Evolutionary selection of proteins with two folds
- PMID: 37673981
- PMCID: PMC10482954
- DOI: 10.1038/s41467-023-41237-2
Evolutionary selection of proteins with two folds
Abstract
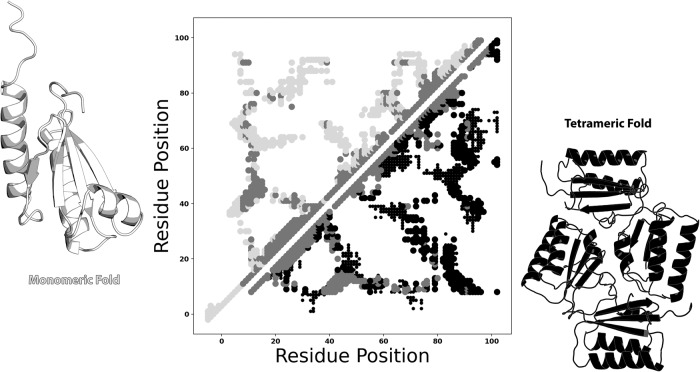
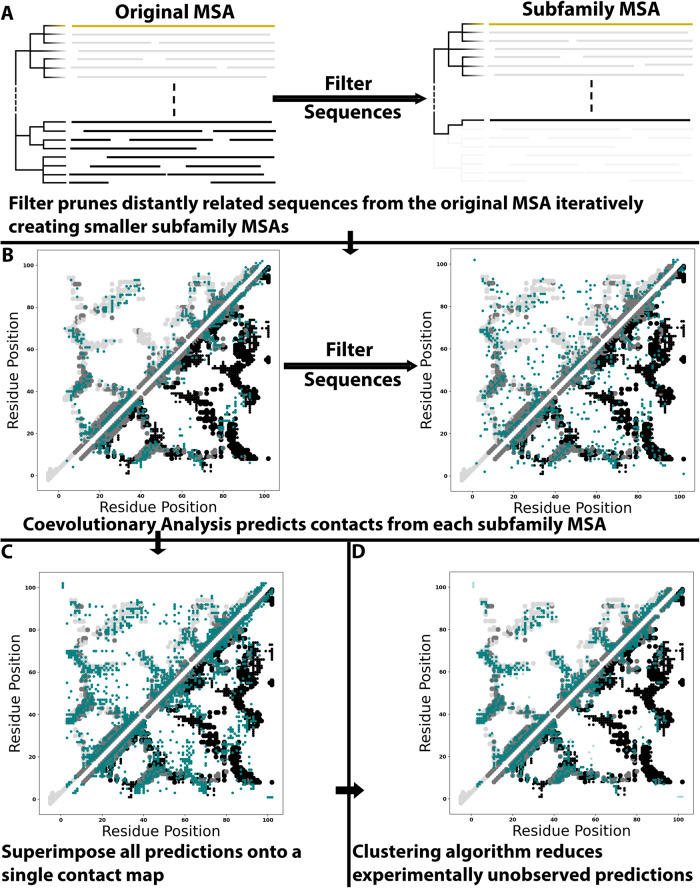
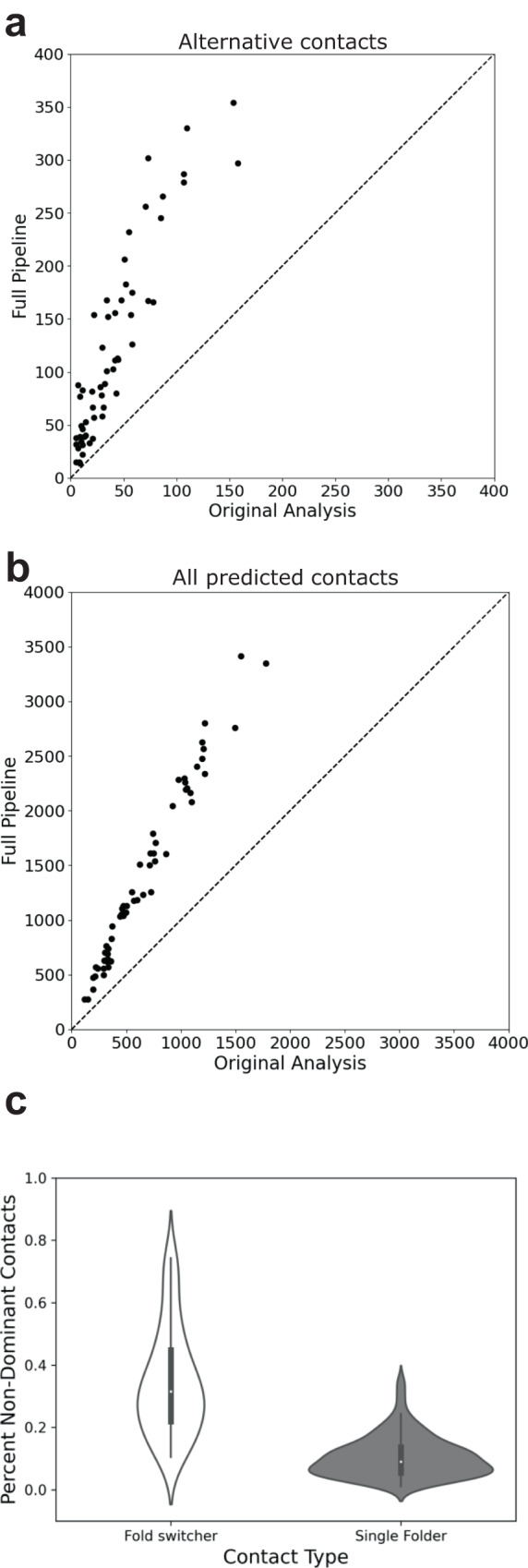
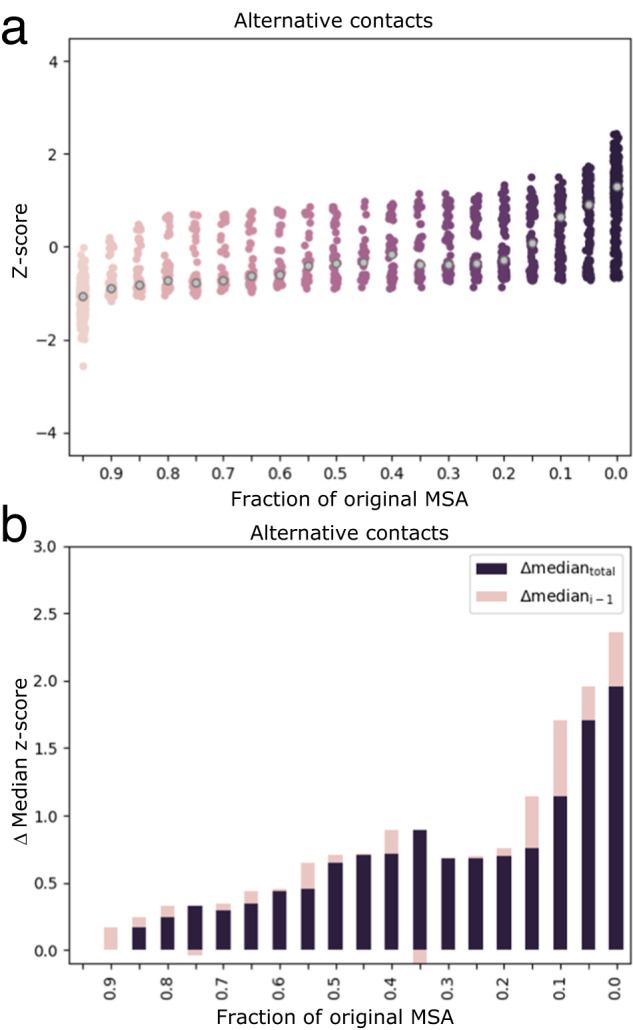
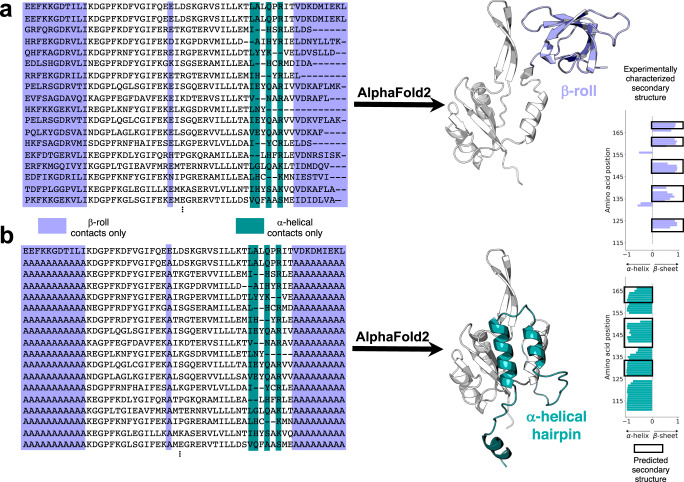
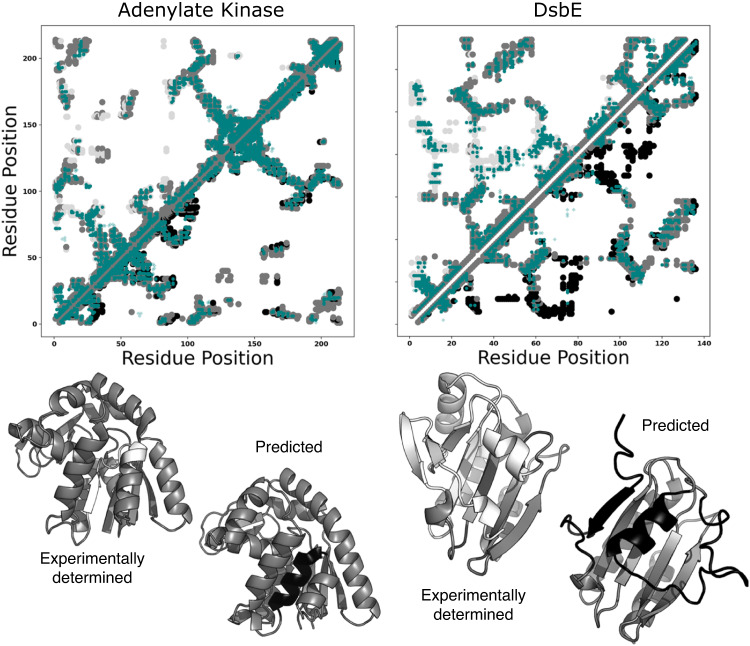
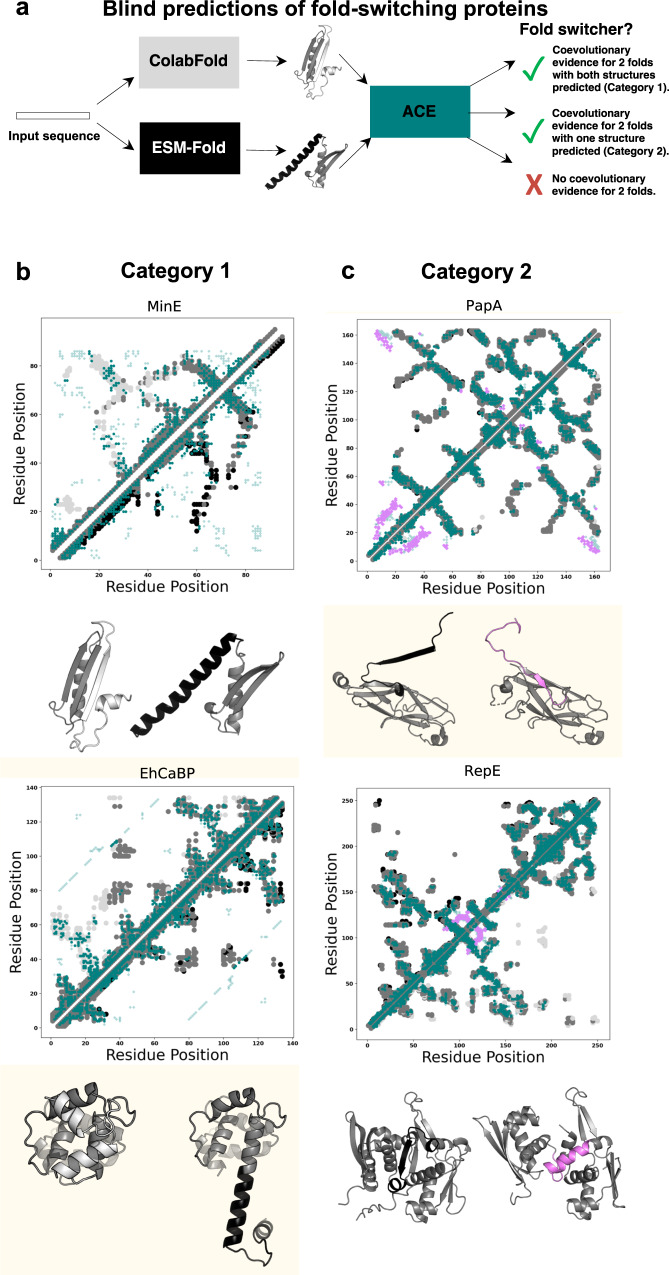
Although most globular proteins fold into a single stable structure, an increasing number have been shown to remodel their secondary and tertiary structures in response to cellular stimuli. State-of-the-art algorithms predict that these fold-switching proteins adopt only one stable structure, missing their functionally critical alternative folds. Why these algorithms predict a single