Mainly Tech projects on Python and Electronic Design Automation.
Sunday, November 10, 2019
Quasi-random Sobol sequence
{kind=link}
In which I revisit low-discrepancy series, Hunt for an understanding of the Sobol sequence, then translate and optimise a C++ program into Python.
Re-visit VdC
I had left a mental note to get back to the Van der Corput sequence after creating the Rosetta Code task some years ago. Van der Corput is a type of low-discrepancy or quasi random sequence often used in Financial simulations; and with ever larger digital systems on automotive System on Chips, I keep a look-out for Verification techniques to add to the toolbox.I decided to investigate the Sobol Sequence, understand the maths and write some Python!
Sobol Maths
I followed references; I googled; I read; and I just could not gain an understanding of what is happening, enough to write some code. What code I initially browsed gave me only snippets - Those snippets were bit twiddling so I coded those up for fun.Fun bit twiddles
Highest 1 bit in binary number
def binhi1(b): "highest 1 bit of binary b. (== ceil(log2(b)))" pos = 0 while b > 0: pos, b = pos + 1, b // 2 return pos
Example 1
for n in range(18): print(f"{n:>5b} {binhi1(n)}") 0 0 1 1 10 2 11 2 100 3 101 3 110 3 111 3 1000 4 1001 4 1010 4 1011 4 1100 4 1101 4 1110 4 1111 4 10000 5 10001 5
Lowest 0 bit in binary number
def binlo0(b): "lowest 0 bit from right of binary b. Always >=1" pos, b2 = 1, b // 2 while b2 * 2 != b: pos, b, b2 = pos + 1, b2, b2 // 2 return pos
Example 2
for n in range(18): print(f"{n:<05b binlo0="" font="" n="">) 00000 1 00001 2 00010 1 00011 3 00100 1 00101 2 00110 1 00111 4 01000 1 01001 2 01010 1 01011 3 01100 1 01101 2 01110 1 01111 5 10000 1 10001 2
Code to translate
One of the Sobol references was this one by S. Joe and F. Y. Kuo. They had written academic papers on Sobol and had generated constants for the use of the sequence in up to 21201 dimensions. They also had a C++ program with BSD-style license and, crucially, sample outputs from their C++ code that could aid me in writing Python conversion of their code.I downloaded their C++ and their latest set of direction numbers and took a look. Eager to code something, I coded up a reader for their directions file:
Initial dirctions file reader
def direction_file_reader(fname="Sobol_new-joe-kuo-6.21201"): """\ Reads direction file of format: d s a m_i 2 1 0 1 3 2 1 1 3 4 3 1 1 3 1 5 3 2 1 1 1 6 4 1 1 1 3 3 ... """ with open(fname) as f: headers = f.readline().strip().split() assert headers == ['d', 's', 'a', 'm_i'] directions = [] for line in f: d, s, a, *m = [int(cell) for cell in line.strip().split()] directions.append((d, s, a, tuple([0] + m))) return directions
The direction file was three single columns then all the other columns made up the list m.
C++ code direct translation.
I decided to translate the C++ code near verbatim to Python, then run the example and ensure that the Python gave the same output as stated for the C++ program.I cut-n-pasted sections of the C++ code as comments/unused triple-quoted strings into my Python then slowly translated from C++.
The C++ used several single-character, uppercase, variable names. I took them to be references to their papers or maybe earlier Fortran programs and either kept them, or made note of their re-naming.
I finally got my first working Python code which is below, but without the C++ code comments I followed:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34
def sobol_points(N, D): """From: C++ Source of Frances Y. Kuo "sobol.cc" """ pow2_32 = 2**32 L = binhi1(N) C = [binlo0(i) for i in range(N)] points= [[0 for j in range(D)] for i in range(N)] V = [1 << (32- i) for i in range(L+1)] X = [0] for i in range(1, N): X.append(X[i-1] ^ V[C[i-1]]) points[i][0] = X[i]/pow2_32; del V, X directions = direction_file_reader() for j in range(1, D): d, s, a, m = directions[j-1] #print(d, s, a, m) if L <= s: V = [0] + [m[i] << (32 - i) for i in range(1, L+1)] else: V = [0] + [m[i] << (32 - i) for i in range(1, s+1)] for i in range(s+1, L+1): V.append(V[i-s] ^ (V[i-s] >> s)) for k in range(1, s): V[i] ^= (((a >> (s-1-k)) & 1) * V[i-k]) X = [0] for i in range(1, N): X.append(X[i-1] ^ V[C[i-1]]) points[i][j] = X[i]/pow2_32 return points
Issues with the directly translated Python/C++:
- The calculation ov V[] in lines 21 to 28 I thought should become a function.
- All points are computed and returned at once. It would be better as a generator function.
