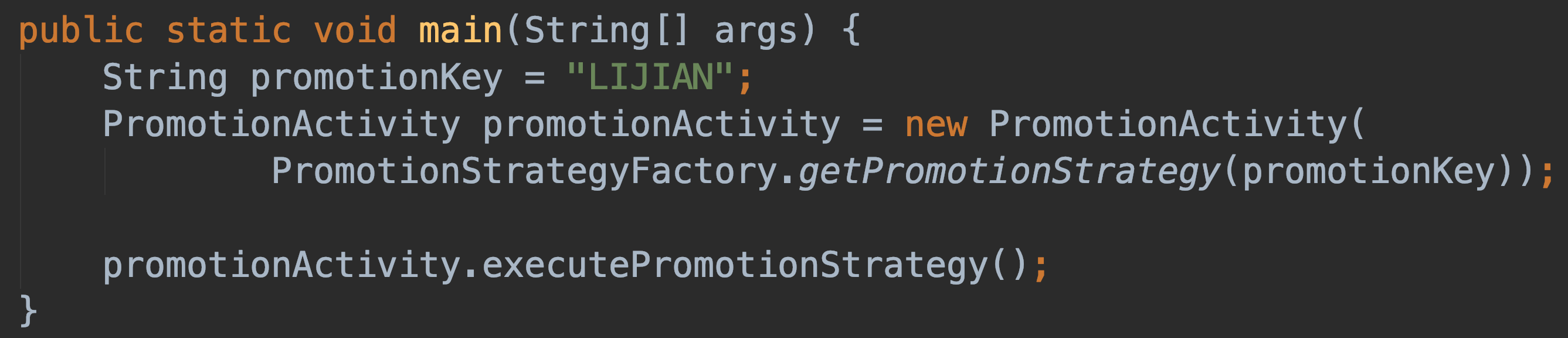
+
- 输出结果
-
+
# 7 源码应用解析
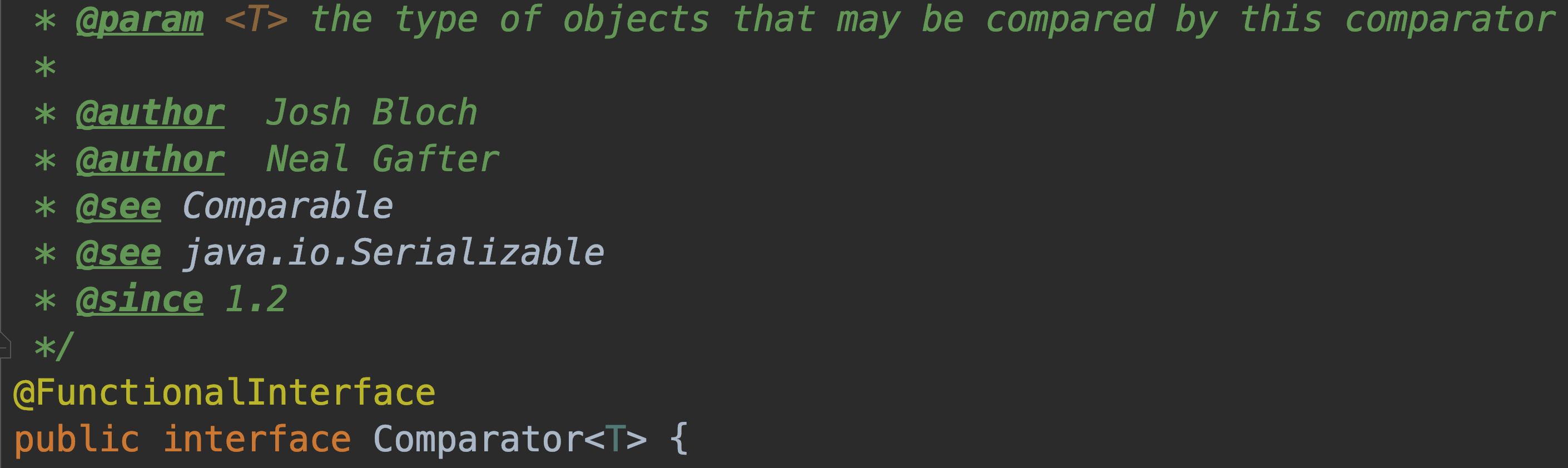
## JDK中的比较器接口
- 策略比较器
-
-
+
+
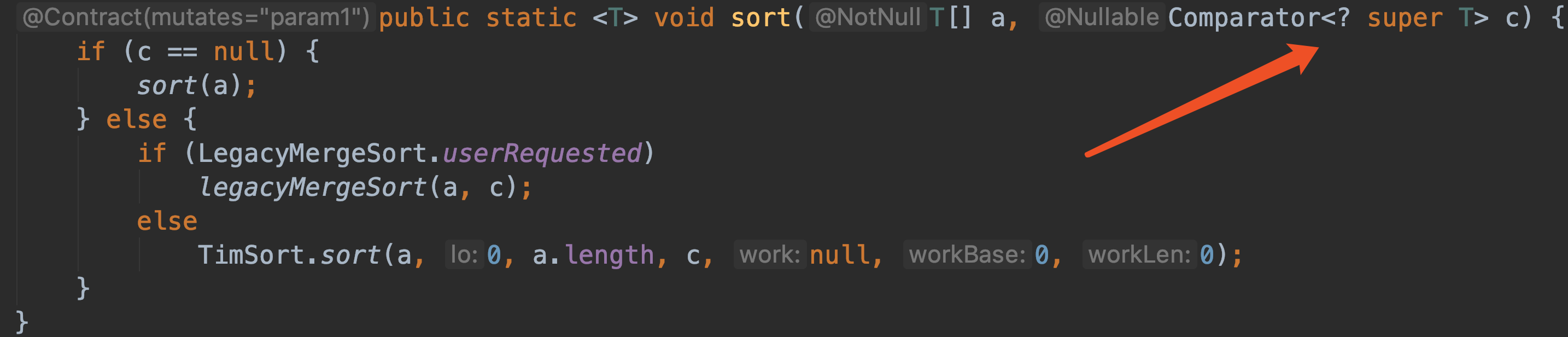
比如Arrays类中的 sort 方法通过传入不同比较接口器的实现达到不同排序策略
-
+
## JDK中的TreeMap
类似于促销活动中有促销策略对象,在T reeMap 中也有比较器对象
-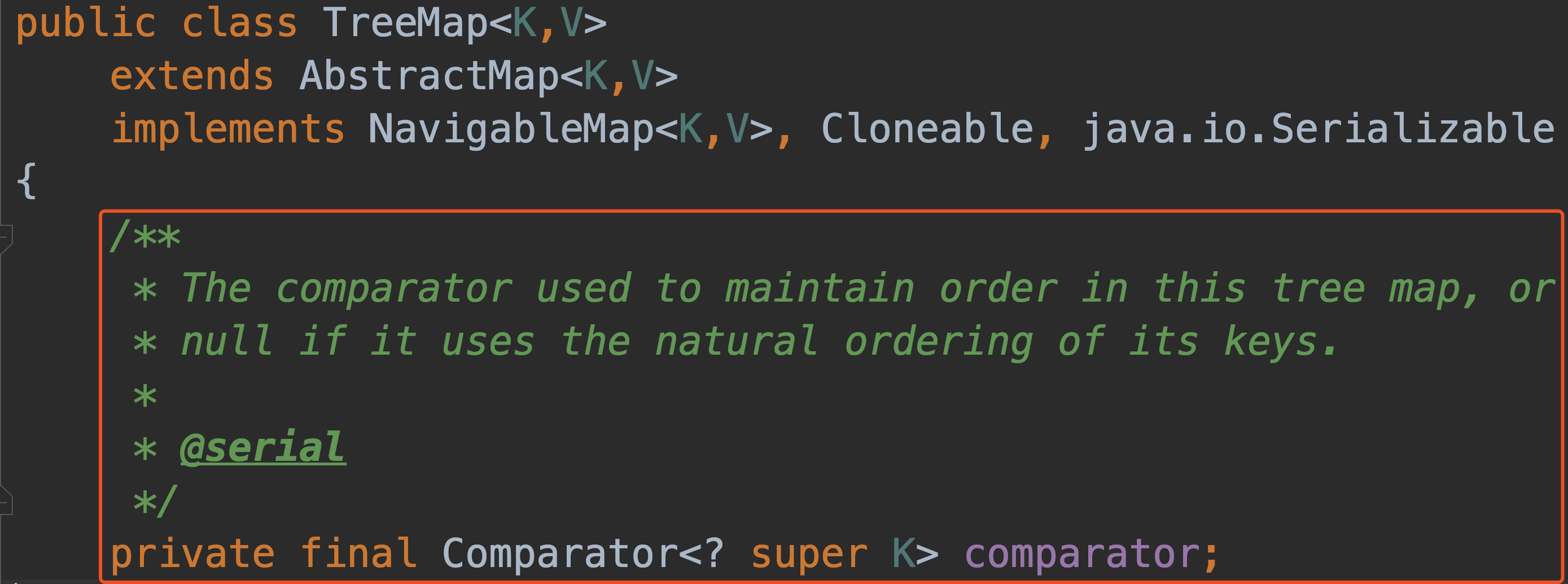
+
compare 方法进步加工
-
+
## Spring 中的Resource
不同访问策略
-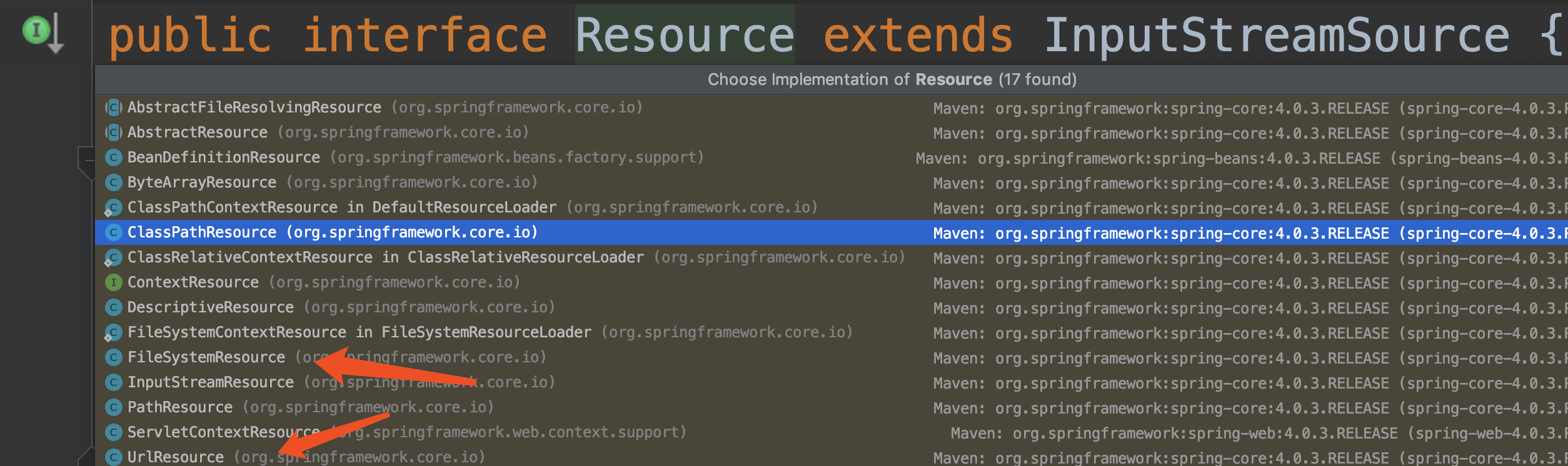
+
## Spring 中bean 的初始化ceInstantiationStrategy
- 两种 bean 的初始化策略
-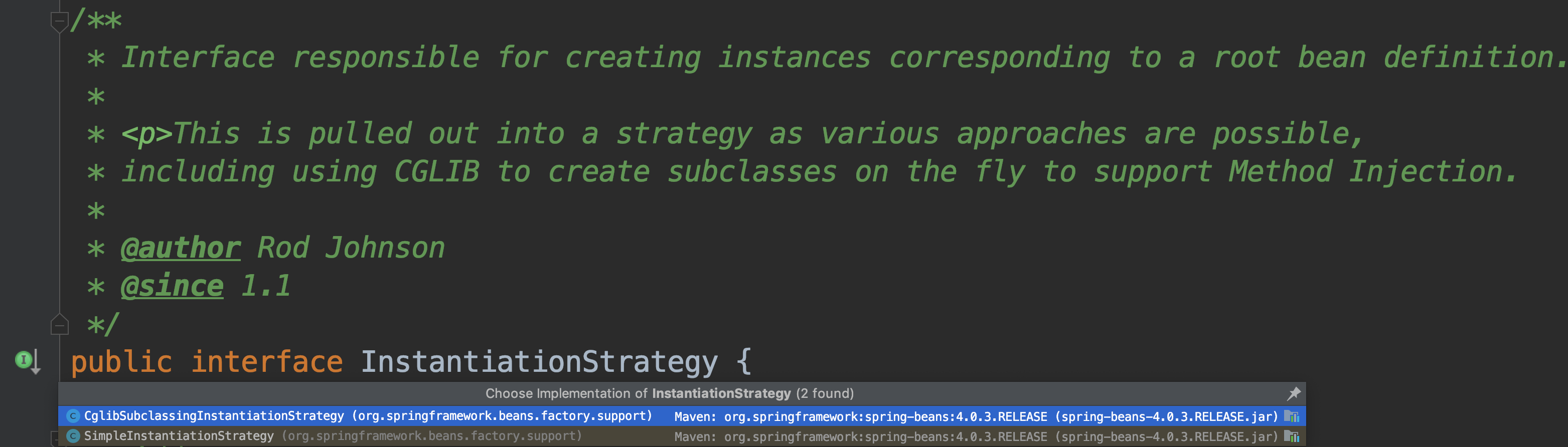
\ No newline at end of file
+