fold is unclear, but all of them infer protein structure from coevolved amino acid pairs. Here, we hypothesize that coevolutionary signatures are being missed. Suspecting that single-fold variants could be masking these signatures, we developed an approach, called Alternative Contact Enhancement (ACE), to search both highly diverse protein superfamilies-composed of single-fold and fold-switching variants-and protein subfamilies with more fold-switching variants. ACE successfully revealed coevolution of amino acid pairs uniquely corresponding to both conformations of 56/56 fold-switching proteins from distinct families. Then, we used ACE-derived contacts to (1) predict two experimentally consistent conformations of a candidate protein with unsolved structure and (2) develop a blind prediction pipeline for fold-switching proteins. The discovery of widespread dual-fold coevolution indicates that fold-switching sequences have been preserved by natural selection, implying that their functionalities provide evolutionary advantage and paving the way for predictions of diverse protein structures from single sequences.
© 2023. Springer Nature Limited.
Conflict of interest statement
The authors declare no competing interests.
Figures
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Update of
-
Evolutionary selection of proteins with two folds.Schafer JW, Porter LL. Schafer JW, et al. bioRxiv [Preprint]. 2023 Jan 20:2023年01月18日.524637. doi: 10.1101/2023.01.18.524637. bioRxiv. 2023. Update in: Nat Commun. 2023 Sep 6;14(1):5478. doi: 10.1038/s41467-023-41237-2. PMID: 36789442 Free PMC article. Updated. Preprint.
References
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Miscellaneous