Hadoop HiveはHadoop上でSQLライクなクエリ操作が可能なDWH向けのプロダクトです。SQLに近い操作が可能なため、HBaseよりもデータベースに慣れ親しんだみなさんには使い勝手がいいかもしれません。本稿ではこのHiveの使い方とレビューを行っていきます。
Hiveは、オープンソースの大規模分散計算フレームワークHadoop上で動作するデータウエアハウス(Data Warehouse:DWH)向けのプロダクトです。
Hadoopは、グーグルが社内で利用しているGFSとMapReduceのオープンソース版です。詳細は次の記事を参照してください。
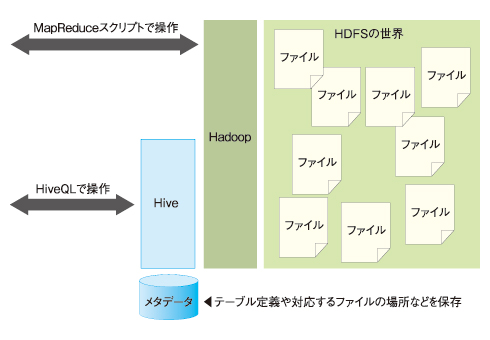
HiveはHiveQLというSQL風の言語でHadoop上のデータを操作できます。Hadoop上のデータベースというとHBaseが有名ですが、HiveはHDFSに対してよりユーザーフレンドリなインターフェイスを提供するもので、HBaseとは根本的に存在意義が異なります。
●くろまる図1 HadoopとHiveの概念
HiveはFacebookで開発され、2008年12月に正式にHadoopプロジェクトに寄贈(contribute)されました。
最新バージョンが0.19.1と、まだバージョンも若く、機能もドキュメントも不足していますが、すでにFacebook社内では2000台のサーバ上で稼働しているようで、今後の進展にも期待が持てるプロダクトです。
実際、2月20日にリリースされた0.19.1ではマイナーバージョンアップにもかかわらず、副問い合わせ(サブクエリ)をはじめ、文字列の連結concat( )や切り出しsubstr( )などの文字列関数、count( )やmin( )、max( )の集約関数など、多くの機能追加がありました。Hiveに関する基本的な情報源を下のコラムに示しますので、これらのドキュメントも参考にしてみてください。
次ページからは、実際にHadoop環境を手元のマシン上に構築し、Hiveの基本的な操作を試していきます。
Hiveについての基本的な情報は下記Webサイトにまとめられています。本稿とあわせて参考にしてください。
Copyright © ITmedia, Inc. All Rights Reserved.
{kind=link}
{kind=link}