- The calculation of X[] in lines 29 to 31 seems like a very inefficient loop within a loop. Furthermore, if turned into a generator; Iwould need to unscramble the loops to try and recalculate X for each point without another loop.
Final Python generator function version
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134
# -*- coding: utf-8 -*- """sobol_point_gen.py Usage: sobol_point_gen.py N D <dimensions_file> sobol_point_gen.py -h | --help Options: -h --help Show this screen. Arguments: N Number of points to generate (<2**32) D Number of dimensions for each point. (D <= max D in dimensions_file) dimensions_file See: https://web.maths.unsw.edu.au/~fkuo/sobol/ Created from an original c++ source by Frances Y. Kuo and Stephen Joe Created on Fri Nov 1 09:13:12 2019 @author: Paddy3118 """ from functools import lru_cache #%% def binhi1(b): "highest 1 bit of binary b. (== ceil(log2(b)))" pos = 0 while b > 0: pos, b = pos + 1, b // 2 return pos def binlo0(b): "lowest 0 bit from right of binary b. Always >=1" pos, b2 = 1, b // 2 while b2 * 2 != b: pos, b, b2 = pos + 1, b2, b2 // 2 return pos #%% def direction_file_reader(d, fname="Sobol_new-joe-kuo-6.21201"): """\ Reads d+header lines from direction file of format: d s a m_i 2 1 0 1 3 2 1 1 3 4 3 1 1 3 1 5 3 2 1 1 1 6 4 1 1 1 3 3 7 4 4 1 3 5 13 8 5 2 1 1 5 5 17 9 5 4 1 1 5 5 5 10 5 7 1 1 7 11 19 11 5 11 1 1 5 1 1 12 5 13 1 1 1 3 11 13 5 14 1 3 5 5 31 14 6 1 1 3 3 9 7 49 15 6 13 1 1 1 15 21 21 16 6 16 1 3 1 13 27 49 17 6 19 1 1 1 15 7 5 18 6 22 1 3 1 15 13 25 19 6 25 1 1 5 5 19 61 20 7 1 1 3 7 11 23 15 103 21 7 4 1 3 7 13 13 15 69 22 7 7 1 1 3 13 7 35 63 23 7 8 1 3 5 9 1 25 53 24 7 14 1 3 1 13 9 35 107 25 7 19 1 3 1 5 27 61 31 26 7 21 1 1 5 11 19 41 61 27 7 28 1 3 5 3 3 13 69 28 7 31 1 1 7 13 1 19 1 29 7 32 1 3 7 5 13 19 59 30 7 37 1 1 3 9 25 29 41 31 7 41 1 3 5 13 23 1 55 32 7 42 1 3 7 3 13 59 17 ... """ with open(fname) as f: headers = f.readline().strip().split() assert headers == ['d', 's', 'a', 'm_i'] directions = [] for i, line in zip(range(d), f): d, s, a, *m = [int(cell) for cell in line.strip().split()] directions.append((d, s, a, tuple([0] + m))) return directions #%% @lru_cache(128) def calc_dnum(s, a, m, mxbits): # V, direction numbers if mxbits <= s: dirnum = [0] + [m[i] << (32 - i) for i in range(1, mxbits+1)] else: dirnum = [0] + [m[i] << (32 - i) for i in range(1, s+1)] for i in range(s+1, mxbits+1): dirnum.append(dirnum[i-s] ^ (dirnum[i-s] >> s)) for k in range(1, s): dirnum[i] ^= (((a >> (s-1-k)) & 1) * dirnum[i-k]) return dirnum def sobol_point_gen(N, D, fname="Sobol_new-joe-kuo-6.21201"): pow2_32 = 2**32 mxbits = binhi1(N) # L, max bits needed dnum = [1 << (32- i) for i in range(mxbits+1)] # V, direction numbers directions = direction_file_reader(D, fname) xd = [0 for j in range(D)] # X pt = [0 for j in range(D)] # POINTS yield pt for n in range(1, N): nfirst0 = binlo0(n-1) # C pt = [0 for j in range(D)] xd[0] = xd[0] ^ dnum[nfirst0] pt[0] = xd[0] / pow2_32 for jj in range(1, D): _, s, a, m = directions[jj-1] dnum2 = calc_dnum(s, a, m, mxbits) # V, direction numbers xd[jj] = xd[jj] ^ dnum2[nfirst0] pt[jj] = xd[jj]/pow2_32 yield pt #%% if __name__ == '__main__': first_sobol_3D_points = [ [0, 0, 0], [0.5, 0.5, 0.5], [0.75, 0.25, 0.25], [0.25, 0.75, 0.75], [0.375, 0.375, 0.625], [0.875, 0.875, 0.125], [0.625, 0.125, 0.875], [0.125, 0.625, 0.375], [0.1875, 0.3125, 0.9375], [0.6875, 0.8125, 0.4375]] generated = list(sobol_point_gen(10, 3)) assert generated == first_sobol_3D_points
Function def direction_file_reader is changed to only read as much of thedirections file as is necessary.
Function def sobol_point_gen is now a generator function in which successive calls to next give successive points. The loops are swapped inside with an outer loop yielding a point every iteration, and an inner loop over dimensions > 1.
Function def calc_dnumis cached. Initial suspicions of a lot of recalculation proved true:
calc_dnum cache stats
In [1]: g = list(sobol_point_gen(10000, 3)) In [2]: calc_dnum.cache_info() Out[2]: CacheInfo(hits=20012, misses=4, maxsize=128, currsize=4)
Sunday, October 20, 2019
Indent datastructure for trees
I was browsing StackOverflow and came across a question that mentioned a new-to-me format for a datatructure for holding a tree of data.I am well used to the (name, list_of_children) set of interconnected node datastructures way of doing things, but this mentioned where you
1
2
4
7
5
3
6
8
9
10
- Create an empty list
- then for each node starting at the root which has a depth of zero:
- add the (depth, name) tuple of the node to the list
- visit all this nodes child node.
An example tree:
{kind=link}
Its indent format:
[(0, 'R'), (1, 'a'), (2, 'c'), (3, 'd'), (3, 'h'), (1, 'b'), (2, 'e'), (3, 'f'), (4, 'g'), (2, 'i')]
Indented representation:
If you print out successive names from the indent format list above, one per line, with indent from the left of the indent value, then you get a nice textual regpresentation of the tree; expanded left-to-right rather than the top-down representation of the graphic:R a c d h b e f g i
Code
I wrote some code to manipulate and traverse this kind of tree datastructure, as well as to use graphviz to draw graphical representations.1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152
import graphviz as gv from collections import defaultdict import re from pprint import pprint as pp #%% node_attr = {at: val for at, val in (line.strip().split() for line in ''' shape record fontsize 12 height 0.1 width 0.1 rankdir LR ranksep 0.25 nodesep 0.25 '''.strip().split('\n'))} edge_attr = {at: val for at, val in (line.strip().split() for line in ''' arrowhead none minlen 1 '''.strip().split('\n'))} root_attr = {at: val for at, val in (line.strip().split() for line in ''' fontcolor green color brown fontname bold '''.strip().split('\n'))} #%% def _pc2indent(pc, root=None, indent=None, children=None): "parent-child dependency dict to indent format conversion" if root is None: parents = set(pc) kids = set(sum(pc.values(), [])) root = parents - kids assert len(root) == 1, f"Need exactly one root: {root}" root = root.pop() if indent is None: indent = 0 if children is None: children = [] children.append((indent, root)) if root in pc: for child in pc[root]: pc2indent(pc, child, indent+1, children) return children def dot2indent(tree): "simple dot format to indent format translator" depends = defaultdict(list) for matchobj in re.finditer(r'\s+(\S+)\s*->\s*(\S+)\s', tree.source): parent, child = matchobj.groups() depends[parent].append(child) parent2child = dict(depends) return _pc2indent(parent2child) #%% def _highlight(txt): return f'#{txt}#' def pp_indent(data, hlight=None, indent=' '): "simple printout of indent format tree with optional node highlighting" if hlight is None: hlight = set() for level, name in data: print(indent * level + (_highlight(name) if name in hlight else name)) #%% def indent2dot(lst): tree = gv.Digraph(name='indent2dot', node_attr=node_attr) tree.edge_attr.update(**edge_attr) levelparent = {} for level, name in lst: levelparent[level] = name if level - 1 in levelparent: tree.edge(levelparent[level-1], name) else: tree.node(name, _attributes=root_attr) return tree #%% def printwithspace(i): print(i, end=' ') def preorder(tree, visitor=printwithspace): for indent, name in tree: visitor(name) def levelorder(tree, reverse_depth=False, reverse_in_level=False, visitor=printwithspace): if not tree: return indent2name = defaultdict(list) mx = -1 for indent, name in tree: if indent > mx: mx = indent indent2name[indent].append(name) if reverse_in_level: for names in indent2name.values(): names.reverse() if not reverse_depth: for indent in range(0, mx + 1): for name in indent2name[indent]: visitor(name) else: for indent in range(mx, -1, -1): for name in indent2name[indent]: visitor(name) #%% # Example tree ex1 = [(0, '1'), (1, '2'), (2, '4'), (3, '7'), (2, '5'), (1, '3'), (2, '6'), (3, '8'), (3, '9'), (3, '10'), ] #%% if __name__ == '__main__': print('A tree in indent datastructure format:') pp(ex1) print('\nSame tree, printed as indented list:') pp_indent(ex1) print('\nSame tree, drawn by graphviz:') display(indent2dot(ex1)) # display works in spyder/Jupyter print('\nSame tree, preorder traversal:') preorder(ex1) print() print('Same tree, levelorder traversal:') levelorder(ex1) print() print('Same tree, reverse_depth levelorder traversal:') levelorder(ex1, True) print() print('Same tree, reverse_depth, reverse_in_level levelorder traversal:') levelorder(ex1, True, True) print() print('Same tree, depth_first, reverse_in_level levelorder traversal:') levelorder(ex1, False, True) print()
