Many but not all deep neural network audio models capture brain responses and exhibit correspondence between model stages and brain regions
- PMID: 38091351
- PMCID: PMC10718467
- DOI: 10.1371/journal.pbio.3002366
Many but not all deep neural network audio models capture brain responses and exhibit correspondence between model stages and brain regions
Abstract
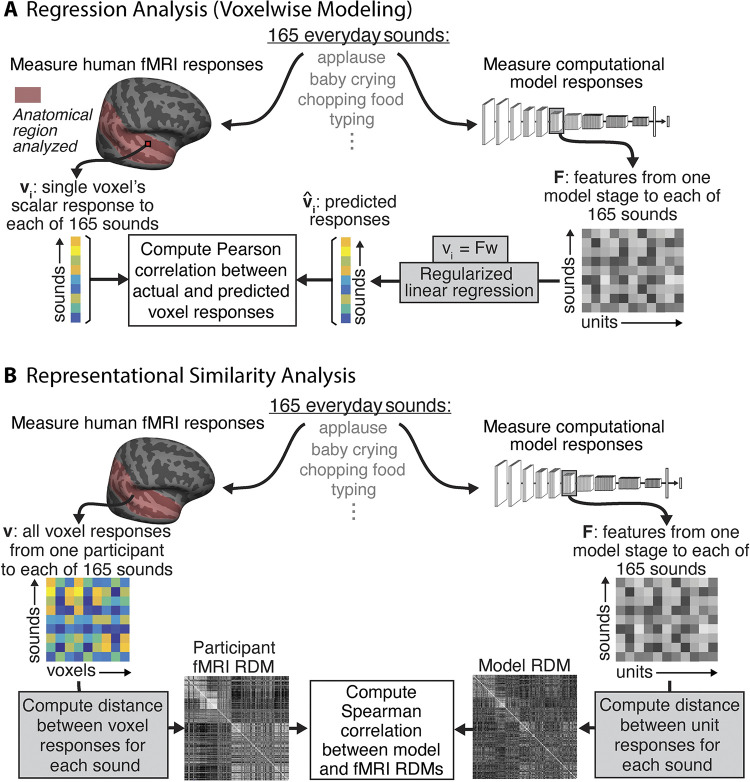
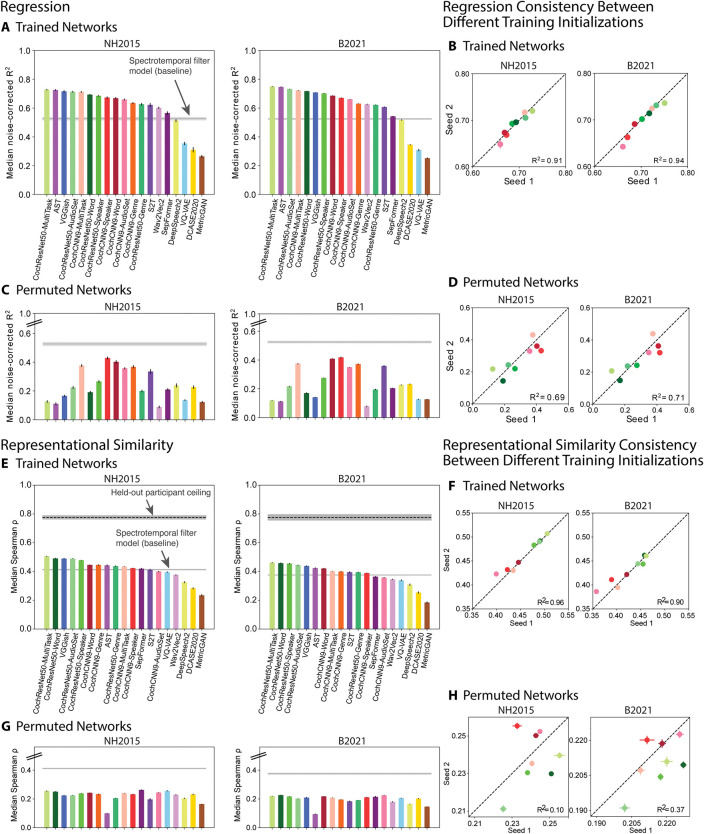
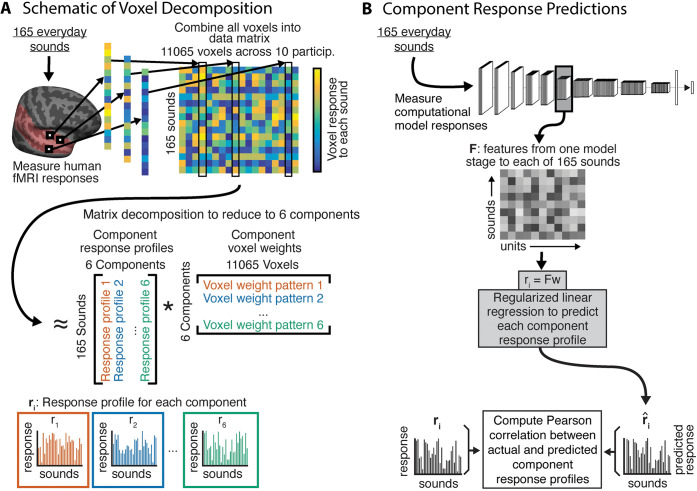
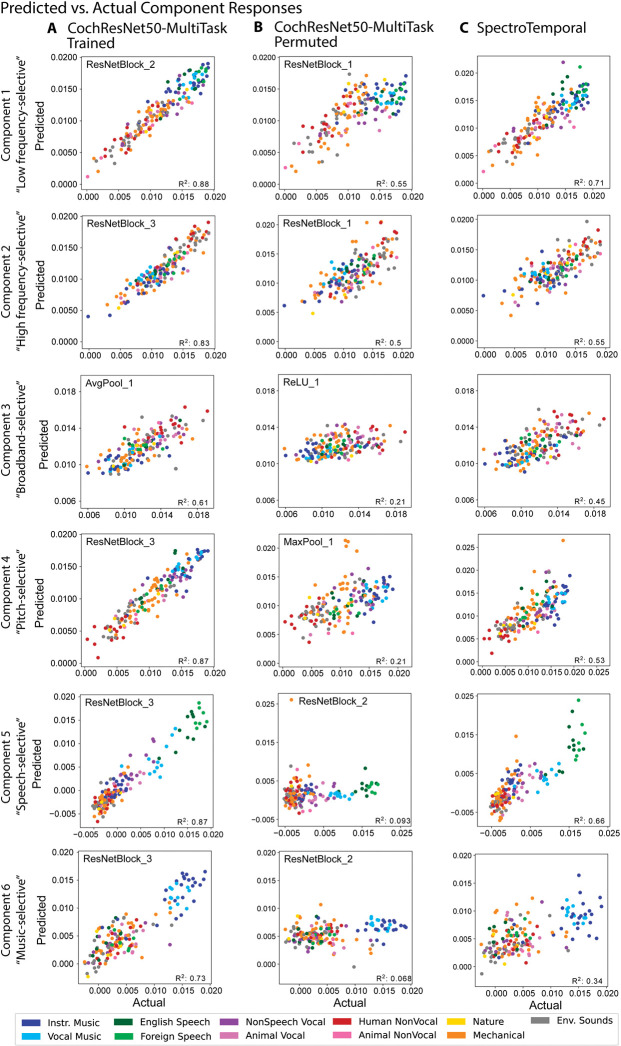
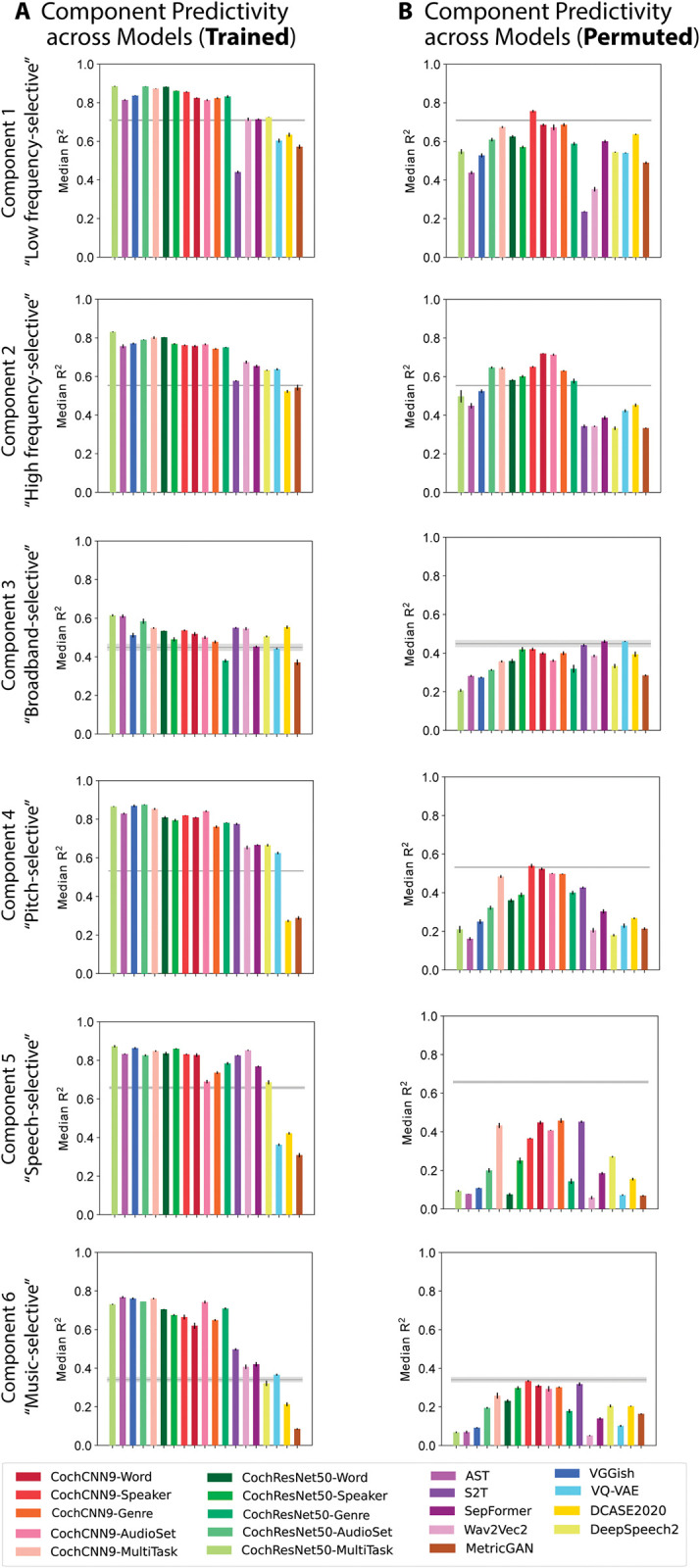
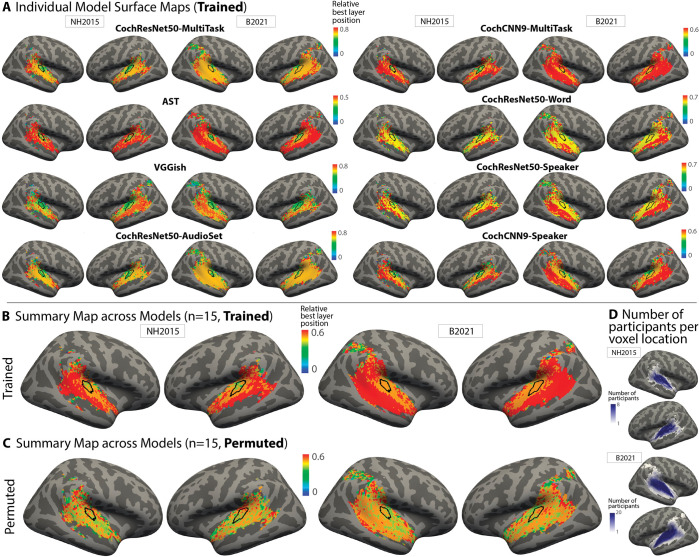
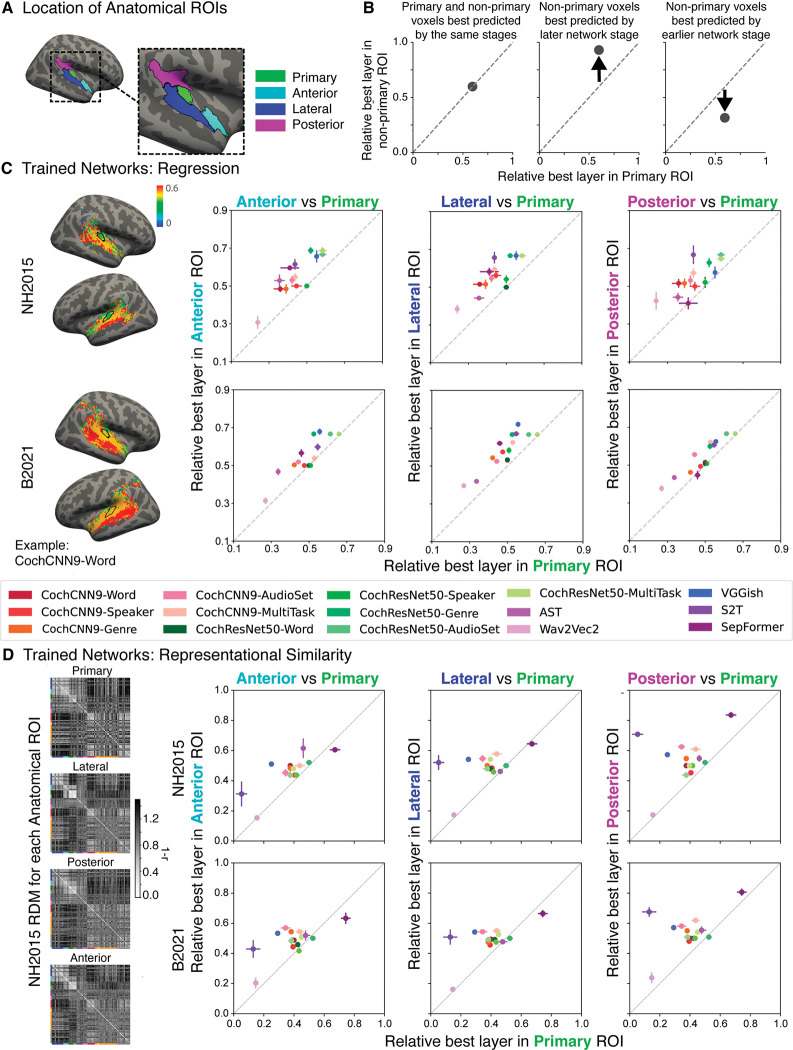
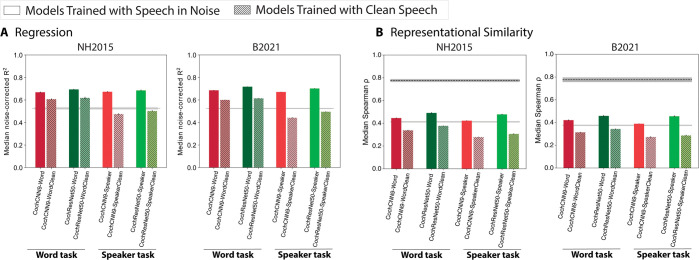
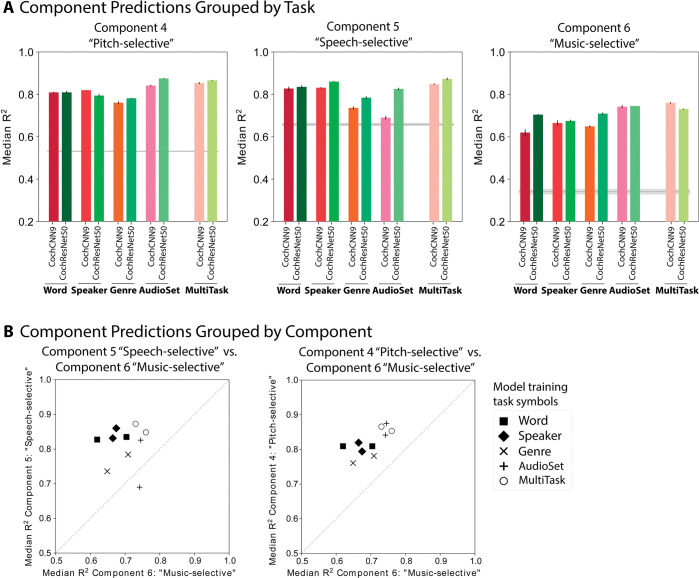