Output:
A tree in indent datastructure format:
[(0, '1'),
(1, '2'),
(2, '4'),
(3, '7'),
(2, '5'),
(1, '3'),
(2, '6'),
(3, '8'),
(3, '9'),
(3, '10')]
Same tree, printed as indented list:
1
2
4
7
5
3
6
8
9
10
Same tree, drawn by graphviz:
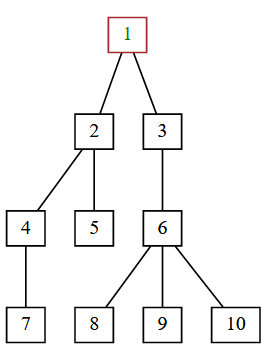{kind=link}
Same tree, preorder traversal:
1 2 4 7 5 3 6 8 9 10
Same tree, levelorder traversal:
1 2 3 4 5 6 7 8 9 10
Same tree, reverse_depth levelorder traversal:
7 8 9 10 4 5 6 2 3 1
Same tree, reverse_depth, reverse_in_level levelorder traversal:
10 9 8 7 6 5 4 3 2 1
Same tree, depth_first, reverse_in_level levelorder traversal:
1 3 2 6 5 4 10 9 8 7
In [47]:
Sunday, October 13, 2019
ISO26262:: Some thoughts on Specs.
It seems as if there are many engineers who can do, but who struggle with doing the documentation.
In safety flows, everything comes from the specification - the designer designs to the spec., the verification team verify that the spec. is correctly implemented.
proceed to write up as the spec. Those tools often create a wealth of structured data such as:
When writing the spec: Parts can be automated by using these concept pre-spec data sources to generate aspects.
When implementing and verifying the design: Parts can be automated by using these data sources.
What is often left out is: ISO26262 mandates that all data come from the spec.
We have standard ways of expressing our technical concepts that are expected to be used. In the world of safety, they need to be built upon.
In safety flows, everything comes from the specification - the designer designs to the spec., the verification team verify that the spec. is correctly implemented.
- The spec. is central.
- The spec. is a document written by engineers.
- In modern system-on-chip designs, the spec. is complex.
Structured data
Let's call those that develop specs Concept Engineers. Concept engineers will have their modelling tools, scripts, and spreadsheets, etc that they use to converge on the correct design that theyproceed to write up as the spec. Those tools often create a wealth of structured data such as:
- Register maps
- Register field descriptions
- Memory maps
- Top level bus maps
- ...
When writing the spec: Parts can be automated by using these concept pre-spec data sources to generate aspects.
When implementing and verifying the design: Parts can be automated by using these data sources.
What is often left out is: ISO26262 mandates that all data come from the spec.
What is the spec?
I assume that the specification must be print friendly and understandable. You need to convince auditors that what is delivered is an expression of the spec. I am assuming that expressing all of the concept-stage structured data in textual form and appending reams of xml as an appendix is unacceptable. You need register tables, state machine diagrams, truth tables, ...We have standard ways of expressing our technical concepts that are expected to be used. In the world of safety, they need to be built upon.
Round tripping
If an item is auto generated from structured date for use by the design verification team, then:- The spec. should contain that data.
- Create a script that can scrape the end spec. format (usually a PDF), and regenrate the structured data - identical enough so that a simple textual diff will show they are the same.
Scraping aids:
(I.e. aids to scrape data from a specification. Like web-scraping does for HTML)- I usually take the spec in PDF as a format for reading. Luckily, if you check with your PDF generation tools, there are PDF readers that can convert PDF's to spreadsheets, In my current case, PDF text lines appear as spreadsheet rows with the text line all in the leftmost column. PDF table columns appear in multiple cells of rows, and each PDF page is a separate sheet of the workbook.
Python, and other languages have libraries that can read spreadsheets. - The "original" structured data generated from concept engineering tools should be "pretty printed" and ordered before use in downstraem flows to allow easier textual comparison by diff'ing or other simple means.
- When generating sections of text for a spec from structured data pre-tag that section.
Pre tagging means adding a recognised word or sequence of words immediately before the generated spec data that denotes the format of that data chunk. For example, it could be a new line starting REGISTER:: that must allways start a register definition with its fields arranged, in-order, inside a 31-to-16, then 15-to-0 annottated horizontal table; then a table with headers of maybe "field, bitrange, type, comment"; defined text specifying register features; ...
That pre-tag format should be used throughout the document and should not detract from how it reads. I use an example of a word followed by double colons above; a hash, '#' followed by a word, (a hashtag), would work too, but choose a format and stick to it.
Making the tag immediately precede what is tagged and having data fields with the same tag be expressed in the same format aids scraping enormousely. (And reading too). - Show the structure in the items: If a pre-tagged item, such as a register name has a range of values then show a parameterised name and use a named index then show how the index links to properties of the register (in this case), that are designed to vary with the index, e.g. register offset, any of the registers bitfields, reset values, ...
Don't expand the index in the spec. as valuable information may be lost. It may seem easier if the index has only two values, to add two sepearate "expanded" entries, but then their inter-relationships and the very fact that they are related, must then be inferred rather than being given.
Different , separate, parameterised items may then share the same named index and index range to show extra information
Scraping benefits
- Data duplication in specs: Explaining a topic might need the mention of a tagged item before items of that type are all shown, for example specific registers before the section where all registers are shown as part of the register map. When the spec is scraped, the scraper can make sure multiple definition are equivalent.
- Scraped data can be used to regenerate the concept data used in design and verification flows before the spec was finalised to ensure the spec is correct. (Or those tools rerun on the specs scraped data).
- By thinking of scraping needs, you are forced to think about finding the patterns in the data, and ensuring th spec is complete.
Diagrams
They are too much bother to try and scrape I find. I'd cut down on expressing Concept data used to generate verification and design parts as only diagrams in the spec. Most diagrams do have textul countrparts such as netlists. Creative layout of textual , parsable "code", may suffice or be used in addition to the diagram that ahows the same - scraping might then just point out an area for manual checking.When you just can't get away from that long list
Lets say you have have 1024 identical register in all but name and "power domain". You could use a parameterised name for the register type, an alias for each indexed instance of that register type. The data format for registers needs to expand to have a field pointing to a named, pre-tagged data table that would map each index to its alias and power domain. (Of course, if the table is never very wide, then it could be doubled-up on the page to save space and make the spec. more presentable - someone will read it.END.
(There are other aspects of spec writing I need to write about in further posts.).Tuesday, August 27, 2019
N-Dimensional matrix to 1-D array indexing translations.
Having done the 2-D address indexing translations, I thught about how to translate between a set of 3-D indices and a linear 1-D array index then extrapolated to n-dimensions.
I liked the idea of testing the solution and have brought that across too (with additions)
The class
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42
# -*- coding: utf-8 -*- """ Created on Tue Aug 27 01:49:51 2019 @author: Paddy3118 """ from collections import OrderedDict from itertools import product from functools import reduce #%% class ND21D_Addressing(): """ Convert n-dimensional indexing to/from 1-D index as if packed into 1-D array. All indices assumed to start from zero """ def __init__(self, *extent): "extent is tuple of index sizes in each dimension" n_dim = len(extent) # Dimensionality self._extent = extent self._offsets = [reduce(int.__mul__, extent[n + 1:], 1) for n in range(n_dim)] # What n-dimensional index-tuple is stored at linear index. def i2ndim(self, index_i): "1-D array index to to n-D tuple of indices" return tuple((index_i // s) % c for s, c in zip(self._offsets, self._extent)) # What linear 1-D index stores n-D tuple of indices. def ndim2i(self, ni): "n-D tuple of indices to 1-D array index" return sum(d * s for s, d in zip(self._offsets, ni)) def __repr__(self): return f"{self.__class__.__name__}({str(self._extent)[1:-1]})" #%%
The test
43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108
def _irange(mini, maxi): "Integer range mini-to-maxi inclusive of _both_ endpoints" # Some think ranges should include _both_ endpoints, oh well. return range(mini, maxi+1) def _print_n_dim(ranges_from_zero): "Represent the indexing of an n-D matrix" last = [0] * len(ranges_from_zero) for ni in product(*ranges_from_zero): for s, t in zip(last, ni): if s != t and t == 0: print() last = ni print(str(ni).replace(' ', ''), end=' ') print() #%% if __name__ == "__main__": # Dimensionality for test n_dim = 4 # range of values in each dimension. dranges = [_irange(0, d+1) for d in range(n_dim)] # Num of values in each dim. extent = [len(dr) for dr in dranges] ## The address mapper instance admap = ND21D_Addressing(*extent) ## A test matrix of given dimensionality # Optimum size of mapping to 1-dim. array size_1d = reduce(int.__mul__, extent) # Range of all mapped to 1-dim. array index values range_1d = _irange(0, size_1d - 1) print(f"\n## ORIGINAL {n_dim}-D ARRAY:") _print_n_dim(dranges) print(f"\n# TEST TRIAL MAP {n_dim}-D TO/FROM 1-D ARRAY ADDRESSING") # Representing a 1-D array mapped to n-D index tuple dim_1 = OrderedDict((index_i, admap.i2ndim(index_i)) for index_i in range_1d) all_ndim = set(dim_1.values()) all_by_dim = [set(d1) for d1 in zip(*all_ndim)] assert len(all_ndim) == size_1d, "FAIL! ndim index count" for a_dim, its_count in zip(all_by_dim, extent): assert len(set(a_dim)) == its_count, \ "FAIL! ndim individual index count" # Representing n-D index tuple mapped to 1-D index dim_n = OrderedDict(((ndim), admap.ndim2i(ndim)) for ndim in product(*dranges)) all_i = set(dim_n.values()) assert min(all_i) == 0, "FAIL! Min index_i not zero" assert max(all_i) == size_1d - 1, \ f"FAIL! Max index_i not {size_1d - 1}" # Check inverse mappings assert all(dim_1[dim_n[ndim]] == ndim for ndim in dim_n), \ "FAIL! Mapping n-D to/from 1-D indices" assert all(dim_n[dim_1[index_i]] == index_i for index_i in range_1d), \ "FAIL! Mapping 1-D to/from n-D indices" print(f" {admap}: PASS!")
The test output
## ORIGINAL 4-D ARRAY: (0,0,0,0) (0,0,0,1) (0,0,0,2) (0,0,0,3) (0,0,0,4) (0,0,1,0) (0,0,1,1) (0,0,1,2) (0,0,1,3) (0,0,1,4) (0,0,2,0) (0,0,2,1) (0,0,2,2) (0,0,2,3) (0,0,2,4) (0,0,3,0) (0,0,3,1) (0,0,3,2) (0,0,3,3) (0,0,3,4) (0,1,0,0) (0,1,0,1) (0,1,0,2) (0,1,0,3) (0,1,0,4) (0,1,1,0) (0,1,1,1) (0,1,1,2) (0,1,1,3) (0,1,1,4) (0,1,2,0) (0,1,2,1) (0,1,2,2) (0,1,2,3) (0,1,2,4) (0,1,3,0) (0,1,3,1) (0,1,3,2) (0,1,3,3) (0,1,3,4) (0,2,0,0) (0,2,0,1) (0,2,0,2) (0,2,0,3) (0,2,0,4) (0,2,1,0) (0,2,1,1) (0,2,1,2) (0,2,1,3) (0,2,1,4) (0,2,2,0) (0,2,2,1) (0,2,2,2) (0,2,2,3) (0,2,2,4) (0,2,3,0) (0,2,3,1) (0,2,3,2) (0,2,3,3) (0,2,3,4) (1,0,0,0) (1,0,0,1) (1,0,0,2) (1,0,0,3) (1,0,0,4) (1,0,1,0) (1,0,1,1) (1,0,1,2) (1,0,1,3) (1,0,1,4) (1,0,2,0) (1,0,2,1) (1,0,2,2) (1,0,2,3) (1,0,2,4) (1,0,3,0) (1,0,3,1) (1,0,3,2) (1,0,3,3) (1,0,3,4) (1,1,0,0) (1,1,0,1) (1,1,0,2) (1,1,0,3) (1,1,0,4) (1,1,1,0) (1,1,1,1) (1,1,1,2) (1,1,1,3) (1,1,1,4) (1,1,2,0) (1,1,2,1) (1,1,2,2) (1,1,2,3) (1,1,2,4) (1,1,3,0) (1,1,3,1) (1,1,3,2) (1,1,3,3) (1,1,3,4) (1,2,0,0) (1,2,0,1) (1,2,0,2) (1,2,0,3) (1,2,0,4) (1,2,1,0) (1,2,1,1) (1,2,1,2) (1,2,1,3) (1,2,1,4) (1,2,2,0) (1,2,2,1) (1,2,2,2) (1,2,2,3) (1,2,2,4) (1,2,3,0) (1,2,3,1) (1,2,3,2) (1,2,3,3) (1,2,3,4) # TEST TRIAL MAP 4-D TO/FROM 1-D ARRAY ADDRESSING ND21D_Addressing(2, 3, 4, 5): PASS!
Monday, August 26, 2019
2-Dimension matrix to 1-D array, index translations.
Work has me working with hardware registers. Many registers; arrayed registers; multi-arrayed registers!.
The verifiction library I use has code to handle 1-D arrays of registers but not for 2-d (matrix) of registers - which is the problem I have today.
Given a 2-D matrix of values to store and access in a system that allows the storingof 1-D arrays of values, how do you map from the 2-D x,y indices to the 1-D i index - and vice-versa?
Rather than "do the math" to work out the correct functions needed to generate a 1-D array index i, from two matrix indices x and y - as well as the reverse function - I decided to take a suck-it-and-see approach. I had ideas that contain the correct solution and devised tests to reject faulty implementations.
To test them I create a python function from the text using eval in line 50 then, knowing that if the matrix has three possible x values and four possible y values and so indexes exactly 3*4 = 24 values, I use a range of 1-D index of 0-to-23 inclsive to hold the corresponding x,y tuples generated, in the (oredered) dict dim_1 in line 52.
Sets all_xy, all_x, and all_y (lines54-56), accumulate the different indexing number-pairs and numbers seen in all/each dimension of the matrix indexing generated from this function i2xy. They are then tested to ensure they have the expected number and range of individual indeces
in lines 57-68.
all permutations of the range of x and y index values are used to generate sample 1-D indeces in dict dim_n (line 73), then the generated 1-D indices are checked (line 76+)
The last check, from line 86, checks that the i2xy function and xy2i functions are inverses of each other, generating and decoding the same indeces.
Or to rewrite the lambdas as functions:
The verifiction library I use has code to handle 1-D arrays of registers but not for 2-d (matrix) of registers - which is the problem I have today.
Problem Statement
A useful description of the problem is:Given a 2-D matrix of values to store and access in a system that allows the storingof 1-D arrays of values, how do you map from the 2-D x,y indices to the 1-D i index - and vice-versa?
Partial memory
It's several decades since I first looked into this but I do remember divmod! Divmod was a part of the solution:divmod(x, y) returns (x // y, x % y) i.e the integer divisor and the integer remainder of x and y, as a tuple.Rather than "do the math" to work out the correct functions needed to generate a 1-D array index i, from two matrix indices x and y - as well as the reverse function - I decided to take a suck-it-and-see approach. I had ideas that contain the correct solution and devised tests to reject faulty implementations.
Setup
- Indices in any dimension count up from zero.
- Use a different maximum index in each matrix dimension to aid later checks
- I created function irange (line 14+), as sometimes people like to generate integer ranges that include both endpoints.
1-D to 2-D
Variable i_to_xy_list on lines 35+, has the source for four functions alternatives that when given a 1-D index generate a tuple of index numbers representing x and y. All four use divmod.To test them I create a python function from the text using eval in line 50 then, knowing that if the matrix has three possible x values and four possible y values and so indexes exactly 3*4 = 24 values, I use a range of 1-D index of 0-to-23 inclsive to hold the corresponding x,y tuples generated, in the (oredered) dict dim_1 in line 52.
Sets all_xy, all_x, and all_y (lines54-56), accumulate the different indexing number-pairs and numbers seen in all/each dimension of the matrix indexing generated from this function i2xy. They are then tested to ensure they have the expected number and range of individual indeces
in lines 57-68.
2-D to 1-D
Similarly xy_to_i_list has four possible ways that could match-up with a passing 1-D to 2-D fnction to do the reverse conversion from x,y coords to linear array index i.all permutations of the range of x and y index values are used to generate sample 1-D indeces in dict dim_n (line 73), then the generated 1-D indices are checked (line 76+)
The last check, from line 86, checks that the i2xy function and xy2i functions are inverses of each other, generating and decoding the same indeces.
The output
## ORIGINAL 2-D ARRAY: 0,0 0,1 0,2 0,3 1,0 1,1 1,2 1,3 2,0 2,1 2,2 2,3 # TRIAL MAPPINGS TO 1-D ARRAY FAIL! x count from `x, y = (lambda index_i: divmod(index_i, xcount))(index_i)` FAIL! Max index_i not 11 in `index_i = (lambda x, y: x * xcount + y)(x, y)` PASS! `x, y = (lambda index_i: divmod(index_i, ycount))(index_i); index_i = (lambda x, y: x * ycount + y)(x, y)` FAIL! Max index_i not 11 in `index_i = (lambda x, y: x + y * ycount)(x, y)` FAIL! Mapping index_i to/from x, y using `x, y = (lambda index_i: divmod(index_i, ycount))(index_i); index_i = (lambda x, y: x + y * xcount)(x, y)` FAIL! Max index_i not 11 in `index_i = (lambda x, y: x * xcount + y)(x, y)` FAIL! Mapping index_i to/from x, y using `x, y = (lambda index_i: divmod(index_i, xcount)[::-1])(index_i); index_i = (lambda x, y: x * ycount + y)(x, y)` FAIL! Max index_i not 11 in `index_i = (lambda x, y: x + y * ycount)(x, y)` PASS! `x, y = (lambda index_i: divmod(index_i, xcount)[::-1])(index_i); index_i = (lambda x, y: x + y * xcount)(x, y)` FAIL! x count from `x, y = (lambda index_i: divmod(index_i, ycount)[::-1])(index_i)` # SUMMARY PASS! `x, y = (lambda index_i: divmod(index_i, ycount))(index_i); index_i = (lambda x, y: x * ycount + y)(x, y)` PASS! `x, y = (lambda index_i: divmod(index_i, xcount)[::-1])(index_i); index_i = (lambda x, y: x + y * xcount)(x, y)`
Or to rewrite the lambdas as functions:
# These two: def i2xy(i): return divmod(i, ycount) def xy2i(x, y): return x * ycount + y # Or these two: def i2xy(i): return reversed(divmod(i, xcount)) def xy2i(x, y): return x + y * xcount
Code:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102
# -*- coding: utf-8 -*- """ Created on Sat Aug 24 21:31:03 2019 @author: Paddy3118 """ from collections import OrderedDict from itertools import product from pprint import pprint as pp #%% def irange(mini, maxi): "Integer range mini-to-maxi inclusive of _both_ endpoints" # Some think ranges should include _both_ endpoints, oh well. return range(mini, maxi+1) #%% xrange = irange(0, 2) yrange = irange(0, 3) xcount = len(xrange) # 3 ycount = len(yrange) # 4 print("\n## ORIGINAL 2-D ARRAY:") for x in xrange: print(' '.join(f"{x},{y}" for y in yrange)) #%% print("\n # TRIAL MAPPINGS TO 1-D ARRAY") print_on_fail, print_on_pass = False, False # Possible ways to get what n-dimensional index-tuple is stored at linear index i_to_xy_list = """ lambda index_i: divmod(index_i, xcount) lambda index_i: divmod(index_i, ycount) lambda index_i: divmod(index_i, xcount)[::-1] lambda index_i: divmod(index_i, ycount)[::-1] """.strip().split('\n') # Possible ways to generate a linear 1-D index from n-D tuple of indices xy_to_i_list = """ lambda x, y: x * xcount + y lambda x, y: x * ycount + y lambda x, y: x + y * ycount lambda x, y: x + y * xcount """.strip().split('\n') passes = [] for i_to_xy in i_to_xy_list: i2xy = eval(i_to_xy) # Representing a 1-D array as OrderedDict preserves insertion order dim_1 = OrderedDict((index_i, i2xy(index_i)) for index_i in irange(0, xcount*ycount - 1)) all_xy = set(dim_1.values()) all_x = set(x for x, y in dim_1.values()) all_y = set(y for x, y in dim_1.values()) if len(all_xy) != xcount * ycount: print(f" FAIL! x,y count from `x, y = ({i_to_xy})(index_i)`") if print_on_fail: pp(dim_1) continue if len(all_x) != xcount: print(f" FAIL! x count from `x, y = ({i_to_xy})(index_i)`") if print_on_fail: pp(dim_1) continue if len(all_y) != ycount: print(f" FAIL! y count from `x, y = ({i_to_xy})(index_i)`") if print_on_fail: pp(dim_1) continue # for xy_to_i in xy_to_i_list: xy2i = eval(xy_to_i) # Representing a N-D array dim_n = OrderedDict(((x, y), xy2i(x, y)) for x, y in product(xrange, yrange)) all_i = set(dim_n.values()) if min(all_i) != 0: print(f" FAIL! Min index_i not zero in " f"`index_i = ({xy_to_i})(x, y)`") if print_on_fail: pp(dim_n) continue if max(all_i) != xcount * ycount - 1: print(f" FAIL! Max index_i not {xcount * ycount - 1} in " f"`index_i = ({xy_to_i})(x, y)`") if print_on_fail: pp(dim_n) continue if not all(dim_1[dim_n[xy]] == xy for xy in dim_n): print(f" FAIL! Mapping index_i to/from x, y using " f"`x, y = ({i_to_xy})(index_i); index_i = ({xy_to_i})(x, y)`") if print_on_fail: pp(dim_1) if print_on_fail: pp(dim_n) continue passes.append((i_to_xy, xy_to_i)) print(f" PASS! `x, y = ({i_to_xy})(index_i); index_i = ({xy_to_i})(x, y)`") if print_on_pass: pp(dim_1) pp(dim_n) print('\n# SUMMARY') for i_to_xy, xy_to_i in passes: print(f" PASS! `x, y = ({i_to_xy})(index_i); index_i = ({xy_to_i})(x, y)`") #
Subscribe to:
Comments (Atom)
About Me
Followers
Subscribe Now: google
Go deh too!
whos.amung.us
Blog Archive
-
2014
(18)
- October (1)
- September (1)
- August (2)
- July (2)
- June (3)
- May (2)
- March (3)
- February (3)
- January (1)
-
2013
(14)
- November (2)
- October (2)
- August (1)
- July (2)
- June (1)
- May (1)
- March (1)
- February (3)
- January (1)
-
2009
(42)
- December (1)
- November (4)
- October (3)
- September (3)
- August (4)
- July (1)
- June (4)
- May (6)
- April (6)
- March (3)
- February (5)
- January (2)
-
2008
(28)
- December (4)
- November (3)
- October (3)
- September (3)
- August (4)
- July (2)
- June (2)
- May (1)
- April (2)
- March (2)
- February (2)