Models that predict brain responses to stimuli provide one measure of understanding of a sensory system and have many potential applications in science and engineering. Deep artificial neural networks have emerged as the leading such predictive models of the visual system but are less explored in audition. Prior work provided examples of audio-trained neural networks that produced good predictions of auditory cortical fMRI responses and exhibited correspondence between model stages and brain regions, but left it unclear whether these results generalize to other neural network models and, thus, how to further improve models in this domain. We evaluated model-brain correspondence for publicly available audio neural network models along with in-house models trained on 4 different tasks. Most tested models outpredicted standard spectromporal filter-bank models of auditory cortex and exhibited systematic model-brain correspondence: Middle stages best predicted primary auditory cortex, while deep stages best predicted non-primary cortex. However, some state-of-the-art models produced substantially worse brain predictions. Models trained to recognize speech in background noise produced better brain predictions than models trained to recognize speech in quiet, potentially because hearing in noise imposes constraints on biological auditory representations. The training task influenced the prediction quality for specific cortical tuning properties, with best overall predictions resulting from models trained on multiple tasks. The results generally support the promise of deep neural networks as models of audition, though they also indicate that current models do not explain auditory cortical responses in their entirety.
Copyright: © 2023 Tuckute et al. This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Conflict of interest statement
The authors have declared that no competing interests exist.
Figures
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
References
-
- Marblestone AH, Wayne G, Kording KP. Toward an integration of deep learning and neuroscience. Front Comput Neurosci [Internet]. 2016. Sep 14 [cited 2022 Feb 8];10. Available from: http://journal.frontiersin.org/Article/10.3389/fncom.2016.00094/abstract - DOI - PMC - PubMed
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources